






最近发现很多面试都会问及关于HashMap的底层源码,所以简单的了解了一下,现在写一篇总结用以备忘。
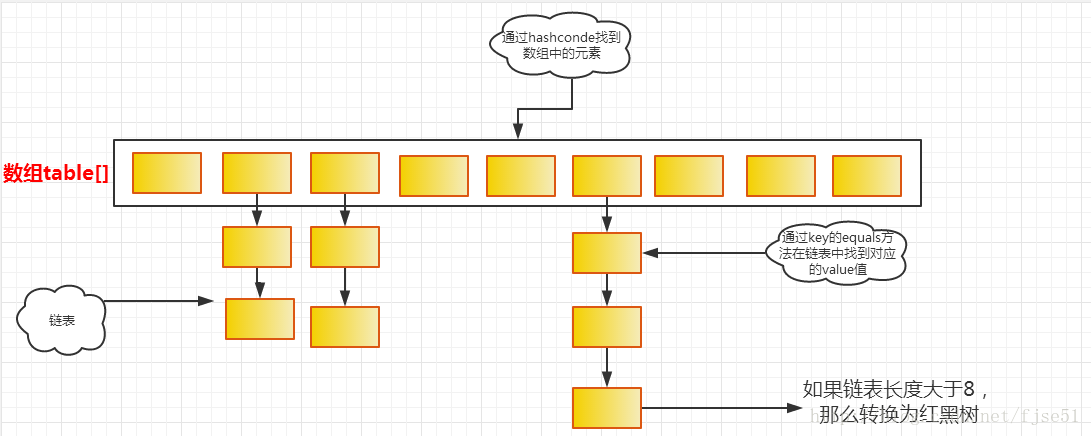
- HashMap的数据结构为“数组+链表形式”,并且链表为单向链表,如下图(图片来源于网络):
- 数组的默认大小为
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4,即将二进制数字1向左位移四位,得到二进制数字10000,换算成10进制就是16,之所以在源码中采用位移运算,是因为效率高。 - 数组的最大长度为
static final int MAXIMUM_CAPACITY = 1 << 30 - 关于数组扩容的时机,源码中给出了一个因子,
static final float DEFAULT_LOAD_FACTOR = 0.75f,这个因子的大小是工程师们通过计算得出的一个最佳的值(可以理解成和黄金比例差不多的东西),当数组的被占用的长度达到“当前长度*因子”时,数组就会进行扩容,并且扩容后的长度为当前长度的二倍。 - 为了方便以后说明,现在这里提一下hash()方法:
static final int hash(Object key) {,当key不为null的时候hash()会通过key调用hashCode()方法,得到的值是一个32位的二进制数据并赋予h,然后将h的高16位和低16位进行异或运算得出hash值,也就是数据将在数组中插入的位置,此方法主要是用来获取0-15之间的数 (因为数组默认长度是16)
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
} - 当向HashMap中进行put操作时,(如果是第一次,则会进行数组的初始化)首先判断要加入的hash是否存在,若不存在填入数据节点,若存在,则继续判断;当put的key和其hash值与数组里的某个节点数据均相同,则将其覆盖,若hash相同而key不同,则在此hash节点后新增节点(这就是链表的产生),在每次put操作过后都会进行一个数组占用size的判断,若占用量达到条件,则对数组进行扩容
if (++size > threshold)
resize(); - 关于数组的扩容机制 resize()方法:当数组长度已经大于最大长度,那么就不管他了;如果当前数组长度大于默认初始长度并且当前长度的二倍小于最大长度,那么就将数组扩大为二倍
if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
} - 当put将链表的长度大于8时,链表会转为红黑树结构;当remove将红黑树长度小于6时,红黑树会转为链表结构(此举可以提高代码效率)
- 数组的大小一直是2的n次方,目的是用来保证数据存入数组位置的分散性,扩容是双倍扩容也是为了保证数组的大小一直为2的n次方
- 当数组扩容后,链表的位置要么是在原来的位置,要么是在原来的位置+16后的位置















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









