






 论文介绍了Sangeun Kum在KAIST的研究,提出了一种Joint Detection and Classification (JDC)网络,用于同时从伴奏中检测歌声片段和识别基频。JDC网络通过主网络预测基频,辅助网络负责uv检测,目标函数包括离散化校正的基频估计和voice segmentation。研究使用RWC, MedleyDB, iKala等多样数据集进行泛化性训练,并评估了 pitch和voice相关指标。
论文介绍了Sangeun Kum在KAIST的研究,提出了一种Joint Detection and Classification (JDC)网络,用于同时从伴奏中检测歌声片段和识别基频。JDC网络通过主网络预测基频,辅助网络负责uv检测,目标函数包括离散化校正的基频估计和voice segmentation。研究使用RWC, MedleyDB, iKala等多样数据集进行泛化性训练,并评估了 pitch和voice相关指标。
作者:Sangeun Kum
单位:KAIST
期刊:Applied Science
文章目录
abstract
Singing melody extraction包含两方面:从带和弦伴奏中检测歌声片段,以及从歌声中检测基频。本文用joint detection and classification (JDC) 网络同时做这两件事情。模型包含主网络和辅助网络两部分,主网络用于预测基频数值,辅助网络检测uv。
introduction
- voice detection 主要是基于歌唱的颤音、发生模式和乐器声音的不同进行区分
- (1) 设定估计阈值(thresholding the likelihood of pitch estimation),方法很简单,但是不准确,因为对应的比例会随着voice和背景音的比例变化。
- (2)分离的模型:因为是单独的专用模型,会增加系统的复杂度;
- (3)直接添加uv信息:在基于分类的旋律提取的任务中是有效的,已知voice seg,输出就是选择一个类别作为目标pitch。
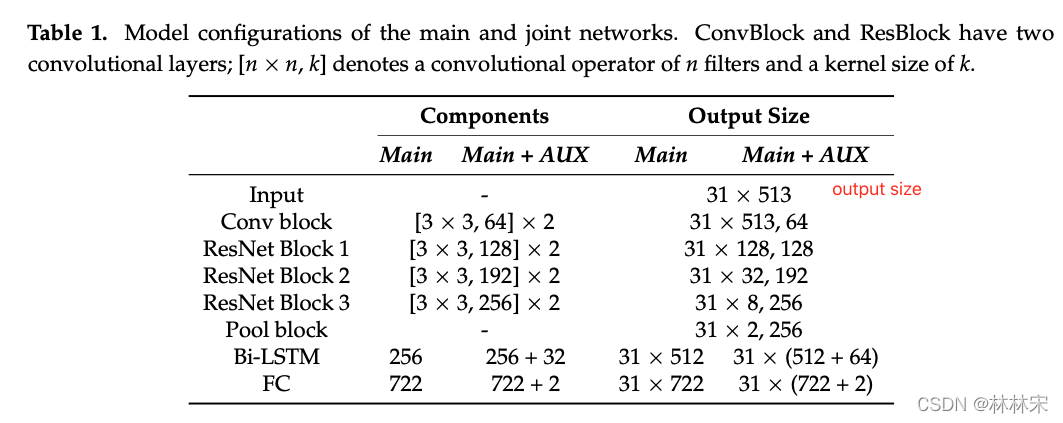
The Main Network
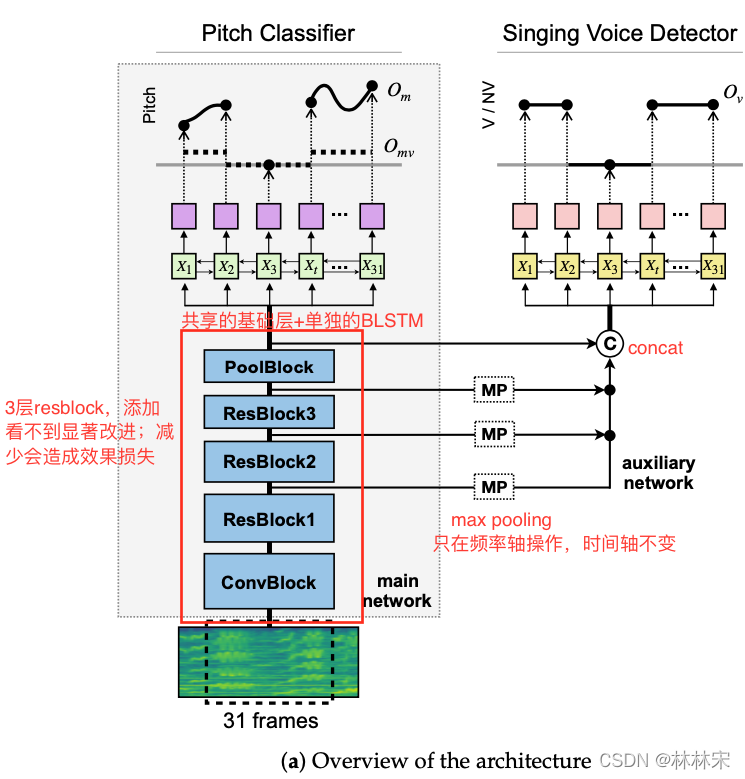
pitch labels和non-voice label被当作模型一个级别的分类。实际上,这两者的抽象程度是不一样的,因而提出了JDC网络。
max-pooling的操作是为了确保与输出的维度一致,BLSTM+softmax函数从拼接的特征中预测voice的概率。
- FC预测722个pitch label
pitch范围D2 (73.416 Hz) to B5 (987.77 Hz),中间间隔45 个midi-note, 1/16 semitone的区间划分,一共720个label,同时会加上2个uv label - 输入31帧连续的对数幅度谱
目标函数
-
pitch估计:
- 将连续的基频数值离散化处理,因为每个量化区间只有6.25 cents,很可能会被误判,因此添加 Gaussian-blurred version 做修正

- 将连续的基频数值离散化处理,因为每个量化区间只有6.25 cents,很可能会被误判,因此添加 Gaussian-blurred version 做修正
-
voice seg估计:
-
O m v 和 O v O_{mv}和O_{v} Omv和Ov分别是main模型和辅助模型的softmax输出
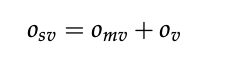
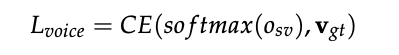
-
total loss
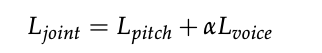
其中, α \alpha α需要根据实验调整,会影响最终效果。 -
JDC网络和loss函数的设计,在ablation test中验证都是正向的。
Experiments
Dataset
- 考虑流派和歌手风格 RWC & MedleyDB & iKala,进行pitch 正负1,2 semitone的移动,使得模型具有更强的泛化性。其他singing voice activity detection和melody extraction实验中都证明了这个观点。
Evaluation
-
pitch相关的指标

-
voice相关的指标

-
两者综合的指标
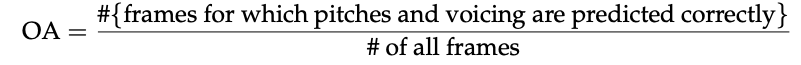
Case Study of Melody Extraction on MedleyDB
在一些人声特别小,或者背景和弦音特别大的时候,提取都会不准,因为是data-driven的方式,因此可以通过在训练数据中调节vocal增益混合的比例。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









