







欢迎关注 OpenMMLab 公众号获取一手技术干货
当我们向 ChatGPT 提问时,我们希望他能准确地回答我们的问题。当我们向他提出不合理的要求,比如询问如何制作炸弹或者如何考试作弊,我们希望他能拒绝回答并及时纠正我们的错误。AI 对齐,就是让 AI 的价值观符合我们人类的价值观,更好地为我们所用。
为什么要自对齐(Self-alignment)
之前的对齐方式一般需要大量高质量的微调数据或者人类反馈的偏好数据,但是随着 LLM 的能力的不断提高,我们已经在越来越多的任务上逊色于 LLM,以往这种依赖于人类标注数据的对齐方式目前面临着如下两个挑战:
-
进一步提升对齐水平需要更多的高质量标注数据,成本过高,且边际效益不断递减。
-
LLM 能力超过人类,我们可能无法继续提供有效的对齐信号。面对能力强大的 LLM,我们不能轻易地分辨出他们回答的好坏来得到偏好数据,或者难以判断 LLM 回答的缺点,此时的对齐信号将不可避免存在许多噪音。
既然从人类标注数据中获取对齐信号的方式遇到了困难,那么能不能依靠模型自己依靠自己来对齐呢?当然有,这就是 Self-alignment 所要解决的问题,依靠模型自己进行对齐,尽量减少人类的干预。 根据当前工作所采用的方法,我们将 Self-alignment 的实现路线大致分为两类:
-
对齐 Pipline 数据合成:对目前对齐 Pipline 中所需的数据用 LLM 合成。传统 Pipline 主要包括 Instructions 和 Response 数据的采集,之后采用 SFT 或 RLHF 训练方式来对齐。既然 LLM 已经足够强大,我们何不利用 LLM 自己来合成这些数据。
-
Multi-agent:基于 Multi-agent 的对齐。我们可以精心设计多个 LLM 之间的组织形式,比如“左右互搏”的对抗方式或者利用多智能体协作合成微调数据。
本系列文章将分享 LLM 自对齐技术的最新研究进展,基于下图的架构,对当前 Self-alignment 相关工作进行全面梳理,厘清技术路线并分析潜在问题。
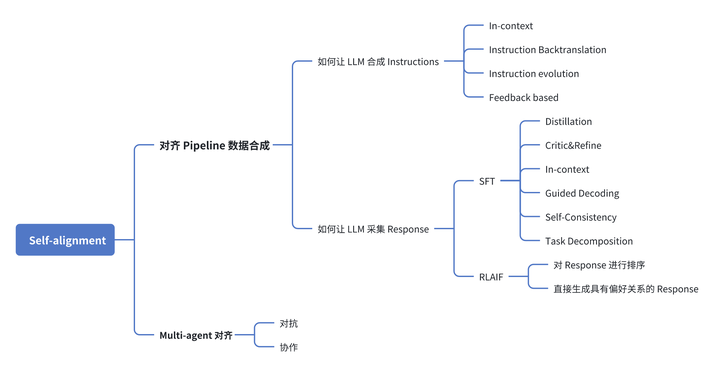
添加图片注释,不超过 140 字(可选)
对齐 Pipline 一般包括收集 Instructions、收集 Response、SFT 或 RLHF 训练三个步骤。这里收集的 Response 数据可能是人类撰写的 Response(SFT)或者是人类标注的偏好 Response(RLHF)。
该 Pipline 以数据作为驱动,依赖于高质量的标注数据。为了实现 Self-alignment,我们需要让 LLM 替代人类来采集这些数据。对于该路线的 Self-alignment,我们需要回答两个问题:
-
如何让 LLM 合成 Instructions
-
如何让 LLM 采集 Response 本篇文章将重点探讨“如何让 LLM 合成 Instructions”,深入分析现有的研究工作是如何解答这一问题的。
首先需要明确一
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









