







文本语义向量的应用场景(搜索、对话和推荐)
所谓"万物皆可embedding",在nlp的领域中,回想一下,起初用于把文字转化向量,用的是最基础的词袋模型,类似于one-hot,不得不说,这种做法很简单粗暴,但问题是维度过高,并且有些词出现多次一般来说更重要,而这种词袋模型无法表示这种情况。
于是出现了以频率为权重的词袋模型,这种词袋模型认为频率高的词有着更高的重要度,但是常识告诉我们,出现多次的词并不一定是更重要的词,比如一些停用词,出现次数极多,却是无关紧要的。
接着出现了TF-IDF,该模型用词频和逆文档词频来综合衡量一个词的重要程度,应用很广泛,很多搜索场景下term weight 权重用的就是这个,然而,也有问题,TF-IDF无法表示出文本中的顺序信息,“我爱GTL”和“GTL爱我”显然完全是两个意思。
为了解决这个问题,人们转而使用了N-gram,N-gram模型能够表示词与词之间的顺序关系,但是还有问题,其无法识别同义词,不能够表示词与词之间的相近关系,于是在2013年,谷歌提出了word2vec,word2vec当时红极一时,用word2vec训练出来的词向量,可以很好的表示出词向量之间的相似关系,效果很好。
然而,长江后浪推前浪,前浪还是被拍死在沙滩上,再好的模型,总是有不足之处,总会有后续更好的模型出现。word2vec的不足之处在于其是一个静态的训练模型,无法表示出一词多义,你说“苹果”是指苹果公司呢,还是水果呢?我也不知道,但是上下文语境知道啊,于是出现了后续更为强大的预训练模型,诸如Elmo、GPT、Bert之类。
恩,以上算是一起回忆了文本embedding的一个发展历程,今天的正题是文本语义向量,文本语义向量其实就是一个文本语义深度embedding的过程,文本语义向量在各个应用系统中起核心支撑的作用,比如搜索引擎、智能问答、知识检索、信息流推荐等。
在真实场景中,如搜索引擎、智能问答、知识检索、信息流推荐等系统中的召回、排序环节,我们抽象总结一下,通常面临的是如下任务:
从大量存储的 doc 中,选取与用户输入 query 最匹配的那个 doc。
如果是在搜索场景下,“doc”对应索引网页的相关信息,如 title、content 等,“query”对应用户的检索请求,“最匹配”对应(点击行为)相关度最高。query 会被表征为包含文本语义和用户信息的 embedding,doc 会被表征为包含索引网页各项信息的 embedding。
如果是在对话场景中,“doc”对应 FAQ 中的 question,“query”对应用户的问题,“最匹配”对应语义相似度最高。query 会被表征为以文本语义为主的 embedding,doc 同样表征为以文本语义为主的 embedding。
如果是在推荐场景中,“doc”对应待推荐的 feed 流,“query”对应用户的画像,“最匹配”对应用户最感兴趣等众多度量标准。query 会被表征为包含文本特征各项信息的 embedding,doc 会被表征为包含用户历史、爱好等信息的 embedding。
以上是文本语义向量在不同应用场景下的差异化应用,文本语义向量在业界的实践方法(Sentence-Bert、Simcse)
实践方法(Sentence-Bert、Simcse)
Sentence-BERT
自从bert 出来之后,就在NLP各大任务中都展现出了强者的姿态。当然,在文本语义表示(semantic textual similarity)任务上也不例外。Sentence-BERT 来源于论文:Sentence Embeddings using Siamese BERT-Networks,地址:https://arxiv.org/abs/1908.10084。
使用过bert模型的用户想必知道,对于两个句子,在计算语义相似度时,需要将两个句子以"[CLS]+text_a+[SEP]+text_b+[SEP]"的形式输入模型,进行信息交互和语义计算。
假设现在存在这样一个对话场景,FAQ中有标准问答数据10000条,当用户进行提问时,常常将用户的问题与所有预先配置好的标准问进行相似度计算,找出与用户问题最相似的标准问,并返回其答案给用户,这样就完成了一次问答操作。
那么按照上文中提到的bert模型的规定,需要将用户的问题与10000条标准问中的每一条数据分别以"[CLS]+text_a+[SEP]+text_b+[SEP]"的形式输入模型,计算相似度,以此来寻找最相似的答案返回给用户,显然这种计算开销,需要耗费巨大的时长,远远无法达到上线要求。
然而Sentence-BERT网络结构的出现,解决了上文提到的这个问题,Sentence-BERT结构如下:

简单通俗地讲,就是借鉴孪生网络模型的框架,将不同的句子输入到两个bert模型中(但这两个bert模型是参数共享的,也可以理解为是同一个bert模型),获取到每个句子的句子表征向量;而最终获得的句子表征向量,可以用于语义相似度计算,也可以用于无监督的聚类任务。
那么对于刚才上文提到的那个对话场景,就可以这样操作:使用训练好的sentence-bert模型在离线时把FAQ中的标准问encoding成语义向量,并且建立语义索引,在线时,使用sentence-bert模型对用户的query进行推理获得query的语义向量,用得到的语义向量进行语义检索(毫秒级),得到最匹配的答案。
回到sentence-bert模型本身,在对sentence-bert模型进行微调时,可以设置不同的目标函数,用于不同任务的训练优化,比如训练的时候,可以当作分类任务使用交叉熵损失,也可以把输入以目标三元组的形式输入模型,使用Triplet Objective Function,具体如下图所示:

并且,在获取句子向量策略方面,CLS向量策略、平均池化策略和最大值池化策略,这三个策略中效果比较好的一般是平均池化策略。
随着GPU算力的提升,sentence-bert在工业界应用越来越普遍了,可快速上线,为业务赋能。
Simcse
Simcse来源于论文:Simple Contrastive Learning of Sentence Embeddings,论文地址:https://arxiv.org/abs/2104.08821
Simcse核心思想在于:在考虑相似样本越相似越好的同时,也就是Alignment,还考虑到了拉大当前样本和不相似样本的距离,即:uniformity。对于Alignment:代表相似样本之间距离更近,所有的样本和自己的相似样本做差平方,越小越相似。

对于uniformity:从另一个角度来考虑问题,不相关的样本越远越好。假设x和y是不相似样本,那么输出的向量f(x)和f(y) 越远,uniformity越小。

这里说的相似样本我们称之为正例,不相似的样本我们称之为负例,如何为每个样本构造正样本与负样本是对比学习中的关键问题。
Simcse可分为无监督Unsupervised-simcse和有监督Supervised-simcse,先来说说无监督的Unsupervised-simcse,如下图所示,


整体来说,分子越大,分母越小,最后损失就越小,越能达到对比学习的思想,在规模为N的batch中,第i个样本对应的InfoNCE损失为:

原理和损失函数都有了,接下来就是如何构造正负例了。
正例构造: 给定输入,用Bert Encoder两次得到的两个向量和作为正例对。由于Bert本身就有随机DropOut 功能,所以同一句话 走两次Bert,得到的两个向量不同,但是是相似的。因为原样本和生成的正样本的语义是完全一致的,只是生成的embedding不同而已,可以看做Bert Encoder过程中,对数据做了一个小增强。
**负例构造:**使用in-batch negatives的方式,即随机采样一个batch中另一个输入作为的负例。说白了就是batch中其他的样本就是负例。
为什么会work?
对比学习的思想来源于cv,对于图片的数据增强,一般基于图片进行缩放、旋转、裁剪等操纵得到正例,对于文本,无非对输入的原始词做改变,无论是删除,替换,回译等等吧,毕竟是源头上,离最后的输出太远了。而 Dropout基本上是最后的阶段,干掉一些神经元,可能效果更直接一些。
接着来说说有监督的Supervised-simcse,如下图所示,损失函数改变了,正负例构建也有所不同,正例就是人工标注的相关的,负例就是batch中其他的负样本。


整篇论文的亮点:1.考虑到了拉大当前样本和不相关样本的距离,uniformity。 而原始的Bert仅仅考虑了相似样本越相似越好,不会考虑不同的样本间的距离增大,也就是Alignment。2.Dropout在Encoder内部干预,要比源头增强更好,更直接,虽然看起来简单粗暴,但确实work。
文本语义向量在业界的应用实例(地图搜索和淘宝电商搜索)
接下来讲解两个特定场景的文本语义向量的应用实例,分别是地图垂直搜索场景和淘宝电商搜索的场景。
这两个场景下都可以使用上文提到的文本语义向量的实践方法,即:MatchPyramid、Sentence-Bert、Simcse,由于MatchPyramid早期用的比较多,bert出来之后,现在效果好且比较主流的是Sentence-Bert和Simcse,接下来我们看下这两个文本语义实践方案具体是怎么实现的。
首先看Sentence-Bert模型如何实现的:
class TextBackbone(torch.nn.Module):
def __init__(self,
pretrained='../bert_model_data/pre_bert/torch_roberta_wwm',
output_dim=128) -> None:
super(TextBackbone, self).__init__()
self.extractor = BertModel.from_pretrained(pretrained).cuda()
self.drop = torch.nn.Dropout(p=0.1)
self.fc = torch.nn.Linear(self.extractor.config.hidden_size, output_dim)
def forward(self, input_ids, attention_mask, token_type_ids):
#CLS向量策略
anchor = self.extractor(input_ids[:,0,:],
attention_mask=attention_mask[:,0,:],
token_type_ids=token_type_ids[:,0,:]).pooler_output
anchor = self.drop(anchor)
anchor = self.fc(anchor)
anchor = F.normalize(anchor, p=2, dim=-1)
pos = self.extractor(input_ids[:, 1, :],
attention_mask=attention_mask[:, 1, :],
token_type_ids=token_type_ids[:, 1, :]).pooler_output
pos = self.drop(pos)
pos = self.fc(pos)
pos = F.normalize(pos, p=2, dim=-1)
neg = self.extractor(input_ids[:, 2, :],
attention_mask=attention_mask[:, 2, :],
token_type_ids=token_type_ids[:, 2, :]).pooler_output
neg = self.drop(neg)
neg = self.fc(neg)
neg = F.normalize(neg, p=2, dim=-1)
return anchor,pos,neg
def predict(self, x):
x["input_ids"] = x["input_ids"].squeeze(1)
x["attention_mask"] = x["attention_mask"].squeeze(1)
x["token_type_ids"] = x["token_type_ids"].squeeze(1)
x = self.extractor(**x).pooler_output
x = self.fc(x)
x = F.normalize(x, p=2, dim=-1)
return x
这里的loss使用的是TripletMarginLoss,具体用户可以自己决定使用哪种loss。
criterion = TripletMarginLoss(margin=1.0, p=2,reduction='sum')
anchor,pos,neg = model(input_ids, attention_mask, token_type_ids)
loss = criterion(anchor,pos,neg)
接着看Simcse模型如何实现的:
class TextBackbone(torch.nn.Module):
def __init__(self,
pretrained='../bert_model_data/pre_bert/torch_roberta_wwm',
output_dim=128) -> None:
super(TextBackbone, self).__init__()
self.extractor = BertModel.from_pretrained(pretrained).cuda()
self.drop = torch.nn.Dropout(p=0.1)
self.fc = torch.nn.Linear(self.extractor.config.hidden_size, output_dim)
def forward(self, input_ids, attention_mask, token_type_ids):
#CLS向量策略
x = self.extractor(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids).pooler_output
x = self.drop(x)
x = self.fc(x)
x = F.normalize(x, p=2, dim=-1)
return x
def predict(self, x):
x["input_ids"] = x["input_ids"].squeeze(1)
x["attention_mask"] = x["attention_mask"].squeeze(1)
x["token_type_ids"] = x["token_type_ids"].squeeze(1)
x = self.extractor(**x).pooler_output
x = self.fc(x)
x = F.normalize(x, p=2, dim=-1)
return x
loss是这样计算的:
def sup_loss(y_pred, lamda=0.05):
row = torch.arange(0, y_pred.shape[0], 3, device="cuda")
col = torch.arange(y_pred.shape[0], device="cuda")
col = torch.where(col % 3 != 0)[0].cuda()
y_true = torch.arange(0, len(col), 2, device="cuda")
similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)
similarities = torch.index_select(similarities, 0, row)
similarities = torch.index_select(similarities, 1, col)
similarities = similarities / lamda
loss = F.cross_entropy(similarities, y_true)
return torch.mean(loss)
criterion = sup_loss
pred = model(input_ids, attention_mask, token_type_ids)
loss = criterion(pred)
以上是sentence-bert和simcse的参考实现,接下来讲两个具体的应用场景。
第一个地图垂直搜索场景,地图场景下,用户一般会搜地址信息或者搜某个具体的poi,这里解释下什么是poi?poi是“Point of Interest”的缩写,中文可以翻译为“兴趣点”。在地理信息系统中,一个poi可以是一栋房子、一个商铺、一个邮筒、一个公交站等,或者说现实世界里你能看见的任何一个能叫得出名字的地点都可以认为是poi。
用户在地图搜索框里面输入一个query,如果这个用户query的意图是想搜某个具体的poi,但是由于用户的query表述不清存在问题,可能是简写、多字、漏字或者错字别字造成的,那么即使数据库里存在用户想要的数据,可能也无法展现给用户。这时候就需要根据文本语义去匹配,找到用户可能想要的数据。
一般流程是离线时对数据库里数据建立语义索引,在线时,将用户query转化为语义向量,在事先建立好的语义索引中进行语义检索,寻找与用户query相匹配的数据,返回给用户,这个流程算是一个召回的过程。下面看一下在这个场景下,利用语义向量匹配进行召回的效果:
用户query 匹配召回项(poi)
九匠和牛烧肉 九匠精酿烤肉
广西中药厂 广西广康中药有限责任公司
陕西实验室台柜机商 陕西迪勒实验室设备柜机供应商
宁波莱斯小火车 宁波火车来斯主题公园
山西石膏文化厂 山西石膏旅游文化发展有限公司
佳帮手集团 佳帮手日用品有限公司
以上数据展示是文本语义向量在地图里的一个应用。
第二个是淘宝电商搜索场景,在电商搜索场景下,用户搜索行为背后是强烈的购买意愿,电商搜索质量的高低将直接决定最终的成交结果。
电商场景下,当用户搜索一个商品时,输入用户query,系统会把用户query跟数据库里商品标题进行匹配,返回最匹配的商品信息,在首页展现给用户,所以用户query和商品标题匹配效果至关重要。
整个流程跟上文描述的基本一致,首先在离线时对数据库里的海量商品标题数据建立语义索引,在线时,将用户query 深度encoding为语义向量,在事先建立好的语义索引中进行语义检索,寻找与用户query最为匹配的商品,然后再经过排序,在首页展现给给用户,这个流程算是一个召回和排序的过程的过程。下面看一下在这个场景下,利用语义向量匹配进行召回的效果:
用户query 匹配召回的商品标题信息
加绒防水雨衣套装 分体雨衣雨裤套装加厚加绒防风雨双层耐磨男女摩托车电动车送外卖
特大号罐 锦康女士真空拔罐器 丰胸罐家用气罐理疗 丰乳女用火罐美容增大罐
烤盘炭火 加厚烧烤盘家用不粘煎盘户外木炭大号烤肉盘烤鱼盘烧烤炉配件工具
红色口布 纯棉口布擦杯布专用布无痕不掉毛吸水酒店餐厅酒吧专业餐巾布折花
幼儿园小旗子 儿童幼儿园小彩旗批发做操早操器械道具舞蹈考级木柄红旗子带杆
河南皮冻 西施冻 五香猪皮冻手工熬煮 肉冻不含胶 无毛无油 即食凉菜 0碳水
以上是文本语义向量在搜索场景下(地图搜索和电商搜索)的使用案例的展示,其实不管是在哪种场景下,可以尝试多种语义向量的实践方案,并不局限于上面我提到的三种方案(MatchPyramid、Sentence-Bert、Simcse),需要根据具体场景和数据特性来做方案的选型,但就我目前的实践经验来看,Simcse在非对称语义方面要明显由于Sentence-Bert。
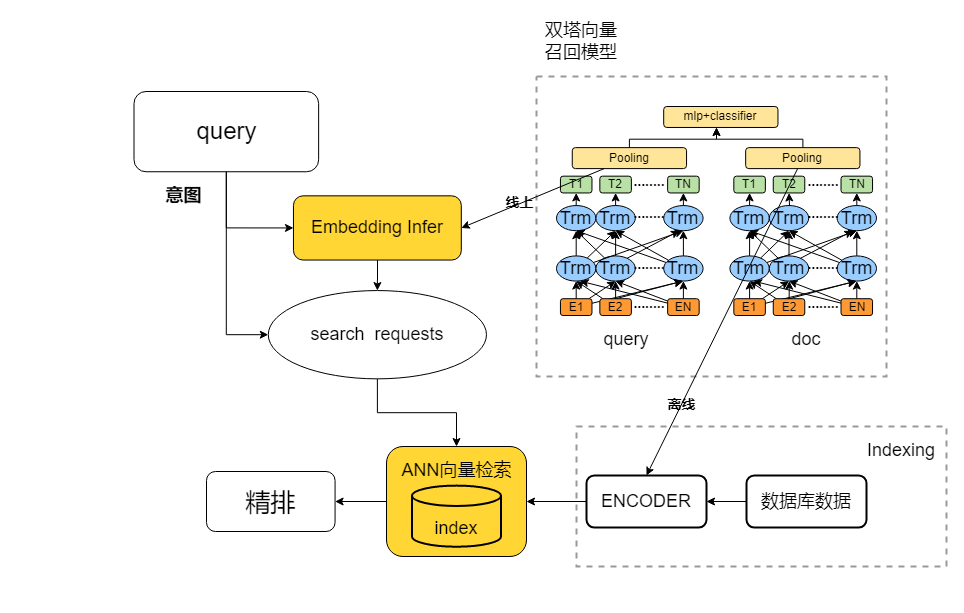
最后说一下实际应用的技术流程,如下图所示,首先离线训练好向量召回模型,然后建立语义向量索引,建立索引的用的比较多的是facebook开源的faiss工具库,也有很多大厂在此基础上做了封装。然后将向量召回模型通过tf_serving或者tensorrt+rpc部署成在线服务,对于实时请求的用户query,infer获取语义向量,进行语义检索后再精排,得到排序后的结果展现给用户。
到此内容就结束了。














 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









