






1.什么是ClickHouse
ClickHouse是一个高性能,面向列的SQL数据库管理系统(DBMS),用于在线分析处理(OLAP)。
2.rpm安装,设置官方存储库
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
3.安装ClickHouse服务器和客户端
sudo yum install -y clickhouse-server clickhouse-client
4.启动ClickHouse服务端
sudo systemctl enable clickhouse-server
sudo systemctl start clickhouse-server
sudo systemctl status clickhouse-server
clickhouse-client # or "clickhouse-client --password" if you set up a password.
停止:
sudo systemctl stop clickhouse-server
重启:
sudo systemctl restart clickhouse-server
5.安装独立ClickHouse Keeper
在生产环境中,我们强烈建议在专用节点上运行ClickHouse Keeper。在测试环境中,如果您决定在同一台服务器上运行ClickHouse Server和ClickHouse Keeper,则不需要安装ClickHouse Keeper,因为它包含在ClickHouse Server中。这个命令只需要在独立ClickHouse Keeper服务器上
sudo yum install -y clickhouse-keeper
启用并启动ClickHouse Keeper:
sudo systemctl enable clickhouse-keeper
sudo systemctl start clickhouse-keeper
sudo systemctl status clickhouse-keeper
6.创建用户和角色
1)修改users.xml 权限
chmod 777 users.xml
默认情况下,对所有用户禁用sql驱动的访问控制和帐户管理。需要在“users.xml”配置文件中配置至少一个用户,并将access_management、named_collection_control、show_named_collections和show_named_collections_secrets的设置值设置为1。
启用SQL用户模式 default用户添加权限:
<access_management>1</access_management>
<named_collection_control>1</named_collection_control>
<show_named_collections>1</show_named_collections>
<show_named_collections_secrets>1</show_named_collections_secrets>
2)修改配置完成重启节点
启动ClickHouse客户端:
clickhouse-client --user default --password <password>

创建SQL管理员帐户:
CREATE USER zhouyx IDENTIFIED BY 'password';
授予新用户完整的管理权限:
GRANT ALL ON *.* TO zhouyx WITH GRANT OPTION;
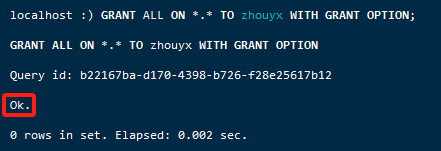
7.测试
使用clickhouse-client --user default连接到ClickHouse服务:
clickhouse-client --user default
创建表:
CREATE TABLE trips( `trip_id` UInt32, `vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15), `pickup_date` Date, `pickup_datetime` DateTime, `dropoff_date` Date, `dropoff_datetime` DateTime, `store_and_fwd_flag` UInt8, `rate_code_id` UInt8, `pickup_longitude` Float64, `pickup_latitude` Float64, `dropoff_longitude` Float64, `dropoff_latitude` Float64, `passenger_count` UInt8, `trip_distance` Float64, `fare_amount` Float32, `extra` Float32, `mta_tax` Float32, `tip_amount` Float32, `tolls_amount` Float32, `ehail_fee` Float32, `improvement_surcharge` Float32, `total_amount` Float32, `payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4), `trip_type` UInt8, `pickup` FixedString(25), `dropoff` FixedString(25), `cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3), `pickup_nyct2010_gid` Int8, `pickup_ctlabel` Float32, `pickup_borocode` Int8, `pickup_ct2010` String, `pickup_boroct2010` String, `pickup_cdeligibil` String, `pickup_ntacode` FixedString(4), `pickup_ntaname` String, `pickup_puma` UInt16, `dropoff_nyct2010_gid` UInt8, `dropoff_ctlabel` Float32, `dropoff_borocode` UInt8, `dropoff_ct2010` String, `dropoff_boroct2010` String, `dropoff_cdeligibil` String, `dropoff_ntacode` FixedString(4), `dropoff_ntaname` String, `dropoff_puma` UInt16) ENGINE = MergeTree PARTITION BY toYYYYMM(pickup_date) ORDER BY pickup_datetime;
插入测试数据:
INSERT INTO trips SELECT * FROM s3( 'https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{1..2}.gz', 'TabSeparatedWithNames', " `trip_id` UInt32, `vendor_id` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15), `pickup_date` Date, `pickup_datetime` DateTime, `dropoff_date` Date, `dropoff_datetime` DateTime, `store_and_fwd_flag` UInt8, `rate_code_id` UInt8, `pickup_longitude` Float64, `pickup_latitude` Float64, `dropoff_longitude` Float64, `dropoff_latitude` Float64, `passenger_count` UInt8, `trip_distance` Float64, `fare_amount` Float32, `extra` Float32, `mta_tax` Float32, `tip_amount` Float32, `tolls_amount` Float32, `ehail_fee` Float32, `improvement_surcharge` Float32, `total_amount` Float32, `payment_type` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4), `trip_type` UInt8, `pickup` FixedString(25), `dropoff` FixedString(25), `cab_type` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3), `pickup_nyct2010_gid` Int8, `pickup_ctlabel` Float32, `pickup_borocode` Int8, `pickup_ct2010` String, `pickup_boroct2010` String, `pickup_cdeligibil` String, `pickup_ntacode` FixedString(4), `pickup_ntaname` String, `pickup_puma` UInt16, `dropoff_nyct2010_gid` UInt8, `dropoff_ctlabel` Float32, `dropoff_borocode` UInt8, `dropoff_ct2010` String, `dropoff_boroct2010` String, `dropoff_cdeligibil` String, `dropoff_ntacode` FixedString(4), `dropoff_ntaname` String, `dropoff_puma` UInt16 ") SETTINGS input_format_try_infer_datetimes = 0
成功提示:
INSERT INTO trips
SETTINGS input_format_try_infer_datetimes = 0
SELECT *
FROM s3('https://datasets-documentation.s3.eu-west-3.amazonaws.com/nyc-taxi/trips_{1..2}.gz', 'TabSeparatedWithNames', ` \`trip_id\` UInt32, \`vendor_id\` Enum8('1' = 1, '2' = 2, '3' = 3, '4' = 4, 'CMT' = 5, 'VTS' = 6, 'DDS' = 7, 'B02512' = 10, 'B02598' = 11, 'B02617' = 12, 'B02682' = 13, 'B02764' = 14, '' = 15), \`pickup_date\` Date, \`pickup_datetime\` DateTime, \`dropoff_date\` Date, \`dropoff_datetime\` DateTime, \`store_and_fwd_flag\` UInt8, \`rate_code_id\` UInt8, \`pickup_longitude\` Float64, \`pickup_latitude\` Float64, \`dropoff_longitude\` Float64, \`dropoff_latitude\` Float64, \`passenger_count\` UInt8, \`trip_distance\` Float64, \`fare_amount\` Float32, \`extra\` Float32, \`mta_tax\` Float32, \`tip_amount\` Float32, \`tolls_amount\` Float32, \`ehail_fee\` Float32, \`improvement_surcharge\` Float32, \`total_amount\` Float32, \`payment_type\` Enum8('UNK' = 0, 'CSH' = 1, 'CRE' = 2, 'NOC' = 3, 'DIS' = 4), \`trip_type\` UInt8, \`pickup\` FixedString(25), \`dropoff\` FixedString(25), \`cab_type\` Enum8('yellow' = 1, 'green' = 2, 'uber' = 3), \`pickup_nyct2010_gid\` Int8, \`pickup_ctlabel\` Float32, \`pickup_borocode\` Int8, \`pickup_ct2010\` String, \`pickup_boroct2010\` String, \`pickup_cdeligibil\` String, \`pickup_ntacode\` FixedString(4), \`pickup_ntaname\` String, \`pickup_puma\` UInt16, \`dropoff_nyct2010_gid\` UInt8, \`dropoff_ctlabel\` Float32, \`dropoff_borocode\` UInt8, \`dropoff_ct2010\` String, \`dropoff_boroct2010\` String, \`dropoff_cdeligibil\` String, \`dropoff_ntacode\` FixedString(4), \`dropoff_ntaname\` String, \`dropoff_puma\` UInt16 `)
SETTINGS input_format_try_infer_datetimes = 0
Query id: d70fd215-15f7-47e0-a05d-c1e469e09406
Ok.
0 rows in set. Elapsed: 63.457 sec. Processed 2.00 million rows, 163.07 MB (31.51 thousand rows/s., 2.57 MB/s.)
Peak memory usage: 1.21 GiB.
查询总数量:
SELECT count() FROM trips
更多操作参考官网高级教程:
[]: https://clickhouse.com/docs/en/tutorial
8.使用dbeaver可视化工具操作clickhouse
下载地址:
[]: https://dbeaver.io/download/
设置/etc/clickhouse-server/config.xml权限:
chmod 777 config.xml
编辑/etc/clickhouse-server/config.xml,设置listen_host
powershell <listen_host>0.0.0.0</listen_host>
保存,重新启动
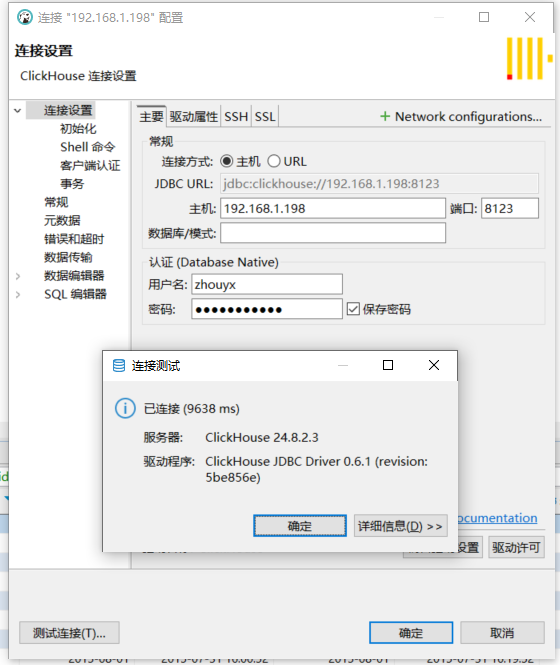
9、配置文件详解
配置文件默认会在:/etc/clickhouse-server/下,需要三个配置文件

1)config.xml
<clickhouse>
<logger>
<!-- 日志级别设置,建议设置成warning级别,日志文件路径,可自行修改
- none (turns off logging)
- fatal
- critical
- error
- warning
- notice
- information
- debug
- trace
- test (not for production usage)
-->
<level>trace</level>
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<size>1024M</size>
<count>3</count>
</logger>
<http_port>8123</http_port>
<tcp_port>9000</tcp_port>
<!-- interserver_http_port 用于在ClickHouse服务器之间交换数据的端口。 -->
<interserver_http_port>9009</interserver_http_port>
<!-- interserver_http_host 一般配置本机IP,也可以配置域名,其他服务器可用于访问此服务器的主机名。 -->
<interserver_http_host>10.0.1.1</interserver_http_host>
<listen_host>0.0.0.0</listen_host>
<!-- 最大连接数 -->
<max_connections>4096</max_connections>
<!-- ClickHouse在关闭连接之前等待传入请求的秒数 -->
<keep_alive_timeout>3</keep_alive_timeout>
<!-- 最大并发查询数 -->
<max_concurrent_queries>100</max_concurrent_queries>
<!-- 服务器进程的最大内存使用,会一直为查询保留占用,当查询超过此配置会引发异常。建议配置为0,即ck默认配置 -->
<max_server_memory_usage>0</max_server_memory_usage>
<!-- 全局线程池中的最大线程数,适合大量数据,如果服务器性能较好,可适当调整此配置,有助于提高并发查询 -->
<max_thread_pool_size>10000</max_thread_pool_size>
<!-- 最大内存使用率配置,一般配置0.8或者0.9,太多可能引起CPU打满-->
<max_server_memory_usage_to_ram_ratio>0.9</max_server_memory_usage_to_ram_ratio>
<!-- 按照官方解释类似于java进程oom的时候产生的temp文件,具体没关注过,可配置为0,表示禁用 -->
<total_memory_profiler_step>4194304</total_memory_profiler_step>
<!-- 收集随机分配和回收,并将它们写入系统。概率是每次分配/自由的,而不管分配的大小。 -->
<total_memory_tracker_sample_probability>0</total_memory_tracker_sample_probability>
<!-- 未压缩缓存仅对非常短的查询和极少数情况有利,对于日志等大量的查询场景来说建议配置为0-->
<uncompressed_cache_size>0</uncompressed_cache_size>
<!-- 同步数据时使用的缓存大小,这个配置太小的话表readonly会发生比较频繁,单位是B -->
<mark_cache_size>5368709120</mark_cache_size>
<!-- 数据存储路径 -->
<path>/var/lib/clickhouse/</path>
<!-- 多磁盘配置 -->
<storage_configuration>
<disks>
<default>
<!-- 最少需要保留多少磁盘空间 -->
<keep_free_space_bytes>1024</keep_free_space_bytes>
</default>
<disk_1>
<path>/var/lib/clickhouse/data1/</path>
<keep_free_space_bytes>1024</keep_free_space_bytes>
</disk_1>
<!-- 以下配置可以做冷、热配置使用disk_2作为冷盘配置,ck自带的ttl可实现自动将数据转到冷盘上,数据量大的情况下修改ttl失败的概率会很高 -->
<!-- <disk_2>
<path>/var/lib/clickhouse/data2/</path>
<keep_free_space_bytes>1024</keep_free_space_bytes>
</disk_2> -->
<!-- 以下配置可以做冷、热、温等配置使用 -->
<!-- <s3>
<type>s3</type>
<endpoint>http://path/to/endpoint</endpoint>
<access_key_id>your_access_key_id</access_key_id>
<secret_access_key>your_secret_access_key</secret_access_key>
</s3>
<blob_storage_disk>
<type>azure_blob_storage</type>
<storage_account_url>http://account.blob.core.windows.net</storage_account_url>
<container_name>container</container_name>
<account_name>account</account_name>
<account_key>pass123</account_key>
<metadata_path>/var/lib/clickhouse/disks/blob_storage_disk/</metadata_path>
<cache_enabled>true</cache_enabled>
<cache_path>/var/lib/clickhouse/disks/blob_storage_disk/cache/</cache_path>
<skip_access_check>false</skip_access_check>
</blob_storage_disk> -->
</disks>
<!-- 存储策略,跟建表有关 -->
<policies>
<william>
<volumes>
<hot>
<disk>disk_1</disk>
</hot>
<!--cold>
<disk>disk_2</disk>
</cold-->
</volumes>
<!-- 移动因子,当热盘空闲还剩多少的时候将数据转移到冷盘 -->
<move_factor>0.2</move_factor>
</william>
</policies>
</storage_configuration>
<!-- 用户级别的配置 -->
<users_config>users.xml</users_config>
<!-- 处理查询的临时数据的路径 -->
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<!-- 默认配置文件 -->
<default_profile>default</default_profile>
<!-- 逗号分隔的自定义设置前缀列表,适用于有特殊建表规范的项目 -->
<custom_settings_prefixes></custom_settings_prefixes>
<!-- 默认数据库 -->
<default_database>default</default_database>
<mlock_executable>true</mlock_executable>
<distributed_ddl>
<!-- ZooKeeper中DDL查询队列的路径 -->
<path>/clickhouse/task_queue/ddl</path>
</distributed_ddl>
<!-- 最大可损坏的部件数 -->
<merge_tree>
<max_suspicious_broken_parts>5</max_suspicious_broken_parts>
</merge_tree>
<!-- 保存建表的schemas -->
<format_schema_path>/var/lib/clickhouse/format_schemas/</format_schema_path>
<!-- 集群配置,副本配置 -->
<include_from>/etc/clickhouse-server/metrika.xml</include_from>
<!-- 同步表的配置 -->
<macros incl="macros" optional="true" />
<!-- 内置字典的重新加载间隔,以秒为单位 -->
<builtin_dictionaries_reload_interval>3600</builtin_dictionaries_reload_interval>
<!-- 最大会话超时时间,配置为0表示查询的时候不会中断 -->
<max_session_timeout>3600</max_session_timeout>
<!-- 默认会话超时时间 -->
<default_session_timeout>60</default_session_timeout>
<!-- 以下配置是一些日志记录配置 -->
<!-- 暴露ck自身的指标,如果有监控需求可以打开
<prometheus>
<endpoint>/metrics</endpoint>
<port>9363</port>
<metrics>true</metrics>
<events>true</events>
<asynchronous_metrics>true</asynchronous_metrics>
<status_info>true</status_info>
</prometheus>
-->
<!-- 执行sql记录,可以理解成ck的审计日志,排查问题很有用 -->
<query_log>
<database>system</database>
<table>query_log</table>
<!-- 配置默认删除时间,否则会占用很大的存储空间,单位有WEEK、DAY
如需要长期保留,也可以到时见后转存到其他磁盘上,eg:event_date + INTERVAL 2 WEEK TO DISK 'bbb' -->
<ttl>event_date + INTERVAL 5 DAY DELETE</ttl>
<partition_by>toYYYYMM(event_date)</partition_by>
<!-- 数据刷新间隔 -->
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>
<!-- 记录trace日志,即调用链路信息,日志量也很大,可参考query_log配置信息
<trace_log>
<database>system</database>
<table>trace_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</trace_log> -->
<!-- 查询线程日志
<query_thread_log>
<database>system</database>
<table>query_thread_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_thread_log> -->
<!-- 查询视图日志。
<query_views_log>
<database>system</database>
<table>query_views_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_views_log> -->
<!-- part日志,会记录每一批数据part的合并、删除等
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>toYYYYMM(event_date)</partition_by>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log> -->
<!-- 记录指标日志
<metric_log>
<database>system</database>
<table>metric_log</table>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
<collect_interval_milliseconds>1000</collect_interval_milliseconds>
</metric_log> -->
<!-- 外部字典的配置。-->
<dictionaries_config>*_dictionary.xml</dictionaries_config>
<!-- 自定义的可执行函数的配置 -->
<user_defined_executable_functions_config>*_function.xml</user_defined_executable_functions_config>
</clickhouse>
2)metrika.xml
<clickhouse>
<remote_servers>
<!-- 分布式配置示例,即集群节点配置。集群有多个节点时直接拷贝此文件到所有集群中的节点即可 -->
<test_shard_localhost>
<shard>
<!-- 写入数据时的分片权重-->
<!-- <weight>1</weight> -->
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
</test_shard_localhost>
<test_cluster_one_shard_three_replicas_localhost>
<shard>
<internal_replication>false</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.3</host>
<port>9000</port>
</replica>
</shard>
<!--shard>
<internal_replication>false</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
<replica>
<host>127.0.0.3</host>
<port>9000</port>
</replica>
</shard-->
</test_cluster_one_shard_three_replicas_localhost>
<test_cluster_two_shards_localhost>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards_localhost>
<test_cluster_two_shards>
<shard>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards>
<test_cluster_two_shards_internal_replication>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>127.0.0.1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>127.0.0.2</host>
<port>9000</port>
</replica>
</shard>
</test_cluster_two_shards_internal_replication>
<test_shard_localhost_secure>
<shard>
<replica>
<host>localhost</host>
<port>9440</port>
<secure>1</secure>
</replica>
</shard>
</test_shard_localhost_secure>
<test_unavailable_shard>
<shard>
<replica>
<host>localhost</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>localhost</host>
<port>1</port>
</replica>
</shard>
</test_unavailable_shard>
</remote_servers>
<!-- 使用集群的时候需要配置zookeeper,用于副本数据同步 -->
<!--
<zookeeper>
<node>
<host>example1</host>
<port>2181</port>
</node>
<node>
<host>example2</host>
<port>2181</port>
</node>
<node>
<host>example3</host>
<port>2181</port>
</node>
</zookeeper>
-->
<!-- 会压缩30-100%的数据,节省磁盘空间 -->
<compression>
<case>
<!-- 最小的part -->
<min_part_size>10000000000</min_part_size>
<!-- 整个表里最小的part -->
<min_part_size_ratio>0.01</min_part_size_ratio>
<!-- 压缩方式. -->
<method>zstd</method>
</case>
</compression>
</clickhouse>
3)users.xml
<clickhouse>
<profiles>
<!-- 记录读取日志 -->
<log_queries>1</log_queries>
<default>
<!-- 最大使用内存 -->
<max_memory_usage>10737418240</max_memory_usage>
<!-- 用户查询最大使用内存,即除系统内部执行的sql外 -->
<max_memory_usage_for_user>10737418240</max_memory_usage_for_user>
<!-- 整个ck服务最大使用内存 -->
<max_memory_usage_for_all_queries>25164708864</max_memory_usage_for_all_queries>
<!-- 使用压缩缓存 -->
<use_uncompressed_cache>0</use_uncompressed_cache>
<!-- 最大线程数,可适当根据服务器性能调节 -->
<max_threads>8</max_threads>
<!-- 线程池大小,太小会影响查询性能 -->
<background_pool_size>8</background_pool_size>
<!-- join查询时发生异常会终止,尽量避免join查询! -->
<joined_subquery_requires_alias>0</joined_subquery_requires_alias>
<!-- 遇到错误是否直接停止,生产环境强烈推荐配置,否则可能引发CPU打满等问题 -->
<join_overflow_mode>break</join_overflow_mode>
<!-- 最大group行数 -->
<max_rows_to_group_by>10000000000</max_rows_to_group_by>
<!-- 可提高group的查询速率 -->
<group_by_overflow_mode>any</group_by_overflow_mode>
<!-- 查询结果超过内存限制时抛出异常 -->
<result_overflow_mode>throw</result_overflow_mode>
<!-- 发生其他超过内存限制时终止操作 -->
<distinct_overflow_mode>break</distinct_overflow_mode>
<!-- 最大group字节数 -->
<max_bytes_before_external_group_by>50000000000</max_bytes_before_external_group_by>
</default>
<!-- 配置文件只读 -->
<readonly>
<readonly>1</readonly>
</readonly>
</profiles>
<users>
<default>
<!-- 密码配置:可用的几种方式:
明文密码,eg:<password>qwerty</password>
SHA256,eg:<password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex>
SHA1,eg:<password_double_sha1_hex>e395796d6546b1b65db9d665cd43f0e858dd4303</password_double_sha1_hex>
ldap,eg:<ldap><server>my_ldap_server</server></ldap>
-->
<password></password>
<!-- 允许外部登录 -->
<networks incl="networks" replace="replace">
<ip>::/0</ip>
</networks>
<profile>default</profile>
<quota>default</quota>
</default>
<!-- 本地访问 -->
<readonly>
<password></password>
<networks incl="networks" replace="replace">
<ip>::1</ip>
<ip>127.0.0.1</ip>
</networks>
<profile>readonly</profile>
<quota>default</quota>
</readonly>
</users>
<!-- 一些配额信息,可参考https://clickhouse.com/docs/en/operations/system-tables/quotas -->
<quotas>
<default>
<interval>
<duration>3600</duration>
<queries>0</queries>
<errors>0</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>
</clickhouse>















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









