







kubernetes介绍和安装(1.25版本)
K8S 是什么?
K8S官网文档:https://kubernetes.io/zh/docs/home/
K8S 是Kubernetes的全称,源于希腊语,意为“舵手”或“飞行员”,基于go语言开发,官方称其是:用于自动部署、扩展和管理“容器(containerized)应用程序”的开源系统。翻译成大白话就是:“K8S 是 负责自动化运维管理多个 Docker 程序的集群”。那么问题来了:Docker 运行可方便了,为什么要用 K8S,它有什么优势?
K8S核心特性
参考官网:https://kubernetes.io/zh-cn/docs/concepts/overview/
- 服务发现与负载均衡:无需修改你的应用程序即可使用陌生的服务发现机制。
- 存储编排:自动挂载所选存储系统,包括本地存储。
- Secret和配置管理:部署更新Secrets和应用程序的配置时不必重新构建容器镜像,且不必将软件堆栈配置中的秘密信息暴露出来。
- 批量执行:除了服务之外,Kubernetes还可以管理你的批处理和CI工作负载,在期望时替换掉失效的容器。
- 水平扩缩:使用一个简单的命令、一个UI或基于CPU使用情况自动对应用程序进行扩缩。
- 自动化上线和回滚:Kubernetes会分步骤地将针对应用或其配置的更改上线,同时监视应用程序运行状况以确保你不会同时终止所有实例。
- 自动装箱:根据资源需求和其他约束自动放置容器,同时避免影响可用性。
- 自我修复:重新启动失败的容器,在节点死亡时替换并重新调度容器,杀死不响应用户定义的健康检查的容器。
K8S 核心架构原理
你需要先了解k8s的架构,以便更好的理解我们的安装步骤。
我们已经知道了 K8S 的核心功能:自动化运维管理多个容器化程序。那么 K8S 怎么做到的呢?这里,我们从宏观架构上来学习 K8S 的设计思想。首先看下图:
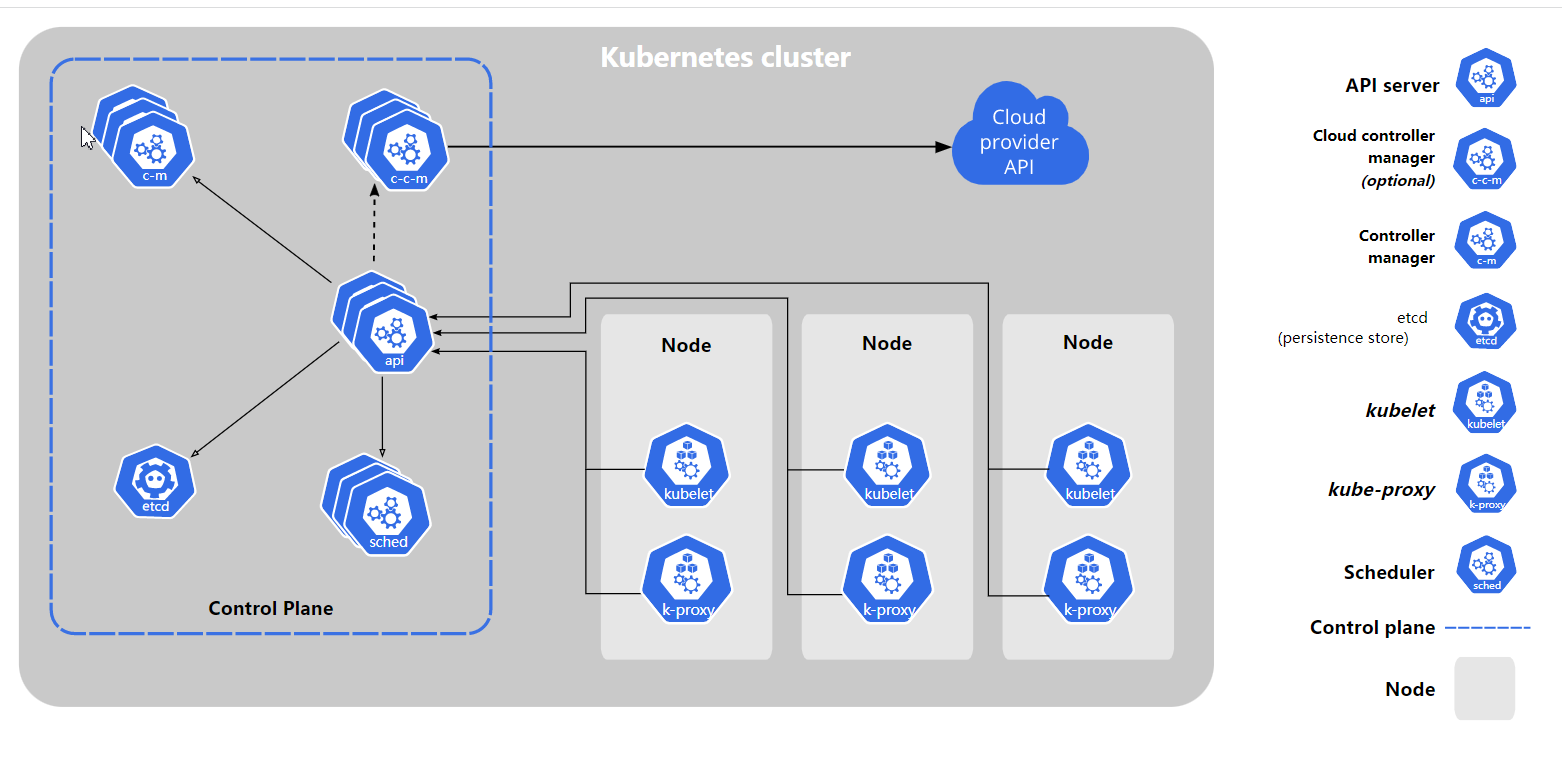
更详细的描述参考请查看官网:https://kubernetes.io/zh-cn/docs/concepts/overview/components/
K8S 是属于主从设备模型(Master-Slave 架构),即有 Master 节点负责核心的调度、管理和运维,Slave 节点则执行用户的程序。但是在 K8S 中,主节点一般被称为MasterNode 或者 Head Node,而从节点则被称为Worker Node 或者Node。按照官方最新的文档,主节点称为控制平面。
注意:Master Node 和 Worker Node 是分别安装了 K8S 的 Master 和 Woker 组件的实体服务器,每个 Node 都对应了一台实体服务器(虽然 Master Node 可以和其中一个Worker Node 安装在同一台服务器,但是建议 Master Node 单独部署),所有 MasterNode 和 Worker Node 组成了 K8S 集群,同一个集群可能存在多个 Master Node 和Worker Node。
Master Node都有哪些组件:
-
API Server : K8S 的请求入口服务。API Server 负责接收 K8S 所有请求(来自UI 界面或者 CLI 命令行工具),然后,API Server 根据用户的具体请求,去通知其他组件干活。
-
Scheduler : K8S 所有 Worker Node 的调度器。当用户要部署服务时,Scheduler 会选择最合适的 Worker Node(服务器)来部署。
-
Controller Manager : K8S 所有 Worker Node 的监控器。ControllerManager 有很多具体的 Controller, Node Controller、Service Controller、Volume Controller 等。Controller 负责监控和调整在 Worker Node 上部署的服务的状态,比如用户要求 A 服务部署 2 个副本,那么当其中一个服务挂了的时候,Controller 会马上调整,让 Scheduler 再选择一个 Worker Node 重新部署服务。
-
etcd : K8S 的存储服务。etcd 存储了 K8S 的关键配置和用户配置,K8S 中仅API Server 才具备读写权限,其他组件必须通过 API Server 的接口才能读写数据。
-
cloud-controller-manager :一个 Kubernetes 控制平面组件, 嵌入了特定于云平台的控制逻辑。 云控制器管理器(Cloud Controller Manager)允许你将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。
Worker Node的组件:
- Kubelet : Worker Node 的监视器,以及与 Master Node 的通讯器。Kubelet 是 Master Node 安插在 Worker Node 上的“眼线”,它会定期向Master Node 汇报自己 Node 上运行的服务的状态,并接受来自 Master Node 的指示采取调整措施。负责控制所有容器的启动停止,保证节点工作正常。
- Kube-Proxy : K8S 的网络代理。Kube-Proxy 负责 Node 在 K8S 的网络通讯、以及对外部网络流量的负载均衡。
- Container Runtime : Worker Node 的运行环境。即安装了容器化所需的软件环境确保容器化程序能够跑起来,比如Docker Engine运行环境。
k8s各个组件协作过程
在大概理解了上面几个组件的意思后,我们来看下上面用K8S部署Nginx的过程中,K8S内
部各组件是如何协同工作的:
我们在master节点执行一条命令要master部署一个nginx应用(kubectl createdeployment nginx --image=nginx)
1、这条命令首先发到master节点的网关api server,这是matser的唯一入口
2、api server讲命令请求交给controller mannager进行控制
3、controller mannager 进行应用部署解析
4、 controller mannager 会生成一次部署信息,并通过api server将信息存入etcd存储中
5、scheduler调度器通过api server从etcd存储中,拿到要部署的应用,开始调度看哪个节点有资源适合部署
scheduler把计算出来的调度信息通过api server再放到etcd中
6、每一个node节点的监控组件kubelet,随时和master保持联系(给api-server发送请求不断获取最新数据),拿到master节点存储在etcd中的部署信息,假设node2的kubelet拿到部署信息,显示他自己节点要部署某某应用,kubelet就自己run一个应用在当前机器上,并随时给master汇报当前应用的状态信息,node和master也是通过master的api-server组件联系的
7、每一个机器上的kube-proxy能知道集群的所有网络,只要node访问别人或者别
人访问node,node上的kube-proxy网络代理自动计算进行流量转发
K8S集群安装
安装前置条件
搭建K8S集群,
准备三台2核4G的虚拟机(内存至少2G以上),
操作系统选择用centos 7以上版本,因为容器要求系统的内核版本高于 3.10
先在三台机器上装好docker :
安装说明
了解了k8s的架构之后,我们就知道k8s分为master和node。我们需要分别在不同的机器上部署kubernets的不同节点。这里我们使用kubeadm集群初始化工具进行安装 。
kuibeadm工具安装k8s官方文档 :https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/
官方的安装文档提供Minikube 工具,可以在单台机器上部署k8s的所有节点: https://kubernetes.io/zh-cn/docs/tutorials/kubernetes-basics/create-cluster/cluster-intro/
官方提供相关的交互式教程用于我们熟悉kubernets相关操作(但是我一直没连接成功) : https://kubernetes.io/zh-cn/docs/tutorials/kubernetes-basics/
其他工具进行集群的安装:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/
端口放通说明
官方文档 :https://kubernetes.io/zh-cn/docs/reference/ports-and-protocols/
安装步骤
以下步骤,如果不特意说明,一般是在集群的所有节点执行。由于我这边是多个云厂商的服务器,所以部分步骤你们仅做参考即可
前置
由于我使用的是云服务器,这部分命令我这边没有执行,已经是关闭状态
参考:http://www.q578.com/s-5-2615546-0/
1.Swap会导致docker的运行不正常,性能下降,是个bug,但是后来关闭swap就解决了,就变成了通用方案,后续可能修复了(我没关注),基本上默认关闭了就OK,内存开大点儿不太会oom,本来容器也可以限制内存的使用量,控制一下就好。
2.Selinux是内核级别的一个安全模块,通过安全上下文的方式控制应用服务的权限,是应用和操作系统之间的一道ACL,但不是所有的程序都会去适配这个模块,不适配的话开着也不起作用,何况还有规则影响到正常的服务。比如权限等等相关的问题。
3防火墙看你说的是那种,如果你说的是iptables的话 ,那样应该是开着的,不应该关。k8s通过iptables做pod间流量的转发和端口映射,如果你说的防火墙是firewalld那就应该关闭,因为firewalld和iptables属于前后两代方案,互斥。当然,如果k8s没用iptables,比如用了其他的方式那就不需要用到自然可以关掉。
1、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2、关闭 selinux(linux权限增强相关)
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久关闭
setenforce 0 # 临时关闭
sestatus # 查看状态
3、#关闭 swap(swap会导致docker运行不正常,性能下降)
swapoff -a # 临时关闭
#永久关闭
sed -ri 's/.*swap.*/#&/' /etc/fstab
systemctl reboot #重启生效
free -m #查看下swap交换区是否都为0,如果都为0则swap关闭成功
前置2
4、给三台机器分别设置主机名(避免主机名重复,导致部分节点无法被识别到,也方便后期查看)
hostnamectl set-hostname <hostname>
第一台:k8s‐master
第二台:k8s‐node1
第三台:k8s‐node2
5、在 k8s‐master机器添加hosts,执行如下命令,ip需要修改成你自己机器的ip(追加数据到对应文件)(由于字符原因,粘贴后用ping命令测试配置是否生效)
cat >> /etc/hosts << EOF
43.143.136.203 k8s-master
61.171.5.6 k8s-node1
47.100.56.197 k8s-node2
EOF
6、将桥接的IPv4流量传递到iptables,添加的是系统规则,起名是k8s.conf, 参考 https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/network-plugins/#network-plugin-requirements
https://kubernetes.io/zh-cn/docs/setup/production-environment/container-runtimes/#%E8%BD%AC%E5%8F%91-ipv4-%E5%B9%B6%E8%AE%A9-iptables-%E7%9C%8B%E5%88%B0%E6%A1%A5%E6%8E%A5%E6%B5%81%E9%87%8F
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sysctl --system # 生效 或 sysctl -p /etc/sysctl.d/k8s.conf
#初始化集群还是报错的话执行,
sysctl -w net.ipv4.ip_forward=1
7、设置时间同步(本身是同步的,我这里不设置)
yum install -y ntpdate
ntpdate time.windows.com
前置3
官方页面前置准备工作:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
由于我这边是公网之间的服务器互相通讯,所以参考https://kubernetes.io/zh-cn/docs/reference/ports-and-protocols/ ,在云服务器提供的安全组-入口规则进行相关配置。
创建虚拟网卡
由于云主机网卡绑定的都是内网 IP, 而且几台云服务器位于不同的内网中, 直接搭建会将内网 IP 注册进集群导致搭建不成功。
# 所有主机都要创建虚拟网卡,并绑定对应的公网 ip
# 临时生效,重启会失效
ifconfig eth0:1 <你的公网IP>
# 永久生效
cat > /etc/sysconfig/network-scripts/ifcfg-eth0:1 <<EOF
BOOTPROTO=static
DEVICE=eth0:1
IPADDR=<你的公网IP>
PREFIX=32
TYPE=Ethernet
USERCTL=no
ONBOOT=yes
EOF
#生效配置
systemctl restart network
# 部分机器是NetworkManager,立即生效参考:https://blog.csdn.net/gxw1994/article/details/120536846
#查看配置是否生效
ifconfig
安装cri-dockerd
自 1.24 版起,Dockershim 已从 Kubernetes 项目中移除。阅读 Dockershim 移除的常见问题了解更多详情。需要对应的容器运行时,这里需要安装支持docker的容器运行时 cri-dockerd
参考 :
# 到https://github.com/Mirantis/cri-dockerd/releases 页面获取你系统支持的安装包,使用wget命令下载
wget https://github.com/Mirantis/cri-dockerd/releases/download/v0.2.6/cri-dockerd-0.2.6-3.el7.x86_64.rpm
sudo rpm -ivh cri-dockerd-0.2.3-3.el7.x86_64.rpm
sudo systemctl daemon-reload
sudo systemctl enable cri-docker.service
sudo systemctl enable --now cri-docker.socket
systemctl enable cri-docker --now
systemctl status cri-docker
#rpm包含的内容展示
[root@k8s-master cri-docker]# rpm -ql cri-dockerd |grep -v share
/usr/bin/cri-dockerd
/usr/lib/systemd/system/cri-docker.service
/usr/lib/systemd/system/cri-docker.socket
可以通过cri-dockerd --help查看支持的参数进行配置。
这里要说明的是–pod-infra-container-image的配置,由于在Kubernetes中是以Pod而不是以Docker容器为管理单元的,在kubelet创建Pod时,还通过启动一个名为k8s.gcr.io/pause:3.1的镜像来实现Pod的概念。
该镜像存在于谷歌镜像库k8s.gcr.io中,需要通过一台能够连上Internet的服务器将其下载,导出文件,再push到私有Docker Registry中。之后,可以给每个Node的kubelet服务都加上启动参数–pod-infra-container-image,指定为私有Docker Registry中pause镜像的地址。因为kubelet中已经弃用了该参数,直接从cri侧获取sandbox image;docker作为cri则需要在这里进行配置,否则会报错( failed pulling image “k8s.gcr.io/pause:3.6”: Error response from daemon: Get “https://k8s.gcr.io/v2/”: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers))。
–network-plugin=cni 如果不指定,pod会使用docker的网络。
[root@k8s-master cri-docker]# systemctl enable cri-docker.service #执行后展示如下
Created symlink from /etc/systemd/system/multi-user.target.wants/cri-docker.service to /usr/lib/systemd/system/cri-docker.service.
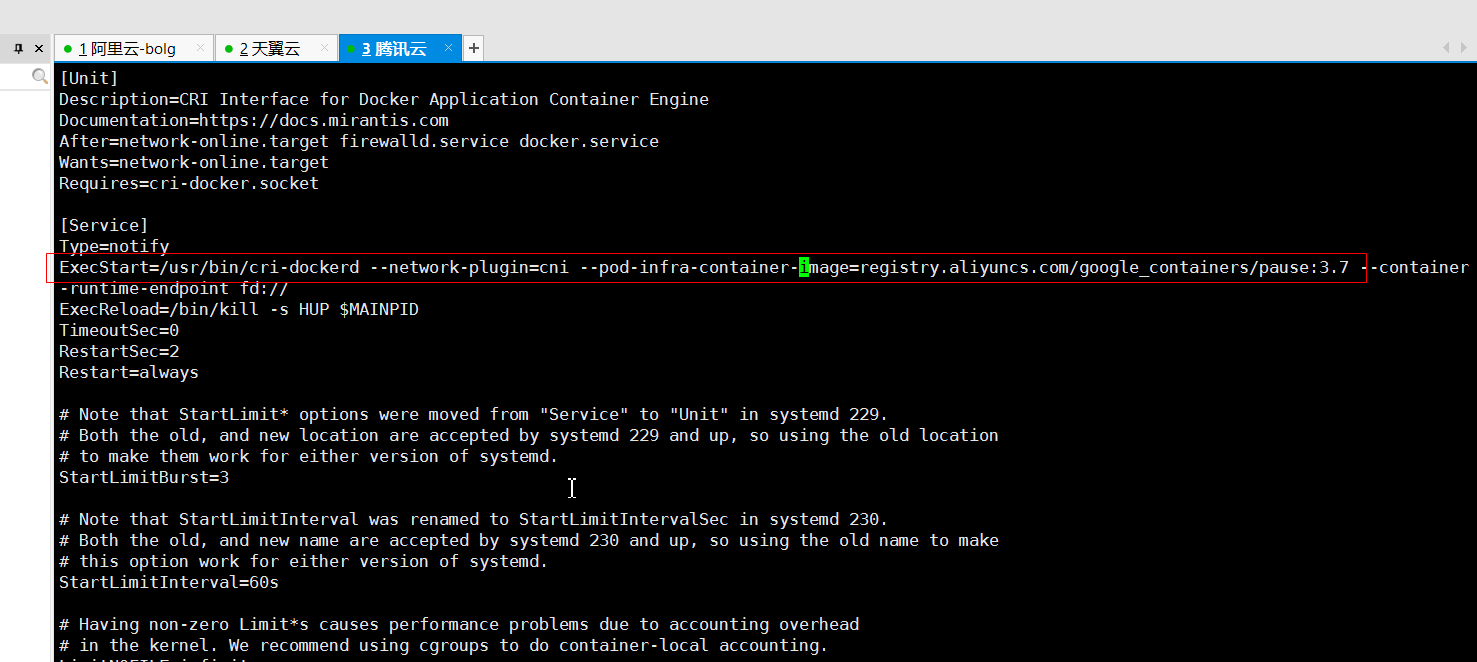
vim /usr/lib/systemd/system/cri-docker.service
添加--network-plugin=cni --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.7
systemctl daemon-reload
systemctl restart cri-docker
正式
安装kubelet kubeadm kubectl
8、添加k8s yum源,报错请查看报错处理 ,参考 https://developer.aliyun.com/mirror/kubernetes
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#由于有两个节点不是阿里云服务器,修改
/etc/yum.repos.d/kubernetes.repo
gpgcheck=0
repo_gpgcheck=0
yum makecache fast
9、 安装相关初始化工具
# 如果之前安装过k8s,先卸载旧版本
yum remove -y kubelet kubeadm kubectl
# 查看可以安装的版本
yum list kubelet --showduplicates | sort -r
yum search kubelet --showduplicates | grep 'kubelet'|sort -r
# 安装kubelet、kubeadm、kubectl 指定版本,我们使用kubeadm方式安装k8s集群,由于我docker安装的版本,这里我安装kubernets的版本选择1.25.2,版本关系查看https://github.com/kubernetes/kubernetes/releases
kubeadm:用来初始化集群的指令。
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
kubectl:用来与集群通信的命令行工具。
yum install -y kubelet-1.25.2 kubeadm-1.25.2 kubectl-1.25.2
systemctl enable kubelet.service
执行后输出 Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
# kubelet的启动命令占时无用,是在集群初始化或join的时候会被启动
systemctl enable kubelet
systemctl start kubelet
# 执行后暂时是dead状态,需要等集群初始化
systemctl status kubelet -l
journalctl -xefu kubelet
修改kubelet启动参数
# 此文件安装kubeadm后就存在了
vim /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
# 注意,这步很重要,如果不做,节点仍然会使用内网IP注册进集群
# 在末尾添加参数 --node-ip=公网IP
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS --node-ip=<公网IP>
systemctl daemon-reload
systemctl restart kubelet
初始化集群
master节点进行操作
更多初始化参数请参考:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
10、
# 查看可以安装的kubernetes版本
yum list --showduplicates kubeadm --disableexcludes=kubernetes
#打印出使用kubeadm初始化集群的默认配置
kubeadm config print init-defaults > kubeadm.yml
初始化的kubeadm.yml有如下需要修改的地方,建议去掉我加的注释:
配置文件参数说明:https://kubernetes.io/zh-cn/docs/reference/config-api/kubeadm-config.v1beta3/
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
#这里我改成我master的公网ip
advertiseAddress: 43.143.136.203
bindPort: 6443
nodeRegistration:
#修改默认的容器运行时
criSocket: unix:///var/run/cri-dockerd.sock
imagePullPolicy: IfNotPresent
#修改为主节点hostName
name: k8s-master
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
# 改成阿里云的镜像地址避免网络问题
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.25.2
networking:
dnsDomain: cluster.local
podSubnet: 150.233.0.0/16
#k8s的service内部网络访问地址,不要和我们宿主机的网段重叠
serviceSubnet: 150.244.0.0/16
scheduler: {}
执行初始化集群
sudo kubeadm init --config=kubeadm.yml
--cri-socket 值选项:
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/install-kubeadm/#installing-runtime calico-node-bpshh
执行失败后,找到原因后可以sudo kubeadm reset --cri-socket /var/run/cri-dockerd.sock(https://kubernetes.io/zh-cn/docs/reference/setup-tools/kubeadm/kubeadm-reset/)之后再执行初始化命令
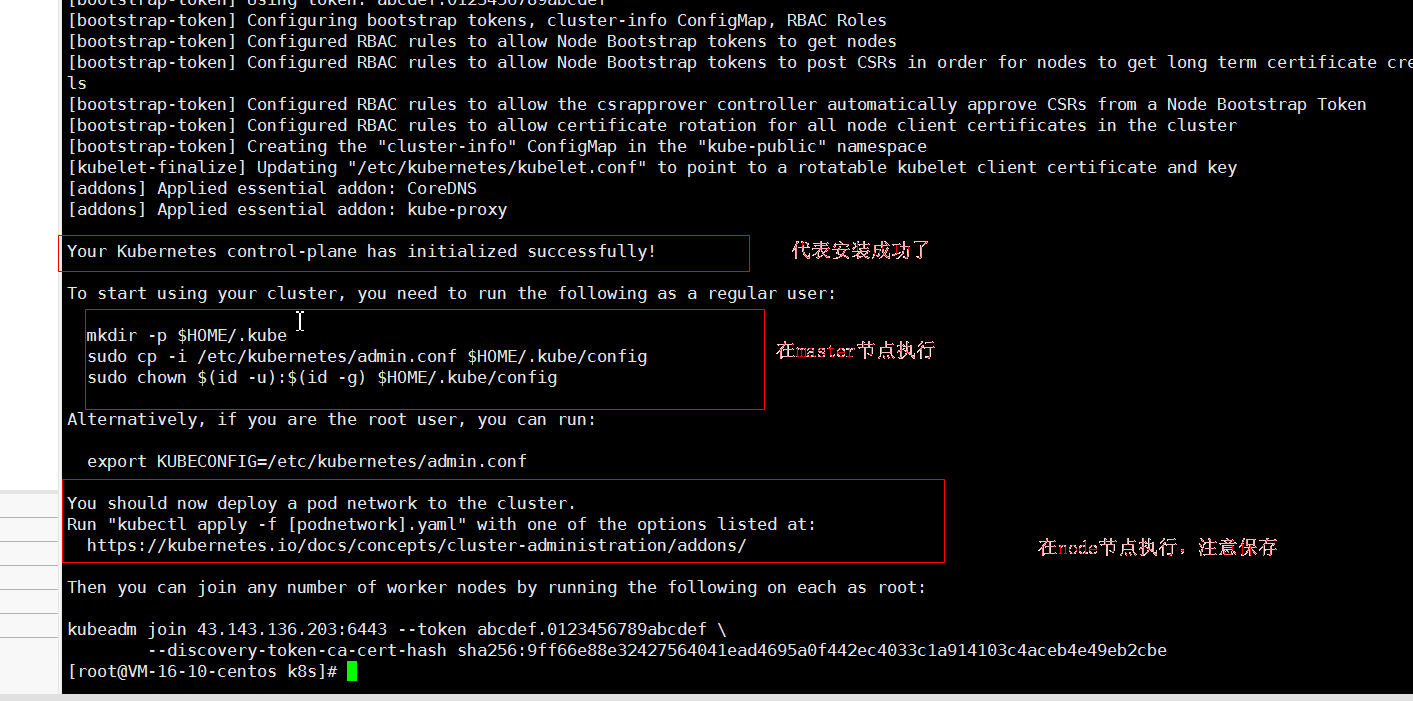
安装成功后后续操作
master节点配置和node节点添加
用于关联master和node节点,以便kubelet和kubectl都可以正常运行
# master节点执行
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 获取节点加入集群的命令
kubeadm token create --print-join-command
# node节点执行 (如果不记得了或者超过失效时长,从新获取 )
kubeadm join 43.143.136.203:6443 --token l96dr6.17czo4ee0m0jzf69 --discovery-token-ca-cert-hash sha256:3b2c96ca6b4d3745b976cef28f935324168507340689d5cac1f01cdb87ba7f6f --cri-socket unix:///var/run/cri-dockerd.sock
#执行失败的话,执行以下命令,再检查swap之类的配置是否关闭,再重新join
sudo kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
calico cni 安装
参考 :https://zhuanlan.zhihu.com/p/563177876
calico运维完全指南:https://zhuanlan.zhihu.com/p/524772977
#其中calico网络插件的安装参考地址(官方)
单主机集群版本:https://projectcalico.docs.tigera.io/getting-started/kubernetes/quickstart
其他方式:https://projectcalico.docs.tigera.io/getting-started/kubernetes/self-managed-onprem/onpremises
现象
kubectl get nodes 显示未就绪
journalctl -f -u kubelet 查看日志显示如下
Oct 08 21:09:34 k8s-master kubelet[1234]: E1008 21:09:34.850938 1234 kubelet.go:2373] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized"
使用tigera-operator.yaml和customer-resources.yaml的方式安装部署(未试验成功)
使用calico.yaml方式部署(使用中)
具体参考我粘贴的官方网址,这个主要截个图记录一下要修改的配置
#两种方式都可以指定网卡,这个的网卡不是虚拟网卡, 由于我这里没有网卡选择的问题,暂不处理,仅做记录
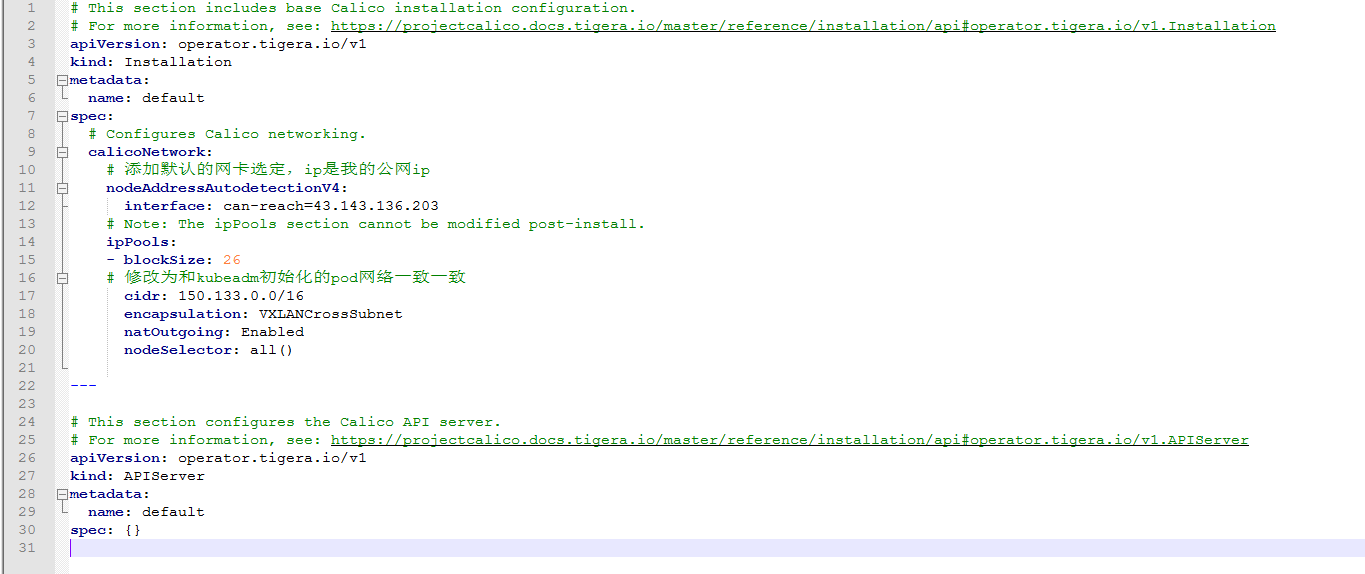
# 修改 custom-resources.yaml
nodeAddressAutodetectionV4:
interface: eth0
# 修改为和kubeadm初始化的pod网络一致
cidr: 150.133.0.0/16
# 另一种方式指定网卡,修改calico.yaml
添加
- name: IP_AUTODETECTION_METHOD
value: "interface=eth0" 或 value: "can-reach=25.10.10.0"
# 修改为和kubeadm初始化的pod网络一致
- name: CALICO_IPV4POOL_CIDR
value: "150.133.0.0/16"
# 客户端安装
#排查其网络问题可能需要用到其客户端
客户端安装 :https://projectcalico.docs.tigera.io/maintenance/clis/calicoctl/install#install-calicoctl-as-a-binary-on-a-single-host
# 安装后执行用于查看状态
calicoctl get nodes
calicoctl node status
# 赋予执行权限
chmod +x ./calicoctl
# 全局执行
ln /usr/local/app/k8s/calicoctl /usr/local/bin/
networkmanager 管理网络需要进行如下配置
使用calico进行网络管理时需要进行配置:
判断是否使用的是
参考:https://projectcalico.docs.tigera.io/maintenance/troubleshoot/troubleshooting#configure-networkmanager
# 验证是否是NetworkManager
systemctl status NetworkManager
sudo tee /etc/NetworkManager/conf.d/calico.conf <<-'EOF'
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:tunl*;interface-name:vxlan.calico;interface-name:vxlan-v6.calico;interface-name:wireguard.cali;interface-name:wg-v6.cali
EOF
# 重启
systemctl restart NetworkManager
成功后如下:

从节点执行kubectl命令
从节点执行kubectl get nodes 后显示
The connection to the server localhost:8080 was refused - did you specify the right host or port?
# 从主节点复制/etc/kubernetes/admin.conf 文件到从节点(master节点执行)
sudo scp /etc/kubernetes/admin.conf root@--.100.56.197:/etc/kubernetes/admin.conf
# 从节点执行
export KUBECONFIG=/etc/kubernetes/admin.conf
systemctl restart kubelet
kubectl get nodes # 查看是否显示正常
master节点设置为工作节点
master节点作为控制面,一般不参与容器的构建,我这里资源不够
# 先查询污点
kubectl get no -o yaml | grep taint -A 5
kubectl describe nodes | grep -E '(Roles|Taints)'
# 删除主服务器上的污点,以便您可以在其上部署POD
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
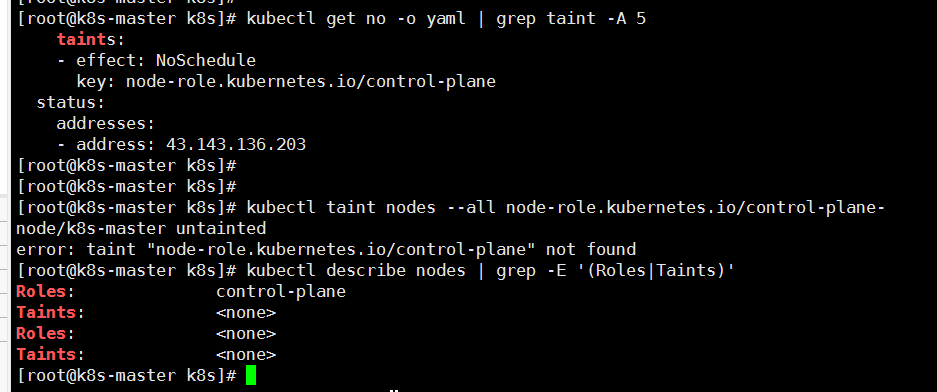
截图中的表示成功
#验证可以正常部署服务
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc -o wide
找到显示中随机生成的端口和其部署的ip,

如果状态全部显示正常,使用对应的公网ip : 端口访问对应服务进行验证
# 删除验证部署的服务和部署
kubectl delete deploy nginx
kubectl delete svc nginx
其他问题
calico-node 对应的pod启动不成功
# 查看kubelet日志 报错显示某个pod报错
[root@k8s-master ~]# systemctl status kubelet -l
# 查找到对应的pod ,READY这一栏显示 为0/1,标识未就绪
kubectl get pod -n kube-system -owide
# 先放通一下端口
calico需要放通的端口 :https://projectcalico.docs.tigera.io/getting-started/kubernetes/requirements
# 可能是网卡选择的问题,最好有对应的外网网卡,改网卡也没解决
- name: IP_AUTODETECTION_METHOD
value: "interface=ens.*"
# 修改使用的网络模式,修改为BGP模式 默认值Always标识IPIP模式,但是根据了解如果是处于不同的网络还是使用IPIP模式才行
- name: CALICO_IPV4POOL_IPIP
value: "Always"
- name: CALICO_IPV4POOL_IPIP
value: "Never"
# 部署了calico之后才有这个配置
# 编辑对应节点的配置(所有节点),修改后calico使用的ip变成了外网ip,最终显示如图,还是不行
kubectl edit node k8s-node2
kubectl annotate node <节点名称> projectcalico.org/IPv4Address=<公网地址>/22 --overwrite
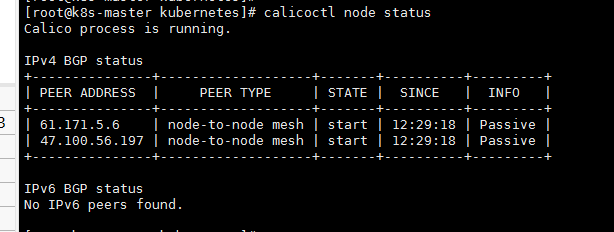
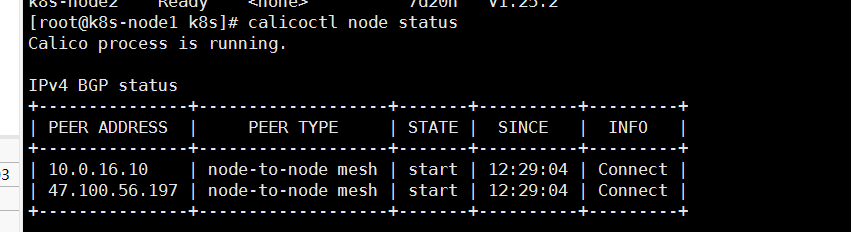
# 了解到passive 的状态calico的主节点去等待从节点进行连接,所以应该是两个从节点显示connect状态,而对应信息的交互应该是通过179端口,查看对应端口详情,发现使用的还是主节点的内网端口,坑定不通
netstat -nt | grep 179
# 所以配置访问主节点ip转发到对应的外网ip
# 参考:https://github.com/kanzihuang/kubespray-extranet/blob/main/docs/solutions.md
# https://zhuanlan.zhihu.com/p/493612033
NAT和SNAT区别 :https://wenku.baidu.com/view/02240f5e32b765ce0508763231126edb6f1a760d.html
# 在两个从节点上执行,配置了两个从节点访问主节点的内网ip转发到外网(此部分可不执行,如果节点显示的全是外网ip)
iptables -t nat -A OUTPUT -d <主节点内网ip>/32 -j DNAT --to-destination <主节点外网ip>

# 如上图,配置之后还是不行,不过这个至少请求发出去了
# 对应的从节点执行,不太理解,似乎是访问出去的数据报中的原地址会变成后面的地址(解释不清了。作用的话应该是让主节点认可对应的请求)
sudo iptables -t nat -I POSTROUTING -s <从节点外网ip>/32 -j SNAT --to-source <从节点内网ip>
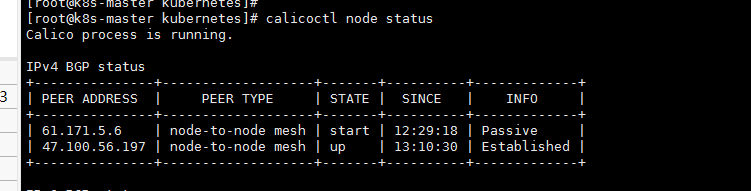
- 一个节点执行后,好了,如上图,继续在另一个节点执行,执行后在主节点显示如图
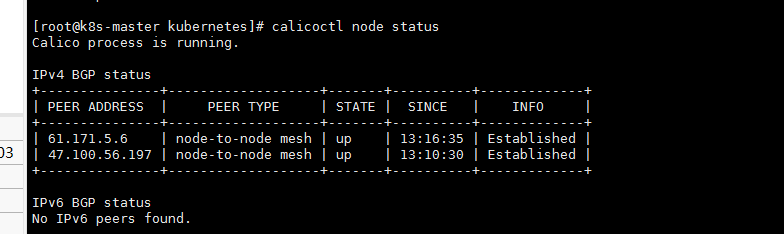
- 但是从节点上执行对应命令显示还是有点问题,但是不管了,之后我对应的pod已经显示正常了
- 到了这一部我发现我没有编辑kubectl edit node k8s-master,更改ip,然后从节点未就绪的问题估计要重新部署
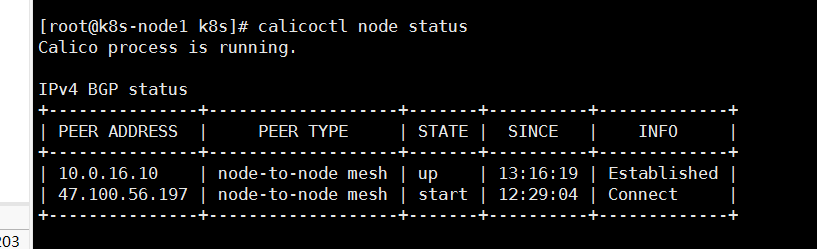
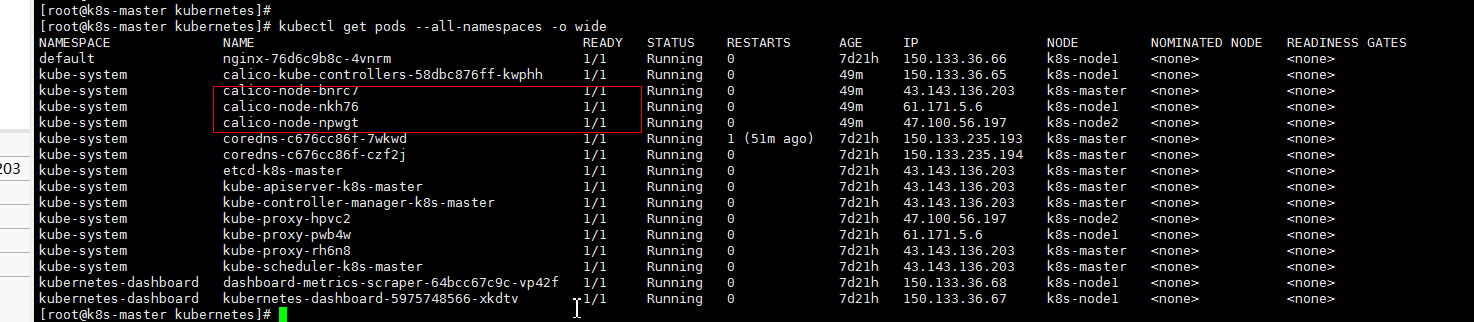
# 这个如果是外网的话,最好有对应的外网网卡,calico这个我也是弄不明白了,反正是正常了,不过也不一定需要calico准备就绪,比如我的部署的nginx镜像在未就绪的状态下也是也访问的
#查看日志 和相关处理命令记录:
kubectl get pods --all-namespaces -o wide
kubectl describe pod -n kube-system calico-node-xtmlj
kubectl logs -f -n kube-system calico-node-xtmlj -c calico-node
kubectl delete pod calico-node-jm5fp -n kube-system
kubectl apply -f calico.yaml
kubectl delete -f calico.yaml
kubectl delete pod calico-node-jm5fp -n kube-system
kubectl delete pod xxx -n xxx --force --grace-period=0 # pod状态变为terminating,无法删除pod,强行删除
# 规则保存
iptables-save > /etc/sysconfig/iptables
# 规则重载
iptables-restore < /etc/sysconfig/iptables
# calicoctl使用的模式
calicoctl get ippool -o wide
k8s节点移除
安装老是有问题,这里记录一下移除节点的办法,比如注册的是内网地址,比如注册的节点名称有问题
参考:https://www.cnblogs.com/siguadd/p/16283607.html
1.获取节点列表:kubectl get node -o wide

2、设置不可调度,不分配新的资源到该节点。
下线命令:kubectl cordon <节点名称>
检查节点状态,kubectl get nodes
被标记为不可调度节点,节点状态变成:Ready,SchedulingDisabled
3、驱逐节点上的pod
kubectl drain <节点名称> --delete-local-data --force --ignore-daemonsets
说明:drain意为排出,此时卸载节点,但是没有删除;daemonset不会被排出节点,其它的pod自动转移到其它节点,比如从node2跑到node1
4、节点上的pod均被驱逐后,直接移除节点
kubectl delete node k8s-node
5、在被删除的node节点中清空集群数据信息
kubeadm reset -f --cri-socket /var/run/cri-dockerd.sock
6、如果是使用的iptables,清楚相关规则
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
安装nginx测试集群正常
# 湖区先有的所有容器
kubectl get pods --all-namespaces
# 创建相关资源
kubectl create deployment nginx --image=nginx
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pod,svc,deploy -o wide
61.171.5.6:31329 (根据内容测试是否可以访问)
# 删除测试的内容
kubectl delete svc nginx
kubectl delete deploy nginx
# 强制删除
--force --grace-period=0
k8s集群卸载
https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/#tear-down
Dashboard安装
Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。 你可以使用 Dashboard 获取运行在集群中的应用的概览信息,也可以创建或者修改 Kubernetes 资源 (如 Deployment,Job,DaemonSet 等等)。 例如,你可以对 Deployment 实现弹性伸缩、发起滚动升级、重启 Pod 或者使用向导创建新的应用。Dashboard 同时展示了 Kubernetes 集群中的资源状态信息和所有报错信息。
官方文档位置 :https://kubernetes.io/zh-cn/docs/tasks/access-application-cluster/web-ui-dashboard/
其他:https://developer.aliyun.com/article/745086
版本对应关系获取:https://github.com/kubernetes/dashboard/releases/tag/v2.7.0
表示安装的版本太新也不友好
# 1、获取编排文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
# 2、修改文件
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
# 修改
type: NodePort
ports:
- port: 443
targetPort: 8443
# 修改
nodePort: 30001
#3、应用
kubectl apply -f recommended.yaml
# 4、运行状况
kubectl get pod,svc,deploy -o wide -n kubernetes-dashboard
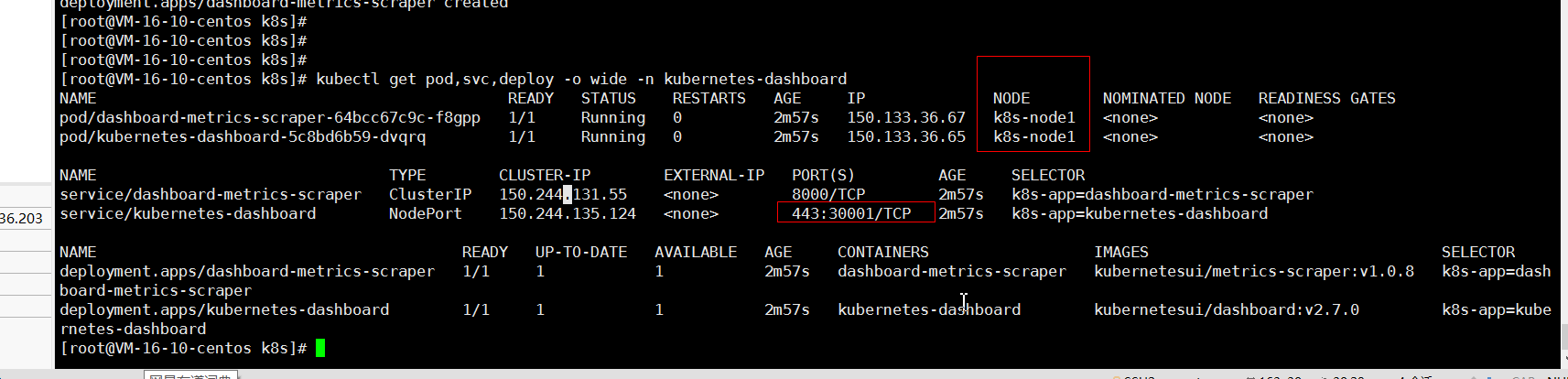
# 5、创建账户并且分配权限
# 在kubernetes-dashboard命名空间中创建服务帐户admin-user
kubectl create serviceaccount admin-user -n kubernetes-dashboard
# 为kubernetes-dashboard命名空间中的服务帐户admin-user授予cluster-admin角色权限
kubectl create clusterrolebinding admin-user-rb --clusterrole=admin-user --serviceaccount=kubernetes-dashboard:dashboard-admin
# 删除账户(不要执行)
kubectl delete serviceaccount dashboard-admin -n kubernetes-dashboard
# 也可以通过编排文件的方式创建用户和分配权限,内容如下,使用kubectl create -f 执行生效即可
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
# 6、获取登录的token,有一定时效,超过失效后再执行此命令
kubectl -n kubernetes-dashboard create token admin-user
# 指定过期的时间 10天
kubectl create token admin-user --duration 14400m -n kubernetes-dashboard
# 希望生成的token永久有效
编排文件修改如下位置,再重新应用
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
# 增加的失效时间配置(设置为0表示永久有效,我设置了,但是没用,单位秒,似乎是登录的失效时间,和用户无任何酸洗)
- --token-ttl=21600
Kubernetes Dashboard使用用户名密码形式登录
没有成功,仅做记录
官方:https://github.com/kubernetes/dashboard/blob/v2.7.0/docs/user/access-control/README.md#basic
参考:http://t.zoukankan.com/wenyang321-p-14149099.html
1、新增密码文件
在装过dashboard环境下。
我们去master节点新增一个文件,如果是ha会有多个master,那么每个master同下操作。
里面内容结构是:用户名,密码(用户名和密码要保持一致),唯一ID。
echo 'admin,admin,1' | sudo tee /etc/kubernetes/pki/basic_auth_file.csv
2、修改配置kube-apiserver.yaml文件,只粘贴一部分,以便确认位置
# 如果报错,可能没有问题是添加的这一条出现了问题,原因是- --basic-auth-file已经在1.19版本被弃用,改为了- --token-auth-file,如果没改,后续kubectl直接就执行失败了
sudo vim /etc/kubernetes/manifests/kube-apiserver.yaml
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=43.143.136.203
- --allow-privileged=true
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --enable-admission-plugins=NodeRestriction
- --enable-bootstrap-token-auth=true
- --etcd-cafile=/etc/kubernetes/pki/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/pki/apiserver-etcd-client.crt
- --etcd-keyfile=/etc/kubernetes/pki/apiserver-etcd-client.key
- --etcd-servers=https://127.0.0.1:2379
- --kubelet-client-certificate=/etc/kubernetes/pki/apiserver-kubelet-client.crt
- --kubelet-client-key=/etc/kubernetes/pki/apiserver-kubelet-client.key
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --proxy-client-cert-file=/etc/kubernetes/pki/front-proxy-client.crt
- --proxy-client-key-file=/etc/kubernetes/pki/front-proxy-client.key
- --requestheader-allowed-names=front-proxy-client
- --requestheader-client-ca-file=/etc/kubernetes/pki/front-proxy-ca.crt
- --requestheader-extra-headers-prefix=X-Remote-Extra-
- --requestheader-group-headers=X-Remote-Group
- --requestheader-username-headers=X-Remote-User
- --secure-port=6443
- --service-account-issuer=https://kubernetes.default.svc.cluster.local
- --service-account-key-file=/etc/kubernetes/pki/sa.pub
- --service-account-signing-key-file=/etc/kubernetes/pki/sa.key
- --service-cluster-ip-range=150.244.0.0/16
- --tls-cert-file=/etc/kubernetes/pki/apiserver.crt
- --tls-private-key-file=/etc/kubernetes/pki/apiserver.key
- --token-auth-file=/etc/kubernetes/pki/basic_auth_file.csv # 这是新增行
3、确定api-server启动成功
kubectl get pods --all-namespaces
4、最后修改 recommended.yaml 配置文件,然后重新应用
ports:
- containerPort: 8443
protocol: TCP
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
# 增加的失效时间配置(设置为0表示永久有效,我设置了,但是没用,单位秒,我对这个配置不太理解了)
- --token-ttl=21600
# 新增行,添加用户名密码访问方式
- --authentication-mode=basic,token
5、为admin用户绑定权限
第四步中文件包含了kubernetes-dashboard用户创建和授权的内容,如果直接使用,给kubernetes-dashboard的集群角色绑定部分添加如下部分即可
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
如果要使用新建的用户访问,参考如下
# 权限绑定
kubectl create clusterrolebinding login-on-dashboard-with-cluster-admin --clusterrole=cluster-admin --user=admin
kubectl delete clusterrolebindings login-on-dashboard-with-cluster-admin
#查看绑定结果
kubectl get clusterrolebinding login-on-dashboard-with-cluster-admin
# 5、创建账户并且分配权限
# 在kubernetes-dashboard命名空间中创建服务帐户admin-user
kubectl create serviceaccount admin -n kubernetes-dashboard
# 为kubernetes-dashboard命名空间中的服务帐户admin-user授予cluster-admin角色权限
kubectl create clusterrolebinding admin-user-rb --clusterrole=admin --serviceaccount=kubernetes-dashboard:admin
6、确定对应的服务启动成功
kubectl get pod -n kubernetes-dashboard
7、登录后访问不到任何资源,且输入任何字符都可以登录
报错为serviceaccounts is forbidden: User “system:anonymous” cannot list resource "
尝试执行如下操作
# 授权匿名用户访问权限
kubectl create clusterrolebinding test:anonymous --clusterrole=cluster-admin --user=system:anonymous
# 执行后退出再次尝试登录,无法登陆,操作回退
kubectl delete clusterrolebindings test:anonymous
8、
参考:https://kubernetes.io/zh-cn/docs/reference/access-authn-authz/abac/
https://stackoverflow.com/questions/64889664/how-to-login-dashboard-with-username-password-in-v1-19-2/64892582#64892582
https://techexpert.tips/zh-hans/kubernetes-zh-hans/%e5%ba%93%e4%bc%af%e5%86%85%e7%89%b9%e4%bb%aa%e8%a1%a8%e6%9d%bf-%e5%90%af%e7%94%a8%e7%94%a8%e6%88%b7%e8%ba%ab%e4%bb%bd%e9%aa%8c%e8%af%81/
参考对应文档尝试添加
vim /etc/kubernetes/manifests/kube-apiserver.yaml
- --authorization-mode=Node,RBAC,ABAC # 这里新增ABAC授权模式
- --authorization-policy-file=/etc/kubernetes/pki/proxy_file.jsonl # ABAC授权模式需要添加的配置
proxy_file.jsonl文件内容如下
{"apiVersion":"abac.authorization.kubernetes.io/v1beta1","kind":"Policy","spec":{"user":"system:serviceaccount:kubernetes-dashboard:admin","namespace":"*","resource":"*","apiGroup":"*"}}
# 还是不行
9、
尝试弄一个secret文件和用户绑定(随便尝试,secret具体的作用是存储机密数据,实现机密数据和应用解耦)
apiVersion: v1
kind: Secret
metadata:
labels:
k8s-app: kubernetes-dashboard
name: admin-secret
namespace: kubernetes-dashboard
type: Opaque
data:
username: YWRtaW4=
password: MTIzNDU2
# 生效文件
kubectl apply -f secret.yaml
#查看
kubectl get secrets -n kubernetes-dashboard
# 详情
kubectl describe secrets/admin-secret -n kubernetes-dashboard
# 根据kubectl create token命令的帮助,绑定对应的secret()
kubectl create token admin --bound-object-kind Secret --bound-object-name admin-secret -n kubernetes-dashboard
kubectl -n kubernetes-dashboard describe sa admin
无语,到这里我放弃了,,回退
不显示内存使用情况
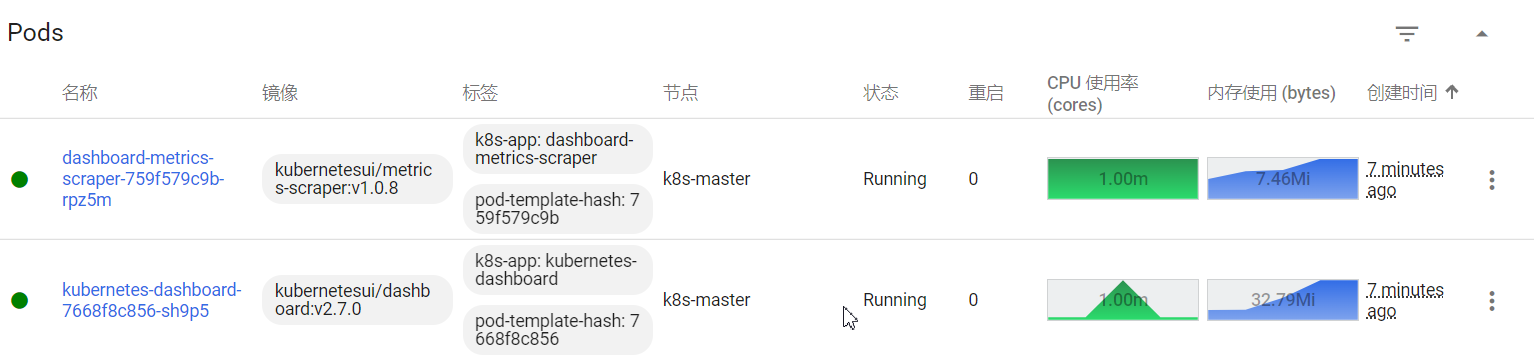
[root@k8s-master k8s]# kubectl top pods
error: Metrics API not available
官网:https://github.com/kubernetes-sigs/metrics-server
1、# 建议下载后编辑再应用
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
2、#出现报错
Pulling image "k8s.gcr.io/metrics-server/metrics-server:v0.6.1"
#修改编排文件
spec:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls=true # 对应下一步的报错
image: bitnami/metrics-server:0.6.1-debian-11-r51 # 这里替换成hub仓库可用镜像
3、# 然后又报错
Readiness probe failed: HTTP probe failed with statuscode: 500
参考:https://blog.csdn.net/liuyanwuyu/article/details/119793631
#应该是需要配置证书,这里直接忽略
在编排文件里添加忽略配置,重新应用
4、 正常启动metrics后报错
[root@k8s-master k8s]# kubectl top nodes
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
# 查看api-server 日志
kubectl logs -f -n kube-system kube-apiserver-k8s-master

最终150.244.127.4 是woker-node上metrics的svc对应的ip,应该是calico网络有问题吧,
参考:https://stackoverflow.com/questions/53811388/error-from-server-serviceunavailable-the-server-is-currently-unable-to-handle
继续修改配置,以下配置的含义是将metrics-server部署在主节点上,而不是之前随机的从节点
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
nodeName: k8s-master # 新增
hostNetwork: true # 新增
5、验证
# 验证
kubectl top nodes

6、ui显示
#发现dashboard界面还是不显示cpu和内存,参照第4步,将dashboard也转移到主节点,然后就好了
nodeName: k8s-master
http访问
# servie部分
ports:
#service 增加http配置
- appProtocol: http
name: http
port: 9090
protocol: TCP
targetPort: 9090
nodePort: 31101
- appProtocol: https
name: https
port: 445
protocol: TCP
targetPort: 8443
nodePort: 30001
# deployment部分
ports:
- containerPort: 8443
protocol: TCP
name: https
- containerPort: 9090
protocol: TCP
name: http
args:
- --auto-generate-certificates
- --namespace=kubernetes-dashboard
- --authentication-mode=token
#增加以下三行配置,使支持http
- --enable-insecure-login
- --insecure-port=9090
livenessProbe:
httpGet:
scheme: HTTPS
path: /
port: 8443
# 增加httpcheck
httpGet:
scheme: HTTP
path: /
port: 9090
一通瞎改之后不是访问不了https就是http可以访问,但是不能登录,恶心,算了
官方:https://github.com/kubernetes/dashboard/blob/master/docs/user/accessing-dashboard/README.md#login-not-available
吐槽
安装比较麻烦,建议选择1.24之前的版本,因为不用考虑容器运行时的问题,特别是docker底层依赖containerd,导致有两个容器运行时,然后就是一堆问题,无语了,切换到containerd似乎不麻烦,只要将docker命令替换成crictl 即可,https://kubernetes.io/zh-cn/blog/2020/12/02/dockershim-faq/ ,还有容器运行时的版本也不知道怎么选
还有就是如果三台机器是在一台局域网的话,可能会比较好处理一点,至少calio-node的网络问题号处理一点
还有好多概念也不太清晰。官网也看不明白,都啥呀。先这样吧
calico节点似乎还是有问题,莫名其妙,下次可以试试内网ip注册,再配置iptables规则
关联信息
-
关联的主题:docker : https://www.liuchengtu.com/swdt/loading.htm#cd96bdebac5a1d23ffc617839bc2acfd
-
上一篇:
-
下一篇:
-
image: 20221006/1

















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









