







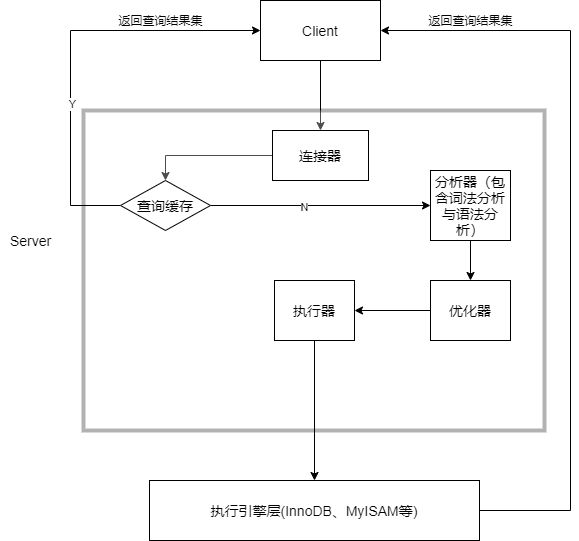
一条SQL查询语句的执行流程分析
-
连接器负责跟客户端建立连接、获取权限、维持和管理连接(mysql -h h o s t − P host -P host−Pport -u$user -p)
-
查询缓存
-
分析器对SQL语句进行词法分析和语法分析
-
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序
-
执行器执行流程:
- 调用存储引擎接口取这个表的第一行,判断条件字段是不是所查询的值,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
一条SQL更新语句的执行流程
更新语句除了与查询语句都经历了相同的流程外,还需要进行两个重要的日志模块(redolog和binlog)的操作。
重做日志(redolog)
为什么强调是重做日志呢?
因为重做日志对于InnoDB存储引擎至关重要,它记录了对于InnoDB存储引擎事务日志。当实例或介质失败时,重做日志文件就能派上用场。例如,数据库由于所在主机掉电导致实例失败,InnoDB存储引擎会使用重做日志恢复到掉电前的时刻,以此来保证数据的完整性。
每个InnoDB存储引擎至少有1个重做日志文件组,每个文件组下至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。为了得到更高的可靠性,用户可以设置多个镜像日志组,将不同的文件组放在不同的磁盘上,以此提高重做日志的高可用性。在日志组中每个重做日志文件的大小一致,并以循环写入的方式运行。
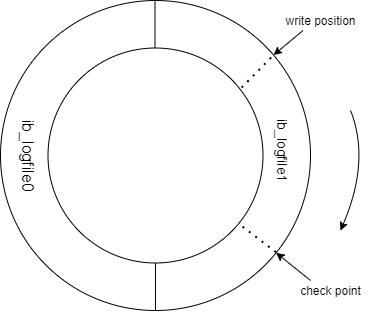
redolog日志循环写入方式,write position 表示当前写入位置,边写入边移动,check point表示当前要擦除的位置,边擦除边移动。write position和check point之间就是未被写入记录的空闲空间。
下列参数影响着重做日志文件的属性:
- innodb_log_file_size:每个重做日志文件的大小,默认为48M
- innodb_log_files_in_group:日志文件组中重做日志文件的数量,默认为2
- innodb_mirrored_log_groups:日志镜像文件组的数量
- innodb_log_group_home_dir:日志文件组所在路径,默认为./
重做日志文件的大小(innodb_log_file_size)设置对InnoDB的性能有着非常大的影响。如果设置的太大,在恢复时可能需要很长的时间;如果设置的太小,可能一个事务的日志需要切换多个日志文件。
参数innodb_flush_log_at_trx_commit的有效值有0、1、2。0表示当提交事务时,并不将事务的重做日志写入磁盘上的日志文件,而是等待主线程每秒刷新。1表示在执行commit时将重做日志缓冲同步写到磁盘,即伴有fsync的调用。2表示将重做日志异步写到磁盘,即写到文件系统的缓存中,因此无法完全保证在执行commit时肯定会写入重做日志,只是有这个动作发生。
最佳实践: 为了保证事务的ACID中的持久性,必须将innodb_flush_log_at_trx_commit设置为1
二进制日志(binlog)
这两种日志有以下三点不同。
- redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
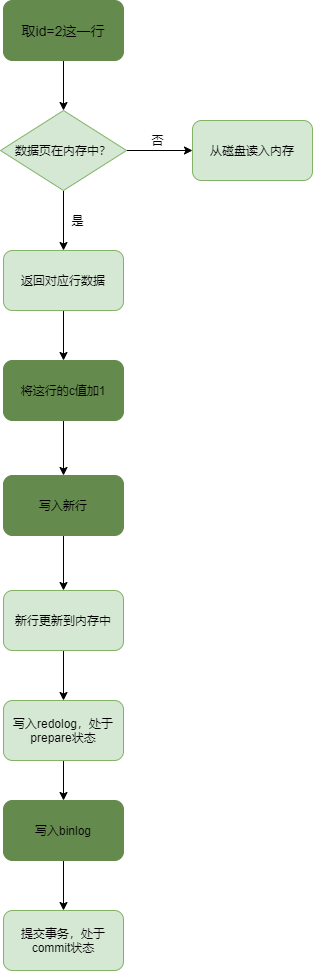
以一个简单的update语句为例:
create table t (
id int primary key,
c int
) engine=innodb, charset=utf8;
update t set c = c + 1 where id = 2;
两阶段提交
用前面的 update 语句来做例子。假设当前 ID=2 的行,字段 c 的值是 0,再假设执行 update 语句过程中在写完第一个日志后,第二个日志还没有写完期间发生了 crash,会出现什么情况呢?
-
先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完的时候,MySQL 进程异常重启。由于我们前面说过的,redo log 写完之后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。但是由于 binlog 没写完就 crash 了,这时候 binlog 里面就没有记录这个语句。因此,之后备份日志的时候,存起来的 binlog 里面就没有这条语句。然后你会发现,如果需要用这个 binlog 来恢复临时库的话,由于这个语句的 binlog 丢失,这个临时库就会少了这一次更新,恢复出来的这一行 c 的值就是 0,与原库的值不同。
-
先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。所以,在之后用 binlog 来恢复的时候就多了一个事务出来,恢复出来的这一行 c 的值就是 1,与原库的值不同。
可以看到,如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。
参考资料:
《MySQL实战45讲》
《MySQL技术内幕:InnoDB存储引擎》














 1761
1761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









