







目标是解析一个xml文件:
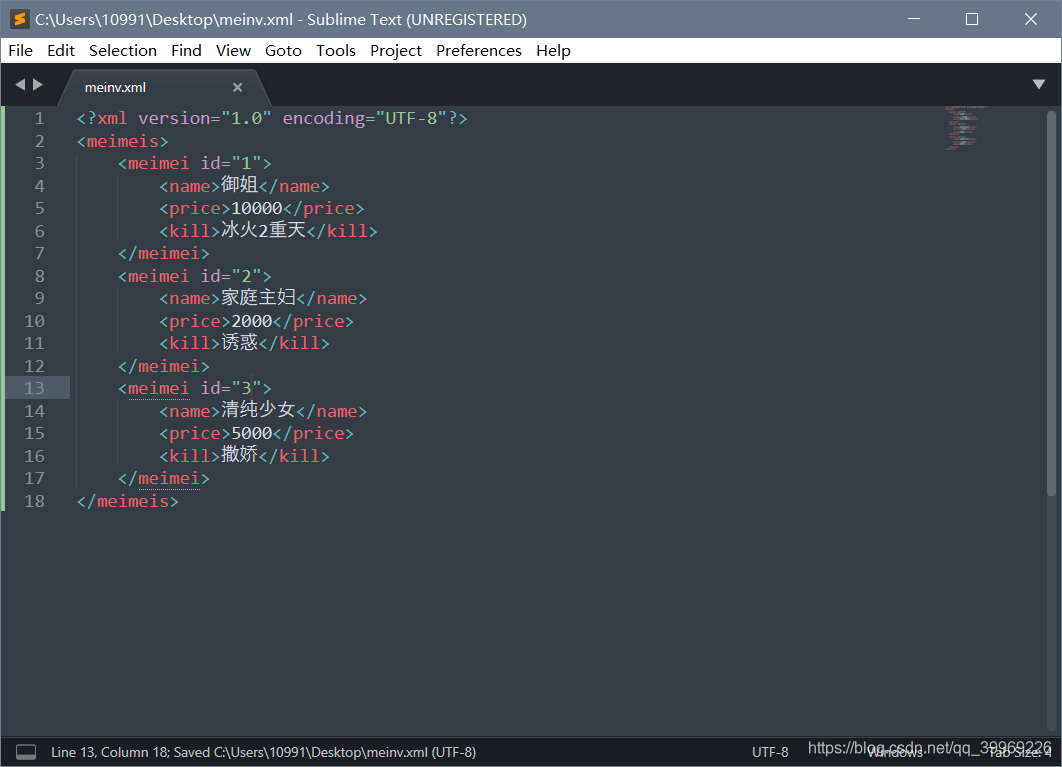
因为解析XML是很重要的技能:比如微信公众号的后台开发、spring的原理、android的xml系统流程解析布局等。
skill写成了kill,手动滑稽~
xml有2种解析方式:
- dom解析(w3c标准解析方法,但是效率低。文档dom树,子节点又有小节点。开辟内存空间把整个dom树弄进来。如果文档大,则dom树占用的内存消耗很大。且如果只要解析一个节点,全部装到内存就浪费了)
- SAX解析(解决dom弊端。扫描开头和结束标签,触发相应的事件,事件驱动【开始结束自动触发】,只拿要用的一部分节点)
这里值得说明的是,很多时候报空指针:

是需要注意,像上方的"尹磊",和其他name、price、kill都属于meimei的子节点。
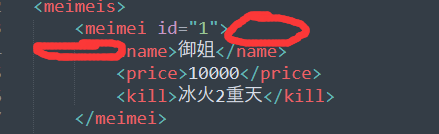
空格和回车都属于子节点。都属于文字。
所以需要排除文字形式的,只讨论标签形式的。
dom解析
1. 准备实体类,根据上图,可以看到相同的属性加一个meimei标签构成了一个实体类:
属性和标签对应:
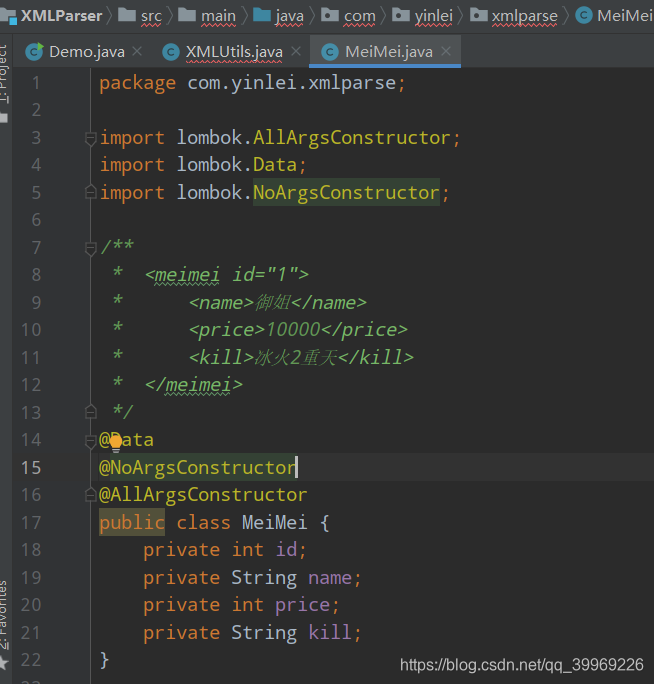
2. 编写解析逻辑:(从DocumentBuilderFactory入手)
package com.yinlei.xmlparse;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class XMLUtils {
public static List<MeiMei> parseXMLToList(String fileName) throws ParserConfigurationException, IOException, SAXException {
List<MeiMei> meimeis = new ArrayList<>();
// DOM方式解析: 入口
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();//产生DOM工厂实例
// 造东西
DocumentBuilder builder = factory.newDocumentBuilder();
// 准备输入流,parse()需要
// 解析成一个可以用java处理的document对象
Document document = builder.parse(new FileInputStream(fileName));
// 获取所有文档的节点
Element element = document.getDocumentElement();
// 获取<meimei>这个节点,得到节点的集合
NodeList nodeList = element.getElementsByTagName("meimei");
// 遍历nodelist
for (int i = 0; i < nodeList.getLength(); i++) {
MeiMei meimei = new MeiMei();
// Node item = nodeList.item(i);// 获取每个<meimei>
Element meimeiElement = (Element)nodeList.item(i);// 获取每个<meimei>
// 获取meimei的id属性
// tem.getAttributes()[0];
int id = Integer.parseInt(meimeiElement.getAttribute("id"));
meimei.setId(id);
//拿<meimei>的子节点<name>、<price><kill>
NodeList childNodes = meimeiElement.getChildNodes();
// 遍历子节点
for (int j=0;j<childNodes.getLength();j++){
// 每一个子节点<name> <price> <kill> ,也有可能是空格或文字
Node meimeiChild = childNodes.item(j);
//只拿标签形式的子节点
if (meimeiChild.getNodeType() == Node.ELEMENT_NODE) {
switch (meimeiChild.getNodeName()){//拿到标签名
case "name":
String name = meimeiChild.getFirstChild().getNodeValue();
meimei.setName(name);
break;
case "price":
String price = meimeiChild.getFirstChild().getNodeValue();
meimei.setPrice(Integer.parseInt(price));
break;
case "kill":
String kill = meimeiChild.getFirstChild().getNodeValue();
meimei.setKill(kill);
break;
default:
break;
}
}
}
meimeis.add(meimei);
}
return meimeis;
}
}


SAX解析
事件驱动:程序执行时,到哪个阶段时,自动触发那个阶段的方法。如web中的ajax
1.还是需要实体类:上面的实体类。
2. 解析:(通过sax的处理器来完成DefaultHandler)
package com.yinlei.xmlparse;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
import java.util.ArrayList;
import java.util.List;
/**
* sax解析
*/
public class SAXParseXML extends DefaultHandler {
private List<MeiMei> meimeis = null;
public List<MeiMei> getMeimeis() {
return meimeis;
}
// 元素的名字
private String tagName;
private MeiMei meiMei;
/**
* 解析xml开始(执行一次)
* @throws SAXException
*/
@Override
public void startDocument() throws SAXException {
meimeis = new ArrayList<>();
}
/**
* 解析xml结束(执行一次)
* @throws SAXException
*/
@Override
public void endDocument() throws SAXException {
System.out.println("SAX解析结束。。");
}
/**
* 解析元素开始(执行多次)
* <name>
* yinlei
* </name>
* 这里的yinlei不在标签里,在characters()里才能拿到。
* @param uri
* @param localName
* @param qName 标签名
* @param attributes 属性
* @throws SAXException
*/
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (qName.equals("meimei")) {
meiMei = new MeiMei();
int id = Integer.parseInt(attributes.getValue(0));
meiMei.setId(id);
}
this.tagName = qName;
}
/**
* 解析元素结束(执行多次)
* @param uri
* @param localName
* @param qName
* @throws SAXException
*/
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
if (qName.equals("meimei")){
meimeis.add(meiMei);
}
this.tagName = null;
}
/**
* 开始解析元素和结束解析元素之间调用多次.
* 拿中间真正的值
* 比如拿<name>yinlei</name>
* 就可以拿到yinlei
* @param ch 里面是要解析的值,自动放在了这里面。
* @param start
* @param length
* @throws SAXException
*/
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
if (this.tagName != null) {
String data = new String(ch,start,length);//ch()=>String
if (this.tagName.equals("name")) {
//name
meiMei.setName(data);
}
if (this.tagName.equals("price")) {
//price
meiMei.setPrice(Integer.parseInt(data));
}
if (this.tagName.equals("kill")) {
//kill
meiMei.setKill(data);
}
}
}
}
3. 使用:
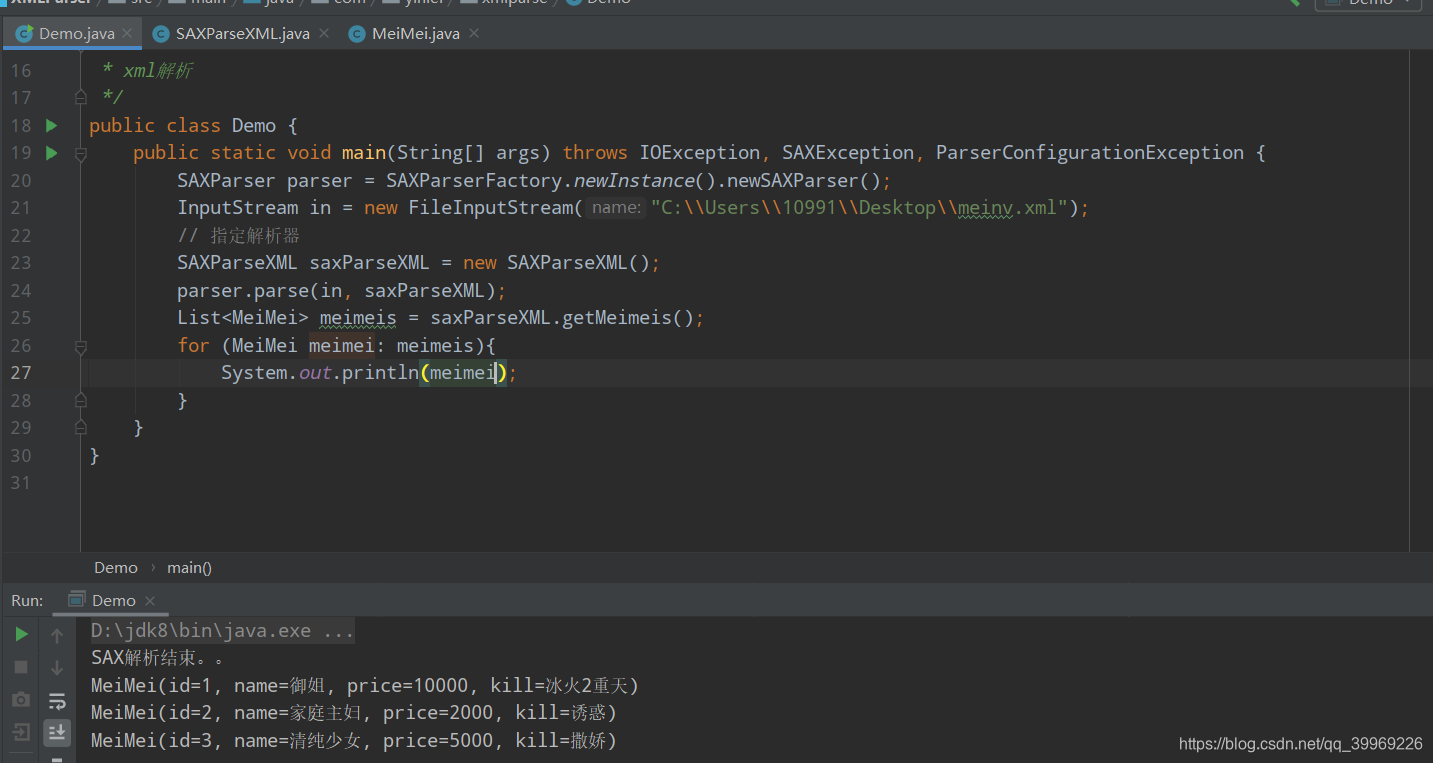
package com.yinlei.xmlparse;
import com.sun.org.apache.xml.internal.resolver.readers.SAXParserHandler;
import org.xml.sax.SAXException;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
/**
* xml解析
*/
public class Demo {
public static void main(String[] args) throws IOException, SAXException, ParserConfigurationException {
SAXParser parser = SAXParserFactory.newInstance().newSAXParser();
InputStream in = new FileInputStream("C:\\Users\\10991\\Desktop\\meinv.xml");
// 指定解析器
SAXParseXML saxParseXML = new SAXParseXML();
parser.parse(in, saxParseXML);
List<MeiMei> meimeis = saxParseXML.getMeimeis();
for (MeiMei meimei: meimeis){
System.out.println(meimei);
}
}
}















 523
523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











