







话说在尝试设置download_delay小于1,并且无任何其他防止被ban的策略之后,我终于成功的被ban了。
关于scrapy的使用可参见之前文章:
http://blog.csdn.net/u012150179/article/details/34913315
http://blog.csdn.net/u012150179/article/details/34486677
http://blog.csdn.net/u012150179/article/details/34441655
http://blog.csdn.net/u012150179/article/details/32911511
敌退我进,敌攻我挡。
本篇博客主要研究使用防止被ban的几大策略以及在scrapy中的使用。
1.策略一:设置download_delay
这个在之前的教程中已经使用过(http://blog.csdn.net/u012150179/article/details/34913315),他的作用主要是设置下载的等待时间,大规模集中的访问对服务器的影响最大,相当与短时间中增大服务器负载。
下载等待时间长,不能满足段时间大规模抓取的要求,太短则大大增加了被ban的几率。
使用注意:
download_delay可以设置在settings.py中,也可以在spider中设置,在之前博客中(http://blog.csdn.net/u012150179/article/details/34913315)已经使用过,这里不再过多阐述。
2.策略二:禁止cookies
所谓cookies,是指某些网站为了辨别用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密),禁止cookies也就防止了可能使用cookies识别爬虫轨迹的网站得逞。
使用:
在settings.py中设置COOKIES_ENABLES=False。也就是不启用cookies middleware,不想web server发送cookies。
3.策略三:使用user agent池
所谓的user agent,是指包含浏览器信息、操作系统信息等的一个字符串,也称之为一种特殊的网络协议。服务器通过它判断当前访问对象是浏览器、邮件客户端还是网络爬虫。在request.headers可以查看user agent。如下,使用scrapy shell查看:
- scrapy shell http://blog.csdn.net/u012150179/article/details/34486677
进而输入如下,可得到uesr agent信息:

由此得到,scrapy本身是使用Scrapy/0.22.2来表明自己身份的。这也就暴露了自己是爬虫的信息。
使用:
首先编写自己的UserAgentMiddle中间件,新建rotate_useragent.py,代码如下:
- # -*-coding:utf-8-*-
- from scrapy import log
- """避免被ban策略之一:使用useragent池。
- 使用注意:需在settings.py中进行相应的设置。
- """
- import random
- from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
- class RotateUserAgentMiddleware(UserAgentMiddleware):
- def __init__(self, user_agent=''):
- self.user_agent = user_agent
- def process_request(self, request, spider):
- ua = random.choice(self.user_agent_list)
- if ua:
- #显示当前使用的useragent
- print "********Current UserAgent:%s************" %ua
- #记录
- log.msg('Current UserAgent: '+ua, level='INFO')
- request.headers.setdefault('User-Agent', ua)
- #the default user_agent_list composes chrome,I E,firefox,Mozilla,opera,netscape
- #for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php
- user_agent_list = [\
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
- "(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
- "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
- "(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
- "(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
- "(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
- "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
- "(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
- "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
- "(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
- "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
- "(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
- "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
- "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
- "(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
- "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
- "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
- "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
- "(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
- ]
除此之外,要在settings.py(配置文件)中禁用默认的useragent并启用重新实现的User Agent。配置方法如下:
- #取消默认的useragent,使用新的useragent
- DOWNLOADER_MIDDLEWARES = {
- 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware' : None,
- 'CSDNBlogCrawlSpider.spiders.rotate_useragent.RotateUserAgentMiddleware' :400
- }
至此配置完毕。现在可以运行看下效果。
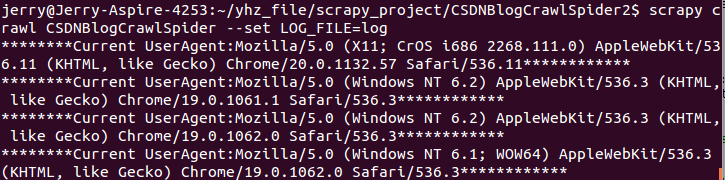
可以发现一直在变化的UserAgent。
4.策略四:使用IP池
web server应对爬虫的策略之一就是直接将你的IP或者是整个IP段都封掉禁止访问,这时候,当IP封掉后,转换到其他的IP继续访问即可。
可以使用Scrapy+Tor+polipo
配置方法与使用教程可参见:http://pkmishra.github.io/blog/2013/03/18/how-to-run-scrapy-with-TOR-and-multiple-browser-agents-part-1-mac/。有时间我会翻译过来。
5.策略五:分布式爬取
这个,内容就更多了,针对scrapy,也有相关的针对分布式爬取的GitHub repo。可以搜一下。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









