






目录
NLP-语法解析(2024.5.30)
1.NP:名词 VP:动词 PP:介词短语 AP:形容词短语(短语级别)
N:名词 V:动词 P:介词 A:形容词
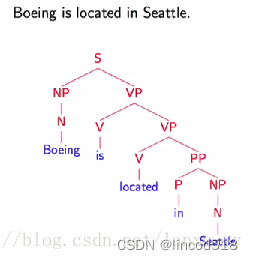
实际存储过程 (S(NP(N Boeing))(VP(V is)(VP(V located)(PP(P in)(NP(N Seattle))))))
上下文无关语法(Context-Free Grammer)
为了生成句子的语法树,我们可以定义如下的一套上下文无关语法。
1)S表示语法树开始的标注
2)N表示一组非叶子节点的标注,例如{S、NP、VP、N...}
3)Σ表示一组叶子结点的标注,例如{boeing、is...}
4)R表示一组规则,每条规则可以表示为X->Y1Y2...Yn,X∈N,Yi∈(N∪Σ)
举例来说,语法的一个语法子集可以表示为下图所示。当给定一个句子时,我们便可以按照从左到右的顺序来解析语法。例如,句子the man sleeps就可以表示为(S (NP (DT the) (NN man)) (VP sleeps))。

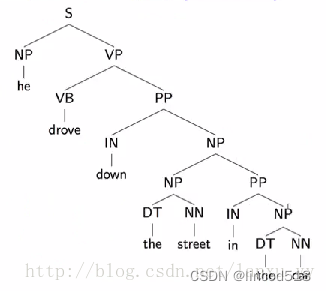
这种上下文无关的语法可以很容易的推导出一个句子的语法结构,但是缺点是推导出的结构可能存在二义性。下面两张图中的语法树都可以表示同一个句子。常见的二义性问题有:1)单词的不同词性,如can一般表示“可以”这个情态动词,有时表示冠词;2)介词短语的作用范围,如VP PP PP这样的结构,第二个介词短语可能形容VP,也可能形容第一个PP;3)连续的名字,如NN NN NN。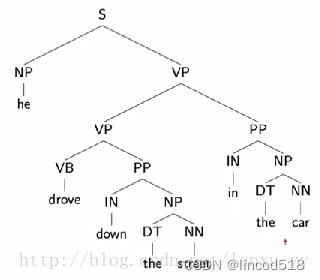
参照
NLP | 自然语言处理 - 语法解析_np,vp 和 pp-CSDN博客
NLP-文本匹配(2024.5.31)
文本匹配主要是将两段文本进行相似度计算,以选择最匹配的内容
经典相似匹配度算法有:Jaccard相似度,Levenshtein编辑距离,Simhash,TF-IDF等
Jaccard相似度
Jaccard相似度,是用于比较有限样本集合的相似性的统计量,定义为两个集合的交集与并集的比例。
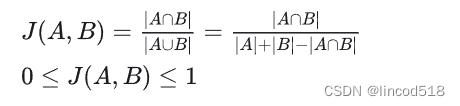
对应的Jaccard距离为:
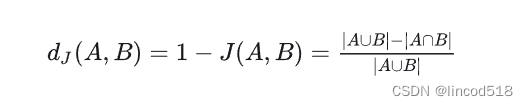
Simhash
Simhash是一种将文本hash编码之后,仍然能保持一定的相似度计算能力的hash编码。基本思路是将词进行hash编码后,得到64位01串,对每个词中0改为-1并对整体加权,最后将所有词求和作为句子的表示。
具体流程包括:
1. 分词。有意义则分词,否则直接分到字
2. hash。将词转为01串,如10101111
3. 加权。如果有单词的权重信息,则加权,如2 -2 2 -2 2 2 2 2
4. 合并。将句子的所有词求和
5. 降维。对合并后的结果中,>0的设置为1,<0的设置为0示例: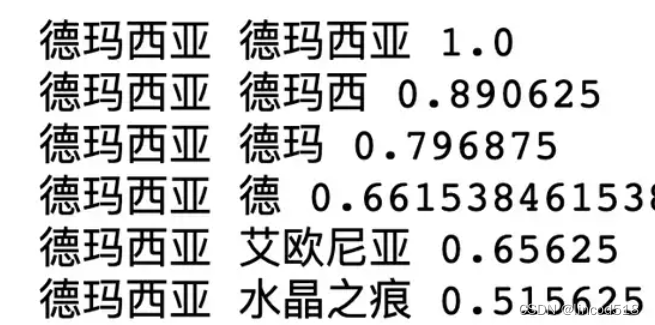
TF-IDF
这个用的还挺多挺常见的。TF-IDF是衡量一个文档集中每个文档中每个词的重要性。TF,一个词在当前文档中出现的次数越多越重要;IDF,文档集中,一个词出现的文档数越少越重要。 
在求文本相似度时,基本思路是找出字符串之间共现的词,并用tfidf做加权。即
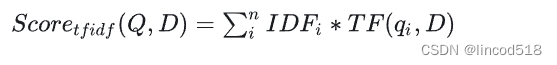
参照
https://zhuanlan.zhihu.com/p/349942043
NLP-文本生成(2024.6.2)
文本生成是自然语言处理的一部分,从知识库或逻辑形式等等机器表述系统去生成自然语言。生成文本的过程可以简单到取用已准备好的章句,再用连结的文字组合起来。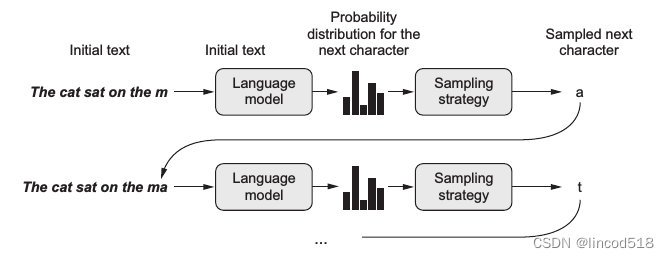
最成功的NLG应用是从数据库或资料集产生文字摘要的“资料转文本”系统,这些系统通常除了文字生成外,也进行资料分析,特别是几个已经建成的从气象资料产生气象报告文的系统。
更近的NLG也用于摘要电子医疗记录,研究人员已显示NLG摘要的医疗资料可以有效辅助医疗专业人员做决定。
NLG系统可以辅助真人作者,让写作过程更有效率。例如利用搜索引擎应用界面,基于网络探勘建立的内容生成工具[10],模拟作者根据各种搜寻结果形成内容,有如剪贴的写作场景。相关度的验证,对于过滤不相关的搜寻结果至为重要,方法基于匹配问题与可能答案的语法树[11]。另一种方法利用真人写的文本建立高层次结构的版型,然后自动写成维基百科新的条目[12]。
文本生成的核心概念
语言模型:用于预测下一个词语或字符的概率分布,是文本生成的基础。
上下文理解:文本生成需要理解输入的上下文,以生成与上下文相符的文本。
序列生成:文本生成是一种序列生成问题,需要生成连续的词语序列。
控制机制:文本生成需要控制生成的内容,例如生成的文本的长度、风格等。
NLG学习方法
学习SimlpeNLG
https://github.com/simplenlg/simplenlg
系统性入门学习NLP
GitHub - slshan/nlp_tutorial: NLP超强入门指南,包括各任务sota模型汇总(文本分类、文本匹配、序列标注、文本生成、语言模型),以及代码、技巧
复述生成和文本摘要可以说是归属于文本生成这个大类里面,所以里面很多方法是可以相通的。
参照https://zh.wikipedia.org/wiki/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E7%94%9F%E6%88%90
自然语言处理中的文本生成-CSDN博客

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











