








基于物品的协同过滤,ItemCF,ItemCollaborationFilter,
核心思想
给用户推荐那些和他们之前喜欢的物品相似的物品。
比如,用户A之前买过《数据挖掘导论》,该算法会根据此行为给你推荐《机器学习》,但是ItemCF算法并不利用物品的内容属性计算物品之间的相似度,它主要通过分析用户的行为记录计算物品之间的相似度。
算法认为,物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢物品B。
算法原理
基于物品的协同过滤算法主要分为两步:
- 计算物品之间的相似度;
- 根据物品的相似度和用户的历史行为给用户生成推荐列表;
1、计算物品之间的相似度
物品i和j的相似度计算公式:
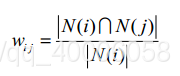
分母|N(i)|是喜欢物品i的用户数,而分子 |N(i)&N(j)| 是同时喜欢物品i和物品j的用户数。因此,上述公式可以理解为喜欢物品i的用户中有多少比例的用户也喜欢物品j。
改进1:上述公式虽然看起来很有道理,但是却存在一个问题。如果物品j很热门,很多人都喜欢,那么Wij就会很大,接近1。因此,该公式会造成任何物品都会和热门的物品有很大的相似度,这对于致力于挖掘长尾信息的推荐系统来说显然不是一个好的特性。为了避免推荐出热门的物品,可以用下面的公式:
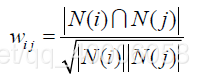
改进2:需要惩罚用户的活跃度。若用户活跃度比较低,只买了有限的几本书,那么这几本书很有可能在一个或者两个兴趣范围内,对计算物品相似度比较有用,但是如果说一书店卖家趁着打折把亚马逊90%的书都买了然后赚差价,那么该用户的行为对计算物品相似度就没什么作用,因为90%的书肯定会覆盖很多范围,故应该惩罚用户的活跃度。
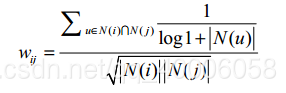
改进3:物品相似度的归一化。归一化不仅仅能提高推荐的准确度,还可以提高推荐的覆盖率和多样性。比如亚马逊上,用户的兴趣爱好肯定是分成几类的,很少说爱好集中在一类。假设有两类A和B,A类之间的相似度为0.5, B类之间的相似度为0.8,A和B之间的相似度为0.2, 当用户买了5本A类的书和5本B类的书后,我们要给用户来推荐书,如果按照之前的方法,最后按照相似度排序,那么推荐的应该都会是B类物品,就算B类中排名比较低,但照样比A类要高阿,所以应该根据类别进行相似度的归一化,这样一来A的相似度为1,B的相似度也为1,这样的话排序后的推荐A,B类商品都有,就大大提高了准确度,覆盖率和多样性。
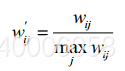
和UserCF类似,我们可以建立一张用户-物品的倒排表(对每个用户建立一个包含他喜欢的物品的列表),这样每次去计算一个用户有过行为的那些物品间的相似度,能够保证计算的相似度都是有用的,而不用花大的计算量在那些0上面(肯定是个稀疏矩阵)

建立相似度矩阵:
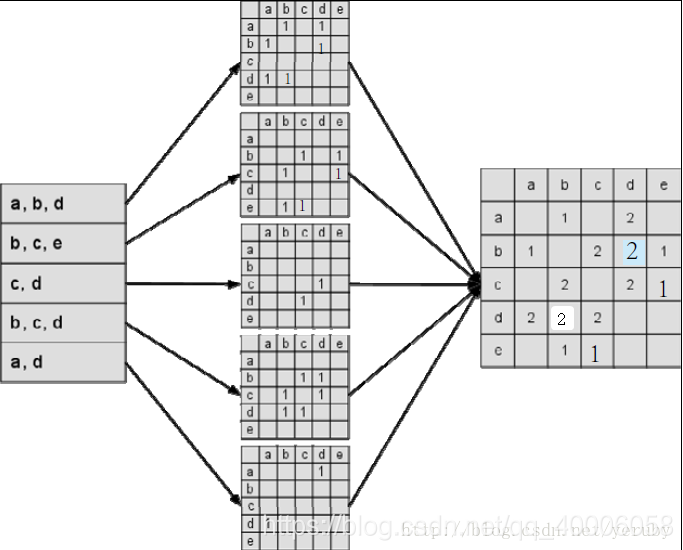
C[i][j]记录了同时喜欢物品i和物品j的用户数,这样我们就可以得到物品之间的相似度矩阵W。
推荐物品
ItemCF通过如下公式计算用户u对一个物品j的兴趣:
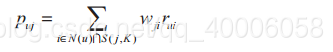
其中,Puj表示用户u对物品j的兴趣,N(u)表示用户喜欢的物品集合(i是该用户喜欢的某一个物品),S(j,k)表示和物品j最相似的K个物品集合(j是这个集合中的某一个物品),Wji表示物品j和物品i的相似度,rui表示用户u对物品i的兴趣(对于隐反馈数据集,如果用户u对物品i有过行为,rui都等于1)。
该公式的含义是:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
例子
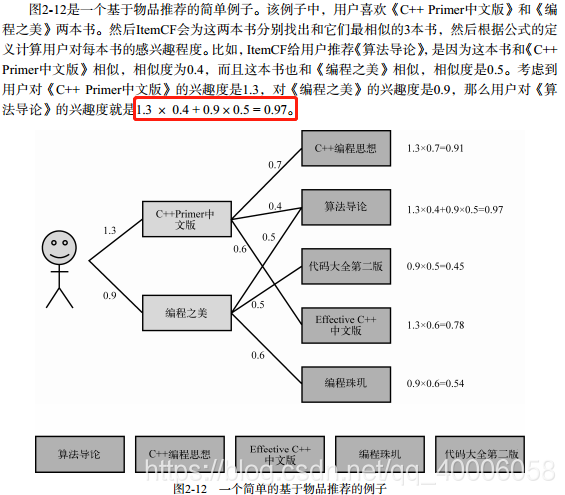
python代码
# -*- coding: utf-8 -*-
'''
Created on 2018年10月25日
@author: https://blog.csdn.net/fjssharpsword/article/details/78223506?utm_source=blogxgwz0
'''
import math
import random
import os
from itertools import islice
class ItemBasedCF:
def __init__(self, datafile = None):
self.datafile = datafile
self.readData()
self.splitData()
def readData(self,datafile = None):
self.datafile = datafile or self.datafile
self.data = []
file = open(self.datafile,'r')
for line in islice(file, 1, None): #file.readlines():
userid, itemid, record = line.split(',')
self.data.append((userid,itemid,float(record)))
def splitData(self,data=None,k=3,M=10,seed=10):
self.testdata = {}
self.traindata = {}
data = data or self.data
random.seed(seed)#生成随机数
for user,item,record in self.data:
self.traindata.setdefault(user,{})
self.traindata[user][item] = record #全量训练
if random.randint(0,M) == k:#测试集
self.testdata.setdefault(user,{})
self.testdata[user][item] = record
def ItemSimilarity(self, train = None):
train = train or self.traindata
self.itemSim = dict()
item_user_count = dict() #item_user_count{item: likeCount} the number of users who like the item
count = dict() #count{i:{j:value}} the number of users who both like item i and j
for user,item in train.items(): #initialize the user_items{user: items}
for i in item.keys():
item_user_count.setdefault(i,0)
item_user_count[i] += 1
for j in item.keys():
if i == j:
continue
count.setdefault(i,{})
count[i].setdefault(j,0)
count[i][j] += 1
for i, related_items in count.items():
self.itemSim.setdefault(i,dict())
for j, cuv in related_items.items():
self.itemSim[i].setdefault(j,0)
self.itemSim[i][j] = cuv / math.sqrt(item_user_count[i] * item_user_count[j] * 1.0)
def recommend(self,user,train = None, k = 10,nitem = 5):
train = train or self.traindata
rank = dict()
ru = train.get(user,{})
for i,pi in ru.items():
for j,wj in sorted(self.itemSim[i].items(), key = lambda x:x[1], reverse = True)[0:k]:
if j in ru:
continue
rank.setdefault(j,0)
rank[j] += pi*wj
return dict(sorted(rank.items(), key = lambda x:x[1], reverse = True)[0:nitem])
def recallAndPrecision(self,train = None,test = None,k = 8,nitem = 5):
train = train or self.traindata
test = test or self.testdata
hit = 0
recall = 0
precision = 0
for user in test.keys():
tu = test.get(user,{})
rank = self.recommend(user,train = train,k = k,nitem = nitem)
for item,_ in rank.items():
if item in tu:
hit += 1
recall += len(tu)
precision += nitem
return (hit / (recall * 1.0),hit / (precision * 1.0))
def coverage(self,train = None,test = None,k = 8,nitem = 5):
train = train or self.traindata
test = test or self.testdata
recommend_items = set()
all_items = set()
for user in test.keys():
for item in test[user].keys():
all_items.add(item)
rank = self.recommend(user, train, k = k, nitem = nitem)
for item,_ in rank.items():
recommend_items.add(item)
return len(recommend_items) / (len(all_items) * 1.0)
def popularity(self,train = None,test = None,k = 8,nitem = 5):
train = train or self.traindata
test = test or self.testdata
item_popularity = dict()
for user ,items in train.items():
for item in items.keys():
item_popularity.setdefault(item,0)
item_popularity[item] += 1
ret = 0
n = 0
for user in test.keys():
rank = self.recommend(user, train, k = k, nitem = nitem)
for item ,_ in rank.items():
ret += math.log(1+item_popularity[item])
n += 1
return ret / (n * 1.0)
def testRecommend(self,user):
rank = self.recommend(user,k = 10,nitem = 5)
for i,rvi in rank.items():
items = self.traindata.get(user,{})
record = items.get(i,0)
print ("%5s: %.4f--%.4f" %(i,rvi,record))
if __name__ == "__main__":
ibc=ItemBasedCF(os.getcwd()+'\\ratings.csv')#初始化数据
ibc.ItemSimilarity()#计算物品相似度矩阵
ibc.testRecommend(user = "345") #单用户推荐
print ("%3s%20s%20s%20s%20s" % ('K',"recall",'precision','coverage','popularity'))
for k in [5,10,15,20]:
recall,precision = ibc.recallAndPrecision( k = k)
coverage =ibc.coverage(k = k)
popularity =ibc.popularity(k = k)
print ("%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (k,recall * 100,precision * 100,coverage * 100,popularity))
与UserCF的区别
ItemCF在实际系统中运用的比较多,主要有两个优点:
- item-item表相比如user-user表要小的多,处理起来比较容易
- itemCF容易提供推荐理由,比如给你推荐《机器学习》是因为你之前买过《数据挖掘》,这样能增加信任度,提高用户和推荐系统的交互,进一步增强个性化推荐

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









