






第二章 操作系统架构
操作系统的一个关键要求是同时支持多个活动。例如,使用第1章中描述的系统调用接口,一个进程可以用fork启动新进程。操作系统必须在这些进程之间分时使用计算机资源。例如,即使进程比硬件处理器多,操作系统也必须确保所有进程都有机会执行。操作系统还必须安排进程之间的隔离。也就是说,如果一个进程有错误和故障,它不应该影响不依赖于有错误的进程的进程。然而,完全隔离又太过头了,进程之间应当可以进行刻意为之的交互;管道就是一个例子。因此,操作系统必须满足三个要求:多路复用、隔离和交互。
本章概述了如何组织操作系统来实现这三个要求。事实证明,有很多方法可以做到这一点,但是本文侧重于以宏内核为中心的主流设计,许多Unix操作系统都使用这种内核。本章还概述了xv6进程(它是xv6中的隔离单元)以及xv6启动时第一个进程的创建。
Xv6运行在多核RISC-V微处理器上,它的许多低级功能(例如,它的进程实现)是特定于RISC-V的。RISC-V是一个64位的中央处理器,xv6是用基于“LP64”的C语言编写的,这意味着C语言中的long(L)和指针(P)变量都是64位的,但int是32位的。这本书假设读者已经在一些架构上做了一些机器级编程,并将在出现时介绍RISC-V特定的想法。RISC-V的一个有用的参考文献是《The RISC-V Reader: An Open Architecture Atlas》。用户级ISA和特权指令架构均是官方规范。
完整计算机中的CPU被支撑硬件包围,其中大部分是以I/O接口的形式。Xv6是以qemu的“-machine virt”选项模拟的支撑硬件编写的。这包括RAM、包含引导代码的ROM、一个到用户键盘/屏幕的串行连接,以及一个用于存储的磁盘。
2.1 抽象系统资源
当谈及操作系统时,人们可能会问的第一个问题是为什么需要它?也就是说,我们可以将图1.2中的系统调用实现为一个库,应用程序可以与之链接。在此方案中,每个应用程序甚至可以根据自己的需求定制自己的库。应用程序可以直接与硬件资源交互,并以应用程序的最佳方式使用这些资源(例如,实现高性能或可预测的性能)。一些嵌入式设备或实时系统的操作系统就是这样组织的。
这种库函数方法的缺点是,如果有多个应用程序在运行,这些应用程序必须表现良好。例如,每个应用程序必须定期放弃中央处理器,以便其他应用程序能够运行。如果所有应用程序都相互信任并且没有错误,这种协同操作的分时方案可能是可以的。 然而更典型的情况是, 应用程序互不信任且存在bug,所以人们通常希望提供比合作方案更强的隔离。
为了实现强隔离, 最好禁止应用程序直接访问敏感的硬件资源,而是将资源抽象为服务。 例如,Unix应用程序只通过文件系统的open、read、write和close系统调用与存储交互,而不是直接读写磁盘。这为应用程序提供了方便实用的路径名,并允许操作系统(作为接口的实现者)管理磁盘。即使隔离不是一个问题,有意交互(或者只是希望互不干扰)的程序可能会发现文件系统比直接使用磁盘更方便。
同样,Unix在进程之间透明地切换硬件处理器,根据需要保存和恢复寄存器状态,这样应用程序就不必意识到分时共享的存在。这种透明性允许操作系统共享处理器,即使有些应用程序处于无限循环中。
另一个例子是,Unix进程使用exec来构建它们的内存映像,而不是直接与物理内存交互。这允许操作系统决定将一个进程放在内存中的哪里;如果内存很紧张,操作系统甚至可以将一个进程的一些数据存储在磁盘上。exec还为用户提供了存储可执行程序映像的文件系统的便利。
Unix进程之间的许多交互形式都是通过文件描述符实现的。文件描述符不仅抽象了许多细节(例如,管道或文件中的数据存储在哪里),而且还以简化交互的方式进行了定义。例如,如果流水线中的一个应用程序失败了,内核会为流水线中的下一个进程生成文件结束信号(EOF)。
2.2 用户态,核心态,以及系统调用
[!NOTE]
用户态=用户模式=目态
核心态=管理模式=管态
强隔离需要应用程序和操作系统之间的硬边界,如果应用程序出错,我们不希望操作系统失败或其他应用程序失败,相反,操作系统应该能够清理失败的应用程序,并继续运行其他应用程序,要实现强隔离,操作系统必须保证应用程序不能修改(甚至读取)操作系统的数据结构和指令,以及应用程序不能访问其他进程的内存。
CPU为强隔离提供硬件支持。例如,RISC-V有三种CPU可以执行指令的模式:机器模式(Machine Mode)、用户模式(User Mode)和管理模式(Supervisor Mode)。在机器模式下执行的指令具有完全特权;CPU在机器模式下启动。机器模式主要用于配置计算机。Xv6在机器模式下执行很少的几行代码,然后更改为管理模式。
在管理模式下,CPU被允许执行特权指令:例如,启用和禁用中断、读取和写入保存页表地址的寄存器等。如果用户模式下的应用程序试图执行特权指令,那么CPU不会执行该指令,而是切换到管理模式,以便管理模式代码可以终止应用程序,因为它做了它不应该做的事情。第1章中的图1.1说明了这种组织。应用程序只能执行用户模式的指令(例如,数字相加等),并被称为在用户空间中运行,而此时处于管理模式下的软件可以执行特权指令,并被称为在内核空间中运行。在内核空间(或管理模式)中运行的软件被称为内核。
想要调用内核函数的应用程序(例如xv6中的read系统调用)必须过渡到内核。CPU提供一个特殊的指令,将CPU从用户模式切换到管理模式,并在内核指定的入口点进入内核(RISC-V为此提供ecall指令)。一旦CPU切换到管理模式,内核就可以验证系统调用的参数,决定是否允许应用程序执行请求的操作,然后拒绝它或执行它。由内核控制转换到管理模式的入口点是很重要的;如果应用程序可以决定内核入口点, 那么恶意应用程序可以在跳过参数验证的地方进入内核。
2.3 内核组织
一个关键的设计问题是操作系统的哪些部分应该以管理模式运行。一种可能是整个操作系统都驻留在内核中,这样所有系统调用的实现都以管理模式运行。这种组织被称为宏内核(monolithic kernel)。
在这种组织中,整个操作系统以完全的硬件特权运行。这个组织很方便,因为操作系统设计者不必考虑操作系统的哪一部分不需要完全的硬件特权。此外,操作系统的不同部分更容易合作。例如,一个操作系统可能有一个可以由文件系统和虚拟内存系统共享的数据缓存区。
宏组织的一个缺点是操作系统不同部分之间的接口通常很复杂(正如我们将在本文的其余部分中看到的),因此操作系统开发人员很容易犯错误。在宏内核中,一个错误就可能是致命的,因为管理模式中的错误经常会导致内核失败。如果内核失败,计算机停止工作,因此所有应用程序也会失败。计算机必须重启才能再次使用。
为了降低内核出错的风险,操作系统设计者可以最大限度地减少在管理模式下运行的操作系统代码量,并在用户模式下执行大部分操作系统。这种内核组织被称为微内核(microkernel)。
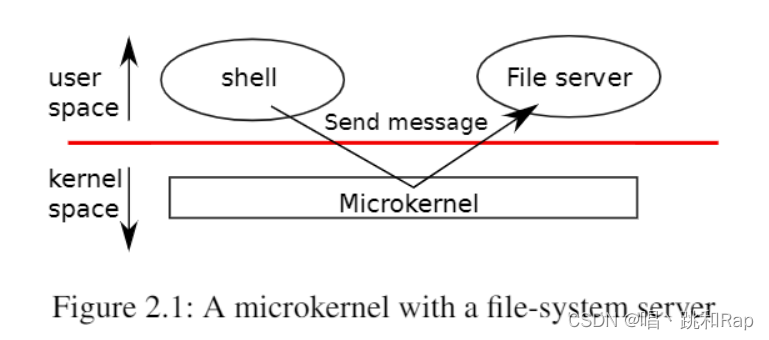
图2.1说明了这种微内核设计。在图中,文件系统作为用户级进程运行。作为进程运行的操作系统服务被称为服务器。为了允许应用程序与文件服务器交互,内核提供了允许从一个用户态进程向另一个用户态进程发送消息的进程间通信机制。例如,如果像shell这样的应用程序想要读取或写入文件,它会向文件服务器发送消息并等待响应。
[!TIP|label:TIPS]
由于客户/服务器(Client/Server)模式,具有非常多的优点,故在单机微内核操作系统中几乎无一例外地都采用客户/服务器模式,将操作系统中最基本的部分放入内核中,而把操作系统的绝大部分功能都放在微内核外面的一组服务器(进程)中实现。
~~
在微内核中,内核接口由一些用于启动应用程序、发送消息、访问设备硬件等的低级功能组成。这种组织允许内核相对简单,因为大多数操作系统驻留在用户级服务器中。
像大多数Unix操作系统一样,Xv6是作为一个宏内核实现的。因此,xv6内核接口对应于操作系统接口,内核实现了完整的操作系统。由于xv6不提供太多服务,它的内核可以比一些微内核还小,但从概念上说xv6属于宏内核。
2.4 代码(XV6架构篇)
XV6的源代码位于kernel/子目录中,源代码按照模块化的概念划分为多个文件,图2.2列出了这些文件,模块间的接口都被定义在了def.h(kernel/defs.h)。
| 文件 | 描述 |
|---|---|
| bio.c | 文件系统的磁盘块缓存 |
| console.c | 连接到用户的键盘和屏幕 |
| entry.S | 首次启动指令 |
| exec.c | exec()系统调用 |
| file.c | 文件描述符支持 |
| fs.c | 文件系统 |
| kalloc.c | 物理页面分配器 |
| kernelvec.S | 处理来自内核的陷入指令以及计时器中断 |
| log.c | 文件系统日志记录以及崩溃修复 |
| main.c | 在启动过程中控制其他模块初始化 |
| pipe.c | 管道 |
| plic.c | RISC-V中断控制器 |
| printf.c | 格式化输出到控制台 |
| proc.c | 进程和调度 |
| sleeplock.c | Locks that yield the CPU |
| spinlock.c | Locks that don’t yield the CPU. |
| start.c | 早期机器模式启动代码 |
| string.c | 字符串和字节数组库 |
| swtch.c | 线程切换 |
| syscall.c | Dispatch system calls to handling function. |
| sysfile.c | 文件相关的系统调用 |
| sysproc.c | 进程相关的系统调用 |
| trampoline.S | 用于在用户和内核之间切换的汇编代码 |
| trap.c | 对陷入指令和中断进行处理并返回的C代码 |
| uart.c | 串口控制台设备驱动程序 |
| virtio_disk.c | 磁盘设备驱动程序 |
| vm.c | 管理页表和地址空间 |
2.5 进程概述
Xv6(和其他Unix操作系统一样)中的隔离单位是一个进程。进程抽象防止一个进程破坏或监视另一个进程的内存、CPU、文件描述符等。它还防止一个进程破坏内核本身,这样一个进程就不能破坏内核的隔离机制。内核必须小心地实现进程抽象,因为一个有缺陷或恶意的应用程序可能会欺骗内核或硬件做坏事(例如,绕过隔离)。内核用来实现进程的机制包括用户/管理模式标志、地址空间和线程的时间切片。
为了帮助加强隔离,进程抽象给程序提供了一种错觉,即它有自己的专用机器。进程为程序提供了一个看起来像是私有内存系统或地址空间的东西,其他进程不能读取或写入。进程还为程序提供了看起来像是自己的CPU来执行程序的指令。
Xv6使用页表(由硬件实现)为每个进程提供自己的地址空间。RISC-V页表将虚拟地址(RISC-V指令操纵的地址)转换(或“映射”)为物理地址(CPU芯片发送到主存储器的地址)。
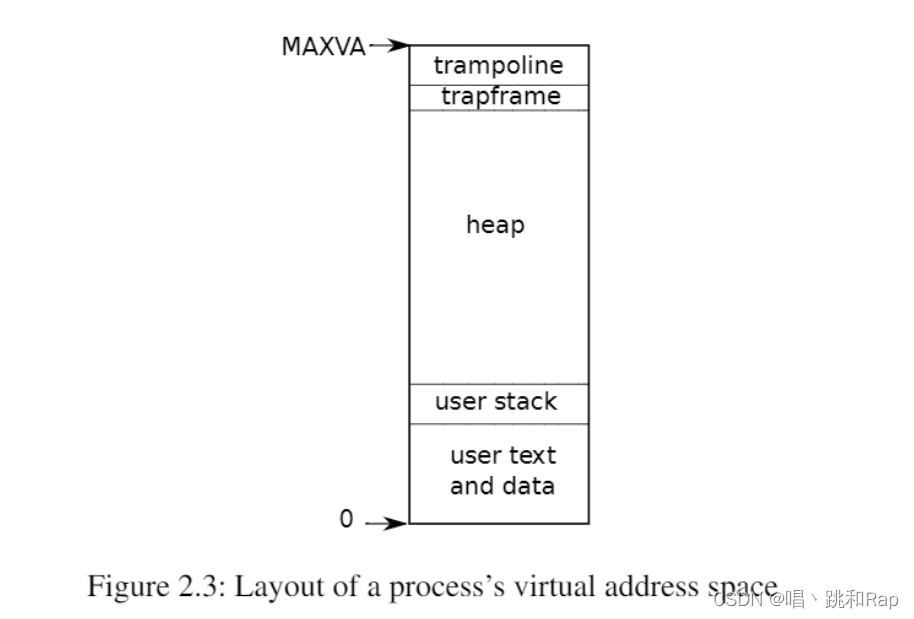
Xv6为每个进程维护一个单独的页表,定义了该进程的地址空间。如图2.3所示,以虚拟内存地址0开始的进程的用户内存地址空间。首先是指令,然后是全局变量,然后是栈区,最后是一个堆区域(用于malloc)以供进程根据需要进行扩展。有许多因素限制了进程地址空间的最大范围: RISC-V上的指针有64位宽;硬件在页表中查找虚拟地址时只使用低39位;xv6只使用这39位中的38位。因此,最大地址是2^38-1=0x3fffffffff,即MAXVA(定义在kernel/riscv.h:348)。在地址空间的顶部,xv6为trampoline(用于在用户和内核之间切换)和映射进程切换到内核的trapframe分别保留了一个页面,正如我们将在第4章中解释的那样。
xv6内核为每个进程维护许多状态片段,并将它们聚集到一个proc(kernel/proc.h:86)结构体中。一个进程最重要的内核状态片段是它的页表、内核栈区和运行状态。我们将使用符号p->xxx来引用proc结构体的元素;例如,p->pagetable是一个指向该进程页表的指针。
每个进程都有一个执行线程(或简称线程)来执行进程的指令。一个线程可以挂起并且稍后再恢复。为了透明地在进程之间切换,内核挂起当前运行的线程,并恢复另一个进程的线程。线程的大部分状态(本地变量、函数调用返回地址)存储在线程的栈区上。每个进程有两个栈区:一个用户栈区和一个内核栈区(p->kstack)。当进程执行用户指令时,只有它的用户栈在使用,它的内核栈是空的。当进程进入内核(由于系统调用或中断)时,内核代码在进程的内核堆栈上执行;当一个进程在内核中时,它的用户堆栈仍然包含保存的数据,只是不处于活动状态。进程的线程在主动使用它的用户栈和内核栈之间交替。内核栈是独立的(并且不受用户代码的保护),因此即使一个进程破坏了它的用户栈,内核依然可以正常运行。
一个进程可以通过执行RISC-V的ecall指令进行系统调用,该指令提升硬件特权级别,并将程序计数器(PC)更改为内核定义的入口点,入口点的代码切换到内核栈,执行实现系统调用的内核指令,当系统调用完成时,内核切换回用户栈,并通过调用sret指令返回用户空间,该指令降低了硬件特权级别,并在系统调用指令刚结束时恢复执行用户指令。进程的线程可以在内核中“阻塞”等待I/O,并在I/O完成后恢复到中断的位置。
p->state表明进程是已分配、就绪态、运行态、等待I/O中(阻塞态)还是退出。
p->pagetable以RISC-V硬件所期望的格式保存进程的页表。当在用户空间执行进程时,Xv6让分页硬件使用进程的p->pagetable。一个进程的页表也可以作为已分配给该进程用于存储进程内存的物理页面地址的记录。
2.6 代码(启动XV6和第一个进程)
为了使xv6更加具体,我们将概述内核如何启动和运行第一个进程。接下来的章节将更详细地描述本概述中显示的机制。
当RISC-V计算机上电时,它会初始化自己并运行一个存储在只读内存中的引导加载程序。引导加载程序将xv6内核加载到内存中。然后,在机器模式下,中央处理器从_entry (kernel/entry.S:6)开始运行xv6。Xv6启动时页式硬件(paging hardware)处于禁用模式:也就是说虚拟地址将直接映射到物理地址。
//ENTRY.c
# qemu -kernel loads the kernel at 0x80000000
# and causes each CPU to jump there.
# kernel.ld causes the following code to
# be placed at 0x80000000.
.section .text
_entry:
# set up a stack for C.
# stack0 is declared in start.c,
# with a 4096-byte stack per CPU.
# sp = stack0 + (hartid * 4096)
la sp, stack0
li a0, 1024*4
csrr a1, mhartid
addi a1, a1, 1
mul a0, a0, a1
add sp, sp, a0
# jump to start() in start.c
call start
spin:
j spin
加载程序将xv6内核加载到物理地址为0x80000000的内存中。它将内核放在0x80000000而不是0x0的原因是地址范围0x0:0x80000000包含I/O设备。
//START.c
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "riscv.h"
#include "defs.h"
void main();
void timerinit();
// entry.S needs one stack per CPU.
__attribute__ ((aligned (16))) char stack0[4096 * NCPU];
// scratch area for timer interrupt, one per CPU.
uint64 mscratch0[NCPU * 32];
// assembly code in kernelvec.S for machine-mode timer interrupt.
extern void timervec();
// entry.S jumps here in machine mode on stack0.
void
start()
{
// set M Previous Privilege mode to Supervisor, for mret.
unsigned long x = r_mstatus();
x &= ~MSTATUS_MPP_MASK;
x |= MSTATUS_MPP_S;
w_mstatus(x);
// set M Exception Program Counter to main, for mret.
// requires gcc -mcmodel=medany
w_mepc((uint64)main);
// disable paging for now.
w_satp(0);
// delegate all interrupts and exceptions to supervisor mode.
w_medeleg(0xffff);
w_mideleg(0xffff);
w_sie(r_sie() | SIE_SEIE | SIE_STIE | SIE_SSIE);
// ask for clock interrupts.
timerinit();
// keep each CPU's hartid in its tp register, for cpuid().
int id = r_mhartid();
w_tp(id);
// switch to supervisor mode and jump to main().
asm volatile("mret");
}
// set up to receive timer interrupts in machine mode,
// which arrive at timervec in kernelvec.S,
// which turns them into software interrupts for
// devintr() in trap.c.
void
timerinit()
{
// each CPU has a separate source of timer interrupts.
int id = r_mhartid();
// ask the CLINT for a timer interrupt.
int interval = 1000000; // cycles; about 1/10th second in qemu.
*(uint64*)CLINT_MTIMECMP(id) = *(uint64*)CLINT_MTIME + interval;
// prepare information in scratch[] for timervec.
// scratch[0..3] : space for timervec to save registers.
// scratch[4] : address of CLINT MTIMECMP register.
// scratch[5] : desired interval (in cycles) between timer interrupts.
uint64 *scratch = &mscratch0[32 * id];
scratch[4] = CLINT_MTIMECMP(id);
scratch[5] = interval;
w_mscratch((uint64)scratch);
// set the machine-mode trap handler.
w_mtvec((uint64)timervec);
// enable machine-mode interrupts.
w_mstatus(r_mstatus() | MSTATUS_MIE);
// enable machine-mode timer interrupts.
w_mie(r_mie() | MIE_MTIE);
}
_entry的指令设置了一个栈区,这样xv6就可以运行C代码。Xv6在start. c (kernel/start.c:11)文件中为初始栈stack0声明了空间。由于RISC-V上的栈是向下扩展的,所以_entry的代码将栈顶地址stack0+4096加载到栈顶指针寄存器sp中。现在内核有了栈区,_entry便调用C代码start(kernel/start.c:21)。
函数start执行一些仅在机器模式下允许的配置,然后切换到管理模式。RISC-V提供指令mret以进入管理模式,该指令最常用于将管理模式切换到机器模式的调用中返回。而start并非从这样的调用返回,而是执行以下操作:它在寄存器mstatus中将先前的运行模式改为管理模式,它通过将main函数的地址写入寄存器mepc将返回地址设为main,它通过向页表寄存器satp写入0来在管理模式下禁用虚拟地址转换,并将所有的中断和异常委托给管理模式。
在进入管理模式之前,start还要执行另一项任务:对时钟芯片进行编程以产生计时器中断。清理完这些“家务”后,start通过调用mret“返回”到管理模式。这将导致程序计数器(PC)的值更改为main(kernel/main.c:11)函数地址。
[!TIP|label:TIPS]
注:mret执行返回,返回到先前状态,由于start函数将前模式改为了管理模式且返回地址改为了main,因此mret将返回到main函数,并以管理模式运行
在main(kernel/main.c:11)初始化几个设备和子系统后,便通过调用userinit (kernel/proc.c:212)创建第一个进程,第一个进程执行一个用RISC-V程序集写的小型程序:initcode. S (***user/initcode.S:***1),它通过调用exec系统调用重新进入内核。正如我们在第1章中看到的,exec用一个新程序(本例中为 /init)替换当前进程的内存和寄存器。一旦内核完成exec,它就返回/init进程中的用户空间。如果需要,init(user/init.c:15)将创建一个新的控制台设备文件,然后以文件描述符0、1和2打开它。然后它在控制台上启动一个shell。系统就这样启动了。
2.7 Real World
在现实中,人们可以同时看到宏内核和微内核。许多Unix都采用宏内核。例如,尽管Linux的一些操作系统功能作为用户级服务器运行(例如窗口系统),但它是宏内核架构。而如L4、Minix和QNX的内核都被组织成一个带有多个服务器的微内核,微内核在嵌入式设备中得到了广泛的应用。
大多数操作系统都采用了进程的概念,并且大多数操作系统的进程看起来与xv6相似。然而,现代操作系统支持在一个进程中创建多个线程,使得一个进程能够利用多个处理器。在一个进程中支持多个线程涉及许多XV6缺乏的机制,包括潜在的接口更改(例如,Linux下fork的变体clone),以控制进程线程共享哪些内容。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









