








 本文详细介绍了TF-IDF的概念,包括词频(TF)和逆文档频率(IDF)的计算,以及如何结合两者得出TF-IDF值。通过实例展示了如何在多个文档中计算特定词汇的TF-IDF权重,进一步解释了TF-IDF在文本关键词提取和相关性判断中的作用。
本文详细介绍了TF-IDF的概念,包括词频(TF)和逆文档频率(IDF)的计算,以及如何结合两者得出TF-IDF值。通过实例展示了如何在多个文档中计算特定词汇的TF-IDF权重,进一步解释了TF-IDF在文本关键词提取和相关性判断中的作用。
TF-IDF基本概念
作用:提取文本关键词;计算查询内容与不同文本的相关程度等。
TF(Term Frequency):词频。也就是,如果一个词很重要,它应该在这篇文章中多次出现。
IDF(Inverse Document Frequency):逆文档频率。说人话,也就是出现频率高的词可能是一些过于常用的词,例如“的”,“是”,“我”,如果仅仅根据TF来作为衡量指标,那么结果会没有意义,所以我们需要设定IDF这个指标,它的大小与一个词的常见程度成反比。
TF-IDF:词频(TF)和逆文档频率(IDF)两个值相乘,得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
计算公式
- 词频(TF) = 某个词在文章中的出现次数
- 逆文档频率(IDF) = log10(语料库的文档总数/包含该词的文档总数)
- TF-IDF = 词频(TF) * 逆文档频率(IDF)
例题
根据路透社的806791份文档中“car”、“auto”、“insurance”和“best”这四个单词的频次,
| term | df |
|---|---|
| car | 18165 |
| auto | 6723 |
| insurance | 19241 |
| best | 25235 |
以及下表中这四个词在Doc1、Doc2和Doc3这3个文档的频次。
| tf | Doc1 | Doc2 | Doc3 |
|---|---|---|---|
| car | 27 | 4 | 24 |
| auto | 3 | 33 | 0 |
| insurance | 0 | 33 | 29 |
| best | 14 | 0 | 17 |
计算关于这四个单词的三个文件的TF-IDF的值以及TF-IDF的权重向量。
Step 1.
计算四个单词的idf值,如下表:
| term | df | idf |
|---|---|---|
| car | 18165 | log10(806791/18165)=1.65 |
| auto | 6723 | log10(806791/6723)=2.08 |
| insurance | 19241 | log10(806791/19241)=1.62 |
| best | 25235 | log10(806791/25235)=1.50 |
Step 2.
计算四个单词在三个文档中的tf-idf值,如下表:
| tf-idf | Doc1 | Doc2 | Doc3 |
|---|---|---|---|
| car | 27*1.65=44.55 | 4*1.65=6.6 | 24*1.65=39.6 |
| auto | 3*2.08=6.24 | 33*2.08=68.64 | 0 |
| insurance | 0 | 33*1.62=53.46 | 29*1.62=46.98 |
| best | 14*1.50=21 | 0 | 17*1.50=25.5 |
Step 3.
根据上表的内容,得到TF-IDF的权重向量:
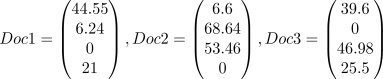

















 8119
8119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









