







什么是敏感词
敏感词一般是指带有敏感政治倾向(或反执政党倾向)、暴力倾向、不健康色彩的词或不文明语,分为色情类、民生类、反动类、政治类、暴恐类、广告类、医疗类、特殊网址等。
主要用在评价、社区、聊天系统中。
一般对于敏感词的处理有两种方式,第一种是直接删除包含敏感词的关键词和内容,第二种是对敏感词进行替换,比如替换为***符号。
如何处理敏感词
目前常见的有3种方案:
- 暴力破解;
- 构建Trie树;
- 双数组Trie树;
方案一: 暴力破解,遍历所有敏感词
这是最简单的过滤方案,遍历所有敏感词,逐个检测输入的文本中是否含有指定的敏感词。代码如下:
@Test
public void sensitiveWordTest() {
Set<String> sensitiveWords = new HashSet<>();
sensitiveWords.add("天🐱");
sensitiveWords.add("二狗子");
sensitiveWords.add("特朗普");
String text = "天🐱店铺地址是二狗子...";
for(String sensitiveWord : sensitiveWords) {
if(text.contains(sensitiveWord)) {
System.out.println("输入的文本存在敏感词:" + sensitiveWord);
break;
}
}
}
这种方案代码简单,也能实现敏感词过滤要求,但是仅仅适用于敏感词非常少的情况,例如只有十几个敏感词的时候,使用这种方案不会存在太大的性能问题。但是敏感词较多的话,时间复杂度是非常高的,CPU消耗很大。所以,一般暴力破解的方式都会被舍弃。
使用DFA算法来匹配敏感词,这也是大多数的敏感词过滤系统采用的方案。 DFA(Deterministic Finite
Automaton)翻译成中文是“确定有穷自动机
”。它的基本思想是基于状态转移来检索敏感词,只需要扫描一次待检测文本,就能对所有敏感词进行检测,所以效率比方案一高不少。
方案二:字典树
Trie树,即字典树,可以理解为前缀树算法,我们可以先把敏感词中有相同前缀的词组合成一个树形结构,不同前缀的词分属不同树形分支。
例如有以下敏感词:军品气枪店、军用手枪、军用枪支、军迷购枪、微型冲锋枪、微声手枪
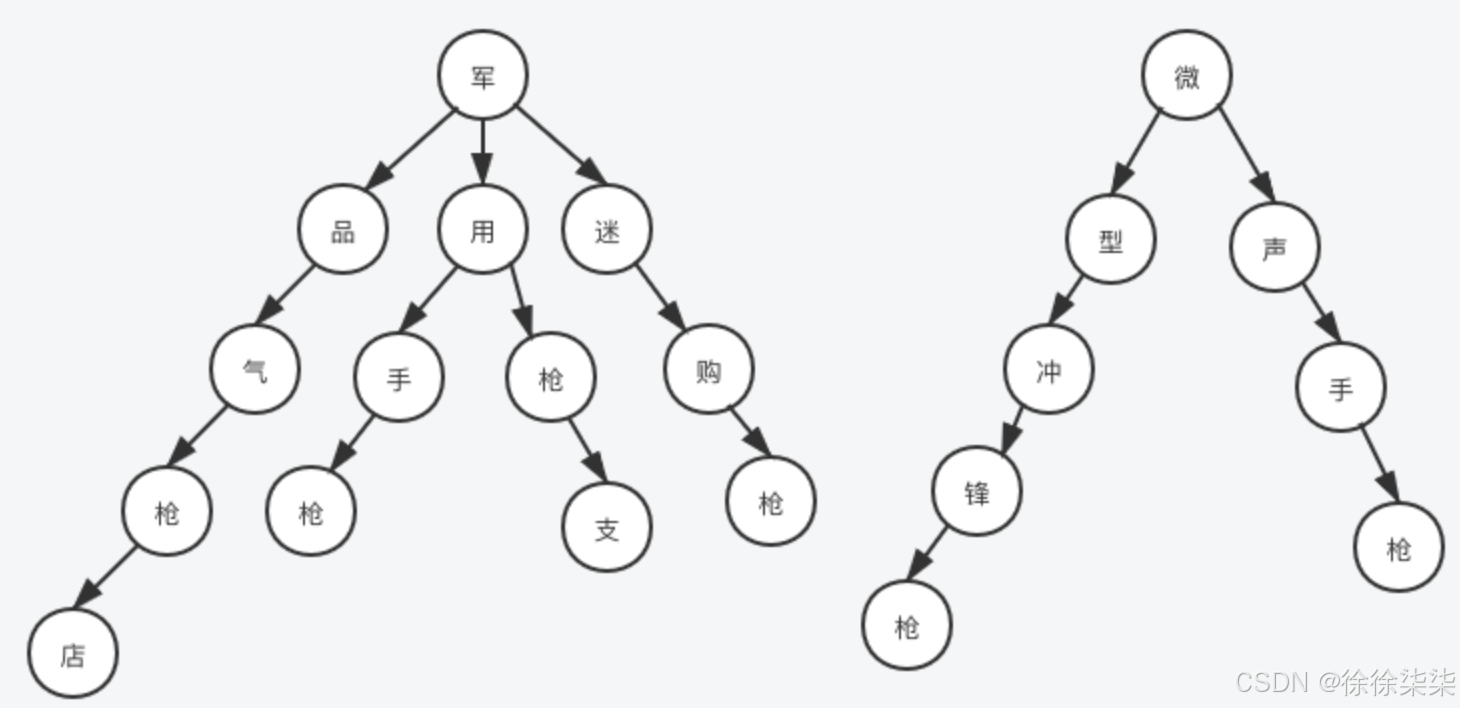
把敏感词组成树形结构最大的好处就是可以减少检索次数,我们只需要遍历一次待检测文本,然后在敏感词库中检索出有没有该字符对应的子树就行了,如果没有相应的子树,说明当前检测的字符不在敏感词库中,则直接跳过继续检测下一个字符;如果有相应的子树,则接着检查下一个字符是不是前一个字符对应的子树的子节点,这样迭代下去,就能找出待检测文本中是否包含敏感词了。
比如对于文本“售卖军用枪支是违法行为”,依次检测每个字符,发现前两个字符“售”和“卖”都找不到对应的子树,所以直接跳过,继续检测第三个字符“军”,发现找到了对应的子树,这时候右侧“微”字开头的子树,压根不用再去扫描。接着再检测下个字符“用”字,则排除了“军”下面的“品”和“迷”的子树,在中间的两个子树下查找就够了,然后再根据“枪”字查找,发现只有一个子树了,并且“枪”字下面正好是“支”字,于是成功检索到了敏感词。
以下是本人手撕的一段Trie树的构建过程和匹配过程的算法(好像leetcode也有类似的算法题),非常简短的构建过程,提供出来做参考:
import lombok.Data;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
public class DFA {
private final DNode startNode = new DNode('\u0000');
//public static final int minMatchType = 1;//匹配符合的最短词
//public static final int maxMatchType = 2;//匹配符合的最短词
public void buildNodeTree(List<String> sensitiveWords) {
sensitiveWords.forEach(word -> {
DNode nextNode = startNode;
for (int i = 0; i < word.length(); i++) {
char charAt = word.charAt(i);
nextNode = nextNode.addNextNode(charAt);
if (i == word.length() - 1) {
nextNode.setEnd(true);
}
}
});
}
public String findSensitiveWord(String context) {
if (context == null)
return null;
return startNode.find(context);
}
public static void main(String[] args) {
DFA dfa = new DFA();
List<String> sensitiveWords = Arrays.asList("江大爷", "sdfs", "火枪", "江江");
dfa.buildNodeTree(sensitiveWords);
System.out.println(dfa.findSensitiveWord("我们江大爱学习"));
System.out.println(dfa.findSensitiveWord("我们江大爷爱学习"));
}
}
@Data
class DNode {
private boolean end = false;
private final Map<Character, DNode> nextNodes = new ConcurrentHashMap<>();
private char val;
public DNode(char val) {
this.val = val;
}
public DNode addNextNode(char val) {
DNode nextNode = nextNodes.getOrDefault(val, new DNode(val));
nextNodes.putIfAbsent(val, nextNode);
return nextNode;
}
public String find(String context) {
for (int i = 0; i < context.length(); i++) {
int len = findNext(context, i);
if (len > 0) {
return context.substring(i, i + len);
}
}
return null;
}
public int findNext(String context, int index) {
if (index >= context.length())
return 0;
char charAt = context.charAt(index);
DNode node = nextNodes.get(charAt);
if (node == null) {
return 0;
}
if (node.isEnd()) {
return 1;
}
int len = node.findNext(context, ++index);
return len == 0 ? 0 : len + 1;
}
@Override
public String toString() {
return String.valueOf(val);
}
}
普通的DFA算法,性能很好,但也有个弊端,就是占用内存过大,如果仅仅只是用作敏感词过滤,还是没啥问题的。但如果使用在分词领域,那内存就会爆炸。我们举个例子,如下几个词语:[美利坚联众国, 联众国, 坚定, 坚定定, 坚定定定定],这个DFA树有会有很多个重复的字,和重复的词,如果我们有办法把这块内存给压缩掉,那么内存会极大的节约。
改进:使用双数组Trie树 -DAT算法,优点:词语越多,内存压缩越高效,在大量词语下,内存使用仅是普通算法的1/10,甚至更低
方案三 - 双数组Trie树
在聊双数组Trie树之前,需要了解双数组Trie树与普通Trie树的区别,有三:
- 算法实现上不同:普通Trie树,一般使用深度优先遍历算法(也可使用广度优先遍历算法)即可实现需求;而双数组Trie只能使用广度优先遍历算法;
- 树形结构构造方式不同:普通Trie树,使用Node构建树形接口;而双数组Trie使用数组构建树形结构;
- 内存结构不同:数组构建树形结构,内存结构紧凑且占用内存小;普通Trie树构建树形结构,内存结构松散且占用内存大;
但其本质都是需要构建树形结构的。
双数组Trie树涉及到两个状态方程:
- base[s] + offset + c = t
- check[t] = s
描述一下两个公式的准确用途:
第一个函数是说,每个词进来以后,通过公式的计算,看这个值是否存在,比如:【手枪,银行】,这两个词计算出来的值一样,那就表示手枪和银行可能存在;
第二个函数,就是第一个函数计算出来的可能性变成确定性。
假设
字符集编码: 中=1, 人=2, 华=3, 大=4, 学=5, 新=6, 清=7
词典: dict = [“清华”, “中华”, “华人”, “清新”, “清华大学”]
词典最大的长度是4,那我们就要循环遍历4次。
Base数组
再看状态方程:base[s] + offset + c = t,offset初始为0
在该状态方程中, s和t分别是表示两种状态,而c是表示一个字符输入,可以使状态从s变成t,即状态转移. Base[s]表示状态t的转移基数。而c表示输入字符c的编码值。
第一层:
计算步骤如下:
- 起始状态0: Base[0] = 1;
- 输入字符 ‘清’, 状态转移至: Base[0] + ‘清’.c = 1 + 7 = 8,并把base[0]的值赋值到base[8]
- 输入字符 ‘中’,状态转移至:Base[0] + ‘中’.c = 1 + 1 = 2,并把base[0]的值赋值到base[2]
- 输入字符 ‘华’,状态转移至:Base[0] + ‘华’.c = 1 + 3 = 4,并把base[0]的值赋值到base[4]
所以我们能看到,在2,4,8上分别有对应的汉字,并且base数组上标记了1
word null null [中] null [华] null null null [清] null null null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 1 0 1 0 0 0 1 0 0 0 0
check -1 -1 0 -1 0 -1 -1 -1 0 -1 -1 -1 -1
同理第二层:
首先在word那行,2,4,8的位置上的汉字不动,需要增加 “清[华]”, “中[华]”, “华[人]”, “清[新]” ,代表第二层的标记,这里有3个父节点,所以要计算3次。
计算步骤如下:
- 起始状态 ‘清’: Base[8] = 1;
1.1 输入字符 ‘华’, 状态转移至’清华’: Base[8] + ‘华’.c = 1 + 3 + 0 = 4,并把base[8]的值赋值到base[4]
1.2 输入字符 ‘新’,状态转移至’清新’:Base[8] + ‘新’.c = 1 + 6 + 0 = 7,并把base[8]的值赋值到base[7] - 起始状态 ‘中’: Base[2] = 1;
2.1 输入字符 ‘华’, 状态转移至’中华’: Base[2] + ‘华’.c = 1 + 3 + 0 = 4,并把base[2]的值赋值到base[4],但我们发现base[4]已经被占用了,所以就需要将offset + 1,base[5]没有被占用,那我们把base[2]的值 + 1在赋给base[5] - 其他的同理
word null null [中] 华[人] [华] 中[华] 清[华] null [清] 清[新] null null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 2 1 1 2 3 0 3 3 0 0 0
check -1 -1 0 4 0 2 8 -1 0 8 -1 -1 -1
第三和四层:同理第二层,最终得到结果如下
word null null [中] 华[人] [华] 中[华] 清[华] 清华[大] [清] 清[新] 清华大[学] null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 2 1 1 2 3 5 3 3 5 0 0
check -1 -1 0 4 0 2 8 6 0 8 7 -1 -1
这样,我们就构建了一个从上到下的树结构。
我们发现,在双数组Trie树中的Base数组以及转移基数是非常重要的。使用双数组Trie树来压缩经典Trie树的内存空间的关键在于转移基数的计算,计算转移基数的基本思路是:在Base数组中, 从某一地址开始,向下找,直到找到一个地址,使得其子结点中所有需要的位置[可达状态]未被占用。不被需要的位置是不存在的状态, 或称不可达状态,可以被其他可达状态占用。
Check数组
当我们对词"清中"进行检测时,其过程如下(请对照着生成好的结构):
- 起始状态 0: Base[0] = 1;
- 输入字符 ‘清’, 状态转移至’清’: Base[0] + ‘清’.code = 1 + 7 = 8
- 输入字符 ‘中’,状态转移至’清中’:Base[‘清’] + ‘中’.code = 3 + 1 = 4.
- Base[‘清中’] != 0, 所以"清中"存在.
以上结论显然是错误的,在我们的假设词典中,并不存在"清中",所以其状态是不可达的。那怎么来区分它们呢?
引入Check数组
我们知道状态"清中",是在状态"清"下输入"中"转移过来的。而状态"华"是在状态"0"下输入"华"转移过来的。这两个状态的上一个状态并不一样,所以我们可以维护另外一个与Base数组长度相同的数组,即Check数组。
在Check数组中,我们在每个状态对应位置保存该状态上一状态。我们在判断一个词是否存在,不只判断Base位置是否为空,还要判断Check数组中对应位置上的值是否指向该状态的上一状态。有的博客中在Check数组中保存的是上一状态的转移基数, 而本文保存上一状态的位置。
所以,计算步骤如下:
第一层的计算步骤就会变成:
计算步骤如下:
- 起始状态0: Base[0] = 1;
- 输入字符 ‘清’, 状态转移至: Base[0] + ‘清’.c = 1 + 7 = 8,并把base[0]的值赋值到base[8],check[8]=[0]
- 输入字符 ‘中’,状态转移至:Base[0] + ‘中’.c = 1 + 1 = 2,并把base[0]的值赋值到base[2],check[2]=[0]
- 输入字符 ‘华’,状态转移至:Base[0] + ‘华’.c = 1 + 3 = 4,并把base[0]的值赋值到base[4],check[4]=[0]
其余层,同上。
重新对词"清中"进行检测:
- 起始状态 0: Base[0] = 1;
- 输入字符 ‘清’, 状态转移至’清’: Base[0] + ‘清’.code = 1 + 7 = 8.
- 输入字符 ‘中’,状态转移至’清中’:Base[‘清’] + ‘中’.code = 3 + 1 = 4.
- Base[‘清中’]不为空, 可能是一个词, 需要与Check数组比较确认.
- Check[‘清中’] = 0 = Base[0] != Base[‘清’],所以"清中"不存在.
词尾的逻辑判断
我们再来匹配一个词’清华中’,在其过程如下:
- 起始状态0: Base[0] = 1;
- 输入字符 ‘清’, 状态转移至 ‘清’:
- 输入字符 ‘华’,状态转移至 ‘清华’:
- 输入字符 ‘中’,状态转移至 ‘清华中’:
- Base[清华中]不为空, 可能是一个词, 需要与Check数组比较确认.
- Check[清华中] = X = Base[清华], 所以"清华中"是一个词
显然上面的结论也是错误的,因为在我们的假设词典里并没有词"清华中"。所以仅仅在Base数组里存放一个非空值并且在Check数组保存上一状态,也还是不够的。
逻辑也是很简单的:通常做法是用一个负值标志词尾,就是把对应的数字变成负数,在base数组或者check数组中操作都行。
我们再来匹配一个词’清华中’,在其过程如下:
- 起始状态0: Base[0] = 1;
- 输入字符 ‘清’, 状态转移至 ‘清’:
- 输入字符 ‘华’,状态转移至 ‘清华’:
- 输入字符 ‘中’,状态转移至 ‘清华中’:
- Base[清华中]不为空, 可能是一个词, 需要与Check数组比较确认.
- Check[清华中] = X = Base[清华], 但是 X > 0,所以不是一个完整的词。
手撕了双数组的data-trie的代码:
打印结果如下
# 代表了每个汉字的编码值
{中=1, 人=2, 华=3, 大=4, 学=5, 新=6, 清=7}
# 每个层级的对应base和check值
----------------------------------------------------
word null null [中] null [华] null null null [清] null null null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 1 0 1 0 0 0 1 0 0 0 0
check -1 -1 0 -1 0 -1 -1 -1 0 -1 -1 -1 -1
----------------------------------------------------
word null null [中] 华[人] [华] 中[华] 清[华] null [清] 清[新] null null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 2 1 1 2 3 0 3 3 0 0 0
check -1 -1 0 4 0 2 8 -1 0 8 -1 -1 -1
----------------------------------------------------
word null null [中] 华[人] [华] 中[华] 清[华] 清华[大] [清] 清[新] null null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 2 1 1 2 3 3 3 3 0 0 0
check -1 -1 0 4 0 2 8 6 0 8 -1 -1 -1
----------------------------------------------------
word null null [中] 华[人] [华] 中[华] 清[华] 清华[大] [清] 清[新] 清华大[学] null null
Position 0 1 2 3 4 5 6 7 8 9 10 11 12
base 1 0 2 -1 1 -2 -3 5 3 -3 -5 0 0
check -1 -1 0 4 0 2 8 6 0 8 7 -1 -1



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











