







Maven配置
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- mybatisplus依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.22</version>
</dependency>
<!-- shardingJDBC核心依赖 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
</dependencies>
inline模式
配置文件
#各种分库分表策略
#配置多个数据源
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/student?serverTimezone=UTC
username: root
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/course?serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
course:
# 指定表的分布情况 配置表在哪个数据库里,表名是什么。水平分表,分到两个库两个表: m1.course_1,m1.course_2
actual-data-nodes: m$->{1..2}.course_$->{1..2}
# 指定表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
#使用inline:分库的策略
database-strategy:
inline:
sharding-column: id
algorithm-expression: m$->{id%2+1}
#使用inline: 指定分片策略 约定cid值为偶数添加到course_1表。如果是奇数添加到course_2表。
#选定计算的字段
table-strategy:
inline:
sharding-column: id
# 根据计算的字段算出对应的表名。
algorithm-expression: course_$->{((id+1)%4).intdiv(2)+1}
# 打开sql日志输出。
props:
sql.show: true # 控制台打印SQL
实体类
package com.example.demosh.entity;
public class Course {
private Long id;
private String name;
private Integer userId;
private int cstatus;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public int getCstatus() {
return cstatus;
}
public void setCstatus(int cstatus) {
this.cstatus = cstatus;
}
@Override
public String toString() {
return "course{" +
"id=" + id +
", name='" + name + '\'' +
", userId=" + userId +
", cstatus=" + cstatus +
'}';
}
}
mapper
@Mapper
public interface CourseMapper extends BaseMapper<Course> {
}
测试类
package com.example.demosh;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.example.demosh.entity.Course;
import com.example.demosh.mapper.CourseMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class DemoshApplicationTests {
@Autowired
private CourseMapper courseMapper;
@Test
void contextLoads() {
for (int i = 1 ; i <= 10 ; i++){
Course course = new Course();
course.setId(Long.valueOf(Integer.toString(i)));
course.setName("name"+i);
course.setUserId(1);
course.setCstatus(1);
courseMapper.insert(course);
}
}
}
效果
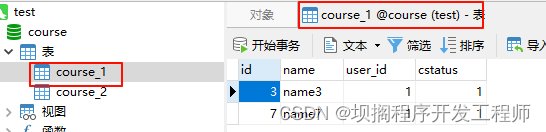
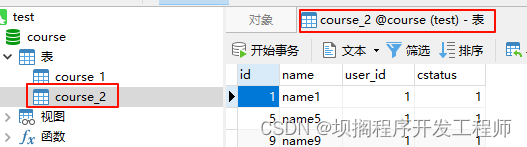
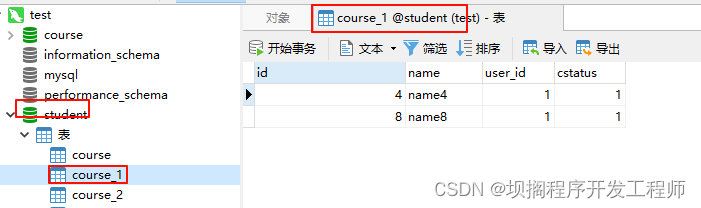
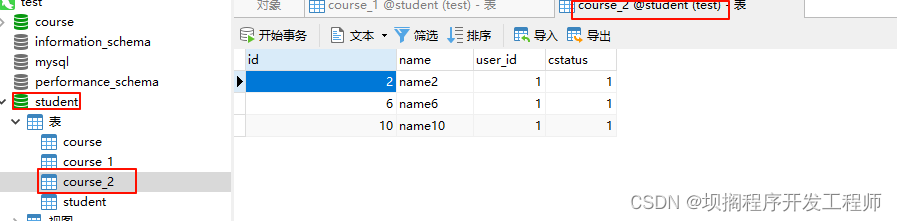
standard标准模式
单库下使用standard标准模式实现between查找
由于inline不支持between查找,所有需要使用standard标准模式
配置文件
#standard
#配置多个数据源
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/student?serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
course:
# 指定表的分布情况 配置表在哪个数据库里,表名是什么。水平分表,分到两个库两个表: m1.course_1,m1.course_2
actual-data-nodes: m1.course_$->{1..2}
# 指定表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
table-strategy:
standard:
sharding-column: id
#指定分片类
precise-algorithm-class-name: com.example.demosh.algorithm.PreciseTableShardingAlgorithm
#范围查找
range-algorithm-class-name: com.example.demosh.algorithm.RangTableShardingAlgorithm
# 打开sql日志输出。
props:
sql.show: true # 控制台打印SQL
指定分片类
PreciseTableShardingAlgorithm.java
package com.example.demosh.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.math.BigInteger;
import java.util.Collection;
public class PreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param collection 有效的数据源或表的名字。这里就对应配置文件中配置的数据源信息
* @param preciseShardingValue 包含 逻辑表名、分片列和分片列的值。
* @return 返回目标结果
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//实现按照 = 或 IN 进行精确分片。
//例如 select * from course where cid = 1 or cid in (1,3,5)
//实现course_$->{cid%2+1} 分表策略
BigInteger shardingValueB = BigInteger.valueOf(preciseShardingValue.getValue());
BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = preciseShardingValue.getLogicTableName()+"_"+resB ;
if(collection.contains(key)){
return key;
}
throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config");
}
}
指定范围策略类
RangTableShardingAlgorithm.java
package com.example.demosh.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.math.BigInteger;
import java.util.Arrays;
import java.util.Collection;
public class RangTableShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
*
* @param collection
* @param rangeShardingValue 包含逻辑表名、分片列和分片列的条件范围。
* @return 返回目标结果。可以是多个。
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
//实现按照 Between 进行范围分片。
//例如 select * from course where cid between 2000 and 3000;
Long lowerEndpoint = rangeShardingValue.getValueRange().lowerEndpoint();//2000
Long upperEndpoint = rangeShardingValue.getValueRange().upperEndpoint();//3000
//实现course_$->{(3000 -2000 )%2+1} 分片策略
// return Arrays.asList(shardingValue.getLogicTableName()+"_"+shardingValue.getLogicTableName() + ((upperEndpoint - lowerEndpoint) % 2 + 1));
//对于我们这个奇偶分离的场景,大部分范围查询都是要两张表都查。
return Arrays.asList(rangeShardingValue.getLogicTableName()+"_1",rangeShardingValue.getLogicTableName()+"_2");
}
}
测试效果
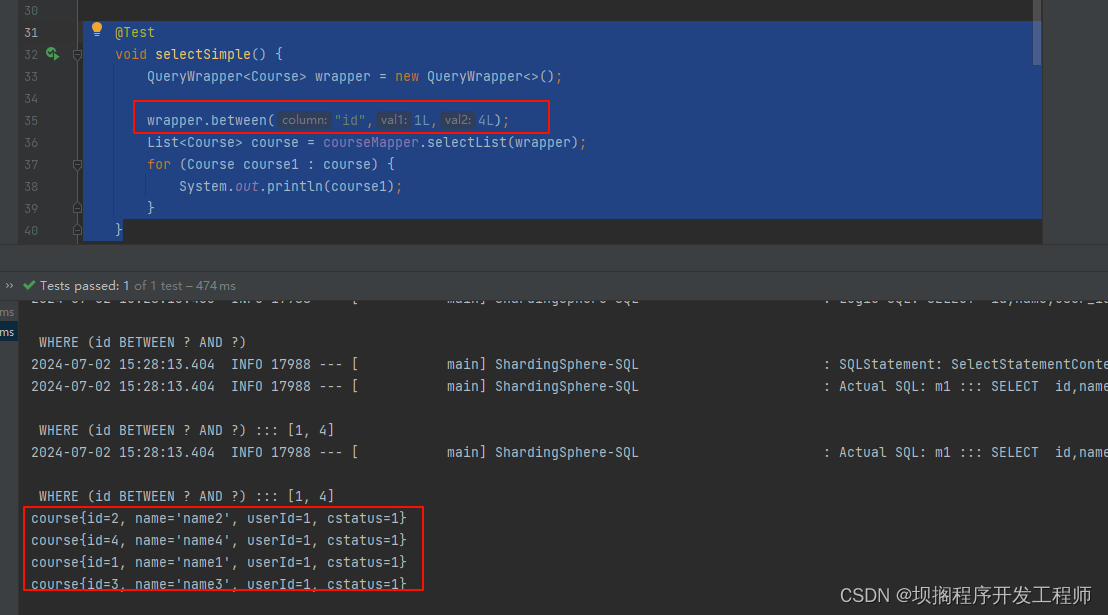
多库下使用standard标准模式实现between查找
配置文件
#各种分库分表策略
#配置多个数据源
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/student?serverTimezone=UTC
username: root
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/course?serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
course:
# 指定表的分布情况 配置表在哪个数据库里,表名是什么。水平分表,分到两个库两个表: m1.course_1,m1.course_2
actual-data-nodes: m$->{1..2}.course_$->{1..2}
# 指定表的主键生成策略
key-generator:
column: id
type: SNOWFLAKE
props:
worker:
id: 1
database-strategy:
standard:
sharding-column: id
precise-algorithm-class-name: com.example.demosh.algorithm.PreciseDSShardingAlgorithm
range-algorithm-class-name: com.example.demosh.algorithm.RangeDSShardingAlgorithm
table-strategy:
standard:
sharding-column: id
#指定分片类
precise-algorithm-class-name: com.example.demosh.algorithm.PreciseTableShardingAlgorithm
#范围查找
range-algorithm-class-name: com.example.demosh.algorithm.RangTableShardingAlgorithm
#使用inline:分库的策略
# database-strategy:
# inline:
# sharding-column: id
# algorithm-expression: m$->{id%2+1}
#使用inline: 指定分片策略 约定cid值为偶数添加到course_1表。如果是奇数添加到course_2表。
#选定计算的字段
# table-strategy:
# inline:
# sharding-column: id
#根据计算的字段算出对应的表名。
# algorithm-expression: course_$->{((id+1)%4).intdiv(2)+1}
# 打开sql日志输出。
props:
sql.show: true # 控制台打印SQL
PreciseDSShardingAlgorithm.java
public class PreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param availableTargetNames 有效的数据源或表的名字。这里就对应配置文件中配置的数据源信息
* @param shardingValue 包含 逻辑表名、分片列和分片列的值。
* @return 返回目标结果
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
//实现按照 = 或 IN 进行精确分片。
//例如 select * from course where cid = 1 or cid in (1,3,5)
// select * from course where userid- 'xxx';
//实现course_$->{cid%2+1} 分表策略
BigInteger shardingValueB = BigInteger.valueOf(shardingValue.getValue());
BigInteger resB = (shardingValueB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = "m"+resB ;
if(availableTargetNames.contains(key)){
return key;
}
throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config");
}
}
PreciseTableShardingAlgorithm.java
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.math.BigInteger;
import java.util.Collection;
public class PreciseTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* @param collection 有效的数据源或表的名字。这里就对应配置文件中配置的数据源信息
* @param preciseShardingValue 包含 逻辑表名、分片列和分片列的值。
* @return 返回目标结果
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//实现按照 = 或 IN 进行精确分片。
//例如 select * from course where cid = 1 or cid in (1,3,5)
//实现course_$->{((i+1)%4)/2+1} 分表策略
BigInteger shardingValueB = BigInteger.valueOf(preciseShardingValue.getValue());
BigInteger resB = (shardingValueB.add(new BigInteger("1"))
.mod(new BigInteger("4")))
.divide(new BigInteger("2"))
.add(new BigInteger("1"));
String key = preciseShardingValue.getLogicTableName()+"_"+resB ;
if(collection.contains(key)){
return key;
}
throw new UnsupportedOperationException(" route "+key+" is not supported. please check your config");
}
}
RangeDSShardingAlgorithm.java
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.Collection;
public class RangeDSShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
*
* @param availableTargetNames
* @param shardingValue 包含逻辑表名、分片列和分片列的条件范围。
* @return 返回目标结果。可以是多个。
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
//实现按照 Between 进行范围分片。
//例如 select * from course where cid between 2000 and 3000;
Long lowerEndpoint = shardingValue.getValueRange().lowerEndpoint();//2000
Long upperEndpoint = shardingValue.getValueRange().upperEndpoint();//3000
//对于我们这个奇偶分离的场景,大部分范围查询都是要两张表都查。
return availableTargetNames;
}
}
RangTableShardingAlgorithm.java
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.math.BigInteger;
import java.util.Arrays;
import java.util.Collection;
public class RangTableShardingAlgorithm implements RangeShardingAlgorithm<Long> {
/**
*
* @param collection
* @param rangeShardingValue 包含逻辑表名、分片列和分片列的条件范围。
* @return 返回目标结果。可以是多个。
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
//实现按照 Between 进行范围分片。
//例如 select * from course where cid between 2000 and 3000;
Long lowerEndpoint = rangeShardingValue.getValueRange().lowerEndpoint();//2000
Long upperEndpoint = rangeShardingValue.getValueRange().upperEndpoint();//3000
//实现course_$->{(3000 -2000 )%2+1} 分片策略
// return Arrays.asList(shardingValue.getLogicTableName()+"_"+shardingValue.getLogicTableName() + ((upperEndpoint - lowerEndpoint) % 2 + 1));
//对于我们这个奇偶分离的场景,大部分范围查询都是要两张表都查。
return Arrays.asList(rangeShardingValue.getLogicTableName()+"_1",rangeShardingValue.getLogicTableName()+"_2");
}
}















 1879
1879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









