






最近一直在搞Mac虚拟机,尝试了parallel、vmware、utm,感觉效果都不是很好,踩了了很多很多坑,parallel破解直接劝退我,并且也不是很稳定;wmware for m1刚开始装了一次挺不错的,但是因为我集群磁盘太小扩展磁盘大小的时候,系统就这样崩了,不管最后怎么装都没有用;最后我转战utm,刚开始因为不熟悉utm也踩了很多坑,弃了一段时间,vmware实在装不了了,我又来找utm了【utm yyds 轻便又好用又不花钱(后续发现的问题是容易闪退),推荐mac m1用户使用】。
ps:建议utm只装3台主机,我装了4台会有闪退的问题,之后我delete掉一台目前还没出现闪退的问题。
写在前面:
我的镜像:链接: https://pan.baidu.com/s/1EKf4hX3ODreDnrLp02t8cw 提取码: aek0
utm:链接: https://pan.baidu.com/s/1vj6EB2iq4dlxJqiHK2hoyQ 提取码: 5kd0
utm
镜像下载完,utm直接打开,新建虚拟机,设置一下系统参数。
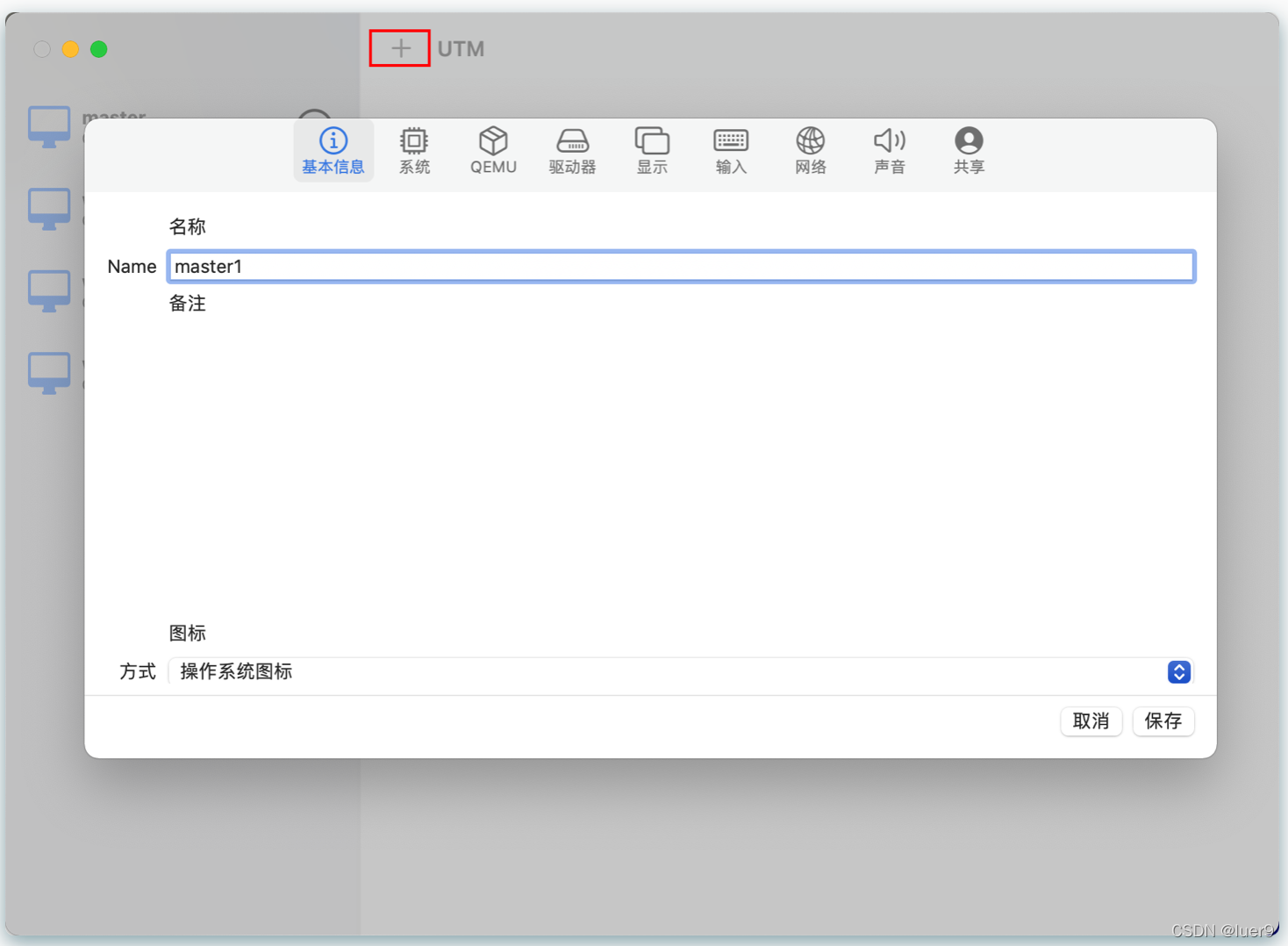
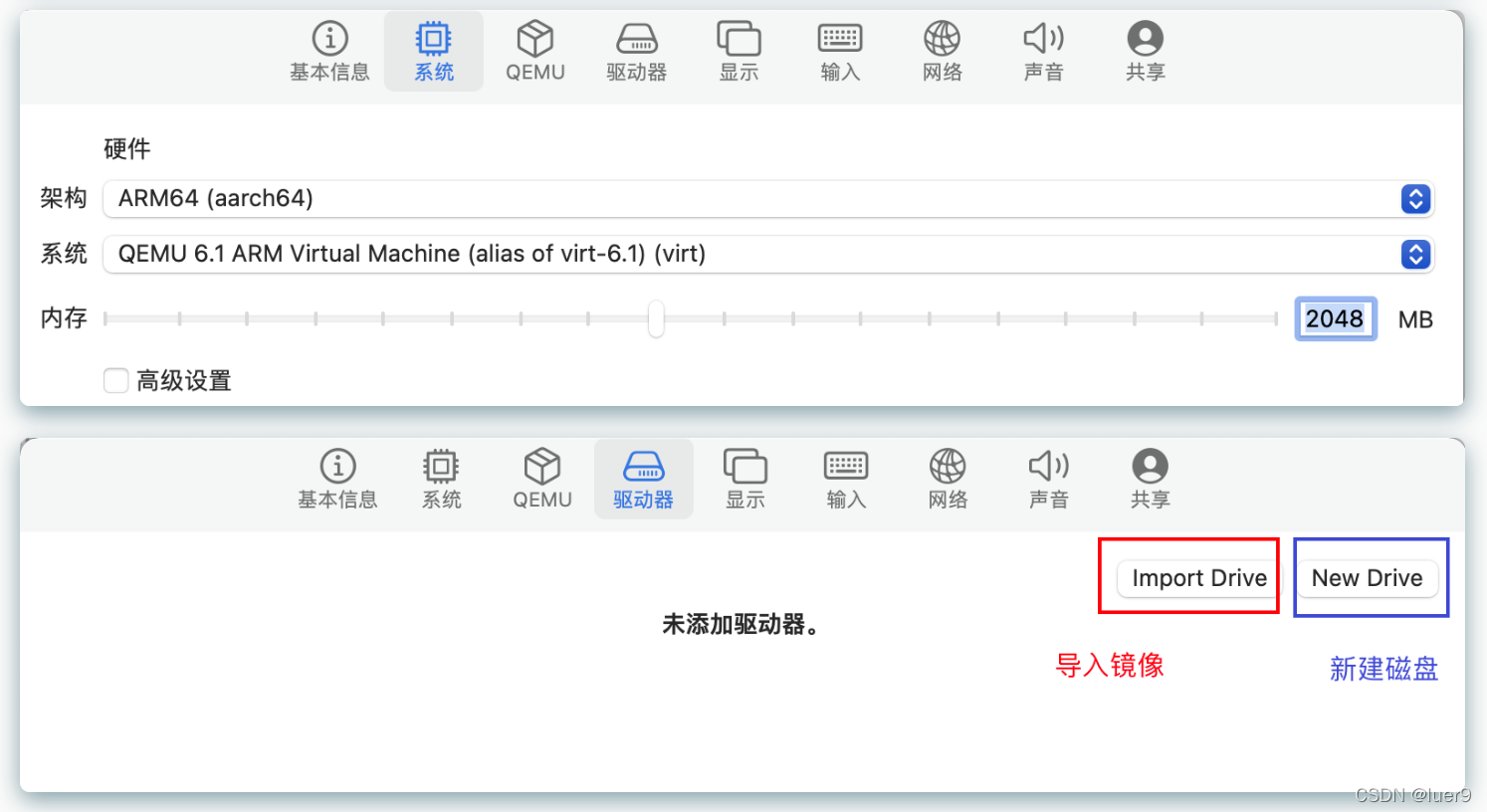
磁盘大小自己按照需要来,我刚开始搞的20g,根本就不够,我这次扩展到40g
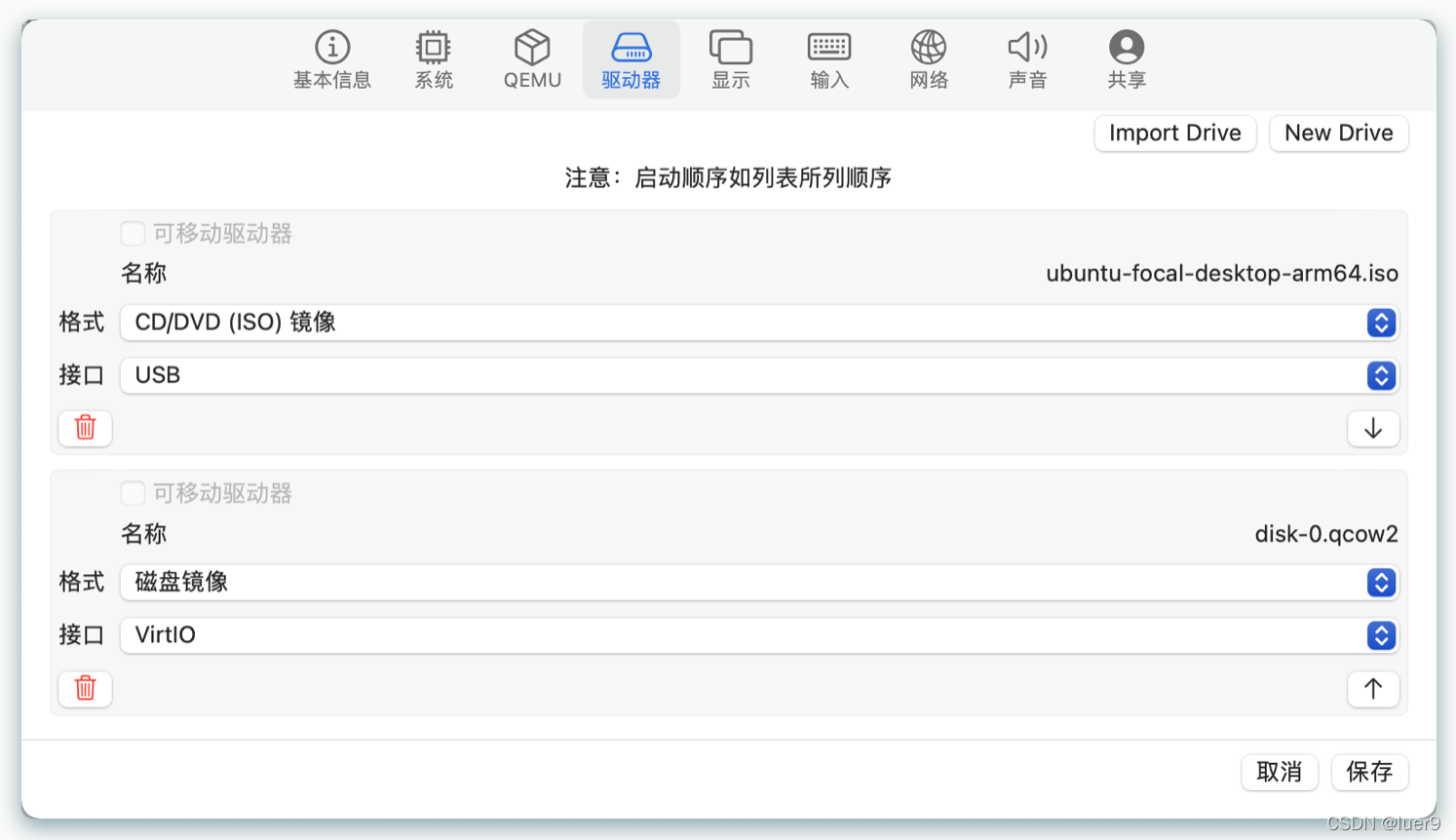
其他没什么要改的了。新建之后打开虚拟机进行安装就行了。
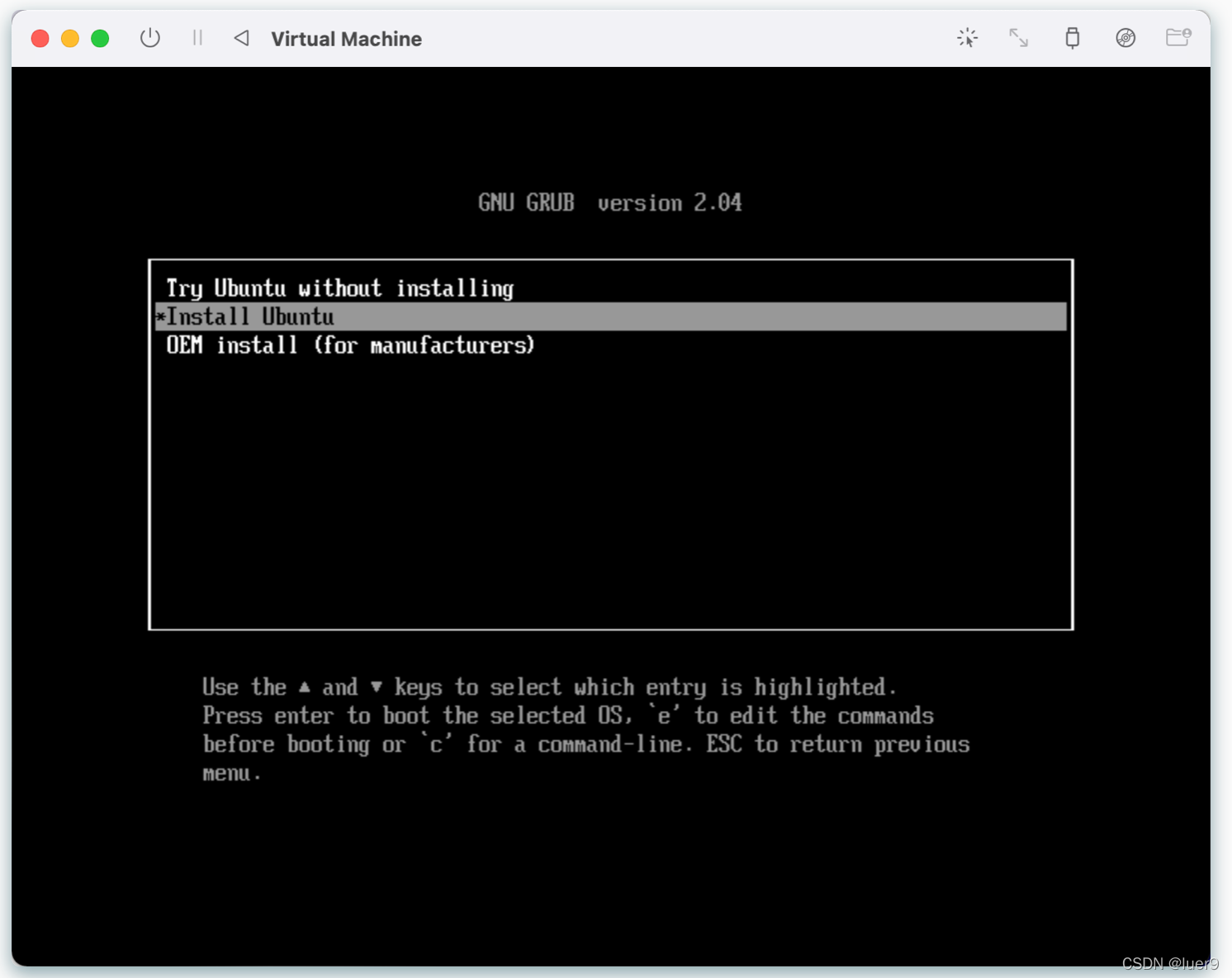
进入到桌面安装教程,按照自己的需要来。
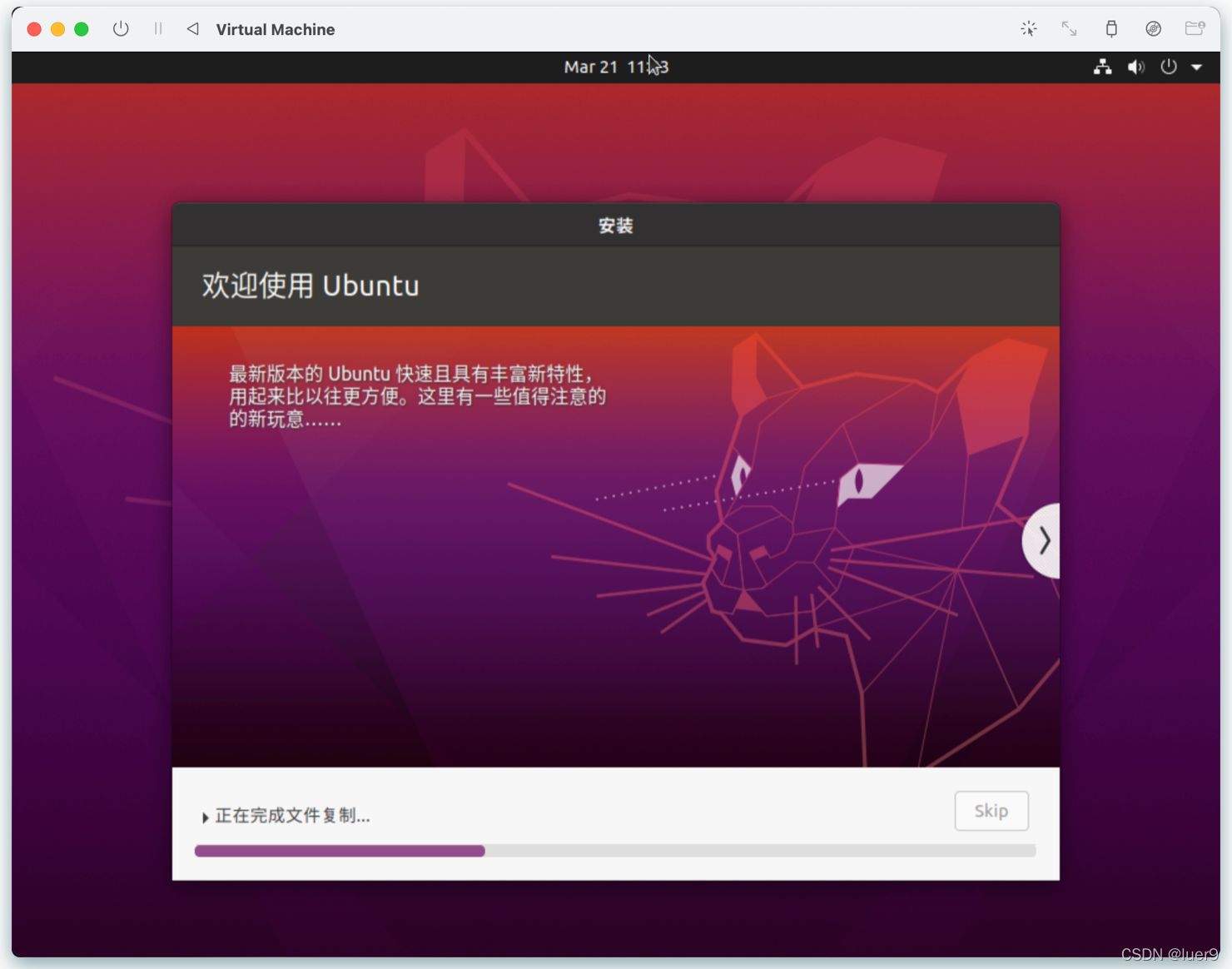
之后会要求你重启,这时候我们点击重新启动。系统直接黑屏了,也没有启动的迹象,这时候,不要慌,咱点击左上角的这个按钮。
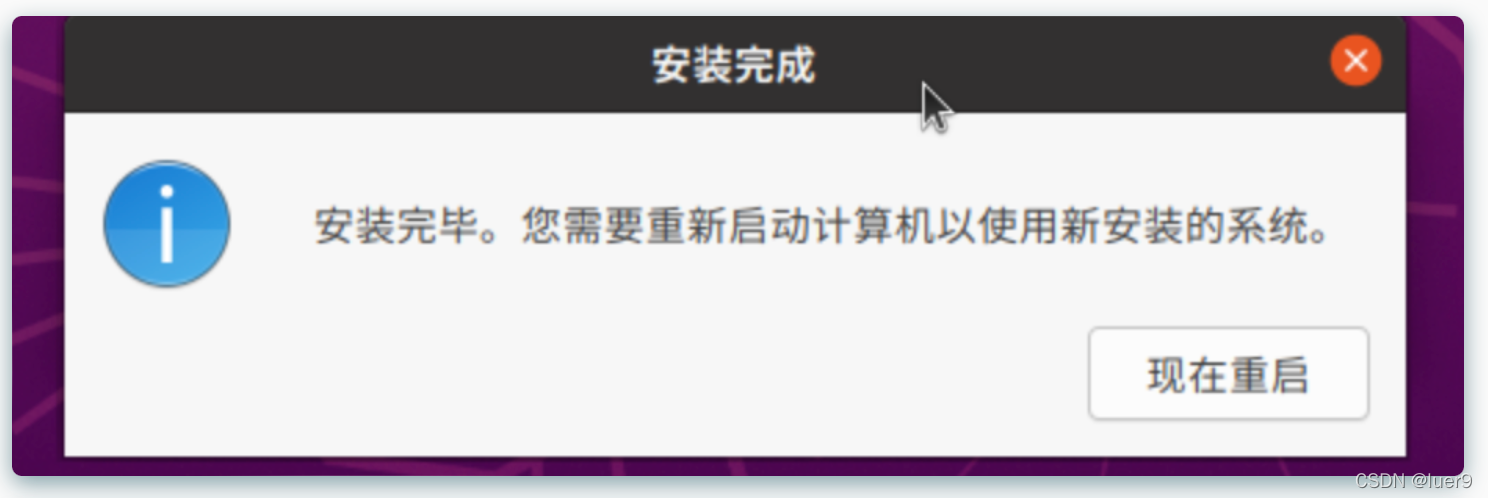
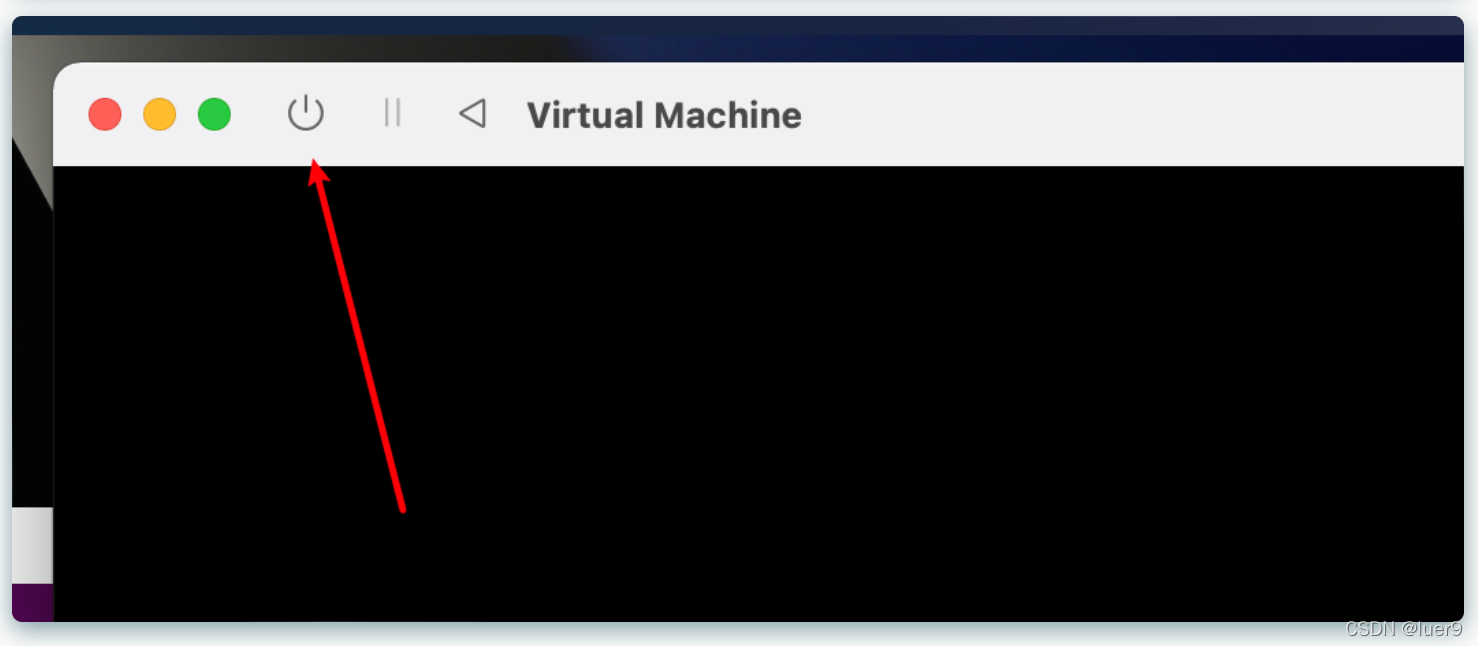
关机之后,咱需要把之前导入的镜像删除,不然会一直重复安装ubuntu【这其实跟u盘安装windows一个道理】。
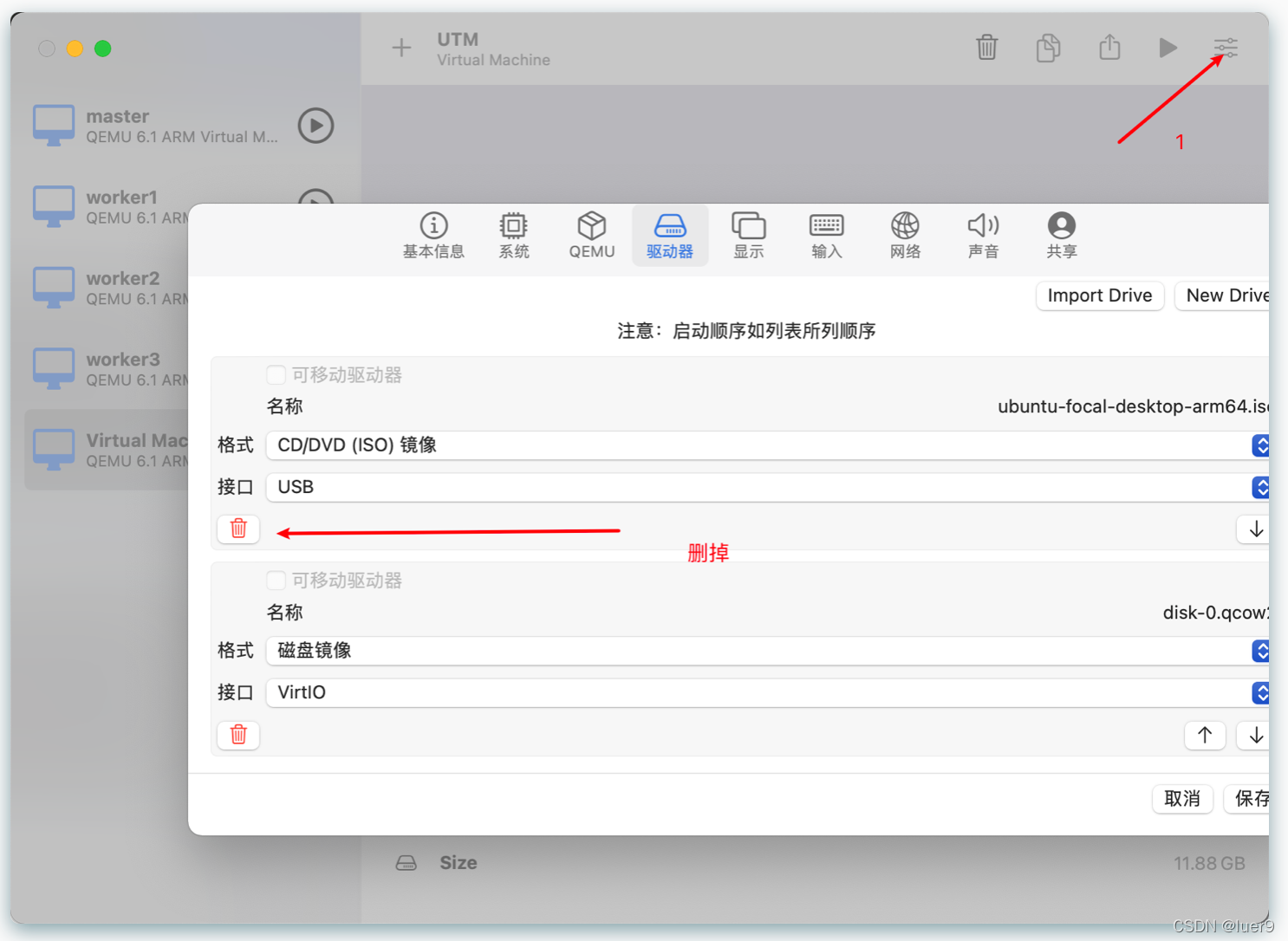
然后再启动虚拟机就可以咯,出现红框下面的就代表成功了哦。
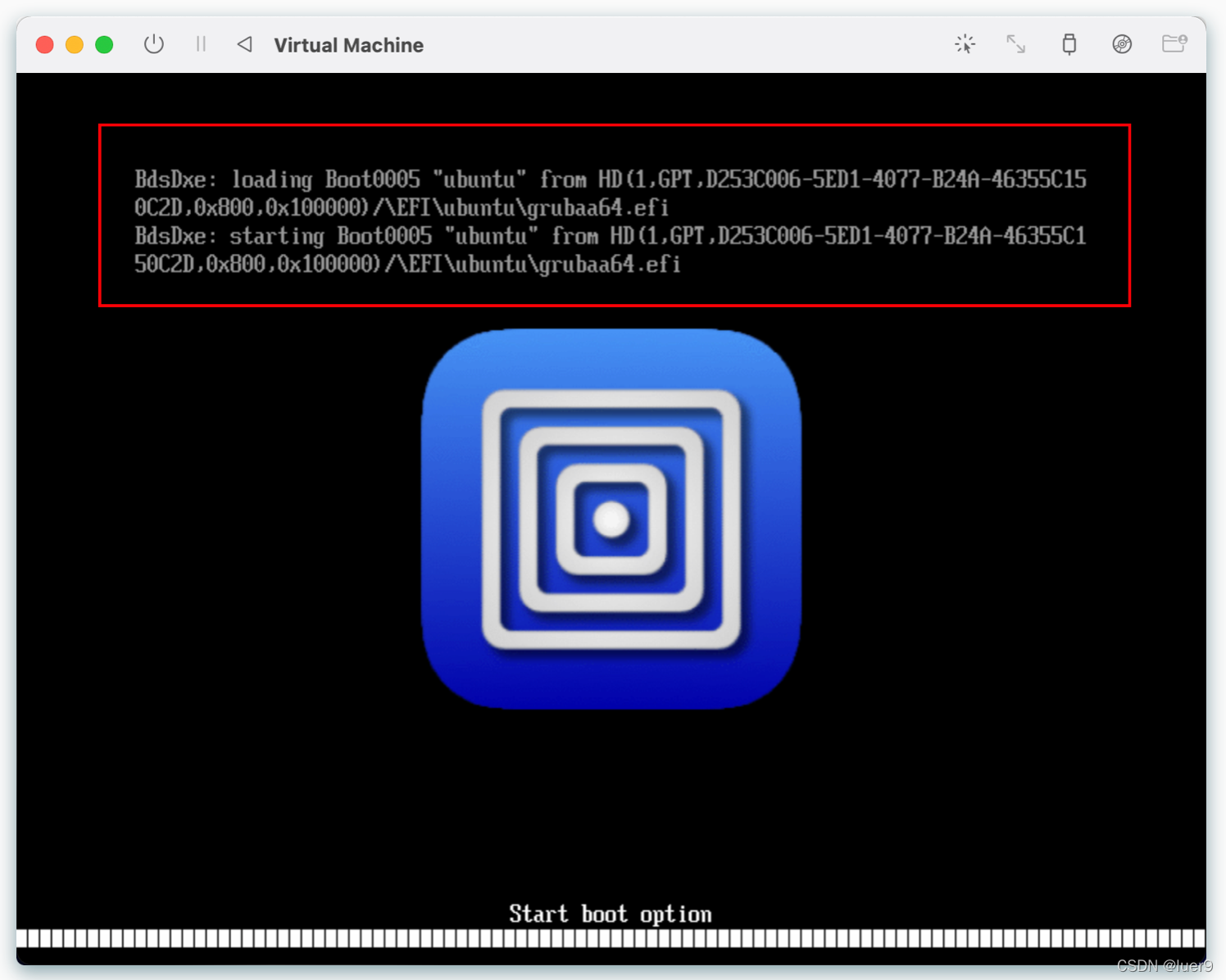
大功告成!在mac m1虚拟机上面花费的时候特别多,一直没有找到合适的,utm目前是最稳定的,完成的教程写在前面,希望我的教程可以节约大家的时间。
集群搭建
集群节点情况:
Master: 50G,其他worker:40G
master:192.168.64.9
worker1:92.168.64.10
worker2:192.168.64.11
所需安装包:
链接: https://pan.baidu.com/s/1_ldD55oaomnNgDPgvXxz9A 提取码: mqia
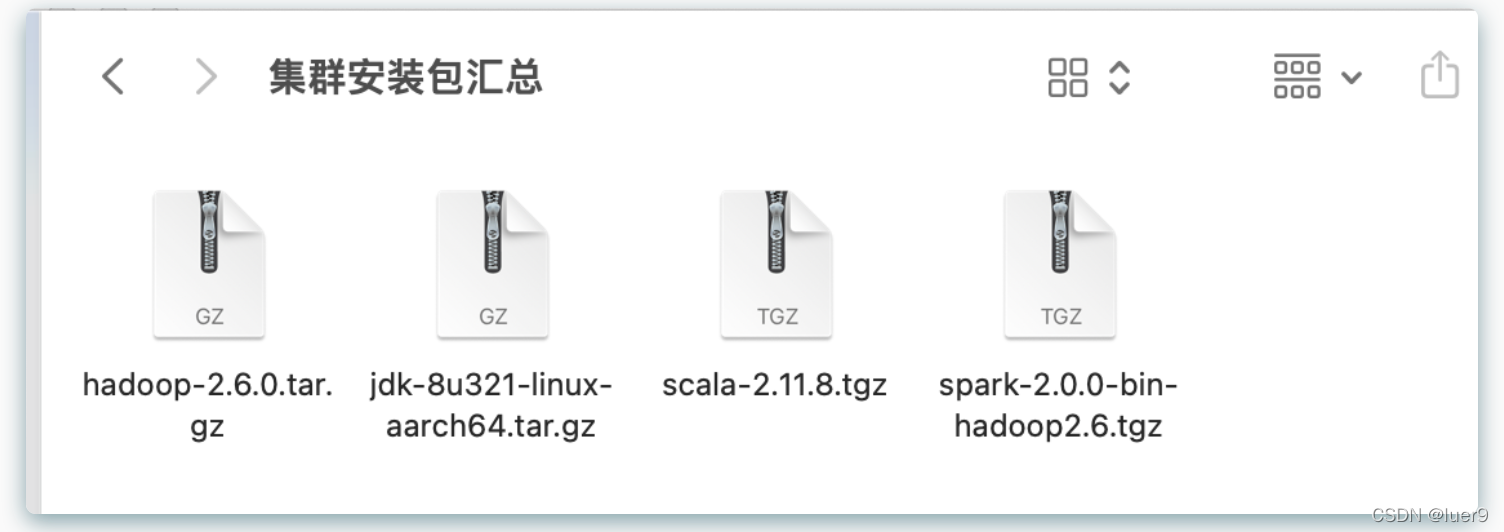
ps:我这jdk是arm版本的哦,安装的时候注意自己电脑的系统架构,但是如果是m1芯片那就没问题。
安装ssh(所有节点)
sudo apt install openssh-server
测试一下:ssh localhost能通就行。
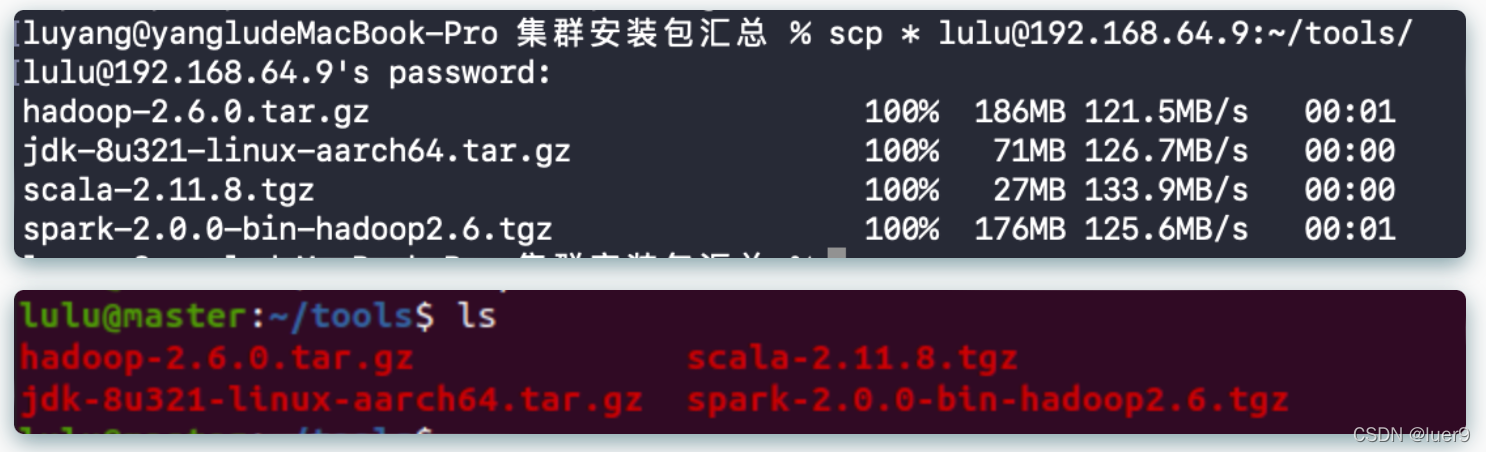
接下来将所有所需的安装包提前scp给master
scp * lulu@192.168.64.9:~/tools/
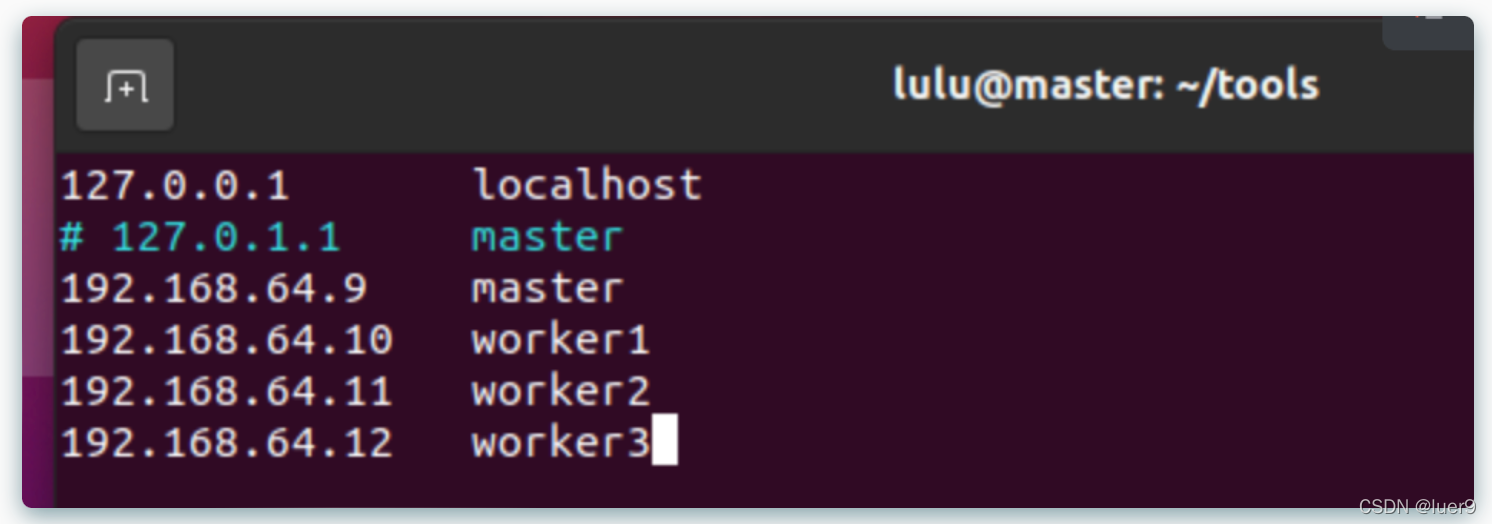
绑定ip
- 修改/etc/hosts,添加master与worker的ip绑定,并且注释127.0.0.1 master(不然会影响集群,或者改成 128.0.0.1)【三台机子都要做】
我在装worker端时hostname已经指定好了,所以不需要再修改hostname计算机名。如果有差异的话修改/etc/hostname。
免密登陆
master端
-
用rsa生成密钥,一路回车
ssh-keygen -t rsa -
进入.ssh目录,将公钥追加到authorized_keys
cat id_rsa.pub >> authorized_keys -
登陆其他主机,将其他主机的公钥内容都拷贝到master主机的authorized_keys中
ssh-copy-id -i master
这样master主机中就有了所有的公钥。
-
修改authorized_keys权限
chmod 600 authorized_keys -
将该文件拷贝到worker主机中
scp authorized_keys worker1:~/.ssh/
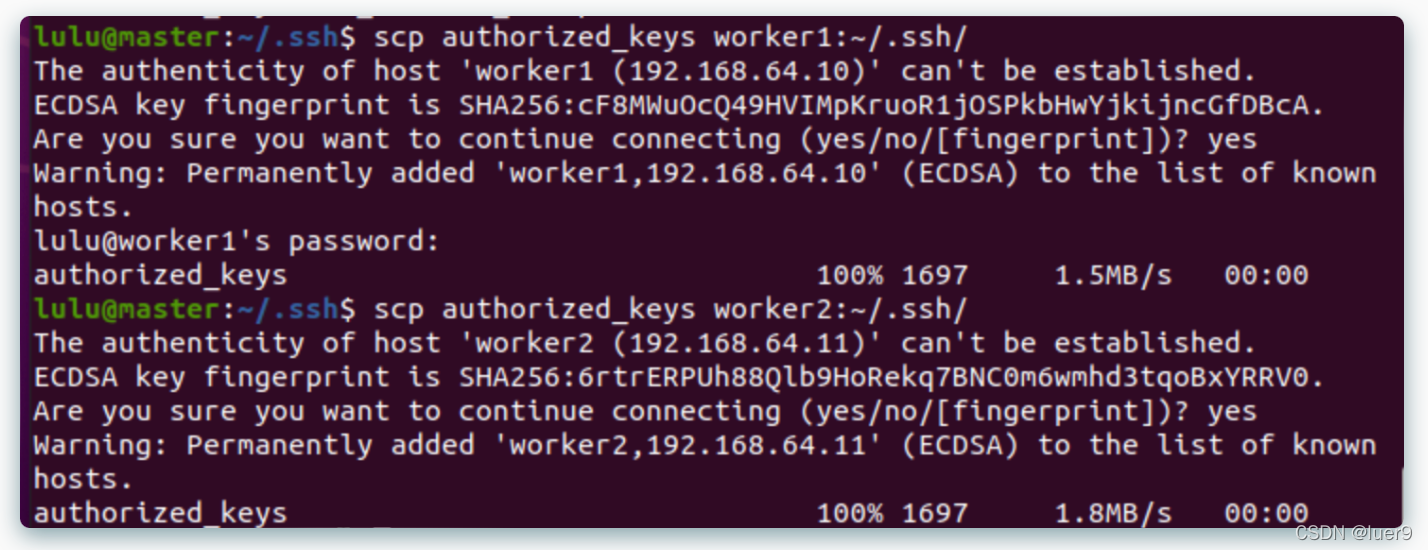
ssh免密登陆搞定!
hadoop集群搭建
jdk安装
-
解压
tar -zxvf jdk-8u321-linux-aarch64.tar.gz -C ~/dev
创建软链接(类似起了个别名)
ln -s jdk1.8.0_321/ jdk1.8
-
配置环境变量(用户级别)
vim ~/.bashrc# jdk export JAVA_HOME=/home/lulu/dev/jdk1.8 export JRE_HOME=/home/lulu/dev/jdk1.8/jre export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$JAVA_HOME/bin:$PATH -
更新环境变量
source ~/.bashrc -
检查
java -version

hadoop
-
解压
tar -zxvf hadoop-2.6.0.tar.gz -C ~/dev
创建软链接
ln -s hadoop-2.6.0/ hadoop
在hadoop主目录下:
mkdir tmp
mkdir dfs
mkdir dfs/name
mkdir dfs/node
mkdir dfs/data
-
hadoop配置
以下操作都在hadoop/etc/hadoop下进行。

-
编辑hadoop-env.sh文件,修改JAVA_HOME环境配置
# export JAVA_HOME=${JAVA_HOME} export JAVA_HOME=/home/lulu/dev/jdk1.8 -
编辑core-site.xml文件
master是主机名
hadoop.tmp.dir是刚刚创建的tmp文件夹/home/lulu/dev/hadoop/tmp
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/lulu/dev/hadoop/tmp</value> <description>Abasefor other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.spark.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.spark.groups</name> <value>*</value> </property> </configuration> -
编辑hdfs-site.xml文件
master是主机名
dfs.namenode.name.dir;dfs.namenode.data.dir是刚刚创建的文件夹:
/home/lulu/dev/hadoop/dfs/name
/home/lulu/dev/hadoop/dfs/data
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/lulu/dev/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/lulu/dev/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration> -
编辑mapred-site.xml文件
复制该文件并且重命名
cp mapred-site.xml.template mapred-site.xml<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration> -
编辑yarn-site.xml文件
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8035</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property> </configuration> -
修改slaves文件,添加集群节点
master worker1 worker2
-
-
hadoop集群搭建
将配置的hadoop以及jdk以及环境变量文件都传送给其他worker。
我的dev里面包含了hadoop以及jdk的文件夹噢。
scp -r dev lulu@worker1:~/ scp -r dev lulu@worker2~/看看worker1文件,检查传过来了没有,发现软链接不见了,文件夹都是两份,咱删除一份就行了,删除hadoop-2.6.0 jdk1.8.0_321,
后续启动的时候会说找不到hadoop-2.6.0/xxx文件,所以我们需要再建立hadoop-2.6.0软链接
ln -s hadoop hadoop-2.6.0。

scp -r .bashrc lulu@worker1:~/ scp -r .bashrc lulu@worker2:~/之后在每个主机更新一下环境变量就行
source ~/.bashrc。 -
hadoop集群启动
-
先格式化文件系统,在hadoop/bin下进行
lulu@master:~/dev/hadoop/bin$ ./hadoop namenode -format -
启动hadoop,在hadoop/sbin下进行
lulu@master:~/dev/hadoop/sbin$ ./start-all.sh出现下列信息,启动成功。
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 22/03/21 15:43:56 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [master] master: starting namenode, logging to /home/lulu/dev/hadoop-2.6.0/logs/hadoop-lulu-namenode-master.out master: starting datanode, logging to /home/lulu/dev/hadoop-2.6.0/logs/hadoop-lulu-datanode-master.out worker1: starting datanode, logging to /home/lulu/dev/hadoop/logs/hadoop-lulu-datanode-worker2.out worker2: starting datanode, logging to /home/lulu/dev/hadoop/logs/hadoop-lulu-datanode-worker2.out Starting secondary namenodes [master] master: starting secondarynamenode, logging to /home/lulu/dev/hadoop-2.6.0/logs/hadoop-lulu-secondarynamenode-master.out 22/03/21 15:44:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable starting yarn daemons starting resourcemanager, logging to /home/lulu/dev/hadoop-2.6.0/logs/yarn-lulu-resourcemanager-master.out worker1: starting nodemanager, logging to /home/lulu/dev/hadoop/logs/yarn-lulu-nodemanager-worker2.out master: starting nodemanager, logging to /home/lulu/dev/hadoop-2.6.0/logs/yarn-lulu-nodemanager-master.out worker2: starting nodemanager, logging to /home/lulu/dev/hadoop/logs/yarn-lulu-nodemanager-worker2.out

-
-
hadoop集群检查
- 8088端口
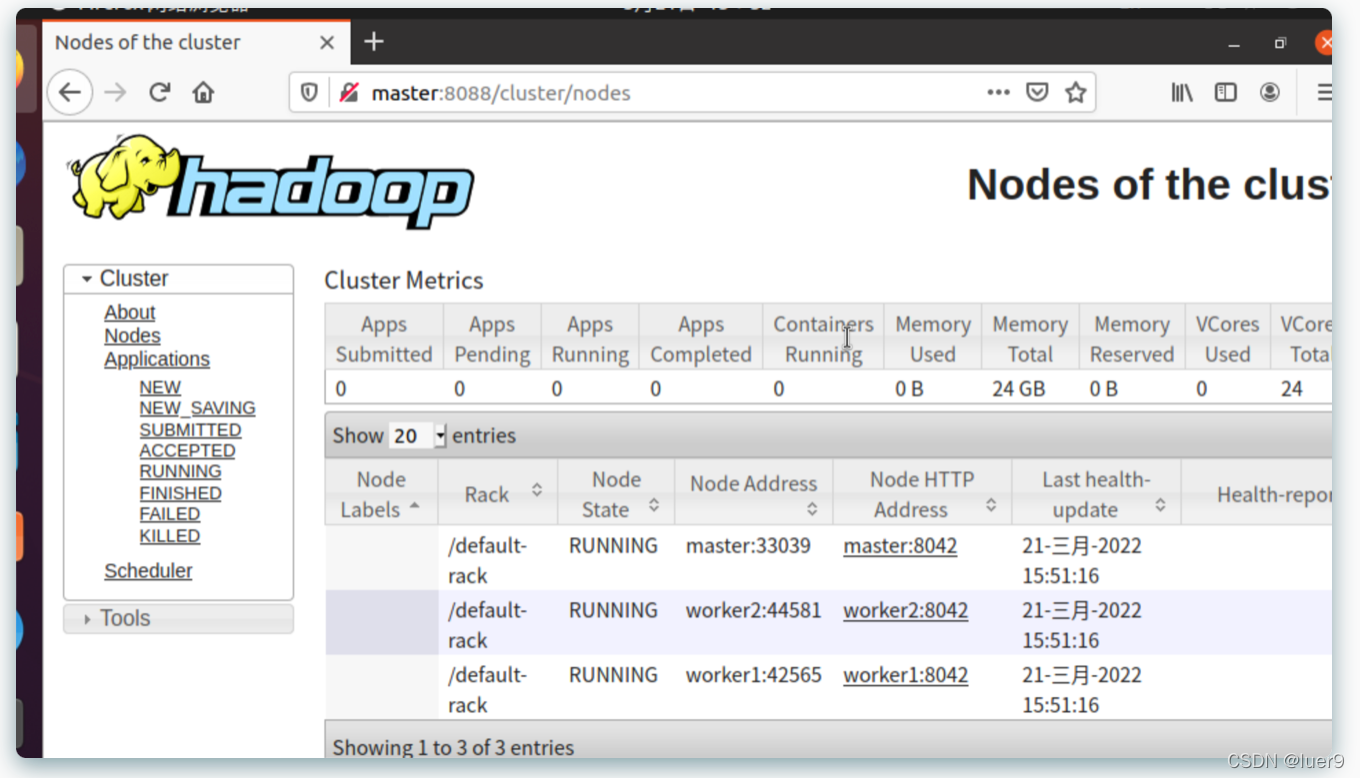
- 50070端口
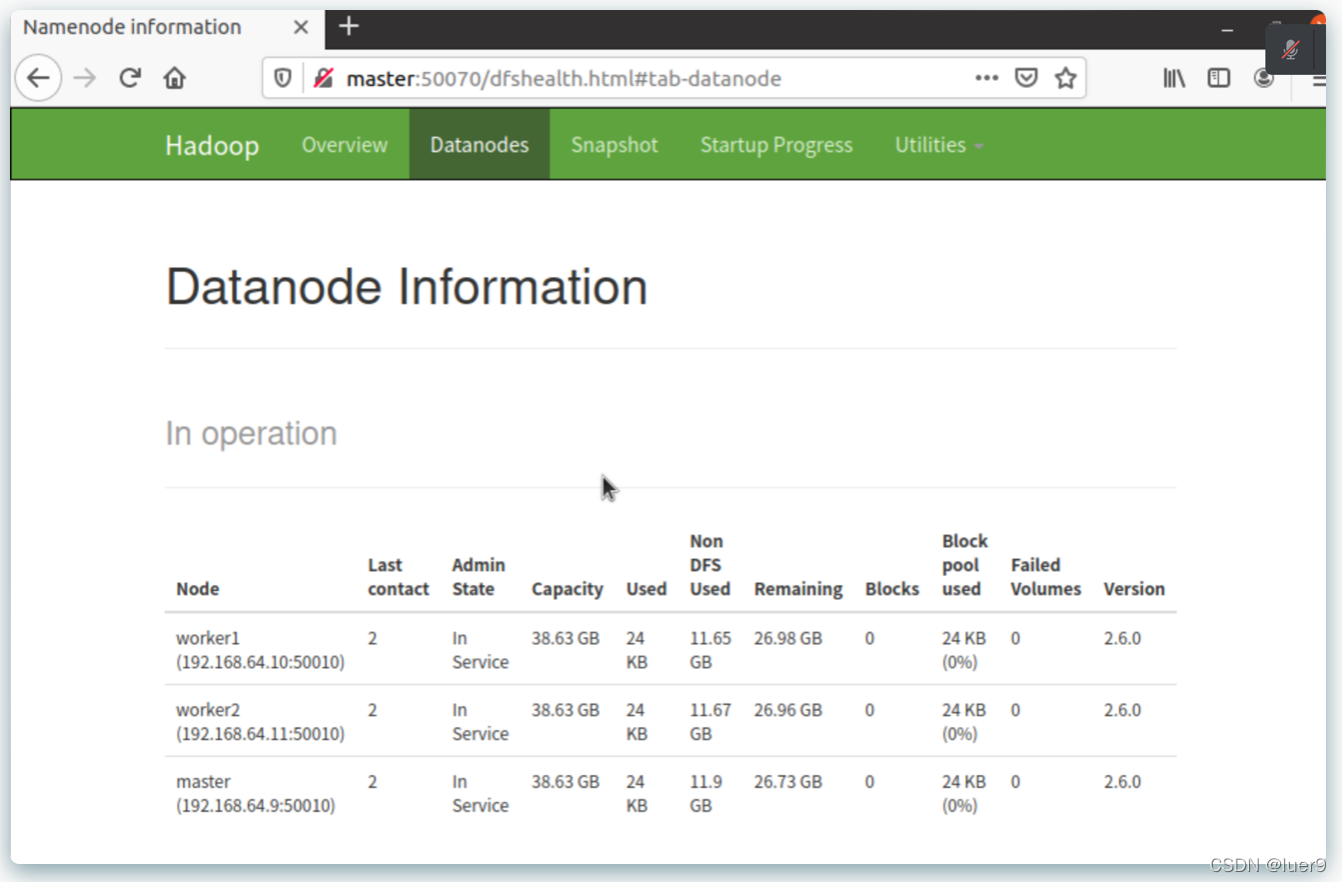
- 8088端口
spark集群搭建
scala安装
tar -zxvf scala-2.11.8.tgz -C ~/dev
建立软链接:ln -s scala-2.11.8/ scala
配置环境变量
# scala
export SCALA_HOME=/home/lulu/dev/scala
export PATH=$JAVA_HOME/bin:$SCALA_HOME/bin:$PATH
spark安装
tar -zxvf spark-2.0.0-bin-hadoop2.6.tgz -C ~/dev/
建立软链接:ln -s spark-2.0.0-bin-hadoop2.6/ spark
配置环境变量
# spark
export SPARK_HOME=/home/lulu/dev/spark
export PATH=$JAVA_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$PATH
spark配置
进入spark下的conf文件中
-
复制spark-env
cp spark-env.sh.template spark-env.sh -
编辑spark-env.sh
export JAVA_HOME=/home/lulu/dev/jdk1.8 export SPARK_MASTER_IP=master export SPARK_WORKER_MEMORY=8g export SPARK_WORKER_CORES=4 export SPARK_EXECUTOR_MEMORY=4g export HADOOP_HOME=/home/lulu/dev/hadoop export HADOOP_CONF_DIR=/home/lulu/dev/hadoop/etc/hadoop export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/lulu/dev/jdk1.8/jre/lib/amd64 -
编辑slaves
cp slaves.template slaves master worker1 worker2
spark配置集群
将spark以及scala以及环境变量都scp到其他节点
scp -r spark-2.0.0-bin-hadoop2.6/ lulu@worker1:~/dev
scp -r spark-2.0.0-bin-hadoop2.6/ lulu@worker2:~/dev
scp -r scala-2.11.8/ lulu@worker1:~/dev
scp -r scala-2.11.8/ lulu@worker2:~/dev
scp -r .bashrc lulu@worker1:~/
scp -r .bashrc lulu@worker2:~/
对穿过去的文件建立软链接,并且更新环境变量。
spark集群启动
在spark/sbin下进行
./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/lulu/dev/spark/logs/spark-lulu-org.apache.spark.deploy.master.Master-1-master.out
worker2: starting org.apache.spark.deploy.worker.Worker, logging to /home/lulu/dev/spark/logs/spark-lulu-org.apache.spark.deploy.worker.Worker-1-worker2.out
worker1: starting org.apache.spark.deploy.worker.Worker, logging to /home/lulu/dev/spark/logs/spark-lulu-org.apache.spark.deploy.worker.Worker-1-worker1.out
master: starting org.apache.spark.deploy.worker.Worker, logging to /home/lulu/dev/spark/logs/spark-lulu-org.apache.spark.deploy.worker.Worker-1-master.out
master、worker都已经启动。👌
spark集群检查
- 8080端口
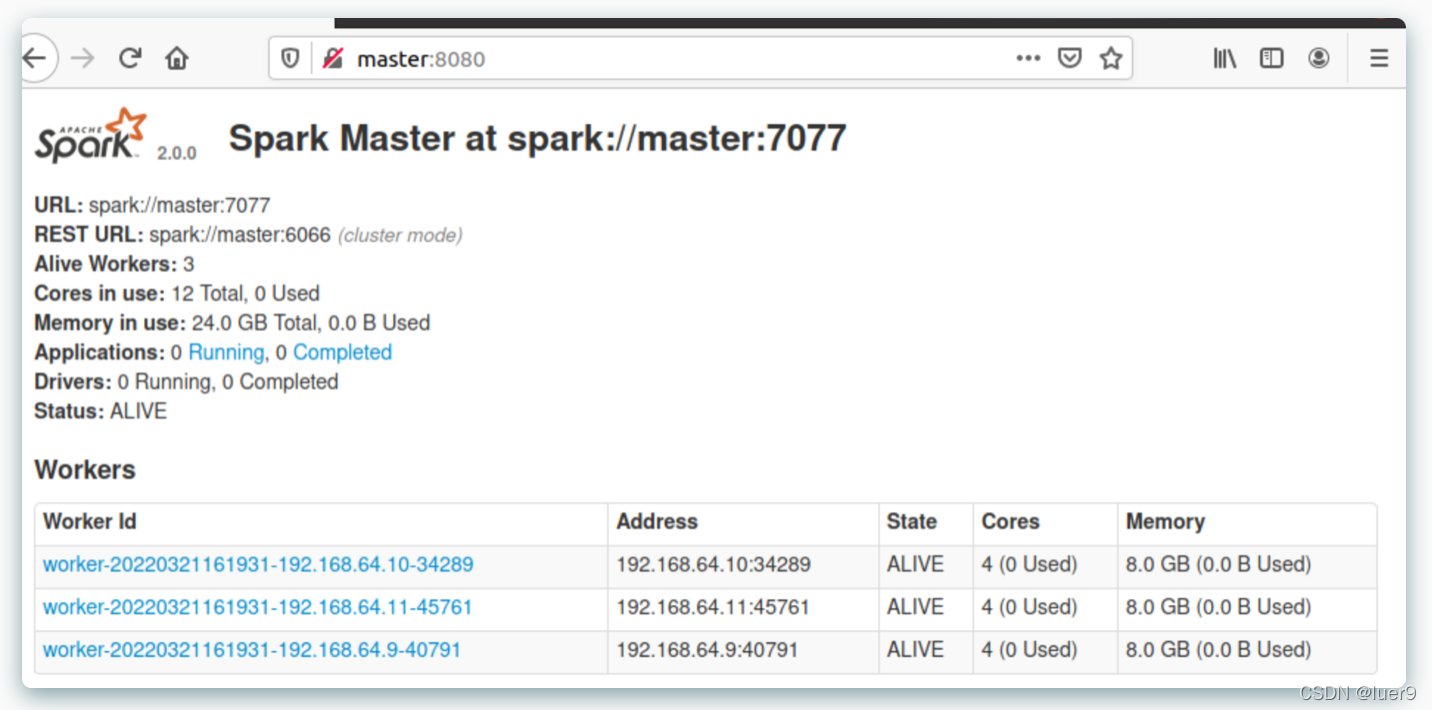
集群搭建到此为止。














 5474
5474











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









