







目录
在编程的过程中,我们可以把一些频繁使用的过程语句封装到一个函数中,需要使用时直接调用函数,而不用在代码中频繁的使用同一段过程语句。这样做即减少了写代码的工作量,又使代码的逻辑更加清晰。所以我们要学会合理的定义函数,来使我们写的代码短而强。
基本结构
# 无参函数定义
def 函数名():
函数内的逻辑语句
# 无参函数调用方式
函数名()
# 有参函数定义
def 函数名(参数名1, 参数名2, ..., 参数名n):
函数内的逻辑语句
# 有参函数调用方式
函数名(值1, 值2, ..., 值n)使用 def 来定义函数,函数名的位置写上要定义函数的名字(函数名要通俗易懂,看一眼函数名就大概知道函数的功能)。函数名后面的括号是用来接收参数的,不需要传参的函数括号内什么也不用写;需要传参的函数则需要在括号内写上用来接收参数的参数名,需要接收多少个参数就写多少个参数名。函数体中就写调用此函数时需要执行的语句。
无参函数
不需要传入参数的函数,函数体有固定的内容或者函数体中的语句使用公共变量。
函数体中有固定的内容
# 定义函数
def hello():
print('hello world')
# 调用函数
hello()执行结果如下:

有固定内容的函数不受外界的影响,被调用时就执行内部的代码,不会因为外界的变化而变化。
使用公共变量
公共变量就是定义在所有函数和类之外的变量,它能被这个py文件中所有的语句使用。它的直接作用域就在整个py文件中,当这个py文件被其他py文件导入时,它还可以被其他py文件中的语句使用。在函数和类中使用公共变量需要注意的点就是:如果要修改公共变量的值时,需要先使用global语句声明要修改的公共变量;如果只是使用公共变量的值,则不需要声明公共变量。
局部变量就是定义在函数或类中的变量,它只能在定义它的函数或类的内部语句中使用,不能被外部的语句使用,它的作用域就在整个函数中。类中的局部变量又被称为类的属性。
# 定义公共变量
name = '小明'
# 定义函数
def hello():
print(f'hello {name}') # 函数内使用公共变量
# 调用函数
hello()执行结果如下:

上面这个例子就是只使用了公共变量name的值,所以我们不需要使用global来声明,直接用就行了。
下面我们来看一个函数中修改公共变量的例子,这时就需要用到global语句了。
name = '小明'
def set_name():
global name # 使用global声明name是公共变量
name = '爆笑蛙' # 修改公共变量name的值(重新赋值为爆笑蛙)
def hello():
print(f'hello {name}')
set_name() # 调用set_name()函数把name的值修改为'爆笑蛙'
hello() # 调用hello()函数打印出'hello 爆笑蛙'执行结果如下:

如果我们不在函数内声明公共变量而直接给变量赋值时,python会认为此变量是函数内的局部变量。虽然此变量的名称和公共变量一模一样,它依然只是函数内部的局部变量。因为python查找一个变量作用域的顺序是:首先查找局部范围内是否存在此变量的定义,其次是查看外层的函数是否存在此变量的定义(如果有外层函数的话),之后是全局查找,最后再查找是否内置了此变量,如果都没有找到则抛出此变量未定义的错误。请看如下例子:
name = '小明'
def set_name():
name = '爆笑蛙' # python认为我们在set_name()函数内定义了一个局部变量name,而非给公共变量name重新赋值
def hello():
print(f'hello {name}')
set_name() # 此时调用set_name()函数不能修改公共变量name的值
hello() # 调用hello()函数打印出'hello 小明'当程序执行到12行set_name()时,因为我们没有在函数set_name中声明name是公共变量,当python查找name的作用域时,首先在函数set_name中找到了name的定义,所以python认为set_name中的变量name是局部变量。所以 name = '爆笑蛙' 只是在给一个局部变量下定义,并不是在给公共变量name重新赋值。执行结果如下:

公共变量name的值并没有被set_name函数改变。
有参函数
需要在被调用时传入参数的函数,传入的参数会参与到函数内部的运算中。传入的参数可以是python中的任意对象,如果我们不想python报错的话还是要传入正确的参数。我们给函数定义参数的时候,可以给参数指定默认值,拥有默认值的参数又被称为缺省参数。当我们不给缺省参数传参时,函数就使用缺省参数的默认值参与运算。
普通参数
下面我们来设计一个加法函数,这个加法函数可以接收两个参数,它能求出传入的两个数之和并打印出结果。
def add(number_a, number_b): # 定义一个名为add的函数,可以接收两个参数,分别用变量number_a和number_b来接收,就是把传入的值分别赋给变量number_a和number_b
number_sum = number_a + number_b # 用加法运算符求出number_a和number_b的和,再赋值给number_sum
print(f'{number_a} + {number_b} = {number_sum}')
add(3, 5)其中number_a和number_b被称为形参,调用函数时传入的值3和5被称为实参。形参的实质就是函数中的局部变量,作用就是用来接收实参的,形参是没有固定值的,我们传入什么值它就是什么值;实参就是一个实实在在的数据,逻辑也是一种数据,所以我们也可以把函数或者类甚至一个py文件当作实参传入到一个函数中。执行结果如下:

缺省参数
缺省参数就是拥有默认值的形参,缺省参数有两个好处。一个是当我们不需要改动默认值时,就不需要给缺省参数传值,有效减少代码字符数量;另一个是当我们在调用函数时,忘记给缺省参数传值函数也能使用默认值完成计算,而不会突然报错终止执行函数内的运算,虽然有可能得不到正确的结果。
def add(number_a=1, number_b=2): # 让number_a和number_b都变成有默认值的缺省参数
number_sum = number_a + number_b
print(f'{number_a} + {number_b} = {number_sum}')
add() # 不给add()传参,直接调用也可以得到结果执行结果如下:

当我们给缺省参数传值时,传入的值会替换掉默认值。
def add(number_a=1, number_b=2): # 让number_a和number_b都变成有默认值的缺省参数
number_sum = number_a + number_b
print(f'{number_a} + {number_b} = {number_sum}')
add(5) # 用按位置传参只给第一个参数传值,第二个参数使用默认值执行结果如下:

按位置传参
把传入的值和函数的形参一一对应起来的传参方式,第一个值对应第一个形参,第二个值对应第二个形参...第n个值对应第n个形参。传入的值的顺序和形参的顺序一样,值的位置对应着形参的位置,这种方式就是按位置传参。
def people_info(name, sex, age):
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
print(f'{name}{adult[sex]}今年{age}岁')
else:
print(f'{name}{minor[sex]}今年{age}岁')
people_info('小明', '男', 20)
people_info('李梅', '女', 15)就像上面这种把值的顺序按照参数的顺序传入,这种传参方式也是我们常用的传参方式。但我们需要注意不能把传入值的顺序搞错了,位置必须一一对应。如果顺序搞错了结果就会很奇怪,也有可能会报错。执行结果如下:
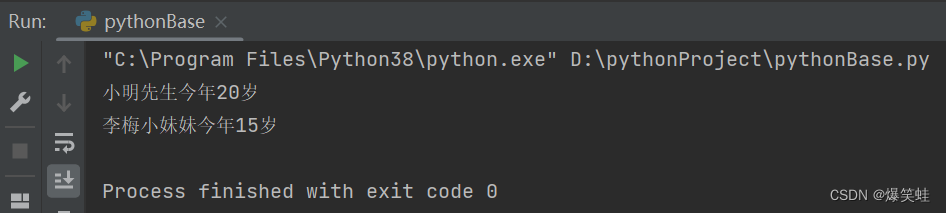
关键字传参(形参=值)
使用关键字传参就可以随意更改传参的顺序,所谓关键字传参就是在传参的时候直接给形参赋值。这种传参方式就不用在乎传参的顺序,因为我们给每一个形参都赋予了相应的值。
def people_info(name, sex, age):
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
print(f'{name}{adult[sex]}今年{age}岁')
else:
print(f'{name}{minor[sex]}今年{age}岁')
people_info(age=22, name='小明', sex='男')
people_info(sex='女', age=17, name='李梅')如上代码种我们在调用函数传参时直接给每一个形参赋予了相应的值,所以我们即使不按照形参的位置来传参,也不会使值和形参不能一一对应。执行结果如下:

混合传参
我们可以把按位置传参和关键字传参混合起来使用,就是在传参的时候既使用按位置传参,又使用关键字传参 。使用混合传参需要注意的地方就是,按位置传参的方式一定要位于关键字传参的前面,关键字传参的后面不能再出现按位置传参;按位置传参传过的参数,不能再使用关键字传参再传一遍。
def people_info(name, sex, age):
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
print(f'{name}{adult[sex]}今年{age}岁')
else:
print(f'{name}{minor[sex]}今年{age}岁')
people_info('小明', age=16, sex='男')
people_info('李梅', '女', age=19)按位置传参的地方,值和形参的位置一定要一一对应。关键字传参的地方任然可以不按形参位置来传参。执行结果如下:

如果把关键字传参放在按位置传参的前面,python就会报语法错误。
def people_info(name, sex, age):
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
print(f'{name}{adult[sex]}今年{age}岁')
else:
print(f'{name}{minor[sex]}今年{age}岁')
people_info(name='小明', sex='男', 16)我们把name和sex都使用关键字传参,把age使用按位置传参,这样写看起来传参的顺序没错。但python解释器不认同这种写法,所以python解释器会认为代码中存在语法错误。执行结果如下:
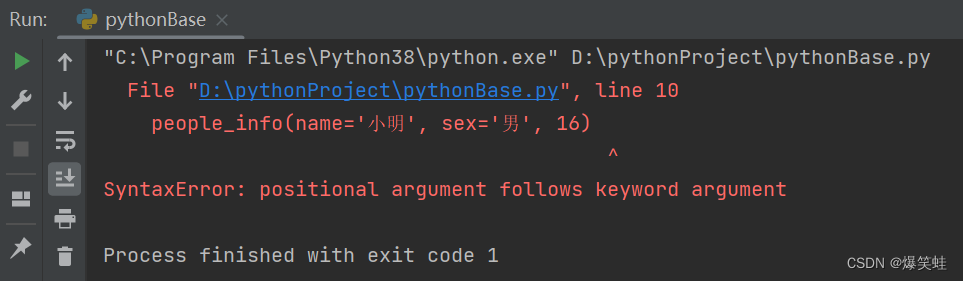
报错显示:位置参数跟在关键字参数后面,SyntaxError是语法错误。
按位置传参传递过的参数,不能再使用关键字传参再传一遍,因为传参时每个参数只能传递一次。
def people_info(name, sex, age):
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
print(f'{name}{adult[sex]}今年{age}岁')
else:
print(f'{name}{minor[sex]}今年{age}岁')
people_info('小明', name='爆笑蛙', sex='男', age=16)我们已经使用按位置传参给name传递了一个值'小明',后面再使用关键字传参name='爆笑蛙'再传递一次参数,python就会报错,因为同一个参数不能同时被传递多个值。执行结果如下:

报错显示:people_info()为参数“name”获取了多个值,TypeError为类型错误。
任意位置参数(*args)
任意参数前面加一个*号就变成了可变参数,但我认为它叫任意位置参数更好理解。任意位置参数是没有参数名和不确定参数个数的位置参数,我们常用*args来表示,args表示位置参数,*表示任意多个。如果一个函数在定义时使用了任意位置参数,我们就可以给这个函数以按位置传参的方式传递任意多个参数。任意位置参数常被用于回调函数的调用函数和多态函数中。
def people_info(name, age, *args):
print(f'我叫{name},今年{age}岁')
print(f'args: {args}')
print('我的爱好有:', end='')
for i in args:
print(f'{i}、', end='')
print('\b')
people_info('小明', 20, '看书', '画画', '钓鱼', '骑自行车')执行结果如下:
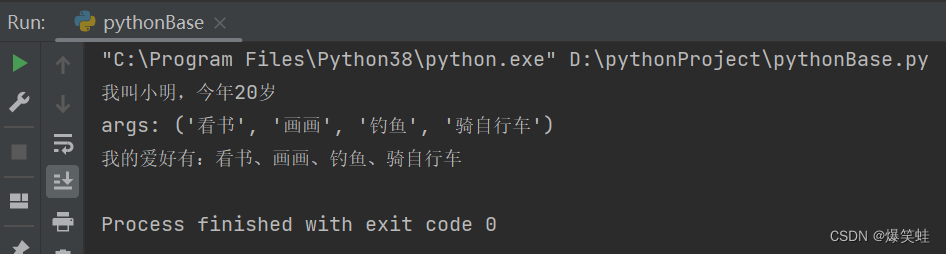
我们从执行结果中可以看出*args可以接收任意多个参数(0个或多个),得到的位置参数args是一个元组,我们可以通过下标取值也可以通过for循环迭代args。args是确定的位置参数,我们可以从中取值;*args则是不确定的位置参数,我们可以给它传值。
我们可以通过*str、*[]、*()、*set()的方式来给*args传值,*对应*,字符串、列表、元组或集合对应args。其实*{}也可以,但是这样只能把字典中的键传进去,不能把值传进去。所以只要是可迭代的对象就能放到*后面传给*args,会把这个可迭代对象中的元素取出来放到args元组中。
def test(*args):
print(args)
test(*'abc')
test(*[1, 2, 3])
test(*(5, 6, 7))
test(*{'i', 'j', 'k'})
test(*{'name': '爆笑蛙', 'sex': '男'})执行结果如下:
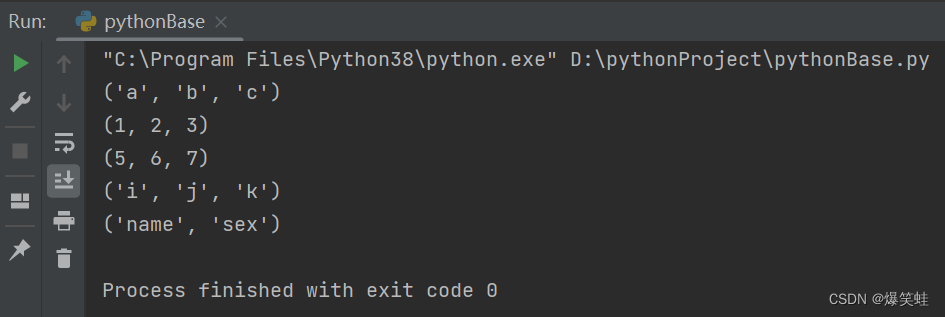
从结果中我们可以看到所有可迭代对象中的元素都被取出来放到了args元组中。
当我们在一个函数中调用另一个函数时,我们可以通过*args给被调用的函数传值。元组args中的值对就可以传递给被调用的函数。
def people_info(*args):
print(args) # 打印元组args
print_info(*args) # 通过*元组传参
def print_info(name, age, *args):
print(f'我叫{name},今年{age}岁')
print('我的爱好有:', end='')
for i in args:
print(f'{i}、', end='')
print('\b')
people_info('小明', 20, '看书', '画画', '钓鱼', '骑自行车')执行结果如下:
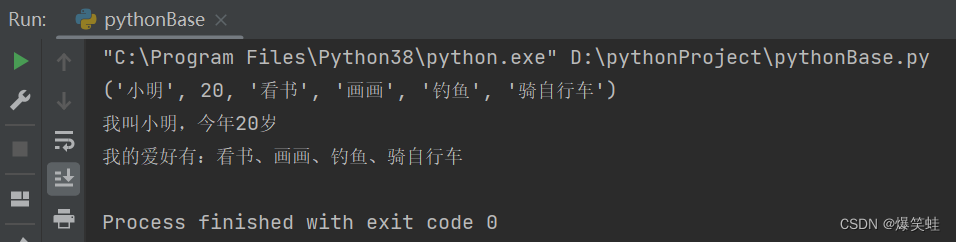
我们使用*args把people_info函数接收到的位置参数args传递给了print_info函数。
任意关键字参数(**kwargs)
任意参数前面加两个*号就变成了关键参数,但我认为它叫任意关键字参数更好理解。任意关键字参数是没有参数名和不确定参数个数的关键字参数,我们常用**kwargs来表示,kwargs表示关键字参数,**表示任意多个(键和值所以是两个*)。如果一个函数在定义时使用了任意关键字参数,我们就可以给这个函数以关键字传参的方式传递任意多个参数。任意关键字参数常被用于回调函数的调用函数和多态函数中。
def people_info(name, age, *args, **kwargs):
print(f'我叫{name},今年{age}岁')
print(f'args: {args}')
print(f'kwargs: {kwargs}')
print('我的爱好有:', end='')
for i in args:
print(f'{i}、', end='')
print('\b')
print(f'身高{kwargs["height"]}cm,体重{kwargs["weight"]}kg')
people_info('小明', 20, '看书', '画画', '钓鱼', '骑自行车', height=170, weight=60)执行结果如下:

我们从执行结果中可以看出**kwargs可以接收任意多个关键字参数(0个或多个),得到的关键字参数kwargs是一个字典,我们可以通过键来取值也可以通过for循环迭代kwargs。kwargs是确定的关键字参数,我们可以从中取值;**kwargs则是不确定的关键字参数,我们可以给它传值。
我们可以通过**{}的方式来给**kwargs传参,**对应**,字典对应kwargs。
def test(**kwargs):
print(kwargs)
test(**{'name': '爆笑蛙', 'sex': '男'})执行结果如下:

从结果中我们可以看到传入字典的元素被放到了kwargs字典中。
当我们在一个函数中调用另一个函数时,我们可以通过*kwargs给被调用的函数传值。字典kwargs中的键值对就会以关键字传参的方式传递给被调用的函数。
def people_info(*args, **kwargs):
print(args) # 打印出args
print(kwargs) # 打印出kwargs
print_info(*args, **kwargs) # 调用print_info函数,并把args和kwargs传递给它
def print_info(name, age, *args, height, weight):
print(f'我叫{name},今年{age}岁')
print('我的爱好有:', end='')
for i in args:
print(f'{i}、', end='')
print('\b')
print(f'身高{height}cm,体重{weight}kg')
people_info('小明', 20, '看书', '画画', '钓鱼', '骑自行车', height=170, weight=60)执行结果如下:
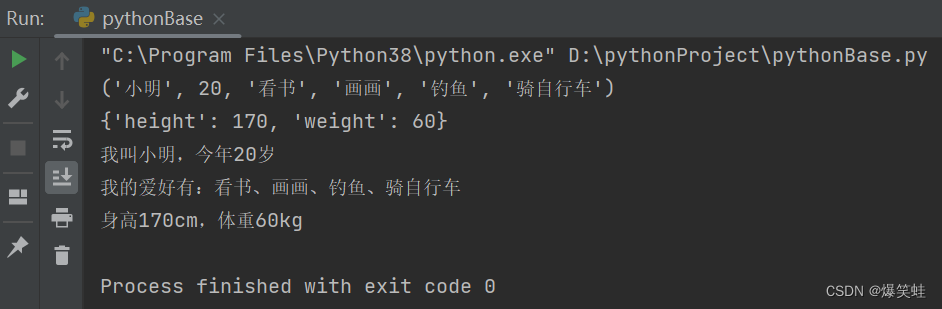
我们使用*kwargs把people_info函数接收到的关键字参数传递给了print_info函数。
return语句
python中的每一个函数都会有返回值,当我们没有给函数定义返回值时,函数返回None。return语句就是专门用来给函数定义返回值的,当函数执行到return语句时就会返回return后面的对象,并立即结束函数(不管函数中的所有语句有没有被执行完,都会立即结束函数)。
只用来提前结束函数不定义返回值
当我们定义的函数不需要返回值,但需要在满足某个条件时提前终止函数。这时我们就可以使用return语句,return语句后面不加任何对象。
def people_info(name, sex, age):
if sex not in ['男', '女']: # 判断sex的值是不是不为男或女
print('性别输入错误,请输入正确的性别男或者女') # sex的值不为男或女时打印错误信息
return # 结束函数
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
print(f'{name}{adult[sex]}今年{age}岁')
else:
print(f'{name}{minor[sex]}今年{age}岁')
info = people_info('小明', sex='大', age=16) # 使用变量info接收people_info函数的返回值
print(info)我们在if条件语句中写了一个return语句,当if语句的条件为真时,就会执行到return语句。一旦执行到return语句就会立即结束函数,后面的语句将不会被执行。因为我们没有在return后面加任何对象,所以这时函数返回None。执行结果如下:

我们使用print打印出people_info函数的返回值,发现是None。
在函数的循环中使用return语句,可以提前结束循环。在函数的循环语句中,return也具有和break语句的相似的作用。但return不能替代break,因为return语句只能在函数中使用,而且return和break的功能不同、作用原理不同,只是在这个地方能达到相同的效果。
def accumulator(number):
while True: # 死循环
if number > 5: # 判断number是否大于5
print(number) # number大于5时打印出number的值
return # 结束函数
number += 1
accumulator(1)执行结果如下:

当number的值大于5时会直接结束函数,在函数结束过程中,函数占用的资源都会被释放掉,所以循环语句会因为函数释放资源而被终止。
用来定义返回值
当我们在return语句后面加上要返回的对象时,return在结束函数时就会把要返回的对象变成函数的返回值返回出来。
def people_info(name, sex, age):
if sex not in ['男', '女']:
return '性别输入错误,请输入正确的性别男或者女'
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
return f'{name}{adult[sex]}今年{age}岁'
else:
return f'{name}{minor[sex]}今年{age}岁'
info = people_info('小明', sex='男', age=23)
print(info)我们在return后面加上了一个字符串,当return结束函数时就会把这个字符串变成函数的返回值返回出来。执行结果如下:

我们使用print打印出people_info函数的返回值,发现打印出了人物的信息。
return还可以同时返回多个值,当我们使用return返回多个值时,要返回的多个值会被放到一个元组中,最后返回这个元组。
def coordinate():
x = 5
y = 6
location = '第一象限'
return x, y, location # 同时返回3个对象
value = coordinate() # 返回一个元组
print(value)执行结果如下:

函数的注释
为了能让别人来查看我们写的函数时,可以快速理解我们所写函数的逻辑。我们在写代码时常常会给函数写上注释。函数注释的写法:使用3对双引号,在3对双引号的中间写上函数的注释。
def funtion():
"""注释内容"""
函数内的语句无参无返回值的函数
对于无参无返回值的函数,我们在注释中只需要简单的描述一下函数的作用即可。
def chess_board():
"""打印出国际象棋的棋盘"""
print('-' * 41) # 打印棋盘上边界线
for i in range(1, 9):
for j in range(1, 9):
print(f'| ', end='') # 打印出左边界
print('|') # 棋盘右边界线
print('-' * 41) # 打印棋盘底部边界线
chess_board()无参有返回值的函数
对于无参有返回值的函数,我们除了要描述函数的作用以外,还要描述函数的返回内容。
name = "爆笑蛙"
def get_name():
"""
获取姓名
:return: 姓名
"""
return name我们需要在注释中使用 :return: 来描述返回内容。
有参无返回值的函数
对于有参无返回值的函数,我们除了要描述函数的作用以外,还要描述传入的参数。
name = "爆笑蛙"
def set_name(name_string):
"""
设置姓名
:param name_string: 姓名字符串
:return:
"""
global name
name = name_string我们需要在注释中使用 :param 形参: 来描述要传入的参数。
有参有返回值的函数
对于有参有返回值的函数,我们要描述函数的作用、传入的参数以及返回内容。
def people_info(name, sex, age):
"""
返回对应的人物信息
:param name: 姓名
:param sex: 性别
:param age: 年龄
:return: 人物信息
"""
if sex not in ['男', '女']:
return '性别输入错误,请输入正确的性别男或者女'
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
return f'{name}{adult[sex]}今年{age}岁'
else:
return f'{name}{minor[sex]}今年{age}岁'如果我们使用的IDE是Pycharm,在写函数注释的时候,只需要打出3对双引号然后敲回车,就会根据定义函数行的内容自动帮我们生成注释的格式。我们只需要在其中添加描述字符就行了。
查看函数的注释
当我们调用了一个函数时,该怎样做才能得到函数中的注释呢?
通过help函数打印函数信息
python中内置的help函数可以打印出一个函数的信息,包括函数名和函数注释。
def people_info(name, sex, age):
"""
返回对应的人物信息
:param name: 姓名
:param sex: 性别
:param age: 年龄
:return: 人物信息
"""
if sex not in ['男', '女']:
return '性别输入错误,请输入正确的性别男或者女'
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
return f'{name}{adult[sex]}今年{age}岁'
else:
return f'{name}{minor[sex]}今年{age}岁'
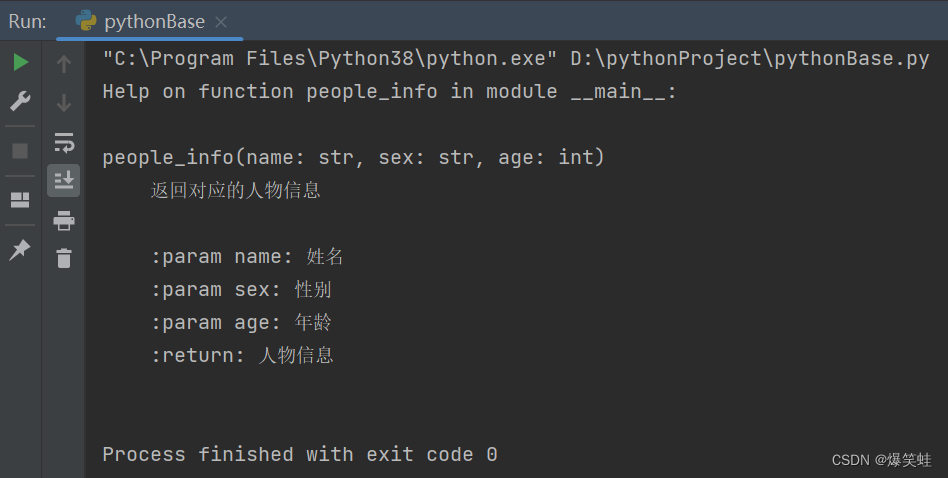
help(people_info) # 使用help函数打印出people_info函数信息执行结果如下:
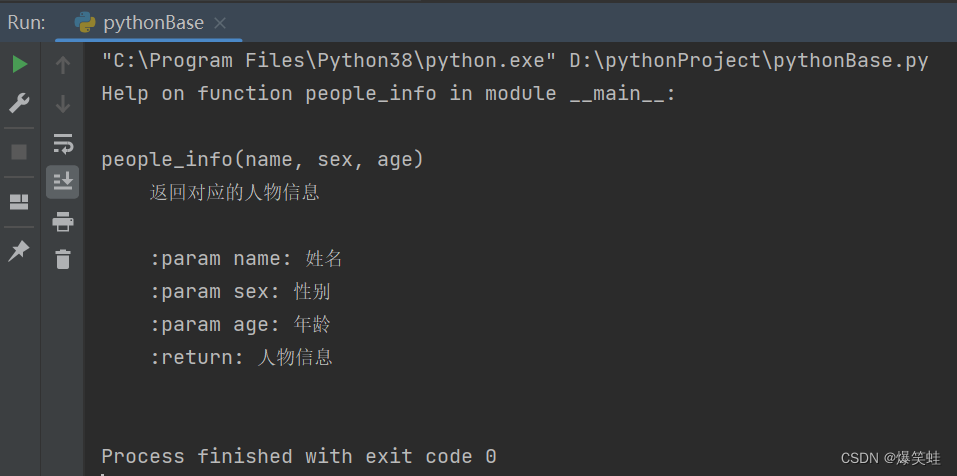
在Pycharm中轻松查看
如果我们使用的IDE是Pycharm,只需要把鼠标放置在函数名的上方,函数的信息就会自动展示出来。
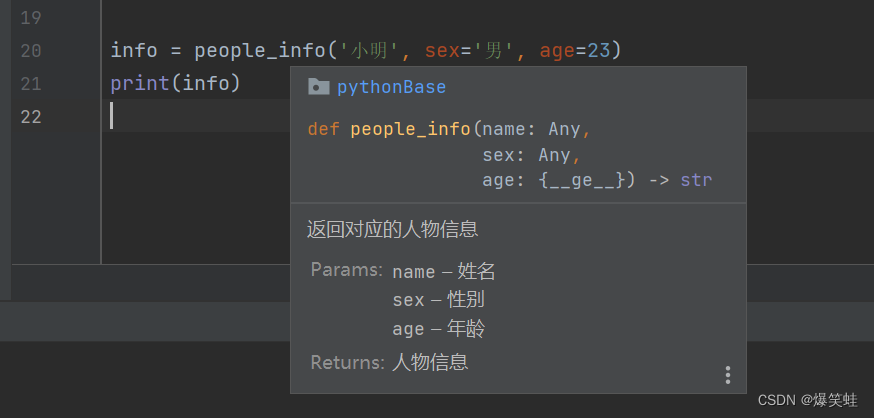
所以我感觉使用Pycharm编写python代码还是非常方便的。
跳转到定义函数的位置查看
我们在IDE中可以使用Ctrl键加鼠标左键的方式,快速跳转到定义函数的位置,直接查看函数的注释和逻辑语句。在代码编辑器中,我们按住Ctrl键的同时再使用鼠标左键点击调用的函数名,可以直接跳转到定义此函数的位置。
标注参数的类型
我们虽然写好了函数的注释,对参数也进行了描述。但是别人在调用我们的函数时,可能不知道该给相应的参数传递什么类型的值。比如上文常用的people_info函数,参数age到底是传入整型23还是传入字符串'23'呢。这时我们就需要给形参标注类型,标注参数类型要使用类型的名称。例如整型就用int、字符串就用str、列表就用list、字典就用dict等等。标注方式如下:
def people_info(name: str, sex: str, age: int):
"""
返回对应的人物信息
:param name: 姓名
:param sex: 性别
:param age: 年龄
:return: 人物信息
"""
if sex not in ['男', '女']:
return '性别输入错误,请输入正确的性别男或者女'
adult = {'男': '先生', '女': '女士'}
minor = {'男': '小弟弟', '女': '小妹妹'}
if age >= 18:
return f'{name}{adult[sex]}今年{age}岁'
else:
return f'{name}{minor[sex]}今年{age}岁'我们标注号参数的类型后,别人在使用help函数或者在Pycharm中直接查看时,都会显示出参数的类型,让别人更好的使用我们写的函数。
使用help函数查看
在Pycharm中直接查看
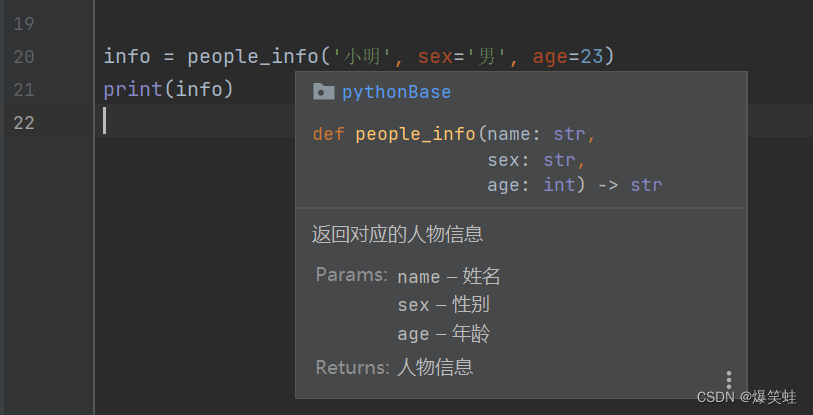
使用这两种方式查看,形参后面都会有参数的类型。这样一来别人就很容易知道每个参数该传入的类型了。
递归函数
递归函数就是一个自己调用自己的函数,当一个函数的逻辑语句中存在调用函数本身的语句时,此函数就是递归函数。为什么要叫递归函数呢,因为递归函数调用了自己,自己又会再调用自己,自己还会再调用自己。一直反复的调用本身的逻辑语句,如果没有终止条件的话,它会无限的调用下去。所以我们在写递归函数时一定要在逻辑语句中写上终止递归的条件,不然会一直递归下去。python官方考虑到了一直递归的情况,所以在python中规定的默认递归的深度为1000,如果函数栈中叠放了1000个同一个函数时,会抛出超出递归深度的错误。所以我们在写递归函数时需要提前考虑它的递归深度问题,如果递归深度超过1000需要在递归函数执行之前自定义递归深度。sys库中的setrecursionlimit函数可以设置递归深度,但真正能实现多大的递归深度和你电脑运行内存的大小以及Python的版本有关。
基本结构
def recursion():
其他逻辑语句(可有可无)
if 条件: # 加个条件防止无限递归
recursion() # 调用自己
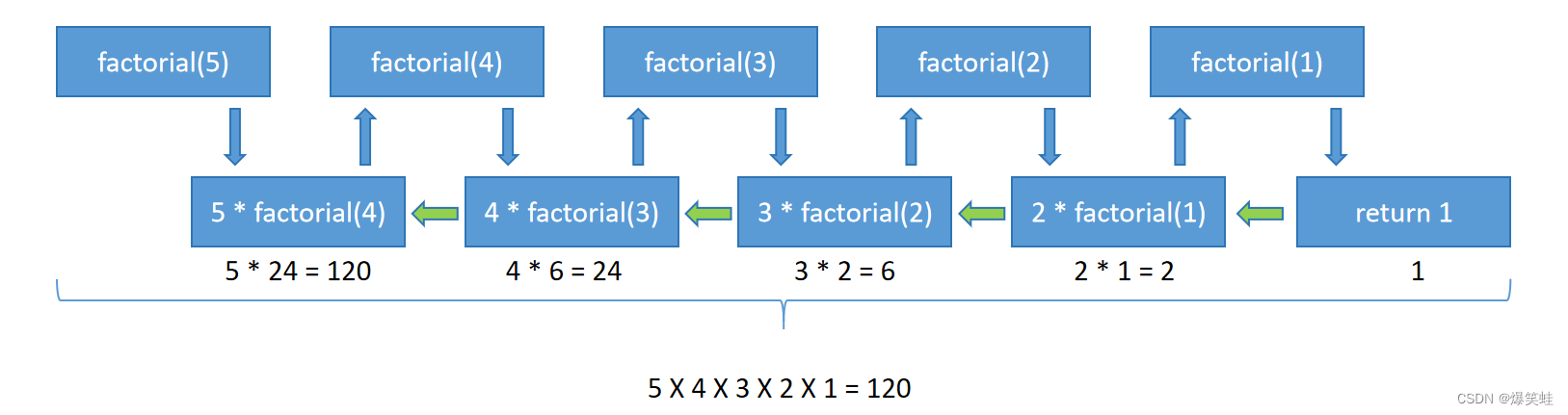
其他逻辑语句(可有可无)举个例子:我们通过递归函数来求整数的阶乘,阶乘的算法n!=1×2×3×...×(n-1)×n,使用递归的方式来定义:0!=1,n!=(n-1)!×n,重复前面的公式,每重复一次n=n-1,当n=1时结束。
def factorial(number: int):
"""
求整数的阶乘
:param number: 要求阶乘的整数
:return: 阶乘的结果
"""
if number > 1: # 控制递归,number大于1时才会递归
print(f'{number} X', end=' ') # 打印本次递归number的值
return number * factorial(number - 1) # 调用了本身
print(f'{number} =', end=' ') # 打印最后一次递归number的值
return number # 返回number,此时number的值一定为1
print(factorial(5)) # 5 X 4 X 3 X 2 X 1 = 120我们可以把调用函数factorial(n)想象成n!,因为n!=(n-1)!×n所以factorial(n)=factorial(n-1)×n。因此我们在factorial函数中写了一个语句 return number * factorial(number - 1) ,当n=1时结束递归,所以我们加了一个if判断语句来控制递归的结束。执行结果如下:

不能理解上面递归函数factorial的时候尝试如下方式:
递归深度
函数递归的深度就是看它在同一时间点上,它能叠放多少层(俄罗斯套娃)。我们使用上面阶乘函数的例子,可得到如下结构:
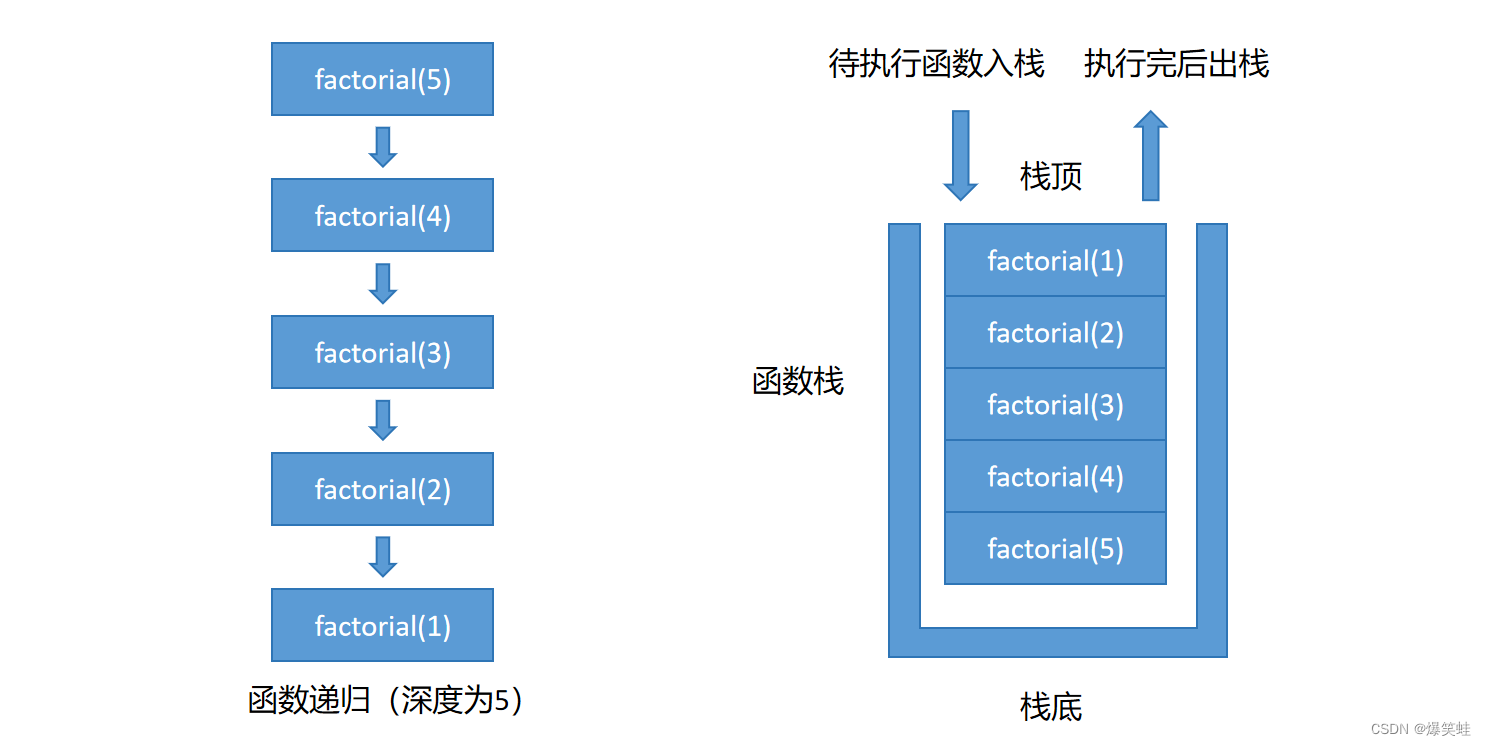
factorial(5)率先入栈,执行过程中调用了factorial(4);factorial(4)进入函数栈,此时递归深度为2,执行过程中调用了factorial(3);factorial(3)进入函数栈,此时递归深度为3,执行过程中调用了factorial(2);factorial(2)进入函数栈,此时递归深度为4,执行过程中调用了factorial(1);factorial(1)进入函数栈,此时递归深度为5。factorial(1)执行后返回值1,factorial(1)执行完毕退出函数栈释放占用资源;factorial(2)得到factorial(1)的返回值1计算出2 * 1的结果,并返回结果2,factorial(2)执行完毕退出函数栈释放占用资源;factorial(3)得到factorial(2)的返回值2计算出3 * 2的结果,并返回结果6,factorial(3)执行完毕退出函数栈释放占用资源;factorial(4)得到factorial(3)的返回值6计算出4 * 6的结果,并返回结果24,factorial(4)执行完毕退出函数栈释放占用资源;factorial(5)得到factorial(4)的返回值24计算出5 * 24的结果,并返回结果120,factorial(5)执行完毕退出函数栈释放占用资源。
递归广度
当我们在一个函数中多次调用自己的时候,就会形成一个拥有一定递归广度的递归函数。举个例子:我们通过函数递归来给列表排序,即递归排序。递归排序就是通过不断的从中间位置分割列表,递归一次就分割一次,一直分到分不动位置(只有一个元素或没有元素)。然后比较左右两个元素的大小,按大小顺序重新放到一个列表中;再比较两个有序列表中每一个元素的大小,按照大小顺序再放入一个新的列表中;一直比较有序列表直到第一个递归函数出栈,即可得到一个有序列表。

一个有递归广度的递归函数递归过程看起来就类似二叉树的结构,二叉树的分支有多少递归的广度就有多大。根据上面的原理图我们可以得到如下递归排序函数。
def recursive_sort(listing: list):
"""
递归排序
:param listing: 需要排序的列表
:return: 有序列表
"""
length = len(listing) # 通过len函数得到列表的长度
if length <= 1: # 判断列表的长度是否小于等于1
return listing # 是则返回该列表
middle = length // 2 # 取列表长度的中位数
left = recursive_sort(listing[:middle]) # 根据中位数取出列表的左半部分继续递归
right = recursive_sort(listing[middle:]) # 根据中位数取出列表的右半部分继续递归
order_list = [] # 定义一个空列表用来按大小顺序存放元素
while left and right: # 使用循环来清空任意一个列表
if left[0] < right[0]: # 判断左边列表的第一个元素是否小于右边列表的第一个元素
order_list.append(left[0]) # 如果是则左边列表的第一个元素加入order_list中
del left[0] # 删除左边列表的第一个元素
else: # 否则
order_list.append(right[0]) # 右边列表的第一个元素加入order_list中
del right[0] # 删除右边列表的第一个元素
order_list += left # 拼接左边列表(有可能是空列表,有可能不是空列表)
order_list += right # 拼接右边列表(有可能是空列表,有可能不是空列表)
return order_list # 返回有序的列表
list1 = [6, 3, 9, 1, 4, 7, 2, 8, 5]
print(recursive_sort(list1))执行结果如下:

深度优先
递归的深度优先就是以递归的深度作为停止递归的条件,当递归的深度达到某个值时就结束递归,而不用去在意递归的广度是多少。例如马踏棋盘这种算法就属于深度优先,当递归深度达到64的时候就得到了一种马踏棋盘的路径。
广度优先
递归的广度优先就是以递归的广度作为停止递归的条件,当递归的广度达到某个值时就结束递归,而不用去在意递归的深度是多少。例如递归排序这种算法就属于广度优先,当递归广度达到列表长度的时候才能实现列表的排序。
回调函数
要了解回调函数我们首先要知道一个知识点,当我们定义一个函数A后,如果只使用函数名A表示存放这个函数逻辑的地址,如果使用A()表示执行函数A。没有括号表逻辑地址,加上括号表示执行逻辑。
def hello():
print('hello world')
print(hello) # 打印出hello函数的地址(16进制)
hello() # 执行hello函数执行结果如下:

回调函数就是:把函数A作为参数传递给函数B,再由函数B中的逻辑来决定什么情况下调用函数A,以及给函数A传递什么样的值。当函数B调用函数A时,就被称为函数回调,函数A就是回调函数。因为回调函数可以被异步调用,所以常被用于多线程程序中。
def person(func, *args, **kwargs):
"""
人类行为
:param func: 行为函数
:param args: 位置参数
:param kwargs: 关键字参数
:return:
"""
func(*args, **kwargs)
def eat(food: str, weight: int):
"""
吃东西行为
:param food: 食物名称
:param weight: 食物重量
:return:
"""
print(f'正在吃{weight}斤重的{food}')
def walk(road: str, status: str, feeling: str):
"""
走路行为
:param road: 道路类型
:param status: 道路状况
:param feeling: 心情
:return:
"""
print(f'心情{feeling}的走在{status}的{road}上')
person(eat, '西瓜', 5)
person(walk, '小路', feeling='沮丧', status='泥泞')执行结果如下:

我们把eat函数和walk函数传入到person函数进行调用,调用过程被称为函数回调,eat函数和walk函数被称为回调函数。eat函数和walk函数未被person函数调用时,它们只是普通函数。
在多线程中的使用
多线程的运用可以提高我们程序的执行效率,不用在主线程中一个一个的去执行函数,可以在多个线程中同步执行多个函数,多线程之间可以通过公共变量来交流信息。
import threading # 使用import导入线程库
import time # 使用import导入时间库
def thread_ui(func, *args, **kwargs):
"""
多线程执行任务
:param func: 任务函数
:param args: 位置参数
:param kwargs: 关键字参数
:return:
"""
thread = threading.Thread(target=func, args=args, kwargs=kwargs) # 定义子线程
thread.setDaemon(True) # 开启线程守护,如果进程结束时该线程未结束,进程会强行结束该线程,保证进程资源全部回收
thread.start() # 执行线程
return thread # 返回线程
def get_thread_name():
"""获取线程名"""
return thread_1.getName() # 使用Thread类中的实例函数getName得到线程名,thread_1是公共变量
def print_time(func):
"""
打印时间
:param func: 获取线程名的函数
:return:
"""
time.sleep(1) # 停止1秒,保证下一行代码是异步进行
thread_name = func() # 异步获取运行自己的线程的线程名
for i in range(3):
print(f"线程{thread_name}报时:{time.strftime('%Y-%m-%d %H:%M:%S')}")
time.sleep(1)
print(f'线程{thread_name}结束')
thread_1 = thread_ui(print_time, get_thread_name) # 执行线程任务,并把线程赋值给公共变量thread_1
while thread_1.is_alive(): # 使用循环来监听子线程是否结束,监听期间也可以去执行其他任务,Thread类中的实例函数is_alive可以得到线程是否存活
print(f'子线程{thread_1.getName()}未结束,主线程继续监听')
time.sleep(0.5)
print(f'子线程{thread_1.getName()}已结束')
print('未接到其他新任务,结束主线程')执行结果如下:
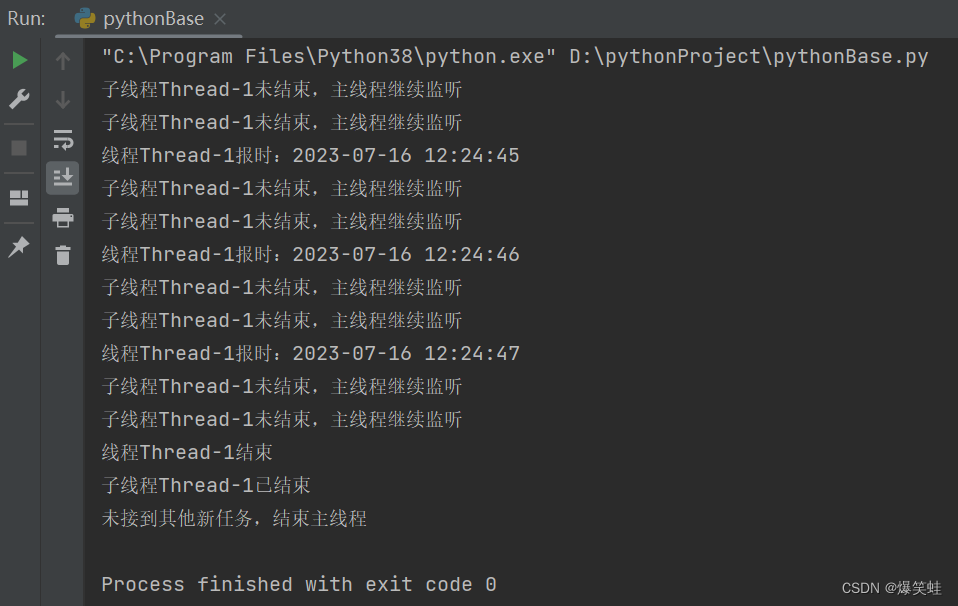
在上面的例子中我们多次使用了回调函数,在执行线程任务的时候我们把print_time函数传给了thread_ui函数,在定义线程的时候又把get_thread_name函数传给了print_time函数。在子线程中回调print_time函数,保证print_time函数的执行不会阻塞主线程。在print_time函数中回调get_thread_name函数,异步获取了运行print_time函数的线程的线程名,这只能通过异步获取。同步获取的话,公共变量thread_1还未被定义。因为print_time函数是在thread_1中运行的,在thread_1运行print_time函数之前,print_time函数不可能提前了解thread_1。就像我们人类是在地球上诞生的,人类不可能在人类诞生之前就知道地球了。
闭包函数
闭包函数就是:在函数A中定义一个函数B,函数A返回函数B;我们执行函数A的时候得到的是函数B,但函数B的逻辑又是由函数A提前控制的。所以闭包函数是一种可以动态生成函数的函数,我们给函数A传入不同的值,函数A就可以通过传入的值来给函数B生成不同的计算逻辑,最后再返回函数B。闭包函数常被我们用于装饰器函数(装饰器)中,我们下一篇文章就会讲到装饰器。
def people_info(if_adult: bool):
"""
返回描述人物信息函数
:param if_adult: 是否成年
:return: 描述人物信息函数
"""
if if_adult: # 通过if_adult来给局部变量info赋予不同的值
info = {'男': '先生', '女': '女士'}
else:
info = {'男': '小弟弟', '女': '小妹妹'}
def description(name: str, sex: str, age: int):
"""
描述人物信息
:param name: 姓名
:param sex: 性别
:param age: 年龄
:return:
"""
print(f'{name}{info[sex]}今年{age}岁') # 使用了局部变量info,但info受people_info函数控制
return description # 返回description函数
adult = people_info(True) # 得到描述成年人的description函数,并赋值给变量adult
minor = people_info(False) # 得到描述未成年的description函数,并赋值给变量minor
adult('小明', '男', 20)
adult('李梅', '女', 20)
minor('小明', '男', 16)
minor('李梅', '女', 16)局部变量info的作用域在整个people_info函数范围内,description函数也属于people_info函数内的逻辑语句,所以description函数可以直接使用变量info。执行结果如下:

我们给people_info函数传入不同的值,就会得到不同逻辑的description函数,我们再去调用不同的description函数,就可以得到不同的输出。
我们前面讲过当一个函数执行完毕,退出函数栈的时候会释放掉占用的资源。但闭包函数是个例外,当外层函数执行完毕释放资源的时候,发现内部函数会使用到它的局部变量,它会把这个局部变量转交给内部函数,然后再结束自己。就相当于people_info函数的局部变量info直接变成了description函数的局部变量。
除了在装饰器中使用闭包函数以外,我使用过闭包函数的场景是在Pyside6框架中,例如鼠标事件可以是按下、抬起、移动,我们只需要写一个鼠标事件函数来接收不同的鼠标事件,通过传入事件的类型来动态的制作要执行任务的逻辑,然后再返回这个逻辑。可以完成一些拖拽事件的处理,例如屏幕使用鼠标滑动、把一个页面元素从一个位置拖动到另一个位置。
多态函数
在C++和Java中我们都能经常看到多态函数,多态函数就是多个函数名相同,但传入的参数个数或类型不同,返回值类型不同的函数。它们被称作一个函数的多态性,多态是面向对象编程的特性之一。在Python中,我们看不到多态函数的写法,因为Python中任意一个函数都是多态函数。C++和Java中能看到多态函数是因为它们死板的格式化写法,Python中的代码写法灵活一些,是因为python解释器帮我们做了太多的工作,所以Python的运行速度比Java要慢。
我们在Python中定义一个有参函数,我们可以给这个函数传入任意的值。在我们没有标注参数类型的时候,参数的类型是Any表示任意类型;即使我们标注了参数类型,还是可以传入其他类型的参数。Python中函数参数的类型定义是在python解释器解释代码的时候,看我们传入的值是什么类型就给参数定义什么类型,所以python解释器后期的工作量比较大。因此我们随便定义一个函数都是自带多态类型的函数,所以Python中不允许出现同名函数,一个函数名只能定义一个函数。
但是我们在Python中还是可以定义描述上的多态函数,因为Python中函数自带多态属性,所以我们强行写的多态函数只是描述上的多态。是用来描述给调用我们写的函数的人看的,当我们定义的函数中使用了*args或**kwargs时,方便别人能更好的调用我们的函数。
在Python中描述多态函数需要使用typing库中的overload装饰器,被overload装饰过的函数可以重复定义。但是被overload装饰过的函数不会被python解释器执行,所以被overload装饰过的函数中不需要有逻辑语句。我们写了多个被overload装饰过的函数后,要写一个不用overload装饰的同名函数,这个函数才是真正能被python解释器执行的函数,所有的多态逻辑都要写在这个函数里面,参数就使用*args或**kwargs来保证多态传参。
from typing import overload, Union # 从typing 中导入overload和Union
@overload
def add(number_a: int, number_b: int) -> int:
...
@overload
def add(number_a: str, number_b: str, number_c: str) -> int:
...
def add(*args: Union[int, str]) -> int: # 使用Union标注位置参数的类型只能是整型或字符串
"""
求和
当传入两个整数时,直接返回求和结果
当传入3个字符串时,转换为整型后再返回求和结果
:param args: 位置参数
:return: 求和结果
"""
if len(args) == 3:
number_a = int(args[0])
number_b = int(args[1])
number_c = int(args[2])
return number_a + number_b + number_c
else:
return args[0] + args[1]
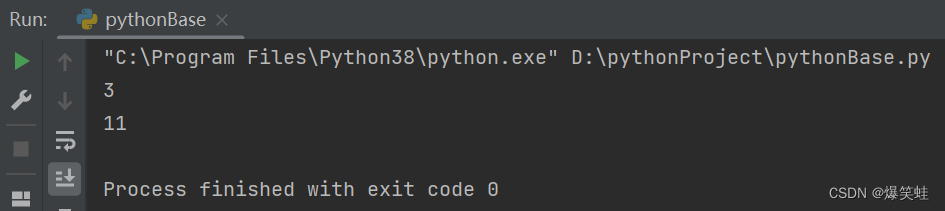
print(add(1, 2))
print(add('2', '3', '6'))我们定义了3个add函数,前面两个都是被overload装饰过的。它们不会被python解释器执行,所以它们下面没有逻辑,用3个点表示略过。它们两个描述了add函数是多态的,可以接收2个整型的参数或者3个字符串类型的参数。真正执行的add函数中实现多态的逻辑,当传入3个字符串时全部转换为整型再返回求和结果,当传入两个整型时直接返回求和结果。执行结果如下:
我们在编辑器中调用add函数时会显示传参类型和个数,如下图:

所以这种多态只是作为一种描述来使用的,方便调用的人能知道有哪几种传参方式,以及返回的结果有哪些类型。C++和Java中的多态函数是自己实现自己的方法,Python跟它们有点区别。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









