








参考张俊林老师的文章对比学习(Contrastive Learning):研究进展精要,这篇文章读完后对对比学习基本概念、模型结构有了深刻的理解。再次感谢,遂据此整理成了笔记,以便帮助学习(主要是俊林老师的这片文章太过轰动,已经不能转载了),其中还有一篇神文利用Contrastive Learning对抗数据噪声:对比学习在微博场景的实践,帮助我对对比学习的应用场景理解更加深刻,对比学习居然这么多的玩法~
1 对比学习
对比学习是自监督学习的一种,也就是说,不依赖标注数据,要从无标注图像中自己学习知识。怎么理解?充分使用越来越大量的无标注数据,使用越来越复杂的模型,采用自监督预训练模式,来从中吸取无标注图像本身的先验知识分布,在下游任务中通过Fine-tuning,来把预训练过程习得的知识,迁移给并提升下游任务的效果。对比学习可以通过后面的一个原则三个关键点进行理解
1.1 指导原则
通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。
1.2 关键点
- 构造相似实例和不相似实例
- 设计模型结构
- 防止模型坍塌
2 SimCLR为例
以SimCLR为例,针对这一个原则三个关键点通过问答进行分析
2.1 关键点1: 如何构造正例和负例?
- 正例。平移、旋转、删除某个特征等
- 负例。batch内随机采样、全局负采样等
对比学习希望习得某个表示模型,它能够将图片映射到某个投影空间,并在这个空间内拉近正例的距离,推远负例距离。也就是说,迫使表示模型能够忽略表面因素,学习图像的内在一致结构信息,即学会某些类型的不变性,比如遮挡不变性、旋转不变性、颜色不变性等。
2.2 关键点2: 如何设计模型结构?
SimCLR模型结构如下。由对称的上下两个分枝(Branch)构成,说白了就是双塔模型
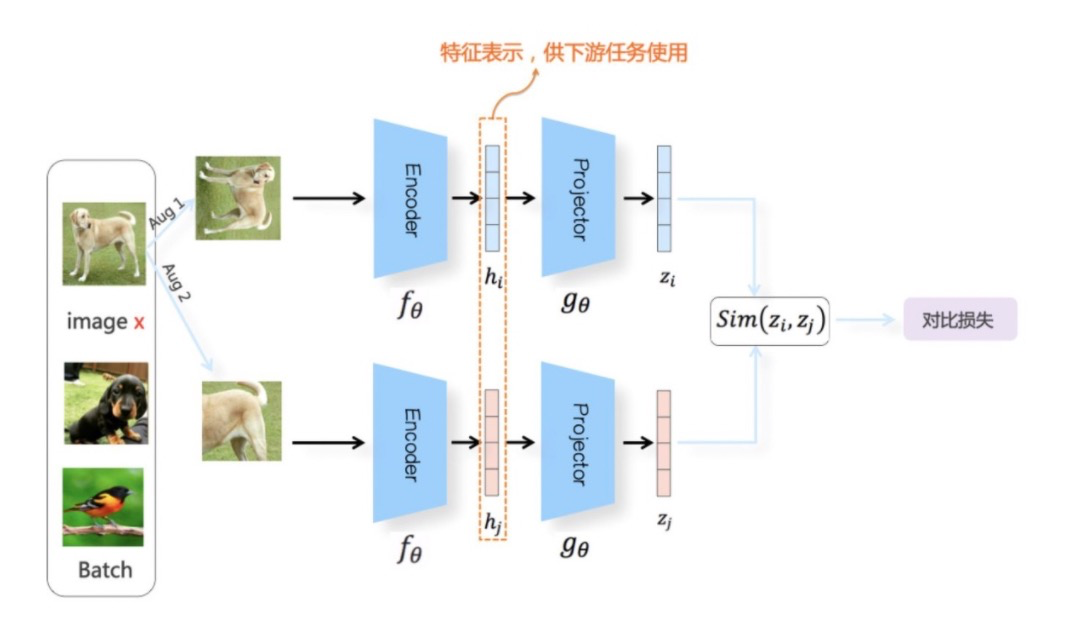
随机从无标训练数据中取N个构成一个Batch,对于Batch里的任意图像,根据前面样本构造方法形成两个图像增强视图:Aug1和Aug2。Aug1 和Aug2各自包含N个增强数据(1个正,其余为负例),并分别经过上下两个分枝,对增强图像做非线性变换,这两个分枝就是SimCLR设计出的表示学习所需的投影函数,负责将图像数据投影到某个表示空间。
对于Batch内某张图像 x x x来说,在Aug1和Aug2里的对应的增强后图像分别是 x i x_i xi和 x j x_j xj,那么数据对 < x i , x j > <x_i, x_j> <xi,xj>,互为正例,而 x i x_i xi和Aug1及Aug2里除 x j x_j xj之外的其它任意2N-2个图像都互为负例。
相似性函数来作为距离度量标准来判断两个向量在投影空间里距离的远近。具体而言,相似性计算函数采取对表示向量L2正则后的点积或者表示向量间的余弦距离
S i m ( z i , z j ) = z i T ∣ ∣ z i ∣ ∣ 2 ⋅ z j ∣ ∣ z j ∣ ∣ 2 Sim(z_i, z_j) = \frac{z_i^T}{||z_i||_2} · \frac{z_j}{||z_j||_2} Sim(zi,zj)=∣∣zi∣∣2ziT⋅∣∣zj∣∣2zj
问题1,为什么L2 norm?
- 后续ANN算法通常是依赖L2距离的,这与点乘学到的向量空间并不等价,而归一化后 ∣ ∣ g 1 − g 2 ∣ ∣ 2 = ∣ ∣ g 1 ∣ ∣ 2 + ∣ ∣ g 2 ∣ ∣ 2 − 2 < g 1 , g 2 > = 2 − 2 < g 1 , g 2 > ||g_1-g_2||_2 = \sqrt{||g_1||^2 + ||g_2||^2 - 2<g_1, g_2>} = \sqrt{2 - 2<g_1, g_2> } ∣∣g1−g2∣∣2=∣∣g1∣∣2+∣∣g2∣∣2−2<g1,g2>=2−2<g1,g2>是与点积目标一致的。
- 相似度计算有两中方法:内积和cosine。把cosine公式 c o s ( a , b ) = a ⋅ b ∣ ∣ a ∣ ∣ 2 ∗ ∣ ∣ b ∣ ∣ 2 cos(a,b) = \frac{a·b}{||a||_2 * ||b||_2} cos(a,b)=∣∣a∣∣2∗∣∣b∣∣2a⋅b,可以发现发现cosine可以理解为对a和b各自先做了一个L2 Norm,然后两者再做内积。
SimCLR的损失函数采用InfoNCE Loss,某个例子对应的InfoNCE损失为
L i = − l o g ( e x p ( S ( z i , z i + ) / τ ) ∑ j = 0 K e x p ( S ( z i , z j ) / τ ) ) L_i = -log(\frac{exp(S(z_i, z_i^{+})/\tau)}{\sum_{j=0}^{K}exp(S(z_i, z_j)/\tau)}) Li=−log(∑j=0Kexp(S(zi,zj)/τ)exp(S(zi,zi+)/τ))
其中, < z i , z i + > <z_i, z_i^{+}> <zi,zi+>代表两个正例相应的表示向量。从InfoNCE可以看出
- 分子部分鼓励正例相似度越高越好,也就是在表示空间内距离越近越好;
- 分母部分,则鼓励任意负例之间的向量相似度越低越好,也就是距离越远越好。
问题2,InfoNCE损失函数中参数 τ \tau τ的作用是什么?
温度参数会将模型更新的重点聚焦到有难度的负例,并对它们做相应的惩罚,难度越大,也即是与 x i x_i xi越近,则分配到的惩罚越多。
惩罚是指在模型优化过程中,将负例从 x i x_i xi 身边推开。如果温度超参数 τ \tau τ 设置得越小,则InfoNCE分配惩罚项的范围越窄,更聚焦在距离 x i x_i xi比较近的较小范围内的负例里。同时,这些被覆盖到的负例,因为数量减少了,所以,每个负例,会承担更大的斥力(参考上图左边子图)。极端情况下,假设温度系数趋近于0,那么InfoNCE基本退化为Triplet,也就是说,有效负例只会聚焦在距离 x i x_i xi 最近的一到两个最难的实例。从上述分析,可以看出:温度超参越小,则更倾向把超球面上的局部密集结构推开打散,使得超球面上的数据整体分布更均匀(参考上图右边子图)。
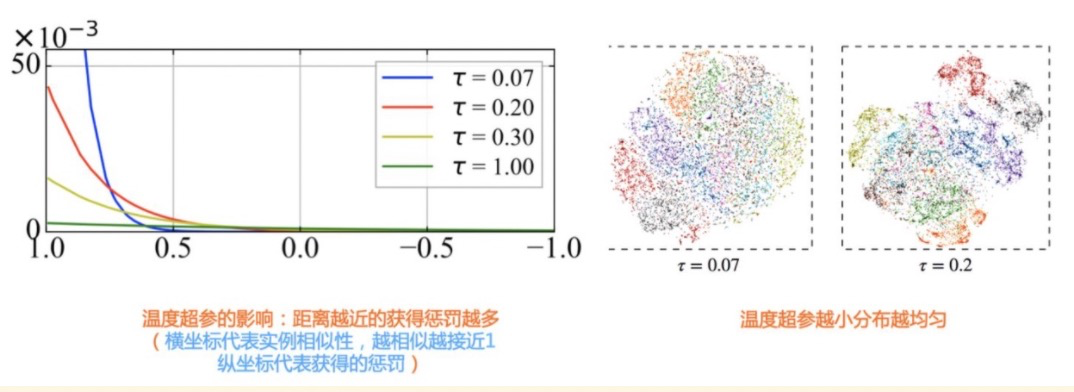
问题3,那是不是参数 τ \tau τ越小越好?
对于某个数据 x i x_i xi ,只有一对正例 < x i , x i + <x_i, x_i^{+} <xi,xi+,可能会发生如下的情形:距离 x i x_i xi比较近的所谓“负例”,其实本来应该是正例,比如 x i x_i xi 是一张狗的照片,而 x i − x_i^{-} xi− 其实也是一张狗的照片。只是因为对比学习是无监督的,我们没有先验知识知晓这一点,所以也会把这张狗的照片当作负例。而如果温度超参越小,则可能越会倾向把这些本来是潜在正例的数据在超球面上推远,而这并不是我们想要看到的。要想容忍这种误判,理论上应该把温度超参设置大一些。所以,温度超参需要在鼓励Uniformity和容忍这种误判之间找到一个平衡点,而调节这个参数大小,其实就是在寻找这两者的平衡点。
2.3 关键点3: 什么是模型坍塌?
回答之前先介绍下什么是好的对比学习系统。好的对比学习系统右2个要素: Alignment和Uniformity。
- Alignment代表我们希望对比学习把相似的正例在投影空间里面有相近的编码。
- Uniformity代表什么含义呢?当所有实例映射到投影空间之后,我们希望它在投影空间内的分布是尽可能均匀的。

追求分布的Uniformity的目的。我们希望实例映射到投影空间后,在对应的Embedding包含的信息里,可以更多保留自己个性化的与众不同的信息。比如有两张图片,都是关于狗的,但是一张是在草地上跑的黑狗,一张是在水里游泳的白狗。如果在投影成Embedding后,模型能各自保留各自的个性化信息,那么两张图片在投影空间里面是有一定距离的,以此表征两者的不同。而这就代表了分布的均匀性,指的是在投影球面上比较均匀,而不会说因为都是关于狗的图片,而聚到球面的同一个点中去,那就会忽略掉很多个性化的信息。这就是说为什么Uniformity分布均匀代表了编码和投影函数f保留了更多的个性化信息。
问题4,什么是模型坍塌?
不论你输入的是什么图片,经过映射函数之后,在投影空间里面,所有图像的编码都会坍塌到同一个点。坍塌到同一个点又是什么含义呢?就是说不论我的输入是什么,最终经过函数映射,被映射成同一个embedding,所有图像对应的Embedding都是一样的,这意味着你的映射函数没有编码任何有用的信息。
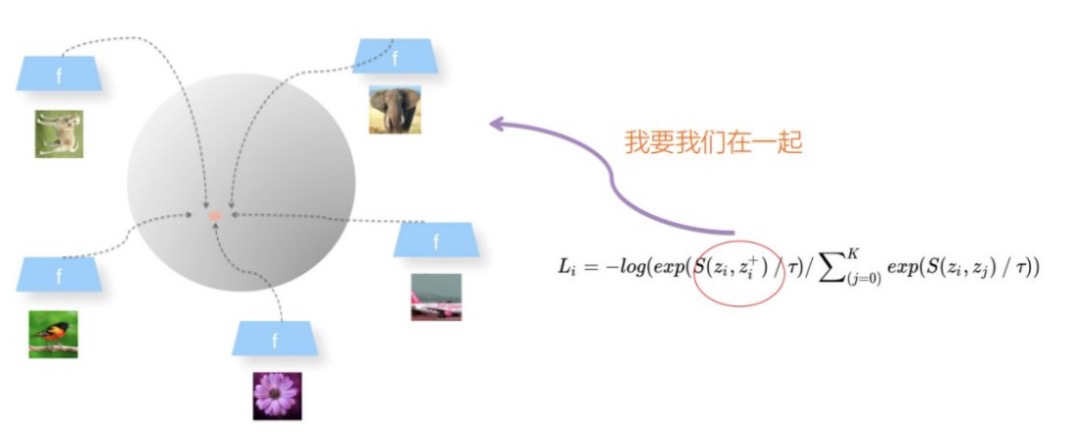
问题5,如何防止模型坍塌?
通过引入负例来防止模型坍塌。InfoNCE的分子部分体现了Alignment这个要素,因为它期望正例在投影空间里面越近越好,也就是相似性越大越好。它防止坍塌是靠分母里的负例,负例体现了“Uniformity”属性,也就是说,如果图片和负例越不相似,则相似性得分越低,代表投影空间里距离越远,则损失函数就越小。InfoNCE通过强迫图片和众多负例之间,在投影球面相互推开,以此实现分布的均匀性,也就兼顾了Uniformity这一要素。所以可以理解为SimCLR是通过随机负例来防止模型坍塌的。
参考
欢迎关注微信公众号(算法工程师面试那些事儿),本公众号聚焦于算法工程师面试,期待和大家一起刷leecode,刷机器学习、深度学习面试题等,共勉~



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









