







文章目录
- demo page
- Ziyue Jiang & Yi Ren
mega-tts1
abstract
-
demo page: https://mega-tts.github.io/demo-page/
-
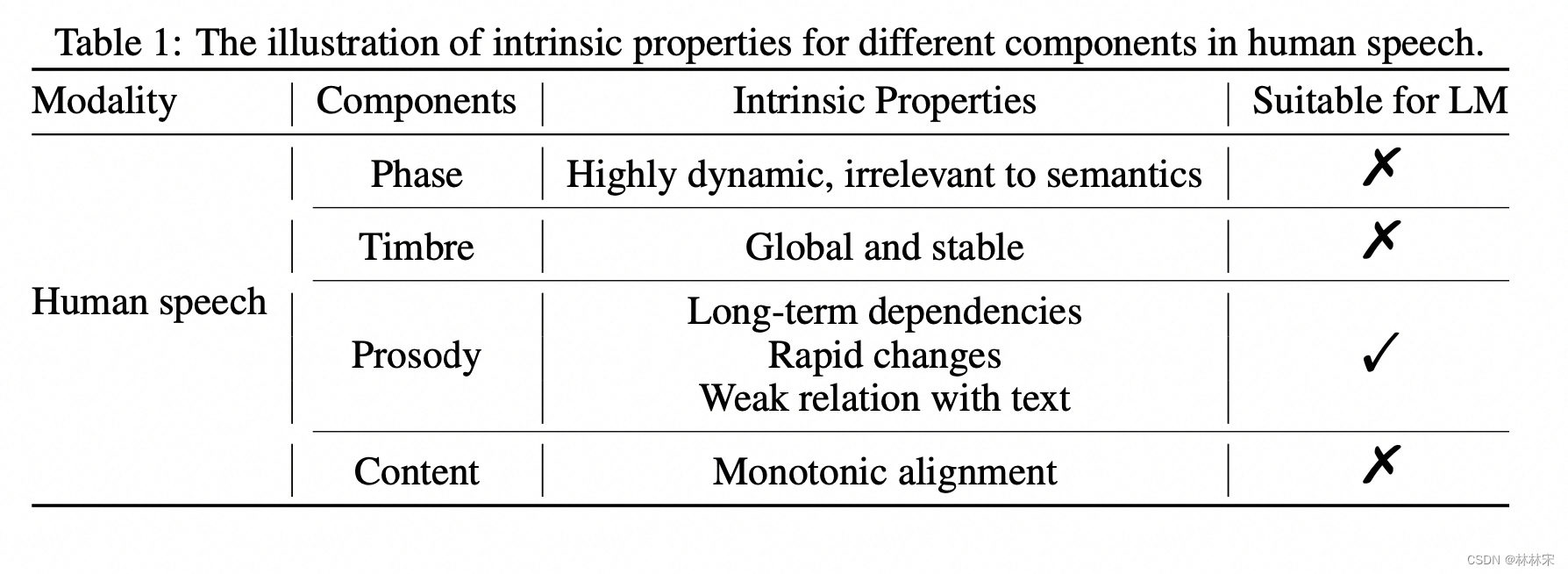
motivation:现有的基于codec量化+LLM做TTS的思路,忽略了音频的内在联系,因此系统缺乏可控性;本文提出将音频按照代表的信息,拆解为几个特征(content, timbre, prosody, and phase),然后单独建模。
-
做zero-shot任务和speech edit任务;
-
拆分特征:
- phase:使用mel spec,自动分离了相位,最后使用GAN Vocoder 恢复;相位变动也很剧烈,但是人耳对相位并不敏感,所以只要波形重建的时候给一个合理的相位即可,没必要浪费算力去建模各种可能的相位信息,这也是GAN-Vocoder流行的原因;
- timbre: global embedding,speaker encoder使用一个人不同的句子,得到 speaker embedding,同时做到content和timbre的解耦;
- prosody:因为韵律变化的非常快&剧烈,而且人耳对韵律的变化很敏感,用LLM建模,LLM擅长于捕捉局部&长时相关信息;
- content:和音频是单向对齐的关系,自回归可能会出现repeat/skip word的问题;VQ-GAN based声学模型生成mel spec;
-
数据:20k小时,8*A100
methods
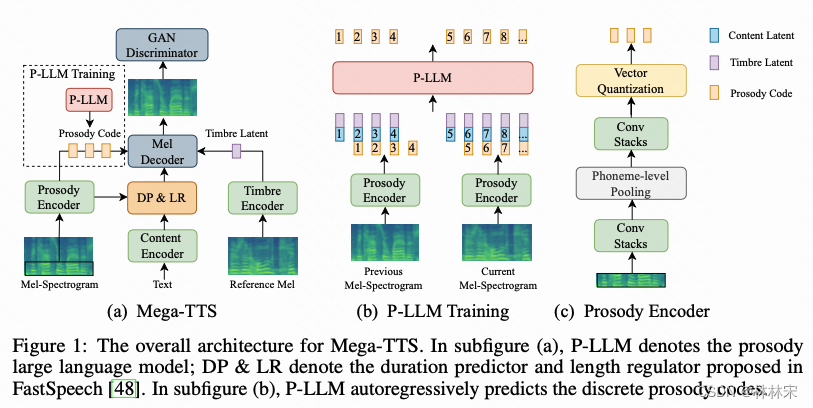
PLM:prosody information language model
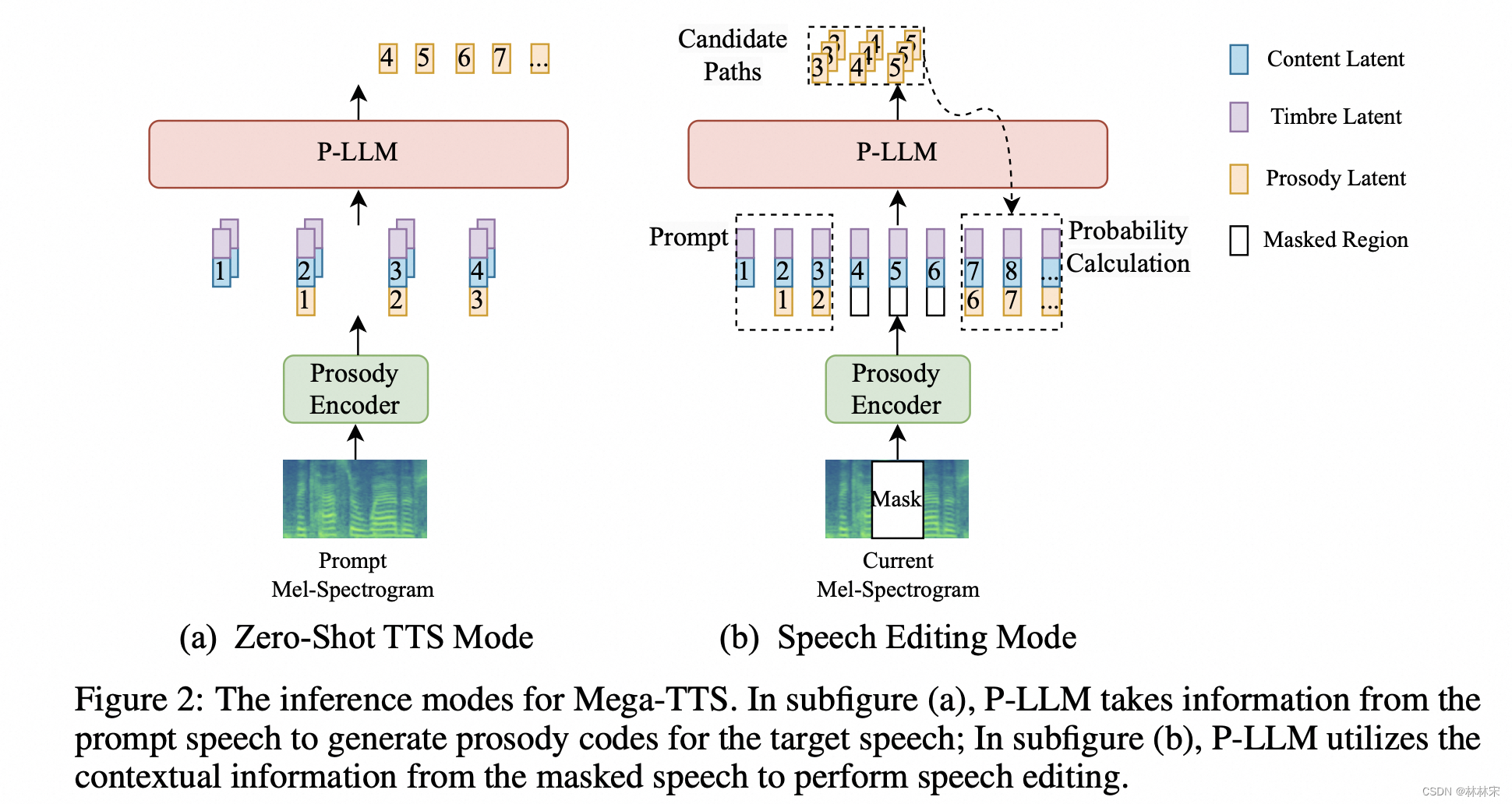
- PLM的设计思考:因为要用LLM建模,所以prosody encoder的输出要做量化,所以选用的是VQ-prosody encoder。建模单元:音素级别。
- 输入:timbre/content/pre-prosody
- 为了减少phn-to-mel一对多预测困难的问题,PLM的结果,会送给duration predictor。
- PLM自回归预测prosody target,单次的预测结果加sample-based method,有助于增加生成语音的多样性;生成的 u p r e d u^{pred} upred和音素等长,直接拼接;
- 模型包含两个部分:(1)phoneme-level pooling layer,输入mel80的前20维(低频的band,所有的韵律信息和很少的音色/内容信息),按照音素时长,将帧级别的mel压缩到音素级别(2)VQ bottleneck,对韵律特征离散化——作者认为这里得到的基频参考,和音色无关。
- 训练阶段prosody encoder和TTS模型一起训练,有vq loss加入;通过控制特征的dim和时长上的压缩,实现bottleneck。
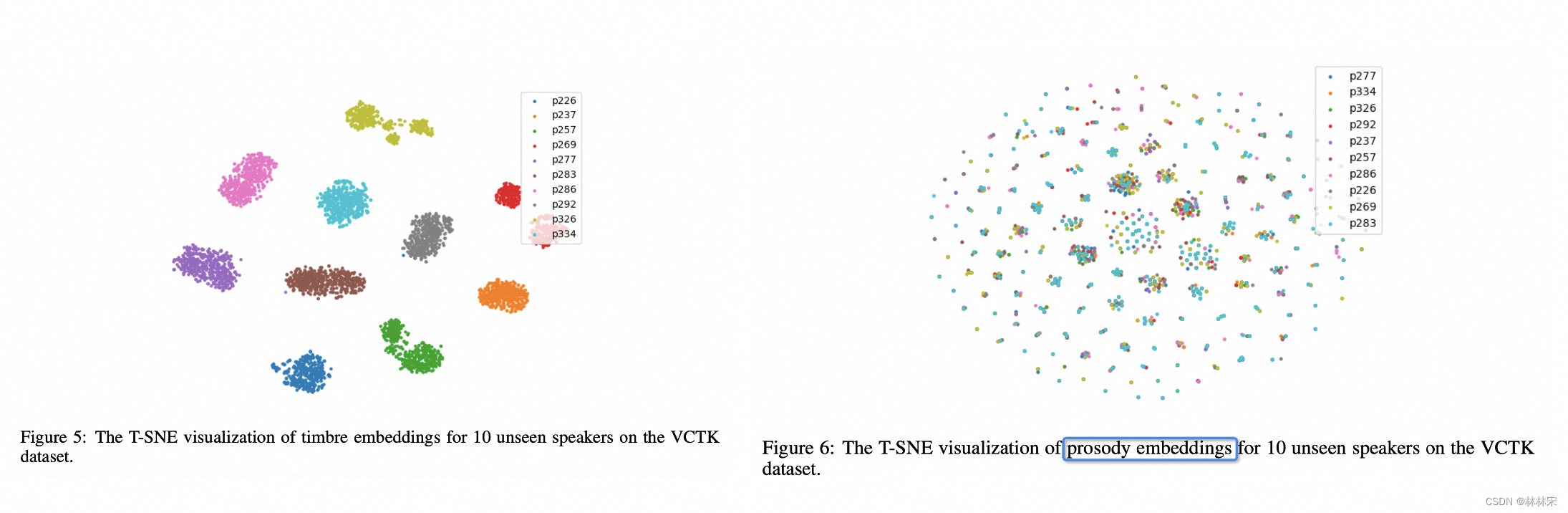
- 证明prosody embedding中确实没有音色信息。
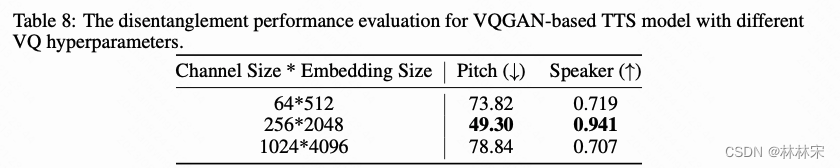 - VQ的超参数包括channel维度和量化的特征维度,维度过大或者过小都会影响性能。进行实验验证PLM得到的基频特征和timbre embedding得到的音色特征都已经很好的解耦
- VQ的超参数包括channel维度和量化的特征维度,维度过大或者过小都会影响性能。进行实验验证PLM得到的基频特征和timbre embedding得到的音色特征都已经很好的解耦
- 实验1:集外说话人 timbre embedding和PLM embedding的特征分布;---- timbre embedding分布和说话人聚类一致,PLM embedding分布和说话人聚类无关;
- 实验2:句子A和句子B经过prosody encoder和timbre encoder的到的特征【Pa, Ta】,【Pb, Tb】, 【Pb,Ta】、【Pa,Tb】交换作为prompt,计算合成音频和prompt speech的pitch distance以及说话人相似度;256*2048是最好的组合。
mega-tts2
- demo page: https://mega-tts.github.io/mega2_demo/
abstract

- motivation:常规的zero-shot TTS任务,从ref audio中提取global embedding,可以代表语音。但实际上,音频说话人相似度的判断,除了音色,还有口音、语速等音素,这些更多和细粒度的特征有关系,global embedding不能完全代表。
- 本文通过一个speech prompt,给多个说话人参考,
- megaTTS2相比于megaTTS1的创新点在于,MRTE(Multi-reference timbre encoder)引入mel-to-phn attention,即mel特征和phn特征直接attention,使得文本获得更多的音素级别韵律&说话人参考。
- 时长预测模块修改为自回归的结构,为了学习更多的in-context info。
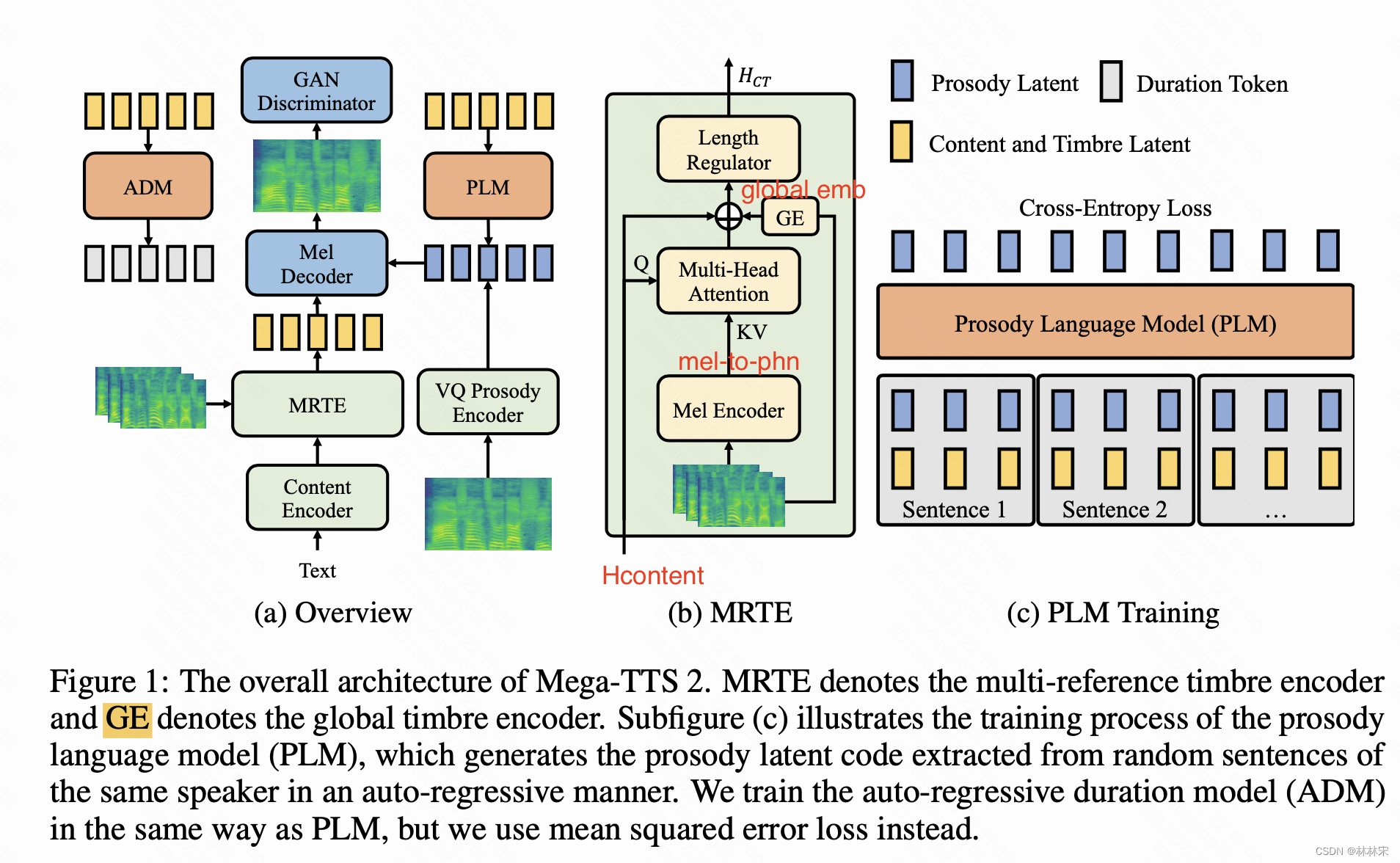
MRTE:Multi-reference timbre encoder
- phn从mel中,找到细粒度的发音特征(语义和发音的对应关系):query:phn-content 【B, T1, D】和value/key:mel-embedding【B, T2, D】计算attention,得到 H C T H_{CT} HCT–【B, T1, D】,和phn等长;
- global embedding,最后加在 H C T H_{CT} HCT上;
- 疑问点:inference的时候,mel-encoder输入的mel从哪里来呢?
- mel encoder仅在train的阶段使用,得到mel VQ的结果。infer阶段,是由PLM自回归的预测Prosody VQ结果,不再需要mel encoder。PLM是单独训练的。
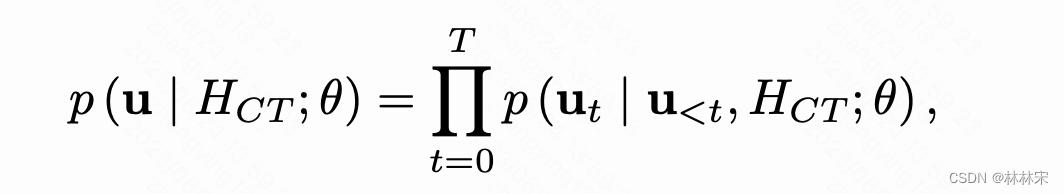
- 自回归的decoder,以VQ的结果为目标,预测韵律编码,类似于teacher-forcing的训练,使用CE Loss;
- 认为此结构前端参考越长,韵律信息建模的越好;训练时候,单个batch语音最长32000帧,会把一个说话人的所有音频拼接在一起,如果不够max_length,自回归的时候做mask;
ADM: Auto-regressive duration model
自回归结构的时长预测,可以更好的利用in-context learning的能力,结构和PLM一样,使用MSE loss,
experiment
数据
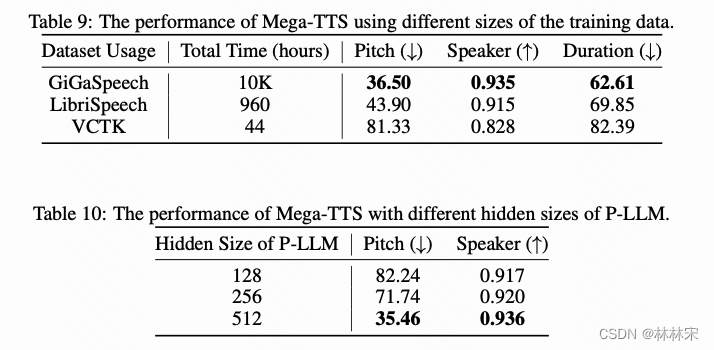
- zero-shot效果会随着数据量的增加显著变好(table 9)
- PLM模型的增加,有助于细粒度韵律建模,也会明显提升zero-shot效果
项目参与者记录
mega-tts2,一来建立的是prompt和target之间的联系(噪声、背景音也在这种联系中);二来VQVAE会吸收掉一定程度的噪声。所以在测试过程中,有尝试过用一些名人的综艺进行生成,这些音频带有背景音乐。会发现生成的样本中也有微弱的背景音乐。并且prompt是音乐,生成的就是音乐,prompt是底噪,生成的也会有一定底噪。
可以理解成训练数据中,有噪声样本wenetspeech,有相对干净样本librilight和一些其他的中文数据。mega-tts2希望能够尽可能模仿prompt,所以噪声样本是有必要存在数据集中的。个人观点是这样的
MRTE:兼顾计算效率和生成效果,一般1000~2000帧比较合适,可以设置一个定值;inference的时候,太短就repeat,太长就截断;
-
抛开LM(因为推理过程才用到,可以用真实mel输入prosody encoder替换) 这个框架就是一个带prosody encoder的GAN-speech 想复现 可以直接fastspeech+gan+prosody_encoder 在开源数据上训 然后推理用真实mel就好
-
Mega2的prosody encoder采用的不是phoneme pooling了,用的是stride=8(统计中数据集的平均phoneme长度约等于9.1);PLM 输入是文本+音色+韵律。真值是用GT mel,使用prosody encoder提取出来的code
-
数据处理:megaTTS没有做降噪,会在mfa阶段丢弃一些不好的数据;大数据是关键;
-
phn-pooling的结构是关键----prosody encoder选择mean-pooling=8,因为统计数据集的phn-dur平均值为9.1(phoneme pooling或者8倍pooling,个人认为8倍会好一点,比phoneme更鲁棒,因为脏数据提取的phoneme边界不太准确),content length需要用对齐信息扩展到T,然后//8。 乍一听这两套方案应该是差不多的,我们也是都做了实验才发现prosody code=T//8会更好一些;
-
推理时PLM的文本输入是prompt文本和target文本,PLM是有prompt依据的一对多,prompt信息在大数据量脏数据的时候是特别关键的;训练的时候也是 目标文本+很多prompt文本+很多prompt韵律–>目标韵律;感觉plm利用了大量的prompt对处理带噪数据很有用,如果噪声被prosody vq建模,训练PLM时,大量的prompt中有干净的数据有噪声数据。PLM可以将干净数据和脏数据隔离开—这个结论是建立在vq能对噪声建模的假设之上,如果vq的信息能很好的表示干净数据和带噪数据,那么llm很容易学到;
加适当英文是对中文有提升的,但是英文数据尽量不要远大于中文; -
分离Demcus 可以选质量低点的

















 4386
4386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









