






c++八股(可能问的多一点)
1.简单说说C++11语法特性
答:
1.auto以及decltype自动类型推导,避免手动声明复杂类型,减少冗长代码提升了可读性和安全性。
2.智能指针 自动释放内存
(具体说说)
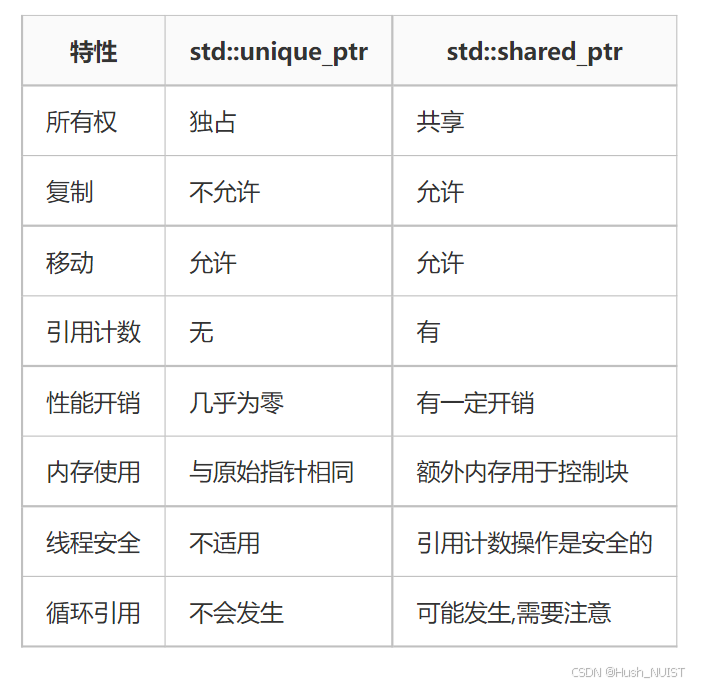
有shared和unique 差异主要体现在所有权、内存开销、引用计数以及线程安全上。
(本质和实现原理)
智能指针本质是一个封装了一个原始C++指针的类模板,为了确保动态内存的安全性而产生的。实现原理是通过一个对象存储需要被自动释放的资源,然后依靠对象的析构函数来释放资源。
(说说shared和unique的区别)
3.nullptr来代替NULL来表示空指针,因为NULL实际上是整数0,而不是一个真正的指针类型,容易产生误导。
4.C++11中的移动语义和右值引用(T&&)用于避免不必要的深拷贝,提高性能。它们允许对象的资源在右值或即将销毁的对象之间转移,而不是复制。例如,std::move 强制将对象转换为右值引用,从而实现高效的资源转移,减少内存分配和拷贝操作。移动构造函数和移动赋值运算符是实现这一功能的关键。
(为什么要引入右值引用?)右值引用是为一个临时变量取别名,它只能绑定到一个临时变量或表达式(将亡值)上。实际开发中我们可能需要对右值进行修改(实现移动语义时就需要)而右值引用可以对右值进行修改。
(左值引用和指针的区别?)
是否初始化:指针可以不用初始化,引用必须初始化 这里要区分初始化和声明的差异
本质不同:指针是一个变量,拥有自己的内存空间,引用是对被引用的对象取一个别名,引用和被引用对象占同一个空间。
5.lambda表达式
6.std::thread 多线程库的支持
7.范围for循环
2.说说面向对象的三大特性及其意义
封装 隐藏实现细节 实现模块化
继承 不修改类的情况下实现代码重用和扩展
多态 一个接口多种形态 为了代码扩展和重用性 分为静态多态和动态多态 分别用函数重载和虚函数重写实现
3.虚函数是怎么实现的?它存放在哪里在内存的哪个区?什么时候生成的
虚函数通过虚函数表和虚函数指针来实现的。虚函数表本质上就是一个由指针构成的数组,每个元素中的指针,即虚函数指针,会指向一个虚函数重写的实现代码。
虚函数表存放在静态存储区,在编译期就会生成。虚函数指针存放在实现该虚函数的对象的内存布局中,对象的内存是堆或栈,它就在哪里。
3 补充 说说虚函数和纯虚函数的区别
虚函数:可以有实现,允许重写。
纯虚函数:没有实现,必须在派生类中实现。
4.Static关键词的作用?
static 关键字有三个主要作用:
局部变量:在函数内部,static 局部变量只初始化一次,且在函数调用结束后仍然保留其值。
全局变量/函数:在文件内部,static 限制全局变量或函数的作用域,使其仅对当前文件可见。
类成员:在类中,static 成员变量或函数属于类本身而非某个对象,可以不通过对象访问(
int MyClass::count = 0;)。
贴个代码理解第三点:
#include <iostream>
class MyClass {
public:
// 静态成员变量,属于类本身
static int count;
// 构造函数,每创建一个对象,count 就增加1
MyClass() {
count++;
}
// 静态成员函数,用于访问或修改静态成员变量
static void showCount() {
std::cout << "Count: " << count << std::endl;
}
};
// 初始化静态成员变量
int MyClass::count = 0;
int main() {
// 在没有创建对象的情况下,直接通过类名访问静态成员函数
MyClass::showCount(); // 输出: Count: 0
MyClass obj1;
MyClass obj2;
// 可以通过类名或者对象访问静态成员
obj1.showCount(); // 输出: Count: 2
MyClass::showCount(); // 输出: Count: 2
return 0;
}
5.typedef和define有什么区别?
typedef 用于定义类型别名,遵循编译器检查.#define 是预处理宏替换,直接文本替换,无类型检查。
6.简单说说final、extern、const、voliate的作用
final 防止继承 保证类不再扩展
extern 跨文件全局变量
const 定义常量
voliate 防止意外修改值 避免编译器优化
7.说说指针常量和常量指针
指针常量是指针本身是一个常量,指针指向的地址不可变 指向的对象值可以修改
常量指针是一个指向常量的指针,指向可以指向其他对象,指向的对象的值不可以改变
8.友元是什么?
友元(friend)是一个能够访问类的私有和保护成员的函数或类。
9.如何解决菱形继承的问题?
菱形继承发生在两个派生类从同一个基类继承,且最终有一个派生类同时继承两个派生类,导致重复继承
用虚基类,这样派生的是最后覆盖的虚函数。
10.如何将数据定义为寄存器变量?
关键字register register int a
11.有没有遇到内存泄漏的情况 如何处理的?
写代码的时候遵循RALL 使用智能指针
Visual Leak Detector
12.为什么不全用mmap分配内存?
mmap将文件映射到内存空间,作为一个系统调用的分配内存的手段,必然伴随着大量用户态和内核态的切换,这对小内存块的分配和释放非常不利,因此mmap知识和大内存块的分配
13.为什么不全用brk分配内存?
brk所操作的是堆的内存空间。堆内存分配往往会导致内存碎片,尤其是当内存频繁分配和释放时,连续的堆空间难以保持。这会影响性能。
14.define和const的区别是什么?
编译阶段:define是在编译预处理阶段进行简单的文本替换,const是在编译阶段确定其值
安全性:define定义的宏常量没有数据类型,只是进行简单的替换,不会进行类型安全检查;const定义的常量是有类型的,是要进行类型判断的
内存占用:define定义的宏常量,在程序中使用多少次就会进行多少次替换,内存中有多个备份,占用的是代码段的内存;const定义常量占用静态存储区域的空间,程序运行过程中只有一份
调试:define定义的宏常量不能调试,因为在预编译阶段就已经进行替换了;const定义的常量是可以进行调试的。
15.程序运行的步骤
预处理 编译 汇编 链接
补充 静态链接
16.class与struct的区别
默认继承权限不同:class默认继承的是private继承,struct默认是public继承。
C++保留struct关键字,原因是保证与C语言的向下兼容性,为了保证百分百的与C语言中的struct向下兼容,C++把最基本的对象单元规定为class而不是struct,就是为了避免各种兼容性的限制。
17.锁的底层机制是什么?
锁的底层原理是通过硬件或操作系统提供的原子操作,如CAS,即Compare And Swap,就是每一个线程从主内存复制一个变量副本后,进行操作,然后对其进行修改,修改完后,再刷新回主内存前。再取一次主内存的值,进行比较,是否一样,如果不一样,说明有其他线程修改,本次修改放弃,重试。
18.原子操作是什么?
是不会被线程调度机制打断的操作,一旦开始就一直运行到结束,不会被打断。
原理是通过硬件实现的
19.为什么要内存对齐
增加程序的可移植性以及提高程序的运行效率 不对齐(有些程序因为不能读任意位置,就要多次访问才能读取想要的数据)
20.进程之间通信的方式
管道
信号
信号量
共享内存
消息队列
套接字
21.线程之间通信的方式
信号量
条件变量
互斥量
补充 Socket
22.介绍一下socket中的多路复用,及其他们的优缺点,epoll的水平和边缘触发模式
socket中的IO多路复用技术主要由select(可移植性好)、poll(没有最大并发连接限制)、epoll
epoll不需要轮询 缺点是只有linux上存在
epoll的et模式是内核只通知一次该IO操作,如果处理就必须一次性将数据读取完。
lt这是默认的方式,如果应用程序不处理该io操作,内核会一直发消息。
23. https协议为什么安全?
加密传输:使用对称加密保护数据的隐私。
身份验证:HTTPS 使用数字证书来验证服务器的身份,确保客户端连接的是可信赖的服务器,而不是冒充的攻击者。
数据完整性:通过消息摘要(Hash)技术,HTTPS 确保传输过程中数据没有被篡改。如果数据被篡改,接收方可以检测到,并拒绝接受数据。
总结:HTTPS 的安全性依赖于加密传输、身份验证和数据完整性,从而确保数据在传输过程中不被窃听、伪造或篡改。
24. 多线程为什么会发生死锁,死锁是什么?死锁产生的条件,如何解决死锁?
因为在多进程中容易发生资源竞争,如果一个进程集合里面的每一个进程都在等待这个集合中的其他一个进程才能继续往下执行,这种情况就是死锁。
产生死锁的四个条件:互斥条件(资源是不可贡献的)、请求和保持条件(请求后保持了一个资源后还请求其他资源,但被阻塞了)、不可剥夺条件(资源不可被系统剥夺 必须自己释放)、环路等待(形成了一个等待链)条件。解决死锁的方法就是破坏上述任意一种条件。
25.描述一下面向对象和面向过程
面向对象:就是将问题分解为各个对象,建立对象的目的不是为了完成一个步骤,而是为了描述某个事物在整个解决问题的步骤中的行为,相比面向过程,代码更易维护和复用。但是代码效率相对较低。
面向过程:就是将问题分析出解决问题的步骤,然后将这些步骤一步一步的实现,使用的时候一个一个调用就好。代码效率更高但是代码复用率低,不易维护。
26.介绍一下vector、list的底层实现原理和优缺点
vector底层是动态数组,支持下表访问,读取比较快,删除和插入比较麻烦,扩容也必要麻烦。
list底层是双向链表,插入删除容易,读取麻烦,内存开销也会大一些。
27.静态变量在哪里初始化?在哪一个阶段初始化?(都存放在全局区域)
静态变量,全局变量,常量都在编译阶段完成初始化和内存分配。其他变量都是在编译阶段进行初始化,运行阶段内存分配
补充 说说C++的内存结构
C++ 的内存结构主要分为以下几个区域:
- 代码段:存放程序的可执行代码。
- 数据段:
- 全局存储区:存放全局变量和静态变量,分为初始化和未初始化部分(BSS)。
- 常量存储区:存放常量字符串和常量值。
- 堆:动态分配的内存区域,由
new和malloc等函数管理,大小可动态变化。 - 栈:存放局部变量、函数参数和返回地址,使用 LIFO(后进先出)策略管理,大小固定。
28.如何实现多线程?
Linux上用fork()
Win上用thread.join
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex mtx; // 互斥锁
std::condition_variable cv; // 条件变量
int turn = 0; // 用于跟踪应该哪个线程输出,0 -> A, 1 -> B, 2 -> C
void printA() {
for (int i = 0; i < 4; ++i) { // 输出4次以达到ABCABCABCABC
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, []{ return turn == 0; }); // 等待 turn 轮到 A
std::cout << "A";
turn = 1; // 轮到 B
cv.notify_all(); // 通知其他线程
}
}
void printB() {
for (int i = 0; i < 4; ++i) {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, []{ return turn == 1; }); // 等待 turn 轮到 B
std::cout << "B";
turn = 2; // 轮到 C
cv.notify_all(); // 通知其他线程
}
}
void printC() {
for (int i = 0; i < 4; ++i) {
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, []{ return turn == 2; }); // 等待 turn 轮到 C
std::cout << "C";
turn = 0; // 轮到 A
cv.notify_all(); // 通知其他线程
}
}
int main() {
std::thread threadA(printA); // 线程A输出A
std::thread threadB(printB); // 线程B输出B
std::thread threadC(printC); // 线程C输出C
threadA.join(); // 等待线程A结束
threadB.join(); // 等待线程B结束
threadC.join(); // 等待线程C结束
std::cout << std::endl;
return 0;
}
29.空类中有什么函数?
默认构造函数、默认拷贝构造函数、默认析构函数、默认赋值运算符
30.New和malloc
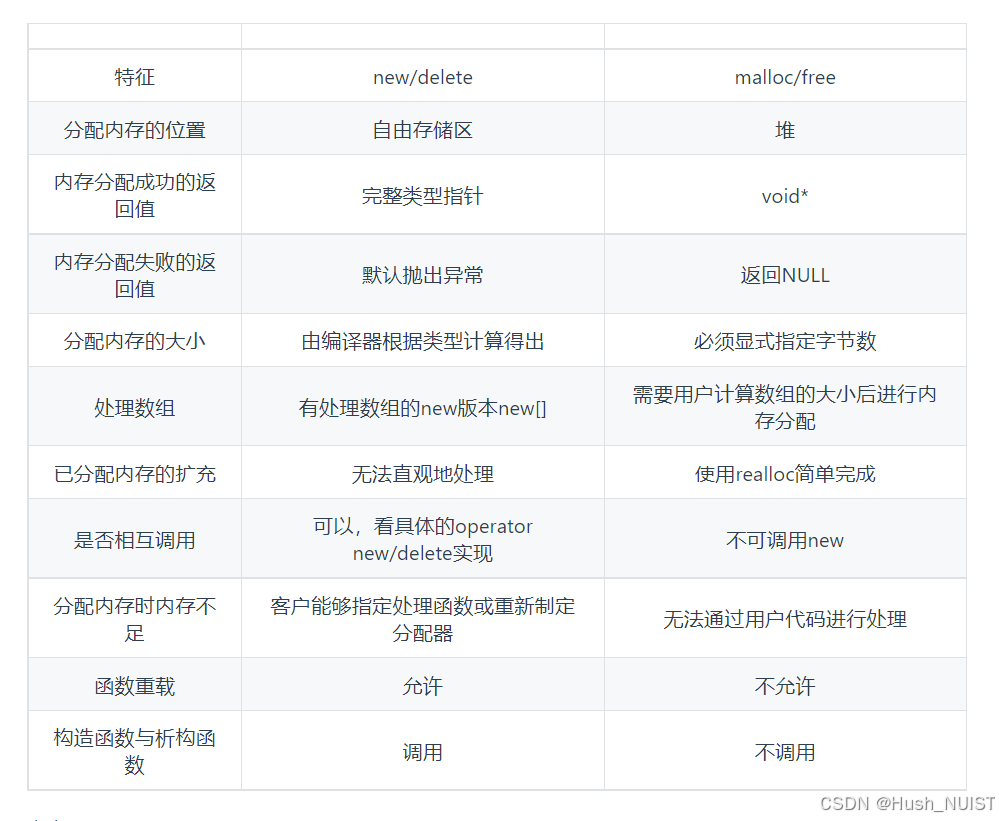
补充 说说malloc的底层原理
malloc 的底层原理基于堆管理。
具体步骤如下:
- 请求处理:
malloc接收请求的字节数。 - 内存管理器:使用特定的内存管理算法(如首次适应、最佳适应或伙伴系统)在堆中寻找足够大的空闲块。
- 分配内存:找到合适的空闲块后,更新块的状态(标记为已分配),并返回指向该内存块的指针。
- 元数据维护:为了管理已分配和空闲的内存块,
malloc会维护元数据,通常在每个块的前面存储大小和状态信息。
31.什么是STL?
它是C++标准库的重要组成部分,不仅是一个可复用的组件库也是一个包含了数据结构与算法的软件架构,它拥有几大类型分别是:算法,迭代器,容器,函数对象
补充 说说STL的类型和特性
STL(标准模板库)主要包括以下几种类型和特性:
-
容器:存储数据的结构,如:
- 序列容器:
vector、list、deque,支持顺序访问。 - 关联容器:
set、map、unordered_set、unordered_map,支持基于键的快速访问。 - 适配器:如
stack、queue,基于其他容器提供特定功能。
- 序列容器:
-
算法:提供对容器的操作,如排序、查找和修改,具有通用性和高效性。
-
迭代器:提供统一的访问容器元素的方式,支持不同类型的容器。
-
函数对象:可作为算法参数的对象,增强灵活性。
STL 的特性包括泛型编程、高效性和可重用性。
32.线程有哪些状态,线程锁有哪些?
五种状态:创建,就绪,运行,阻塞,死亡
线程锁的种类:互斥锁,条件锁,自旋锁,读写锁,递归锁
33.C++中空类的大小是多少?
1字节
34.哪些函数不能被声明为虚函数?
构造函数,内联函数(内联函数有实体,在编译时展开,没有this指针),静态成员函数,友元函数(C++不支持友元函数的继承),非类成员函数
35.空类中有哪些函数
析构 构造 拷贝构造 运算符
36.weak_ptr的实现方式和作用
实现依赖于计数器和寄存器实现的,计数器用来记录弱引用的数量,寄存器用来存储shared_ptr
作用和目的是为了解决share_ptr的循环引用问题
37.移动构造和拷贝构造的区别是什么?
移动构造函数本质上是基于指针的拷贝,实现对堆区内存所有权的移交,在一些特定场景下,可以减少不必要的拷贝。比如用一个临时对象或者右值对象初始化类实例时。我们可以使用move()函数,将一个左值对象转变为右值对象。而拷贝构造则是将传入的对象复制一份然后放进新的内存中
算法与数据结构
顺序表和链表的差异
物理结构上顺序表相邻 链表一般不相邻
访问元素 O(1)和O(n)
顺序表静态分配空间 链表动态分配
栈和队列
队列是一端进行插入另一端进行删除的线性表
栈是表尾进行插入和删除的线性表
栈和队列可以用于前缀表达式和后缀表达式
二叉树
完全二叉树和满二叉树:除了最后一层外,其他任何一层的节点数均达到最大值,且最后一层也只是在最右侧缺少节点(完全)
平衡二叉树(AVL):任意结点的左、右子树高度差的绝对值不超过1
哈夫曼树:带权路径长度最小的二叉树,即最优二叉树
图的遍历方式
深度搜索和广度搜索
排序
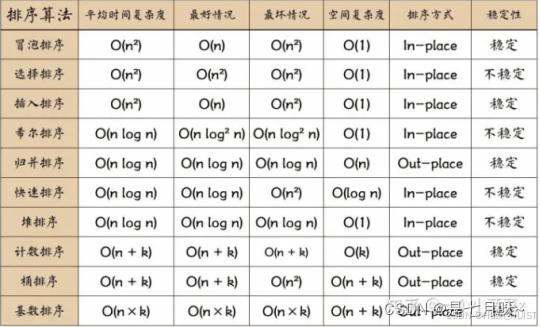
以下是每种排序算法的简单伪代码,帮助理解其基本原理。
1. 冒泡排序(Bubble Sort)
冒泡排序通过重复比较相邻元素,将较大或较小的元素“冒泡”到序列的一端。
for i from 0 to n - 1:
for j from 0 to n - i - 1:
if array[j] > array[j + 1]:
swap(array[j], array[j + 1])
2. 选择排序(Selection Sort)
选择排序每次从未排序部分中找到最小元素,放到已排序部分的末尾。
for i from 0 to n - 1:
minIndex = i
for j from i + 1 to n:
if array[j] < array[minIndex]:
minIndex = j
swap(array[i], array[minIndex])
3. 插入排序(Insertion Sort)
插入排序将每个元素插入到它前面已经排序好的部分中,确保前面的序列始终有序。
for i from 1 to n:
current = array[i]
j = i - 1
while j >= 0 and array[j] > current:
array[j + 1] = array[j]
j = j - 1
array[j + 1] = current
4. 希尔排序(Shell Sort)
希尔排序是插入排序的优化版,通过分组减少元素移动次数,逐步缩小分组间隔至 1。
gap = n / 2
while gap > 0:
for i from gap to n:
current = array[i]
j = i
while j >= gap and array[j - gap] > current:
array[j] = array[j - gap]
j = j - gap
array[j] = current
gap = gap / 2
5. 归并排序(Merge Sort)
归并排序是分治法排序算法,将数组递归拆分为两半,分别排序后合并。
function mergeSort(array):
if array has 1 element:
return array
mid = array.length / 2
left = mergeSort(array[0:mid])
right = mergeSort(array[mid:])
return merge(left, right)
function merge(left, right):
result = empty array
while left and right are not empty:
if left[0] < right[0]:
append left[0] to result and remove it from left
else:
append right[0] to result and remove it from right
append remaining elements of left (if any) to result
append remaining elements of right (if any) to result
return result
6. 快速排序(Quick Sort)
快速排序通过选一个“基准”元素,将序列分成小于和大于基准的两部分,递归排序。
function quickSort(array, low, high):
if low < high:
pivotIndex = partition(array, low, high)
quickSort(array, low, pivotIndex - 1)
quickSort(array, pivotIndex + 1, high)
function partition(array, low, high):
pivot = array[high]
i = low - 1
for j from low to high - 1:
if array[j] < pivot:
i = i + 1
swap(array[i], array[j])
swap(array[i + 1], array[high])
return i + 1
7. 堆排序(Heap Sort)
堆排序通过构建最大堆,然后依次将堆顶元素与最后一个元素交换,再调整堆。
function heapSort(array):
buildMaxHeap(array)
for i from n - 1 down to 1:
swap(array[0], array[i])
maxHeapify(array, 0, i)
function buildMaxHeap(array):
for i from n / 2 down to 0:
maxHeapify(array, i, n)
function maxHeapify(array, root, size):
largest = root
left = 2 * root + 1
right = 2 * root + 2
if left < size and array[left] > array[largest]:
largest = left
if right < size and array[right] > array[largest]:
largest = right
if largest != root:
swap(array[root], array[largest])
maxHeapify(array, largest, size)
这些伪代码展示了排序算法的基本结构和核心逻辑。希望这些可以帮助你理解每种排序算法的原理!
Linux和操作系统的八股
1.常用指令
列出文件列表 ls
切换目录 CD
复制文件 cp
关机 shutdown now
文件修改权限 chmod
创建文件夹 mkdir 创建文件 touch
删除 rm
查找 grep find
查看内存 free cat
解压 tar -xzvf
打包 tar -czvf
查看进程 top
查看内存 free
2.gcc编译的四个步骤:预处理 编译 汇编 链接
3.Linux常见信号
SIGHUP 挂机进程
SIGINT 中断进程
SIGQUIT 退出进程
4.Linux内核的组成部分
Linux内核主要由五个子系统组成:进程调度、内存管理、虚拟文件系统、网络接口、进程间通信。
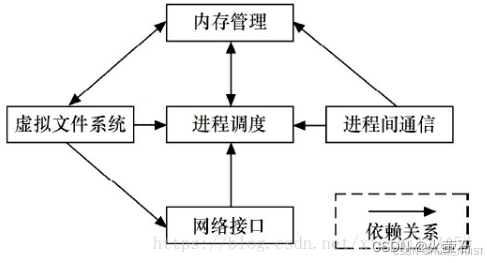
这五个子系统的作用可以简单理解如下:
-
进程调度:负责管理系统中的所有进程,决定哪个进程在何时使用CPU资源。它的目标是让CPU高效地为多个任务服务,实现多任务处理。
-
内存管理:控制系统内存的分配和回收。它为每个进程分配内存,确保进程不会互相干扰,并提供虚拟内存的功能,让程序运行时可以使用比物理内存更大的地址空间。
-
虚拟文件系统 (VFS):提供一个通用的接口,让不同类型的文件系统可以一致地访问。无论底层是磁盘文件、网络文件还是其他类型,进程都可以通过同一接口进行文件操作。
-
网络接口:处理网络通信。它提供了网络协议的实现(如TCP/IP),使系统能够连接网络,与其他计算机交换数据。
-
进程间通信 (IPC):为进程之间的数据交换提供机制。它包括信号、管道、消息队列等方法,让进程可以协作或同步工作。
依赖关系理解
- 进程调度作为核心,连接和协调其他子系统。例如:
- 它依赖内存管理来分配进程运行所需的内存。
- 进程间通信需要进程调度来管理进程间的数据交换。
- 网络接口通过进程调度安排与网络相关的任务。
- 虚拟文件系统同样依赖进程调度来完成文件操作。
这些子系统共同协作,确保系统资源被有效利用,实现稳定和高效的操作。
补充 说说Linux的内存结构
内核区
用户区
代码区
数据区(全局和静态变量)
堆
栈
5.Linux系统的组成部分
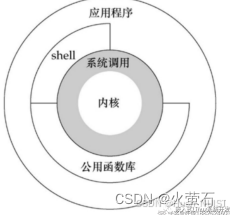
内核、shell、文件系统和应用程序。
6.用户空间与内核通信方式有哪些?
1)系统调用。用户空间进程通过系统调用进入内核空间,访问指定的内核空间数据;
2)驱动程序。用户空间进程可以使用封装后的系统调用接口访问驱动设备节点,以和运行在内核空间的驱动程序通信;
3)共享内存mmap。在代码中调用接口,**实现内核空间与用户空间的地址映射,**在实时性要求很高的项目中为首选,省去拷贝数据的时间等资源,但缺点是不好控制;
7. 内核态,用户态的区别
内核态,操作系统在内核态运行——运行操作系统程序
用户态,应用程序只能在用户态运行——运行用户程序
当一个进程在执行用户自己的代码时处于用户运行态(用户态),此时特权级最低,为3级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态。Ring3状态不能访问Ring0的地址空间,包括代码和数据;当一个进程因为系统调用陷入内核代码中执行时处于内核运行态(内核态),此时特权级最高,为0级。执行的内核代码会使用当前进程的内核栈,每个进程都有自己的内核栈。
8. 硬链接与软链接
链接操作实际上是给系统中已有的某个文件指定另外一个可用于访问它的名称。对于这个新的文件名,我们可以为之指定不同的访问权限,以控制对信息的共享和安全性的问题。如果链接指向目录,用户就可以利用该链接直接进入被链接的目录而不用打一大堆的路径名。而且,即使我们删除这个链接,也不会破坏原来的目录。
1>硬链接
硬链接只能引用同一文件系统中的文件。
它引用的是文件在文件系统中的物理索引(也称为inode)。
当您移动或删除原始文件时,硬链接不会被破坏,因为它所引用的是文件的物理数据而不是文件在文件结构中的位置。
硬链接的文件不需要用户有访问原始文件的权限,也不会显示原始文件的位置,这样有助于
文件的安全如果您删除的文件有相应的硬链接,那么这个文件依然会保留,直到所有对它的引用都被
删除。
2>软链接(符号链接)
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的(那就和windows 下的快捷方式的那个文件有很接近的意味)。
软连接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用。
9. bootloader、内核 、根文件的关系
启动顺序:bootloader->linux kernel->rootfile(app)
Bootloader全名为启动引导程序,是第一段代码,它主要用来初始化处理器及外设,然后调用Linux内核。Linux内核在完成系统的初始化之后需要挂载某个文件系统作为根文件系统(RootFilesystem),然后加载必要的内核模块,启动应用程序。(一个嵌入式Linux系统从软件角度看可以分为四个部分:引导加载程序(Bootloader),Linux内核,文件系统,应用程序。)
10. 计算机中,32bit与64bit有什么区别
64bit计算主要有两大优点:
可以进行更大范围的整数运算;
可以支持更大的内存。
64位操作系统下的虚拟内存空间大小:地址空间大小不是232,也不是264,而一般是2^48。因为并
不需要2^64那么大的寻址空间,过大的空间只会造成资源的浪费。所以64位Linux一般使用48位表示虚拟空间地址,40位标识物理地址。
11.MMU基础
现代操作系统普遍采用虚拟内存管理(Virtual Memory Management)机制,这需要MMU(
Memory Management Unit,内存管理单元)的支持。有些嵌入式处理器没有MMU,则不能运行依赖
于虚拟内存管理的操作系统。
也就是说:操作系统可以分成两类,用MMU的、不用MMU的。
用MMU的是:Windows、MacOS、Linux、Android;不用MMU的是:FreeRTOS、VxWorks、
UCOS……
与此相对应的:CPU也可以分成两类,带MMU的、不带MMU的。
带MMU的是:Cortex-A系列、ARM9、ARM11系列;
不带MMU的是:Cortex-M系列……(STM32是M系列,没有MMU,不能运行Linux,只能运行一些
UCOS、FreeRTOS等等)。
MMU就是负责虚拟地址(virtual address)转化成物理地址(physical address
IP寄存器是通用寄存器么?
IP寄存器存储的是下一条要执行指令的地址 有特殊用途 所以不是通用寄存器
LR寄存器是什么?
LR寄存器存储的是程序运行函数或子函数时的地址,这样子程序或者函数运行完后可以通过LR寄存器返回调用点继续执行剩余的代码。
线程有哪几种状态?
创建 就绪 运行 阻塞 等待 超时等待 终止

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









