






目录
- 一、维度表设计核心原理
- 1.1 维度表本质解析
- 1.2 四大设计原则
- 二、企业级维度表设计全流程
- 2.1 业务建模阶段
- (1) 业务流程解构
- (2) 实体属性采集
- 2.2 物理设计阶段
- (1) 标准表结构
- (2) 特殊结构设计
- 2.3 SCD策略深度实现
- (1) Type 2 全流程实现
- (2) 混合策略应用
- 三、性能优化体系
- 3.1 存储层优化
- 3.2 计算层加速
- 3.3 查询优化技巧
- 四、企业级问题解决方案库
- 4.1 数据一致性问题
- 4.2 缓慢变化维度追踪
- 4.3 大数据量处理
- 五、实战训练营
- 案例背景
- 解决方案
- 六、效能评估体系
- 6.1 质量检查矩阵
- 6.2 性能基准测试
- 七、扩展阅读推荐
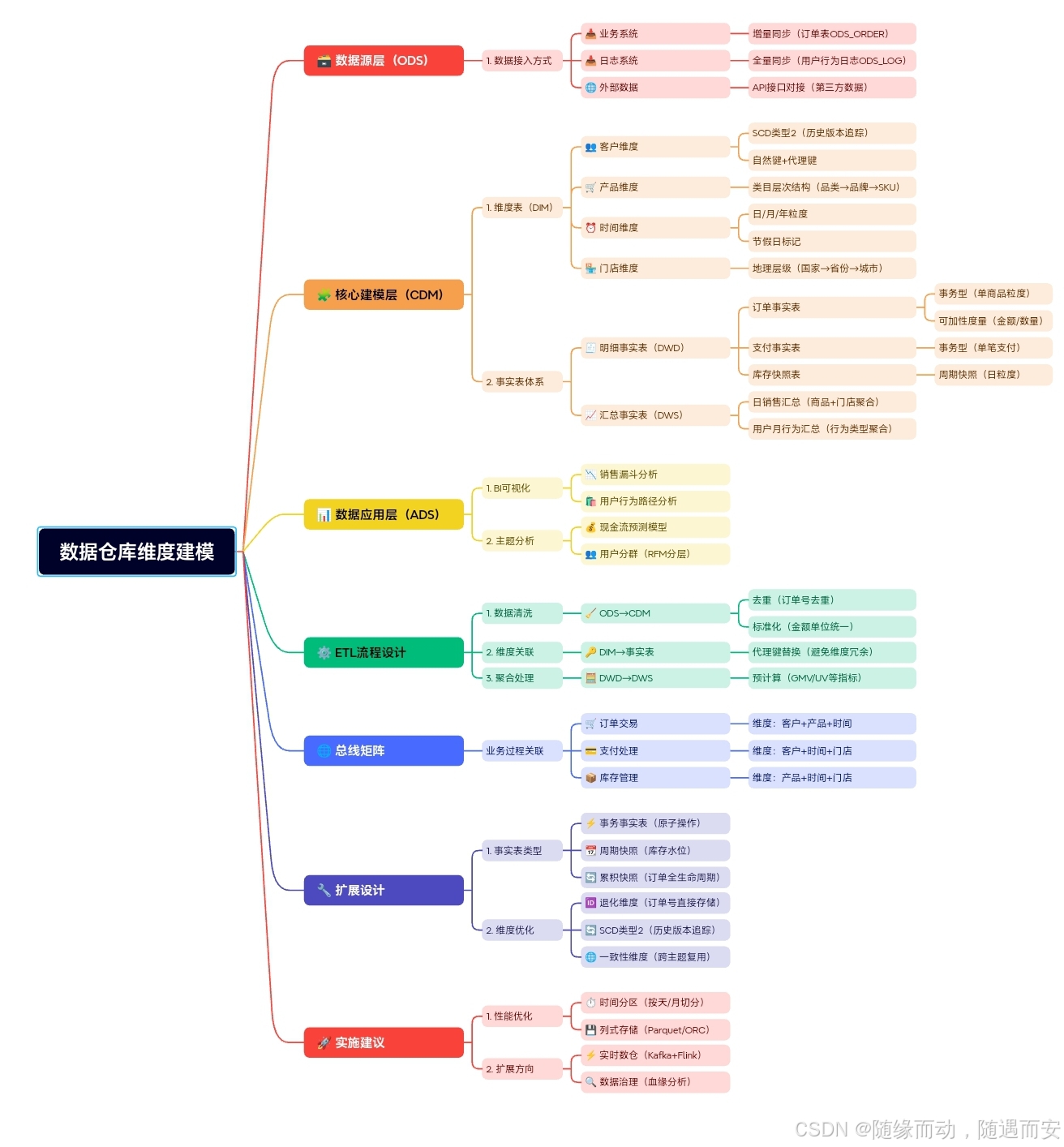
一、维度表设计核心原理
1.1 维度表本质解析
维度表是数据仓库中业务实体描述性数据的容器,其核心价值体现在:
- 业务语义映射:将事实表中的数值型度量转化为可理解的业务指标
- 上下文锚定:通过代理键建立与事实表的关联桥梁(自然键与代理键的映射机制)
- 时间旅行能力:支持历史数据回溯(基于SCD策略的时间有效性标记)
技术演进:传统维度表 -> 渐变维度 -> 微型维度
1.2 四大设计原则
| 原则 | 实施要点 | 典型反模式案例 |
|---|---|---|
| 原子性 | 属性存储最小业务单元(如拆分"省-市-区"为独立字段) | 将完整地址存储为单个字段 |
| 稳定性 | 非易变属性设计(如用户ID为持久键) | 使用电话号码作为用户标识 |
| 可扩展性 | 预留10%-20%的扩展字段 | 表结构频繁变更导致ETL中断 |
| 一致性 | 跨系统统一编码规则(如性别统一使用M/F编码) | 不同系统使用1/0和男/女混用 |
二、企业级维度表设计全流程
2.1 业务建模阶段
(1) 业务流程解构
使用BPMN 2.0标准建模工具,识别关键业务实体:
(2) 实体属性采集
构建属性矩阵表:
| 维度类型 | 属性名称 | 数据类型 | 来源系统 | 更新频率 | SCD策略 |
|---|---|---|---|---|---|
| 商品 | 商品ID | VARCHAR | ERP | 静态 | Type 0 |
| 商品 | 价格区间 | VARCHAR | CRM | 周更新 | Type 3 |
| 用户 | 会员等级 | INT | 会员系统 | 日更新 | Type 2 |
2.2 物理设计阶段
(1) 标准表结构
CREATE TABLE dim_product (
product_sk BIGINT PRIMARY KEY, -- 代理键
product_id VARCHAR(20) NOT NULL, -- 自然键
product_name NVARCHAR(255),
category_id INT,
category_name VARCHAR(50),
price_segment VARCHAR(20),
valid_from DATETIME2 GENERATED ALWAYS AS ROW START,
valid_to DATETIME2 GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME (valid_from, valid_to)
WITH (SYSTEM_VERSIONING = ON);
(2) 特殊结构设计
桥接表示例(多值维度处理):
-- 医生-患者关系桥接表
CREATE TABLE bridge_doctor_patient (
doctor_sk INT,
patient_sk INT,
relationship_weight DECIMAL(5,2),
effective_date DATE,
expiration_date DATE
);
-- 查询某医生的所有患者
SELECT p.*
FROM dim_patient p
JOIN bridge_doctor_patient b ON p.patient_sk = b.patient_sk
WHERE b.doctor_sk = 12345
AND GETDATE() BETWEEN b.effective_date AND b.expiration_date;
2.3 SCD策略深度实现
(1) Type 2 全流程实现
-- 历史记录失效
UPDATE dim_customer
SET valid_to = '2023-12-31'
WHERE customer_id = 'C1001'
AND valid_to = '9999-12-31';
-- 新记录插入
INSERT INTO dim_customer
(customer_sk, customer_id, tier, valid_from, valid_to)
VALUES
(NEXT VALUE FOR customer_sequence,
'C1001', 'VIP', '2024-01-01', '9999-12-31');
(2) 混合策略应用
# SCD策略选择器逻辑
def select_scd_strategy(attribute_metadata):
if attribute_metadata['history_required'] == False:
return 'Type1'
elif attribute_metadata['change_frequency'] == 'HIGH':
return 'Mini-Dimension'
else:
return 'Type2'
三、性能优化体系
3.1 存储层优化
| 技术手段 | 实施方法 | 适用场景 |
|---|---|---|
| 列式存储 | 使用Parquet/ORC格式 | 分析型查询为主 |
| 数据分片 | 按时间范围分片(每月一个分区) | 时序维度 |
| 编码压缩 | 字典编码低基数字段 | 性别、状态等字段 |
3.2 计算层加速
位图索引实现原理:
// 伪代码:性别字段位图索引
Map<String, BitSet> genderIndex = new HashMap<>();
genderIndex.put("M", new BitSet());
genderIndex.put("F", new BitSet());
void buildIndex(List<Record> records) {
for (int i=0; i<records.size(); i++) {
String gender = records.get(i).gender;
genderIndex.get(gender).set(i);
}
}
// 查询所有男性用户
BitSet result = genderIndex.get("M");
3.3 查询优化技巧
-- 低效查询
SELECT * FROM dim_product
WHERE category_id IN (SELECT id FROM categories WHERE level=3);
-- 优化后(使用预存层级)
SELECT * FROM dim_product
WHERE category_level3 IS NOT NULL;
四、企业级问题解决方案库
4.1 数据一致性问题
问题现象:
跨系统商品类目ID映射冲突(系统A的1001=手机,系统B的1001=电脑)
解决方案:
建立企业级维度中心:
4.2 缓慢变化维度追踪
历史数据回溯方案:
-- 时态查询语法
SELECT * FROM dim_product
FOR SYSTEM_TIME BETWEEN '2023-01-01' AND '2023-12-31'
WHERE product_id = 'P100';
4.3 大数据量处理
微型维度设计模式:
-- 用户信用分拆分为独立维度
CREATE TABLE mini_dim_credit (
credit_sk INT PRIMARY KEY,
credit_score INT,
risk_level VARCHAR(20)
PARTITIONED BY (score_range VARCHAR(20));
-- 主维度保留最新分关联
ALTER TABLE dim_user ADD credit_sk INT;
五、实战训练营
案例背景
某银行客户维度表需记录以下变更历史:
- 基本信息变更(地址、电话)→ Type2
- 风险评估等级变更 → Type2
- 客户经理变更 → Type3
解决方案
-- 混合策略表结构
CREATE TABLE dim_customer (
cust_sk BIGINT,
cust_id VARCHAR(20),
address VARCHAR(200),
risk_level VARCHAR(10),
previous_manager VARCHAR(50),
current_manager VARCHAR(50),
valid_from DATE,
valid_to DATE
);
-- 处理客户经理变更
UPDATE dim_customer
SET previous_manager = current_manager,
current_manager = '新经理姓名'
WHERE cust_id = 'C1001';
六、效能评估体系
6.1 质量检查矩阵
| 检查项 | 合格标准 | 检测方法 |
|---|---|---|
| 代理键唯一性 | 100%唯一 | COUNT(DISTINCT)验证 |
| 历史数据完整性 | 无时间重叠区间 | 窗口函数检测时间线连续性 |
| 属性填充率 | 关键字段>99.9% | NULL值比率统计 |
| SCD策略符合性 | 与设计文档100%一致 | 变更日志审计 |
6.2 性能基准测试
# 使用PySpark进行压力测试
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DimensionBenchmark").getOrCreate()
def run_query(query):
start = time.time()
spark.sql(query).count()
return time.time() - start
# 测试不同规模数据下的查询响应时间
for scale in ['1M', '10M', '100M']:
dim_df = spark.read.parquet(f"/data/dim_user_{scale}")
dim_df.createOrReplaceTempView("dim_user")
print(f"{scale}数据查询时间:{run_query('SELECT * FROM dim_user WHERE city="北京"')}s")
七、扩展阅读推荐
- 《维度建模模式》(作者:Ralph Kimball)
- 行业实践白皮书
- 金融行业客户维度设计规范
- 电商商品维度管理最佳实践
- 工具链文档
- dbt维度建模工作流配置指南
- Apache Atlas维度血缘追踪方案
🎯下期预告:《缓慢变化维》
💬互动话题:你在学习SQL时遇到过哪些坑?欢迎评论区留言讨论!
🏷️温馨提示:我是[随缘而动,随遇而安], 一个喜欢用生活案例讲技术的开发者。如果觉得有帮助,点赞关注不迷路🌟


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









