






1.极客时间(通俗):数据结构与算法之美_算法实战_算法面试-极客时间
知识架构:
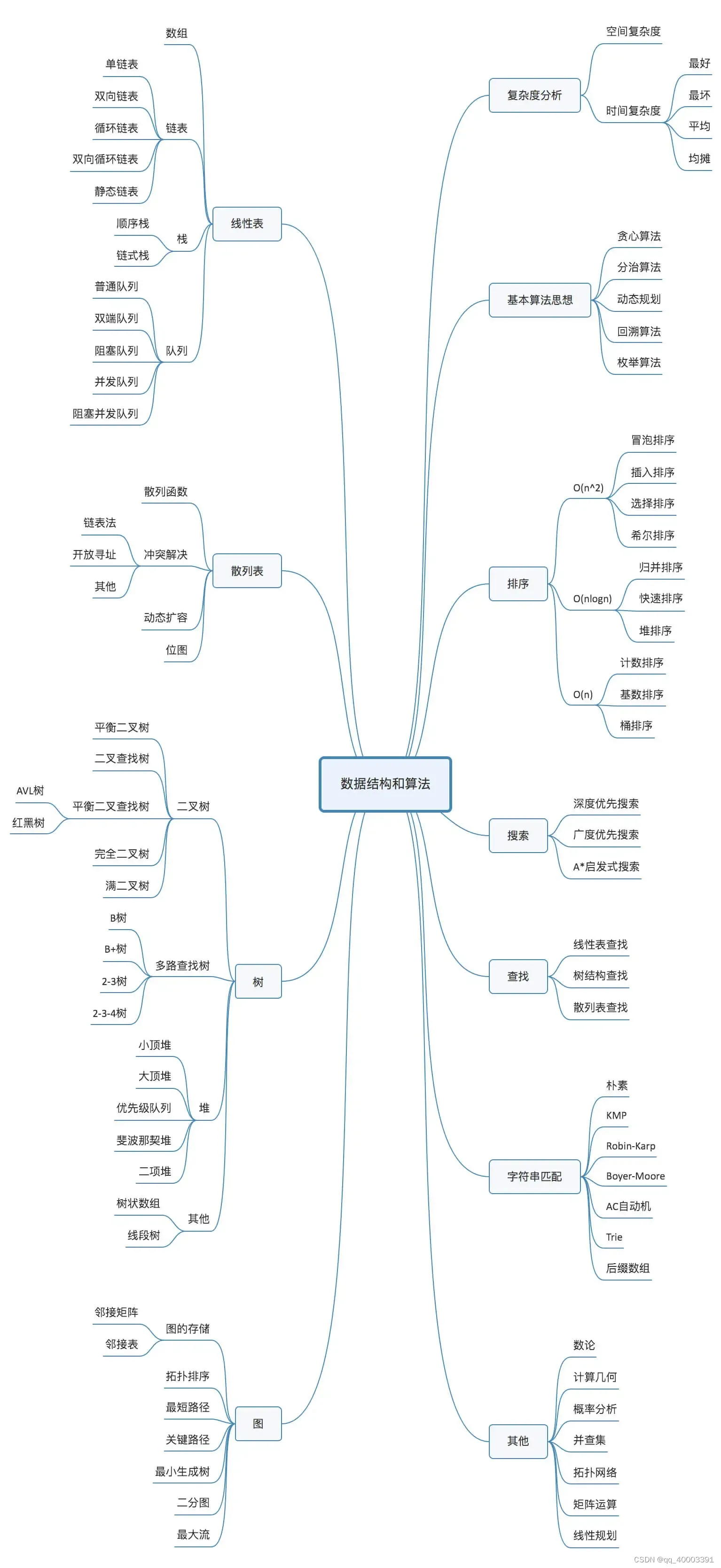
第01章 复杂度分析:
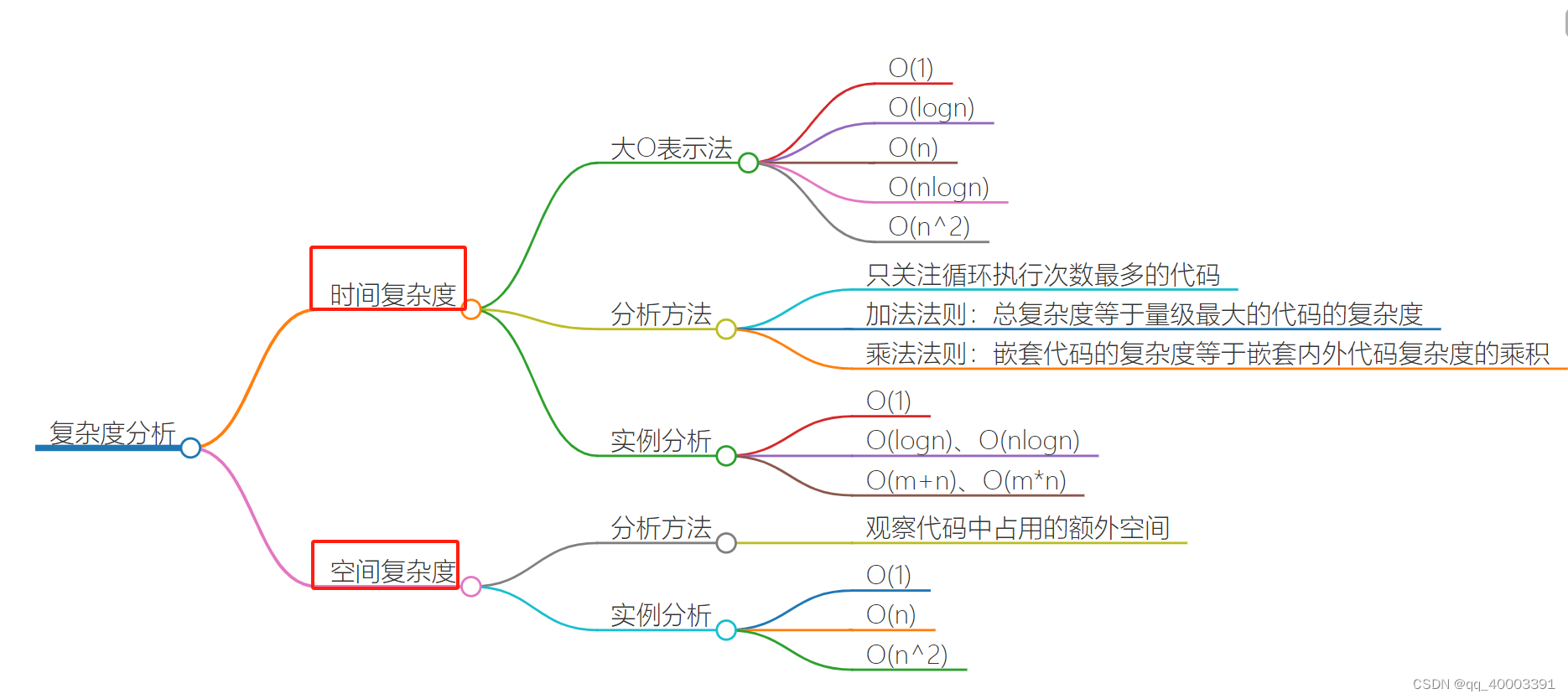
最坏情况下的时间复杂度W(n)
平均情况下的时间复杂度A(n)

第02章 数据结构:
1.数组

问题1:为什么大多数编程语言中,数组要从 0 开始编号,而不是从 1 开始呢?
寻址公式:a[i]_address = base_address + i * data_type_size
为了减少一次减法操作,数组选择了从0开始编号
问题2:JVM标记清除算法:
大多数主流虚拟机采用可达性分析算法来判断对象是否存活,在标记阶段,会遍历所有 GC ROOTS,将所有 GC ROOTS 可达的对象标记为存活。只有当标记工作完成后,清理工作才会开始。
不足:1.效率问题。标记和清理效率都不高,但是当知道只有少量垃圾产生时会很高效。
2.空间问题。会产生不连续的内存空间碎片。
问题3:二维数组内存寻址:
对于 m * n 的数组,a [ i ][ j ] (i < m,j < n)的地址为:
address = base_address + ( i * n + j) * type_size
2.链表(*)

缓存淘汰策略常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
实践:

比如:链表反转、有序链表合并等
技巧一:理解指针或引用的含义
将某个变量赋值给指针,实际上就是将这个变量的地址赋值给指针。
或者反过来说,
指针中存储了这个变量的内存地址,指向了这个变量,通过指针就能找到这个变量。
p->next=q。这行代码是说,p 结点中的 next 指针存储了 q 结点的内存地址。
p->next=p->next->next。这行代码表示,p 结点的 next 指针存储了 p 结点的下下一个结点的内存地址。
技巧二:警惕指针丢失和内存泄漏

如图所示,我们希望在结点 a 和相邻的结点 b 之间插入结点 x,假设当前指针 p 指向结点 a。
如果我们将代码实现变成下面这个样子,就会发生指针丢失和内存泄露。
p->next = x; // 将p的next指针指向x结点;
x->next = p->next; // 将x的结点的next指针指向b结点;初学者经常会在这儿犯错。
p->next 指针在完成第一步操作之后,已经不再指向结点 b 了,而是指向结点 x。第 2 行代码相当于将 x 赋值给 x->next,自己指向自己。因此,整个链表也就断成了两半,从结点 b 往后的所有结点都无法访问到了。
所以,我们插入结点时,一定要注意操作的顺序,要先将结点 x 的 next 指针指向结点 b,再把结点 a 的 next 指针指向结点 x,这样才不会丢失指针,导致内存泄漏。所以,对于刚刚的插入代码,我们只需要把第 1 行和第 2 行代码的顺序颠倒一下就可以了。
技巧三:利用哨兵简化实现难度
针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。
如果我们引入哨兵结点,在任何时候,不管链表是不是空,head 指针都会一直指向这个哨兵结点。我们也把这种有哨兵结点的链表叫带头链表。相反,没有哨兵结点的链表就叫作不带头链表。

技巧四:重点留意边界条件处理
我经常用来检查链表代码是否正确的边界条件有这样几个:
- 如果链表为空时,代码是否能正常工作?
- 如果链表只包含一个结点时,代码是否能正常工作?
- 如果链表只包含两个结点时,代码是否能正常工作?
- 代码逻辑在处理头结点和尾结点的时候,是否能正常工作?
技巧五:举例画图,辅助思考
比如往单链表中插入一个数据这样一个操作,我一般都是把各种情况都举一个例子,画出插入前和插入后的链表变化,如图所示:

技巧六:多写多练,没有捷径
精选案例:
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 求链表的中间结点
3.栈:

函数调用栈:操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量
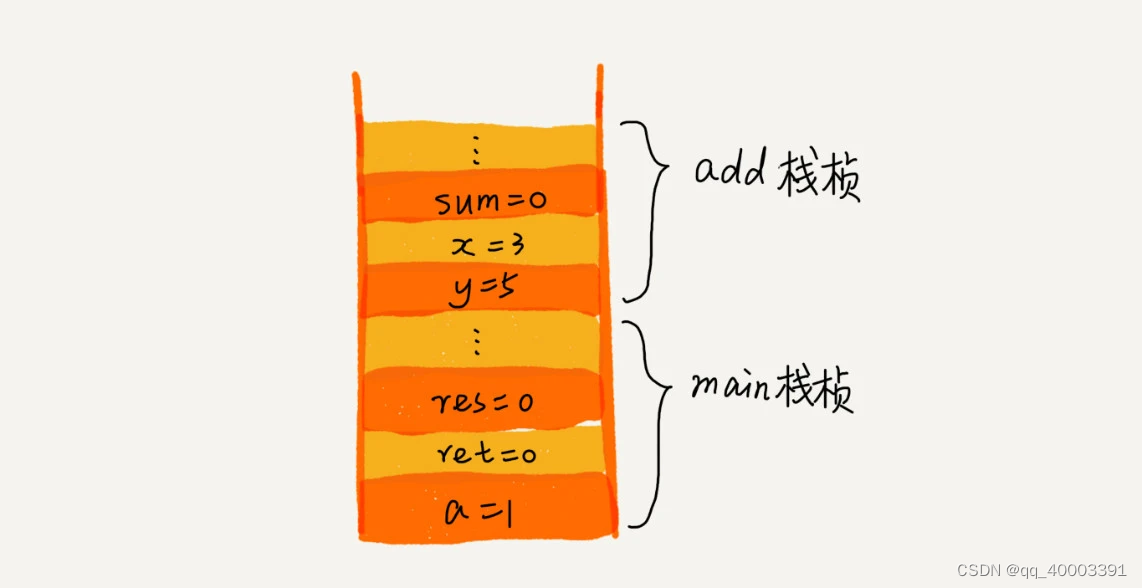
表达式求值:

4.队列:

顺序队列和链式队列
循环队列
阻塞队列和并发队列
5.跳表
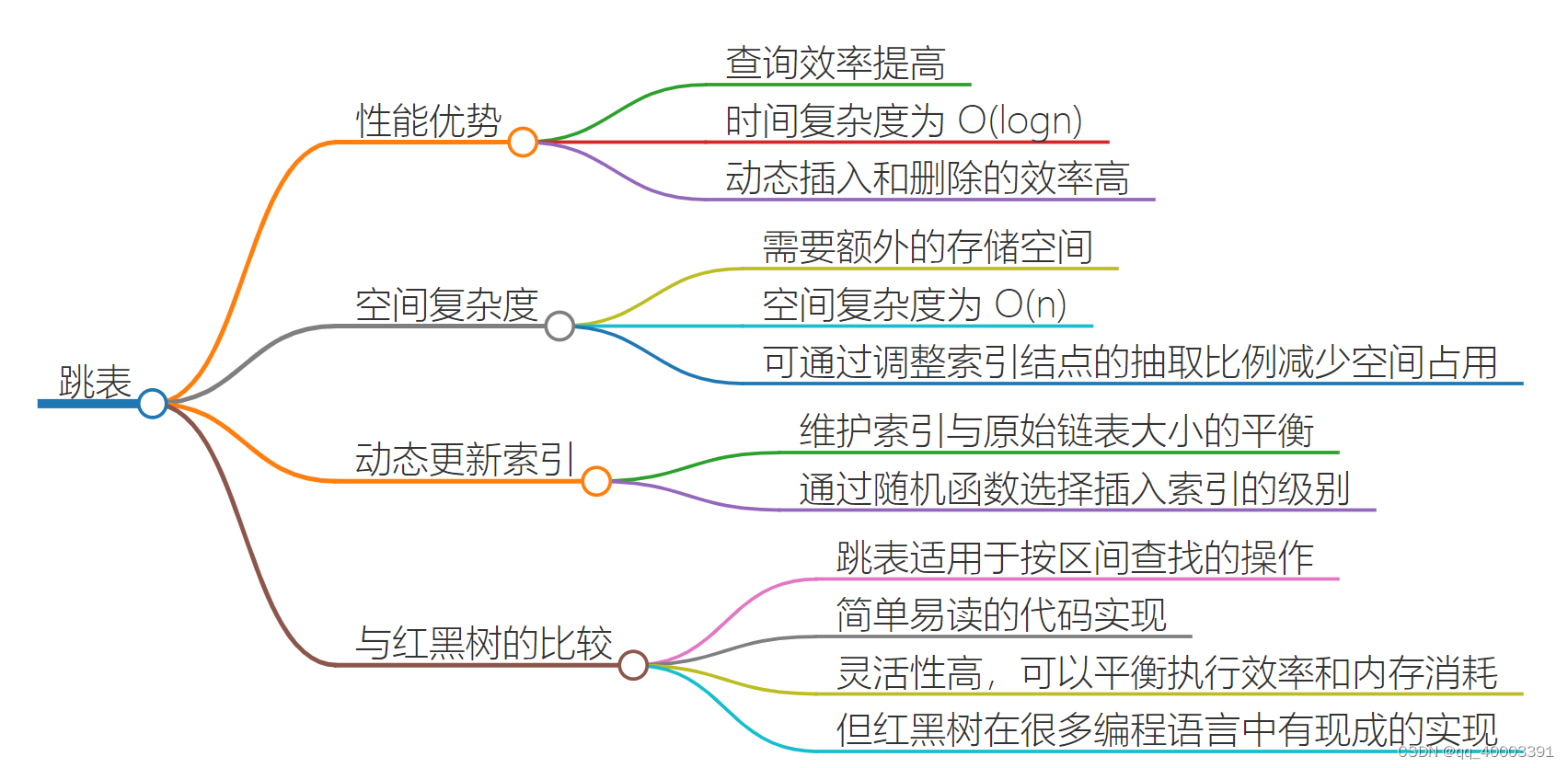
定义:这种链表加多级索引的结构,就是跳表。

6.散列表(*)
6.1原理

散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。
可以说,如果没有数组,就没有散列表。

散列函数:hash(key)
- 散列函数计算得到的散列值是一个非负整数;
- 如果 key1 = key2,那 hash(key1) == hash(key2);
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
散列冲突
1. 开放寻址法:二次探测(Quadratic probing)和双重散列(Double hashing)
装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。
2.链表法(*)

6.2:设计:

散列函数:
散列函数的设计不能太复杂,散列函数生成的值要尽可能随机并且均匀分布
如何选择冲突解决方法?
我总结一下,当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
我总结一下,基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,链表法它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
6.3应用
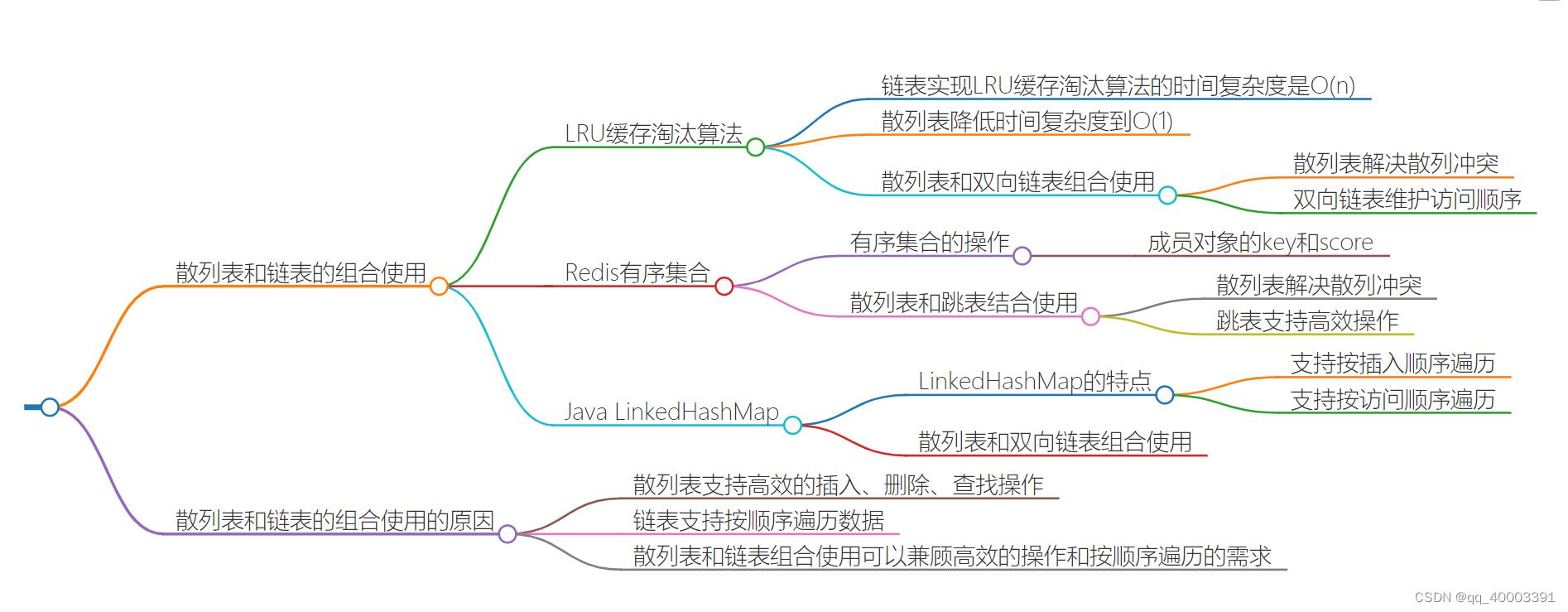
散列表和链表组合使用(*)
LRU 缓存淘汰算法

双向链表存储数据,链表中的每个结点处理存储数据(data)、前驱指针(prev)、后继指针(next)之外,还新增了一个特殊的字段 hnext。这个 hnext 有什么作用呢?
前驱和后继指针是为了将结点串在双向链表中,hnext 指针是为了将结点串在散列表的拉链中。
Redis 有序集合
key(键值)和 score(分值)
如果我们仅仅按照分值将成员对象组织成跳表的结构,那按照键值来删除、查询成员对象就会很慢,解决方法与 LRU 缓存淘汰算法的解决方法类似。我们可以再按照键值构建一个散列表,这样按照 key 来删除、查找一个成员对象的时间复杂度就变成了 O(1)。同时,借助跳表结构,其他操作也非常高效。
实际上,Redis 有序集合的操作还有另外一类,也就是查找成员对象的排名(Rank)或者根据排名区间查找成员对象。这个功能单纯用刚刚讲的这种组合结构就无法高效实现了。这块内容我后面的章节再讲。
LinkedHashMap(Java )
LinkedHashMap 是通过双向链表和散列表这两种数据结构组合实现的。LinkedHashMap 中的“Linked”实际上是指的是双向链表,并非指用链表法解决散列冲突。
其他资料参考:
总结一下,
为什么散列表和链表经常一块使用?
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那我们需要将散列表中的数据拷贝到数组中,然后排序,再遍历。因为散列表是动态数据结构,不停地有数据的插入、删除,所以每当我们希望按顺序遍历散列表中的数据的时候,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
7.树:

7.1树:
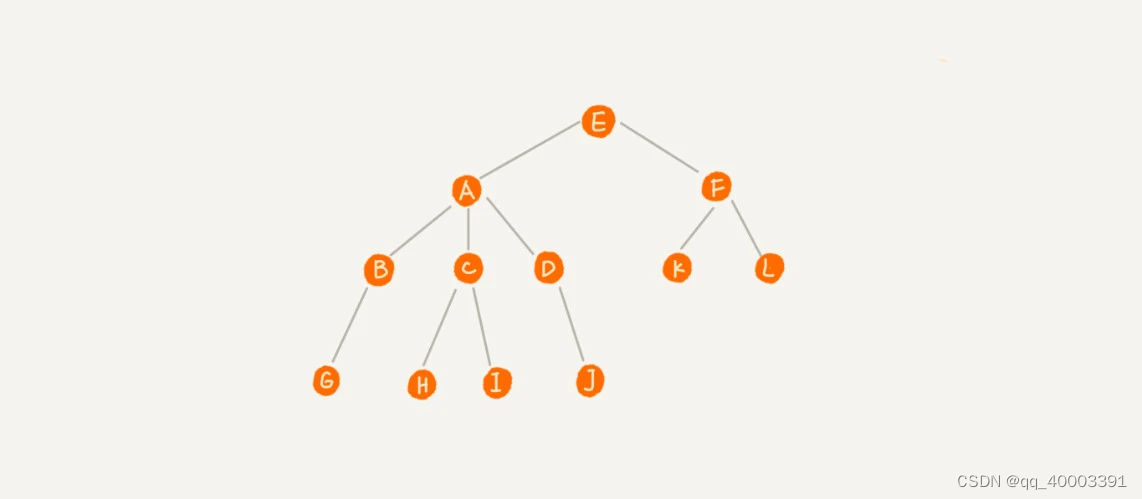
A 节点就是 B 节点的父节点,B 节点是 A 节点的子节点。B、C、D 这三个节点的父节点是同一个节点,所以它们之间互称为兄弟节点。我们把没有父节点的节点叫做根节点,也就是图中的节点 E。我们把没有子节点的节点叫做叶子节点或者叶节点,比如图中的 G、H、I、J、K、L 都是叶子节点。

7.2 二叉树(Binary Tree)
左子节点和右子节点

编号 2 的二叉树中,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树。
编号 3 的二叉树中,叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树。
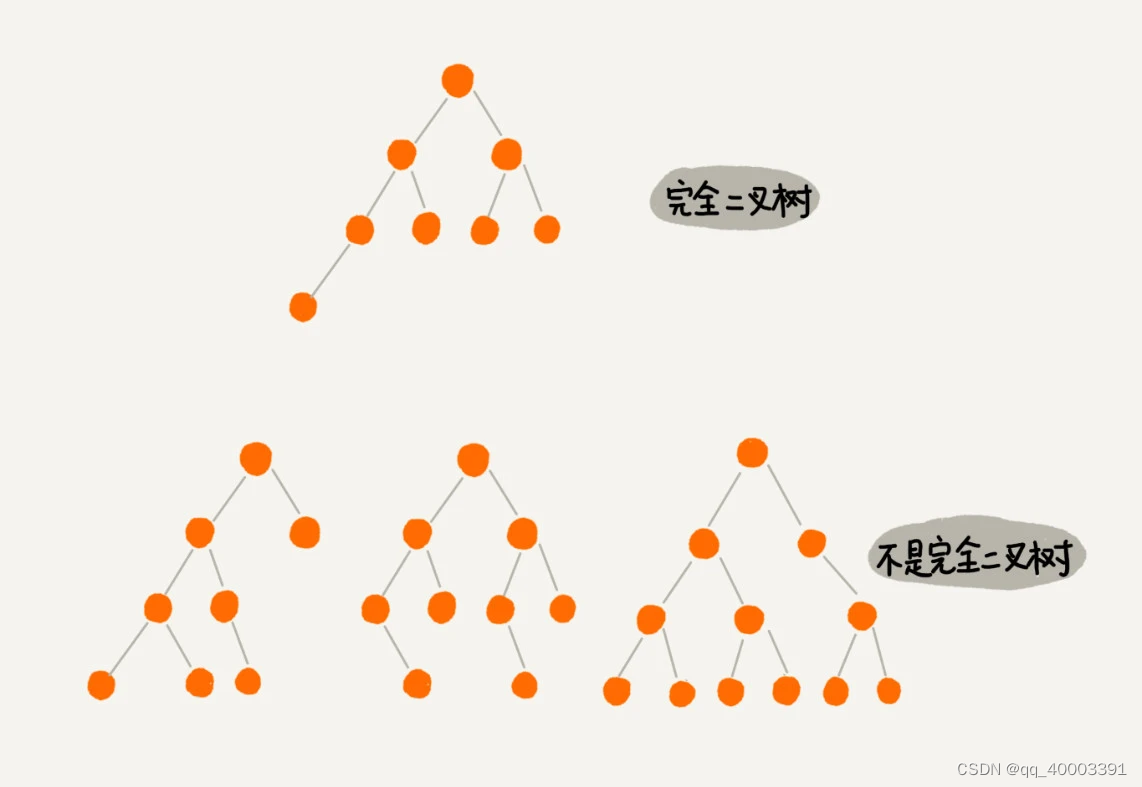
完全二叉树存储存储:

如果节点 X 存储在数组中下标为 i 的位置,下标为 2 * i 的位置存储的就是左子节点,下标为 2 * i + 1 的位置存储的就是右子节点。反过来,下标为 i/2 的位置存储就是它的父节点。通过这种方式,我们只要知道根节点存储的位置(一般情况下,为了方便计算子节点,根节点会存储在下标为 1 的位置),这样就可以通过下标计算,把整棵树都串起来。
二叉树的遍历
前序遍历、中序遍历和后序遍历
根节点相对于左右节点:前序遍历、中序遍历和后序遍历

- 前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
- 中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
- 后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身。
实际上,二叉树的前、中、后序遍历就是一个递归的过程。
课后思考
给定一组数据,比如 1,3,5,6,9,10。你来算算,可以构建出多少种不同的二叉树?
我们讲了三种二叉树的遍历方式,前、中、后序。实际上,还有另外一种遍历方式,也就是按层遍历,你知道如何实现吗?
1、既然是数组了,说明是完全二叉树,应该有n的阶乘个组合。
2、二叉树按层遍历,可以看作以根结点为起点,图的广度优先遍历的问题。
7.3 二叉查找树(Binary Search Tree)
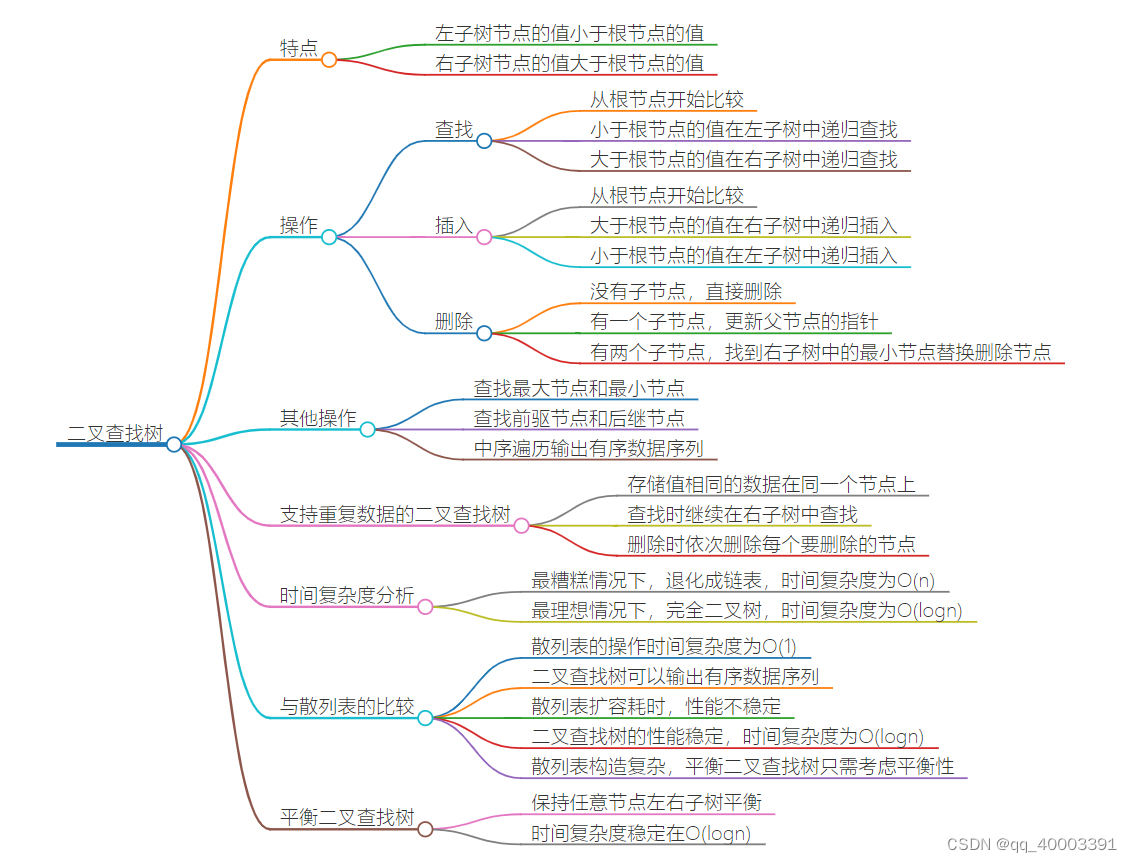
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。

中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度是 O(n),非常高效。
插入、删除还是查找,时间复杂度其实都跟树的高度成正比,也就是 O(height)
散列表的插入、删除、查找操作的时间复杂度可以做到常量级的 O(1),非常高效。而二叉查找树在比较平衡的情况下,插入、删除、查找操作时间复杂度才是 O(logn),相对散列表,好像并没有什么优势,那我们为什么还要用二叉查找树呢?
11
第一,散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在 O(n) 的时间复杂度内,输出有序的数据序列。
第二,散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在 O(logn)。
第三,笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比 logn 小,所以实际的查找速度可能不一定比 O(logn) 快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高。
第四,散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
综合这几点,平衡二叉查找树在某些方面还是优于散列表的,所以,这两者的存在并不冲突。我们在实际的开发过程中,需要结合具体的需求来选择使用哪一个。
7.4红黑树

平衡二叉查找树:
平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。

7.5 递归树

借助递归树来分析递归算法的时间复杂度
递归树其他参考视频:02-06 递归树_哔哩哔哩_bilibili
8.图

8.1图的概念:
图(Graph)。和树比起来,这是一种更加复杂的非线性表结构。(多对多)

图中的元素我们就叫做顶点(vertex),顶点建立连接关系叫做边(edge),跟顶点相连接的边的条数顶点的度(degree),边有方向的图叫做“有向图”,边没有方向的图就叫做“无向图”,带权图。
8.2存储方法
8.2.1邻接矩阵存储方法

稀疏图(Sparse Matrix),也就是说,顶点很多,但每个顶点的边并不多,那邻接矩阵的存储方法就更加浪费空间了
8.2.2邻接表存储方法

邻接矩阵存储方法的缺点是比较浪费空间,但是优点是查询效率高,而且方便矩阵运算。邻接表存储方法中每个顶点都对应一个链表,存储与其相连接的其他顶点。尽管邻接表的存储方式比较节省存储空间,但链表不方便查找,所以查询效率没有邻接矩阵存储方式高。针对这个问题,邻接表还有改进升级版,即将链表换成更加高效的动态数据结构,比如平衡二叉查找树、跳表、散列表等。
8.3图的遍历
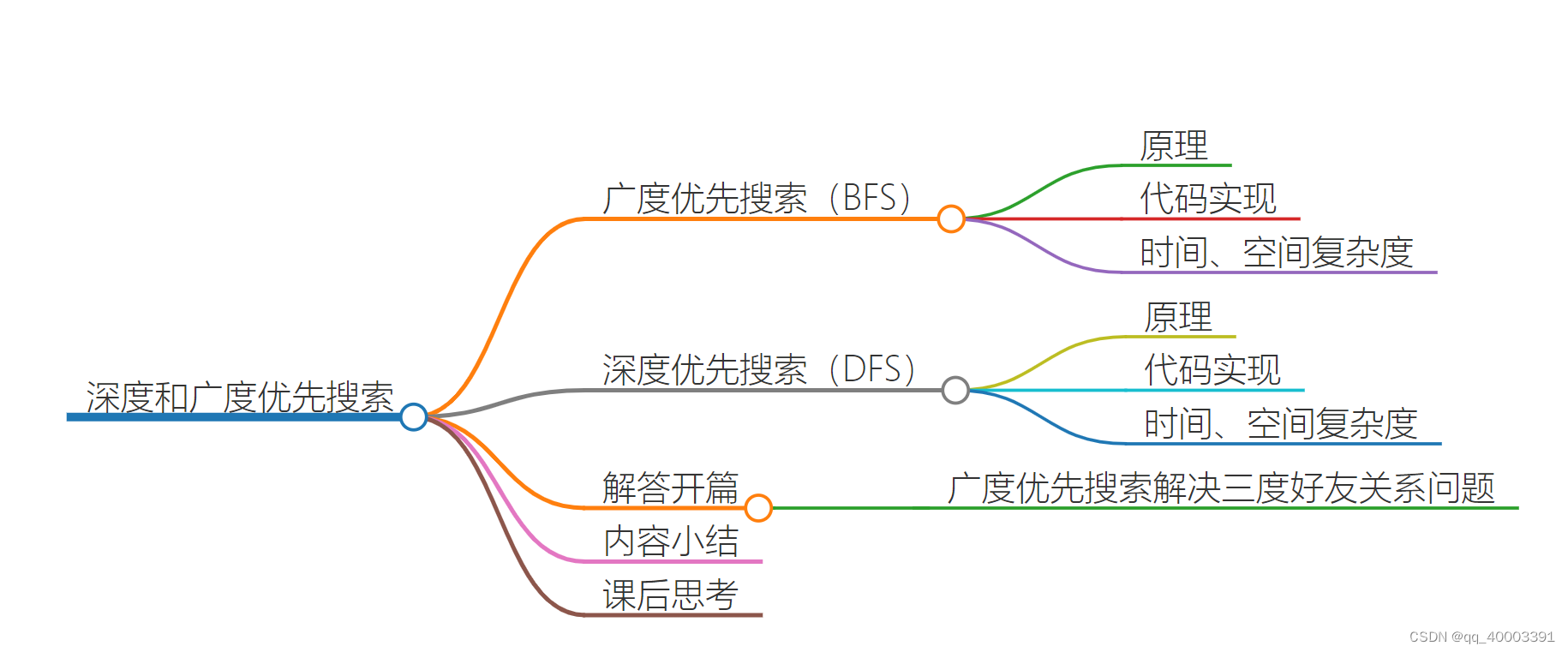
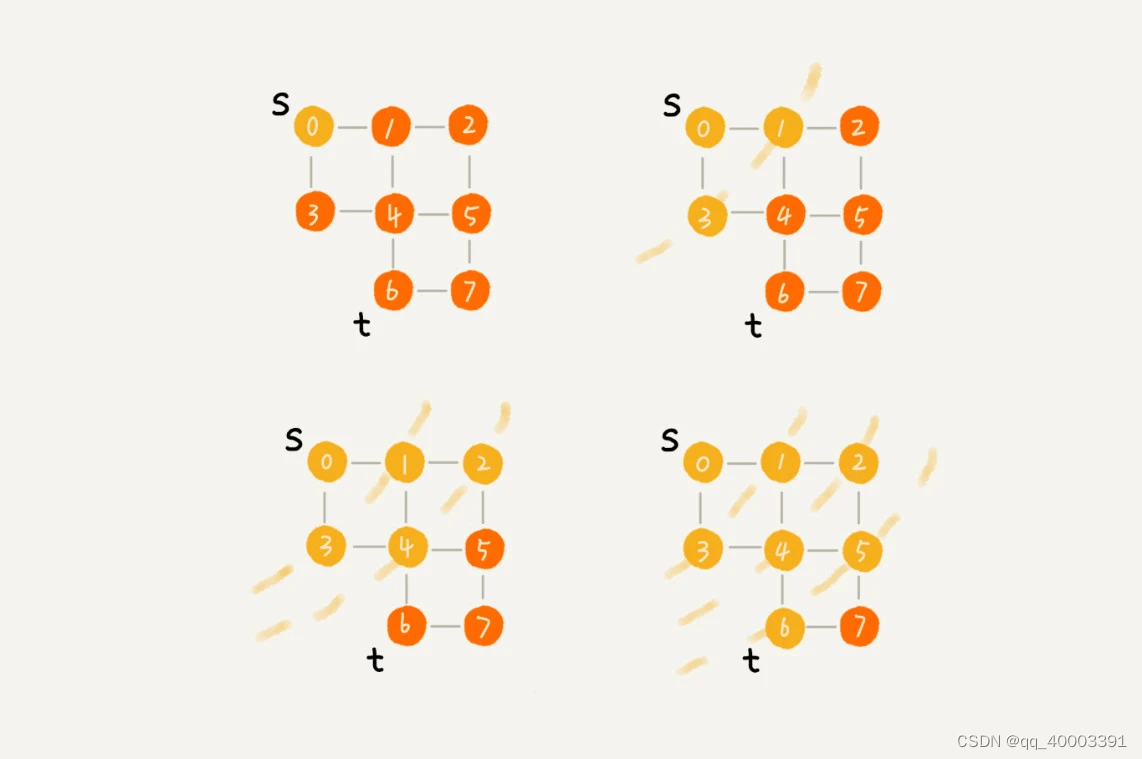
8.3.1广度优先搜索(BFS)
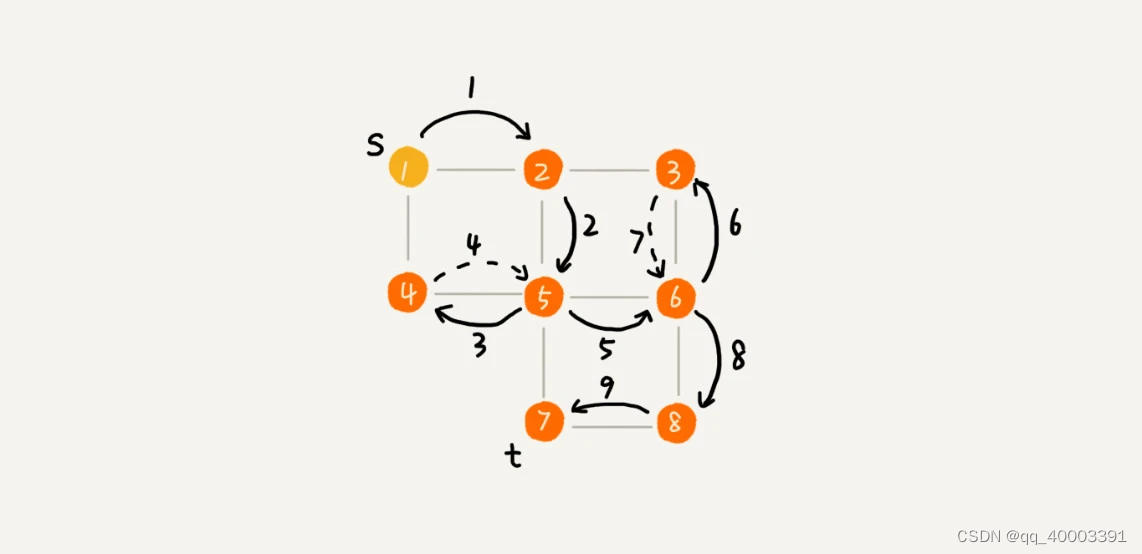
8.3.2深度优先搜索(DFS)
第03章 算法分析:
1.排序问题:

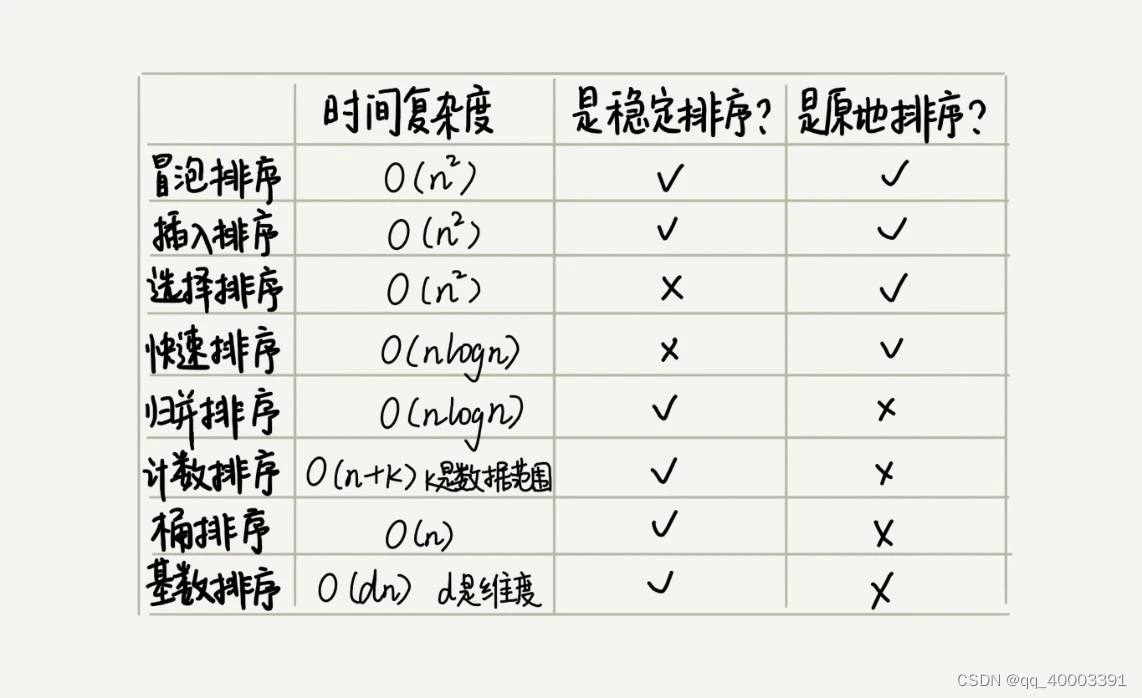
最常用的:冒泡排序、插入排序、选择排序、归并排序、快速排序、计数排序、基数排序、桶排序。
冒泡排序(Bubble Sort)
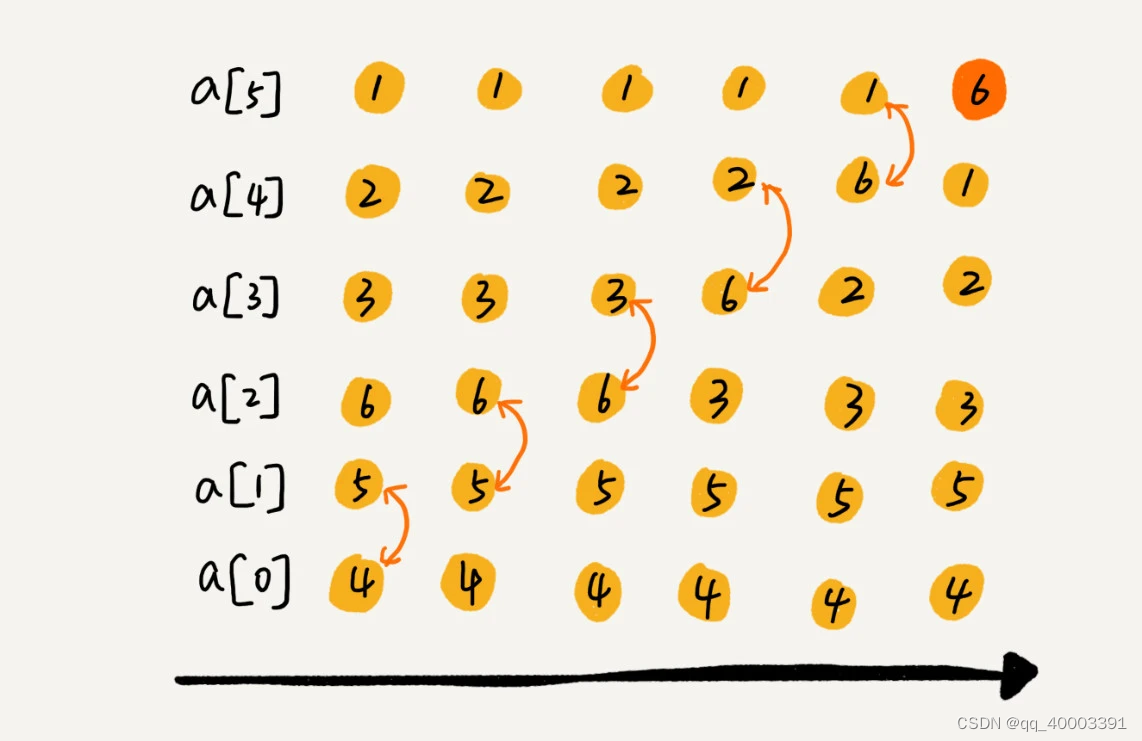
插入排序(Insertion Sort)

选择排序(Selection Sort)

小结1: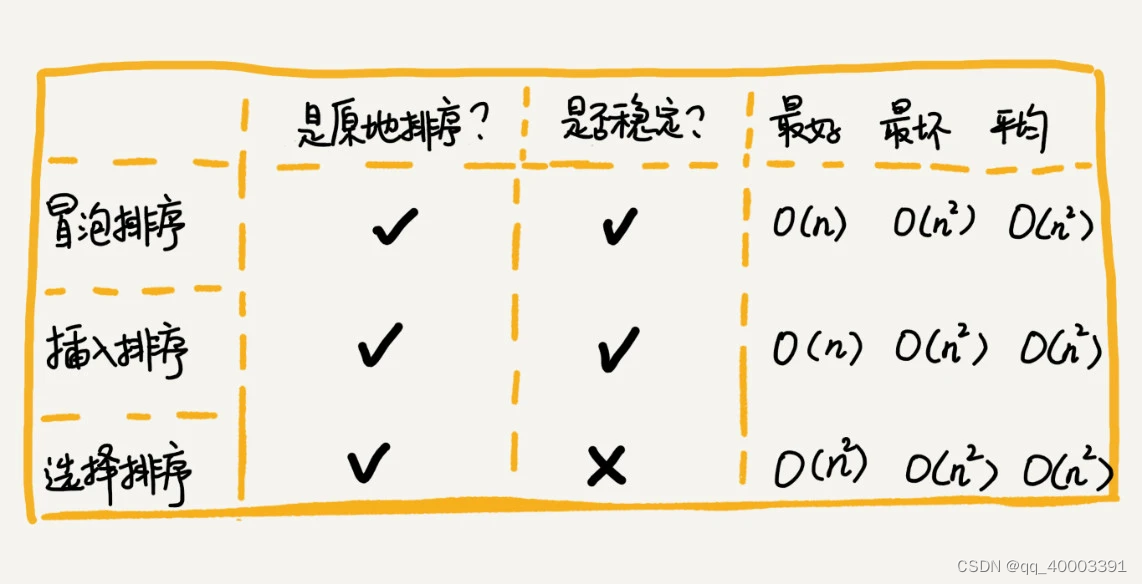
原地排序算法,就是特指空间复杂度是 O(1) 的排序算法
稳定性:如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变
归并排序(Merge Sort)
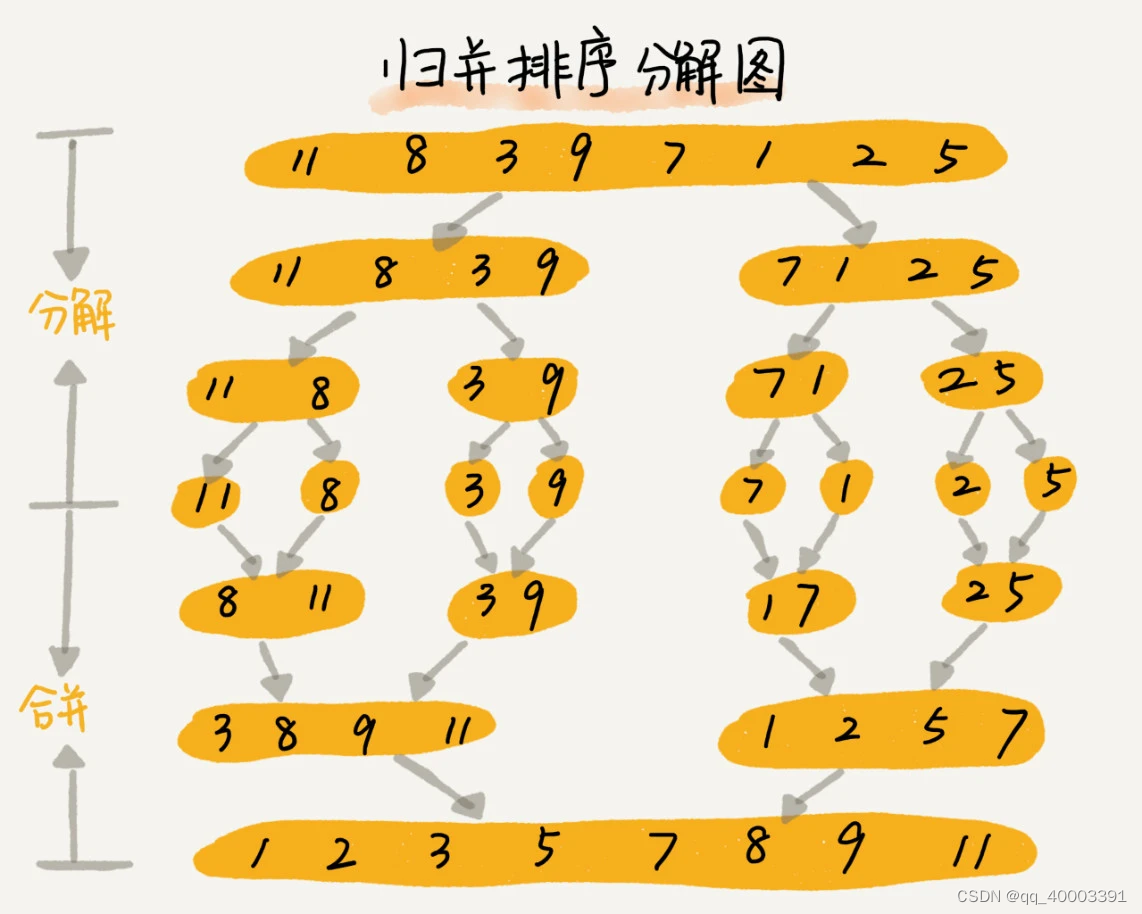
分治是一种解决问题的处理思想,递归是一种编程技巧
快速排序(Quicksort)
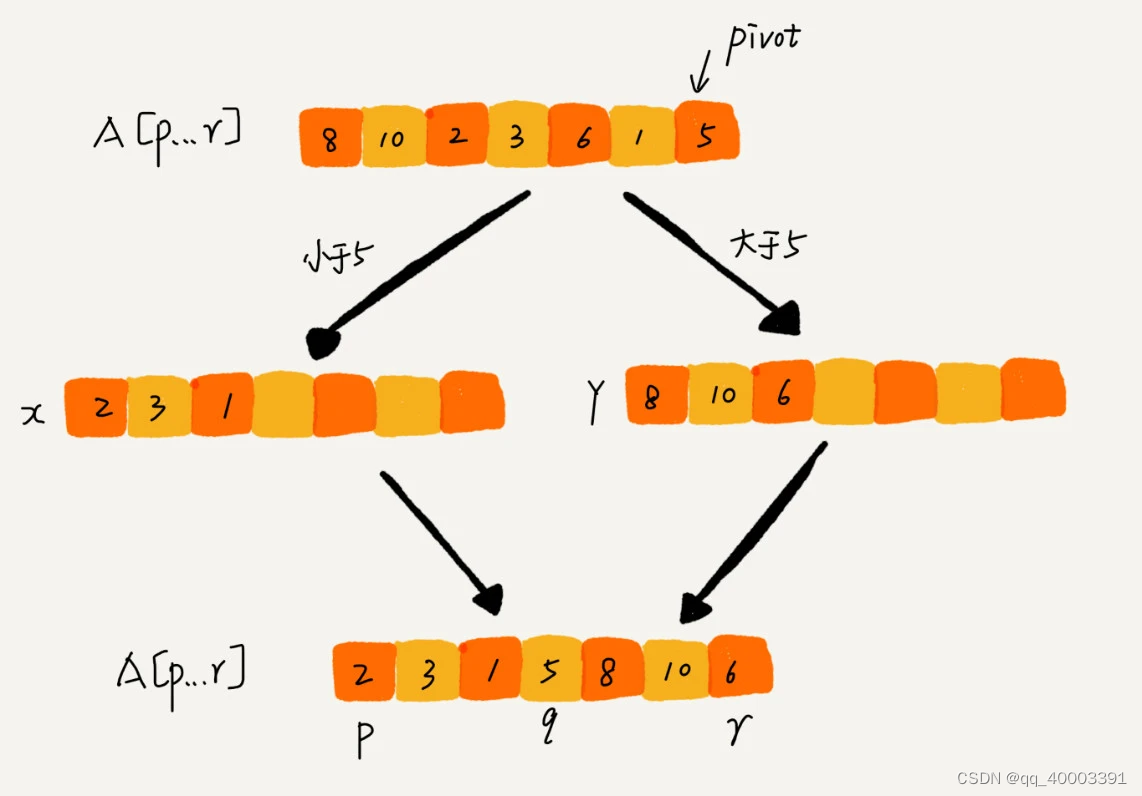
如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
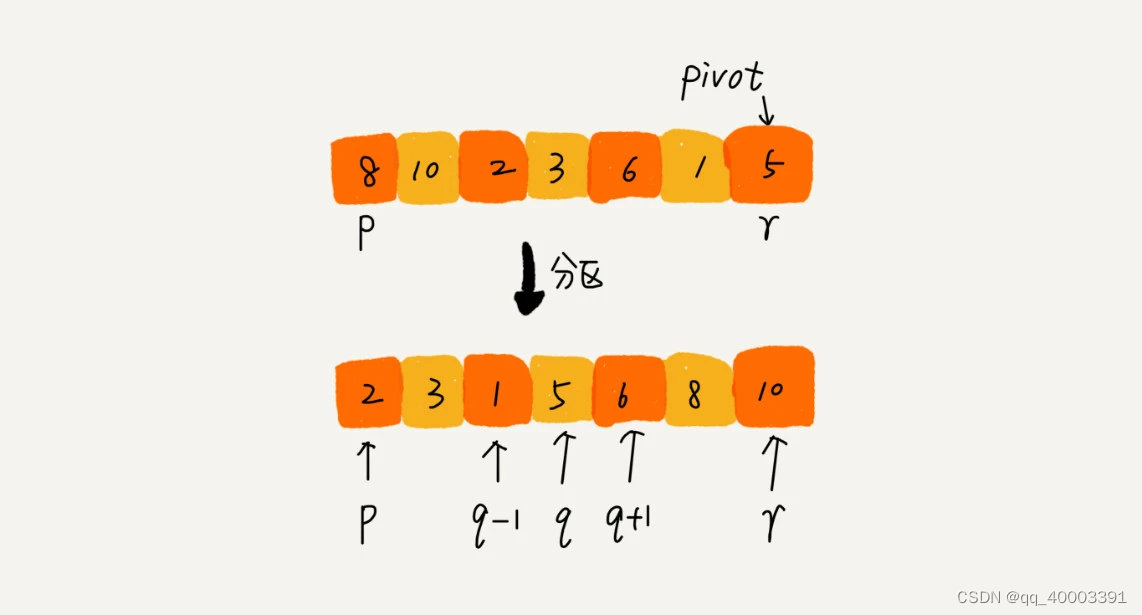
根据分治、递归的处理思想,我们可以用递归排序下标从 p 到 q-1 之间的数据和下标从 q+1 到 r 之间的数据,直到区间缩小为 1,就说明所有的数据都有序了。

比较:

可以发现,
归并排序的处理过程是由下到上的,先处理子问题,然后再合并。
而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。
归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。
快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
快排是一种原地、不稳定的排序算法。
归并排序和快速排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。
理解归并排序的重点是理解递推公式和 merge() 合并函数。同理,理解快排的重点也是理解递推公式,还有 partition() 分区函数。
归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是 O(n)。正因为此,它也没有快排应用广泛。
快速排序算法虽然最坏情况下的时间复杂度是 O(n2),但是平均情况下时间复杂度都是 O(nlogn)。不仅如此,快速排序算法时间复杂度退化到 O(n2) 的概率非常小,我们可以通过合理地选择 pivot 来避免这种情况。
线性排序:
桶排序(Bucket sort),计数排序(Counting sort)基数排序(Radix sort)
小结:《计算之魂》-1.4关于排序的讨论(*)
2.查找问题:
线性表查找:
树查找:
散列查询:
3.递归(*)
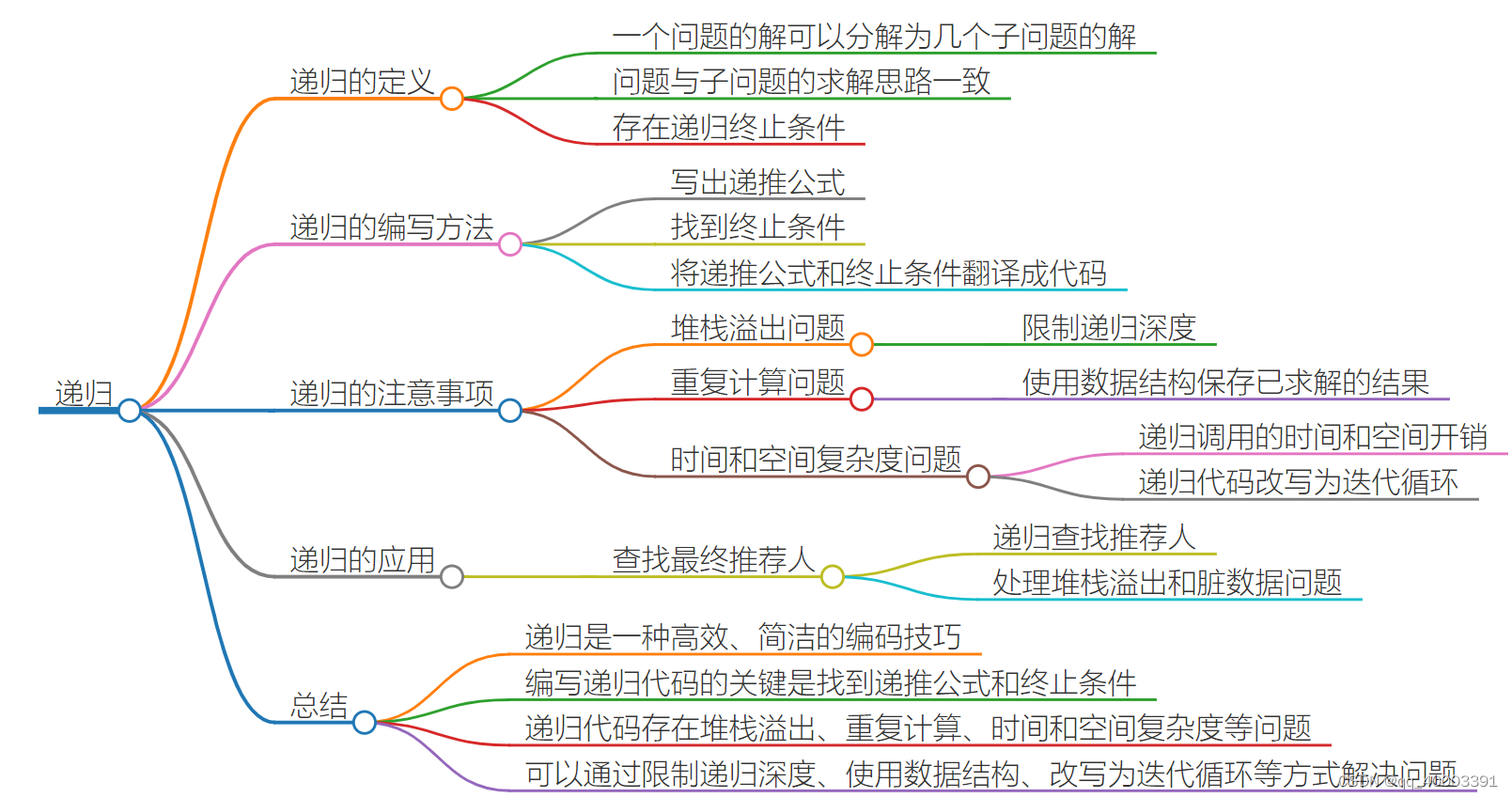
递归需要满足的三个条件
- 一个问题的解可以分解为几个子问题的解
- 这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
- 存在递归终止条件
如何编写递归代码
写出递推公式,找到终止条件
写递归代码的关键就是找到如何将大问题分解为小问题的规律,并且基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
4.分治算法(*)
第04章 巩固练习:
数组
- 实现一个支持动态扩容的数组
- 实现一个大小固定的有序数组,支持动态增删改操作
- 实现两个有序数组合并为一个有序数组
数组
- Three Sum(求三数之和)
英文版:https://leetcode.com/problems/3sum/
中文版:https://leetcode-cn.com/problems/3sum/
- Majority Element(求众数)
英文版:https://leetcode.com/problems/majority-element/
中文版:https://leetcode-cn.com/problems/majority-element/
- Missing Positive(求缺失的第一个正数)
英文版:https://leetcode.com/problems/first-missing-positive/
中文版:https://leetcode-cn.com/problems/first-missing-positive/
链表
- 实现单链表、循环链表、双向链表,支持增删操作
- 实现单链表反转
- 实现两个有序的链表合并为一个有序链表
- 实现求链表的中间结点
链表
- Linked List Cycle I(环形链表)--->(1)
英文版:https://leetcode.com/problems/linked-list-cycle/
中文版:https://leetcode-cn.com/problems/linked-list-cycle/
- Merge k Sorted Lists(合并 k 个排序链表)
英文版:https://leetcode.com/problems/merge-k-sorted-lists/
中文版:https://leetcode-cn.com/problems/merge-k-sorted-lists/
栈
- 栈用数组实现一个顺序栈
- 用链表实现一个链式栈
- 编程模拟实现一个浏览器的前进、后退功能
栈
- Valid Parentheses(有效的括号)
英文版:https://leetcode.com/problems/valid-parentheses/
中文版:https://leetcode-cn.com/problems/valid-parentheses/
- Longest Valid Parentheses(最长有效的括号)
英文版:https://leetcode.com/problems/longest-valid-parentheses/
中文版:https://leetcode-cn.com/problems/longest-valid-parentheses/
- Evaluate Reverse Polish Notatio(逆波兰表达式求值)
英文版:https://leetcode.com/problems/evaluate-reverse-polish-notation/
中文版:https://leetcode-cn.com/problems/evaluate-reverse-polish-notation/
队列
- 用数组实现一个顺序队列
- 用链表实现一个链式队列
- 实现一个循环队列
队列
Design Circular Deque(设计一个双端队列)
英文版:https://leetcode.com/problems/design-circular-deque/
中文版:https://leetcode-cn.com/problems/design-circular-deque/
Sliding Window Maximum(滑动窗口最大值)
英文版:https://leetcode.com/problems/sliding-window-maximum/
中文版:https://leetcode-cn.com/problems/sliding-window-maximum/
递归
- 编程实现斐波那契数列求值 f(n)=f(n-1)+f(n-2)
- 编程实现求阶乘 n!
- 编程实现一组数据集合的全排列
递归
Climbing Stairs(爬楼梯)
英文版:https://leetcode.com/problems/climbing-stairs/
中文版:https://leetcode-cn.com/problems/climbing-stairs/
排序
- 实现归并排序、快速排序、插入排序、冒泡排序、选择排序
- 编程实现 O(n) 时间复杂度内找到一组数据的第 K 大元素
二分查找
- 实现一个有序数组的二分查找算法
- 实现模糊二分查找算法(比如大于等于给定值的第一个元素)
Sqrt(x) (x 的平方根)--->(1)
英文版:https://leetcode.com/problems/sqrtx/
中文版:https://leetcode-cn.com/problems/sqrtx/
散列表
- 实现一个基于链表法解决冲突问题的散列表
- 实现一个 LRU 缓存淘汰算法
字符串
- 实现一个字符集,只包含 a~z 这 26 个英文字母的 Trie 树
- 实现朴素的字符串匹配算法
字符串
Reverse String (反转字符串)
英文版:https://leetcode.com/problems/reverse-string/
中文版:https://leetcode-cn.com/problems/reverse-string/
Reverse Words in a String(翻转字符串里的单词)
英文版:https://leetcode.com/problems/reverse-words-in-a-string/
中文版:https://leetcode-cn.com/problems/reverse-words-in-a-string/
String to Integer (atoi)(字符串转换整数 (atoi))
英文版:https://leetcode.com/problems/string-to-integer-atoi/
中文版:https://leetcode-cn.com/problems/string-to-integer-atoi/
二叉树
- 实现一个二叉查找树,并且支持插入、删除、查找操作
- 实现查找二叉查找树中某个节点的后继、前驱节点
- 实现二叉树前、中、后序以及按层遍历
堆
- 实现一个小顶堆、大顶堆、优先级队列
- 实现堆排序
- 利用优先级队列合并 K 个有序数组
- 求一组动态数据集合的最大 Top K
Invert Binary Tree(翻转二叉树)
英文版:https://leetcode.com/problems/invert-binary-tree/
中文版:https://leetcode-cn.com/problems/invert-binary-tree/
Maximum Depth of Binary Tree(二叉树的最大深度)
英文版:https://leetcode.com/problems/maximum-depth-of-binary-tree/
中文版:https://leetcode-cn.com/problems/maximum-depth-of-binary-tree/
Validate Binary Search Tree(验证二叉查找树)
英文版:https://leetcode.com/problems/validate-binary-search-tree/
中文版:https://leetcode-cn.com/problems/validate-binary-search-tree/
Path Sum(路径总和)
英文版:https://leetcode.com/problems/path-sum/
中文版:https://leetcode-cn.com/problems/path-sum/
图
- 实现有向图、无向图、有权图、无权图的邻接矩阵和邻接表表示方法
- 实现图的深度优先搜索、广度优先搜索
- 实现 Dijkstra 算法、A* 算法
- 实现拓扑排序的 Kahn 算法、DFS 算法
Number of Islands(岛屿的个数)
英文版:https://leetcode.com/problems/number-of-islands/description/
中文版:https://leetcode-cn.com/problems/number-of-islands/description/
Valid Sudoku(有效的数独)
英文版:https://leetcode.com/problems/valid-sudoku/
中文版:https://leetcode-cn.com/problems/valid-sudoku/
贪心
分治
- 利用分治算法求一组数据的逆序对个数
回溯
- 利用回溯算法求解八皇后问题
- 利用回溯算法求解 0-1 背包问题
动态规划
- 0-1 背包问题
- 最小路径和(详细可看 @Smallfly 整理的 Minimum Path Sum)
- 编程实现莱文斯坦最短编辑距离
- 编程实现查找两个字符串的最长公共子序列
- 编程实现一个数据序列的最长递增子序列
Regular Expression Matching(正则表达式匹配)
英文版:https://leetcode.com/problems/regular-expression-matching/
中文版:https://leetcode-cn.com/problems/regular-expression-matching/
Minimum Path Sum(最小路径和)
英文版:https://leetcode.com/problems/minimum-path-sum/
中文版:https://leetcode-cn.com/problems/minimum-path-sum/
Coin Change (零钱兑换)
英文版:https://leetcode.com/problems/coin-change/
中文版:https://leetcode-cn.com/problems/coin-change/
Best Time to Buy and Sell Stock(买卖股票的最佳时机)
英文版:https://leetcode.com/problems/best-time-to-buy-and-sell-stock/
中文版:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock/
Maximum Product Subarray(乘积最大子序列)
英文版:https://leetcode.com/problems/maximum-product-subarray/
中文版:https://leetcode-cn.com/problems/maximum-product-subarray/
Triangle(三角形最小路径和)
英文版:https://leetcode.com/problems/triangle/
中文版:https://leetcode-cn.com/problems/triangle/
leetcode经典例题100道:
其他链接:
数据结构复习:复习100分钟拿下100分,你能做的到吗?【数据结构】(总复习)加油、加油!!!_哔哩哔哩_bilibili
算法设计与分析(理论):【北大公开课】 算法设计与分析 屈婉玲教授 (76p)_哔哩哔哩_bilibili
《计算之魂》(实践);















 4696
4696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









