







Spring源码(六)loadBeanDefinitions方法
前言
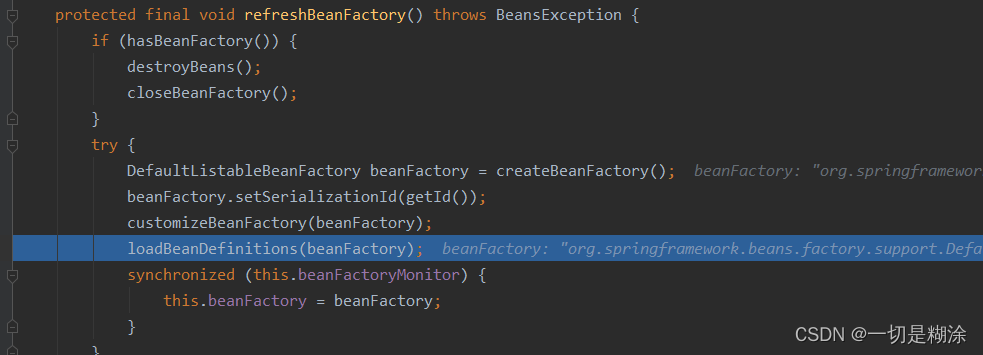
上文介绍了除了loadBeanDefinitions方法的其他方法,再来复习一下。
首先会判断是否创建了一个工厂,如果没有,那么默认创建一个DefaultListableBeanFactory工厂,里面主要设置了允许循环依赖、可以覆盖以及忽视一些aware接口。然后给创建好的beanFactory设置专属的ID。然后就是可以定制化自己的BeanFactory了,可以改变两个参数,一个循环依赖,一个beanDefinitions的覆盖,这里可以作为一个扩展点。最后是将xml文件解析成document,解析document的每个元素并设置到beanDefinition,并加入到BeanFactory中。本文主要记录下loadBeanDefinitions的具体实现过程。
loadBeanDefinitions方法前准备操作
首先看下里面有什么
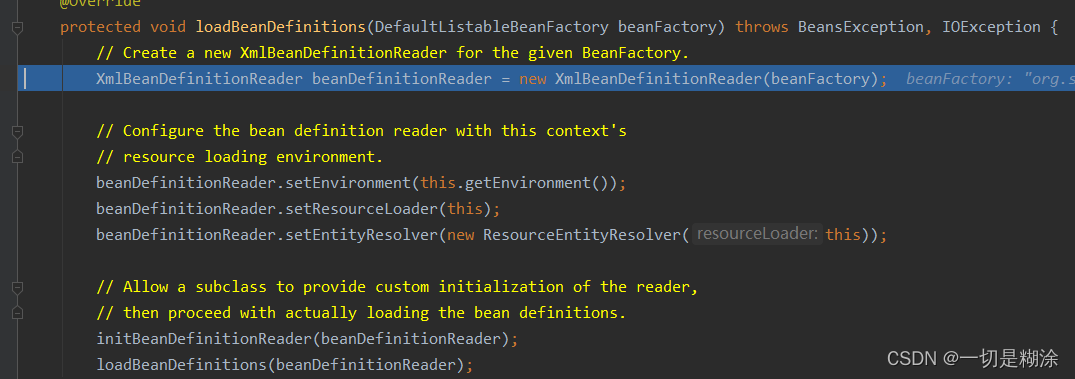
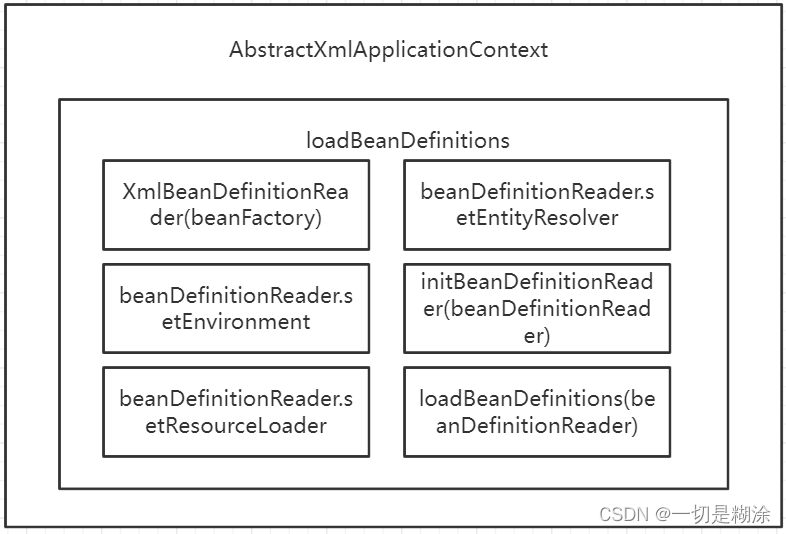
可以看到一共六个方法,第一个new XmlBeanDefinitionReader(beanFactory);这个方法就是我们常常说的BeanDefinitionReader方法,将xml文件读到beanDefinitionReader里,方便后续的处理。
第二个方法是beanDefinitionReader.setEnvironment(this.getEnvironment());,这就是简单的设置下beanDefinitionReader的环境,方便对某些东西进行替换工作。
第三个方法beanDefinitionReader.setResourceLoader(this);设置下资源加载器,这里把自己设置进去了,也就是xmlapplicationContext。
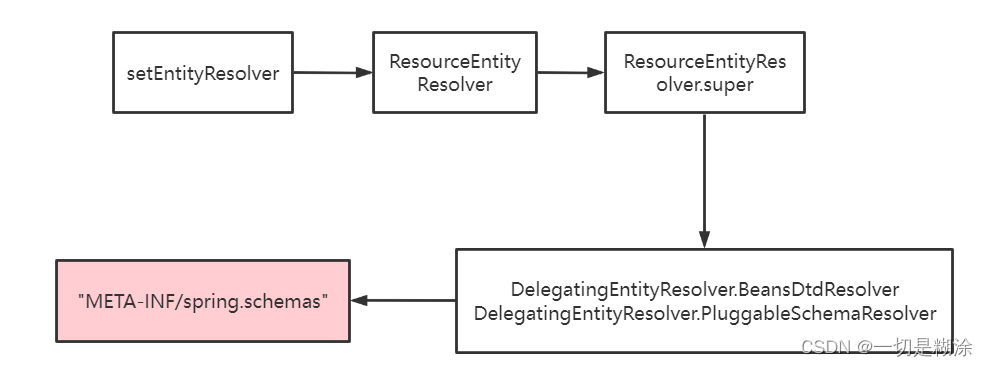
第四个方法beanDefinitionReader.setEntityResolver(new ResourceEntityResolver(this));这个方法也就是我们访问xml文件时,都有它的格式规定,一般为xsd或者dtd,我们都会在xml文件上面定义一些网址,意思是xsd文件从这个网址上找,比如下面:

但是一般情况下,网址是不可访问的,这个时候,需要读取本地的dtd、xsd了,这个方法就是这个用途。
进入下(new ResourceEntityResolver(this))方法里面,发现

这里默认创建了dtd的处理器与xsd处理器,现在我们一般都是xsd,进入到第二个方法里看下,

这里就知道了,默认实在META-INF/spring.schemas里面找xsd对应的格式了。
我们找一下这个文件:
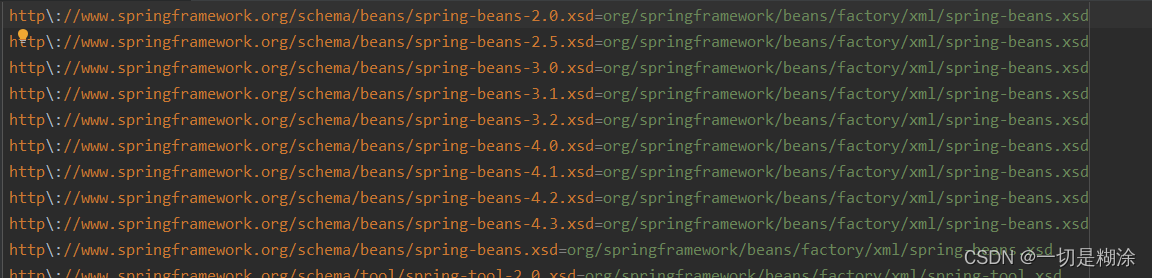
这里会发现有一堆的网络地址到本地的映射。
所以这个方法主要也是做了一些准备工作,将xsd或者dtd的本地文件准备一下。大致画了一下流程图形式,这里主要是xsd格式的流程图,如下图所示。
第5个方法initBeanDefinitionReader(beanDefinitionReader); 这个方法比较简单了,点进去看下

这里的validating就是我们在super时,默认设置了这个值为true,也就是这个方法呢设置了xml文件需要进行验证操作。
第6个方法loadBeanDefinitions方法,这个方法才是整个方法的核心,下面单独开一个小节记录下过程。
loadBeanDefinitions方法
这个方法重载特别多,我们先一步步看,首先将beanDefinitionReader当作参数传进去,看到如下代码:
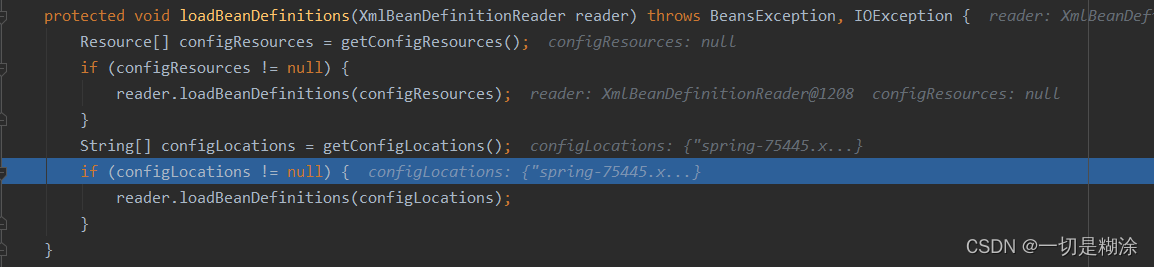
这里我们会获取getConfigLoations,这个东西实际上是在refresh方法前一个方法,setConfigLocations设置进去了,当时我们设置的其实是String[]数组形式,所以这里会走第二个判断条件。此时会将String[]数组传入到loadBeanDefinitions里,看下这个代码:
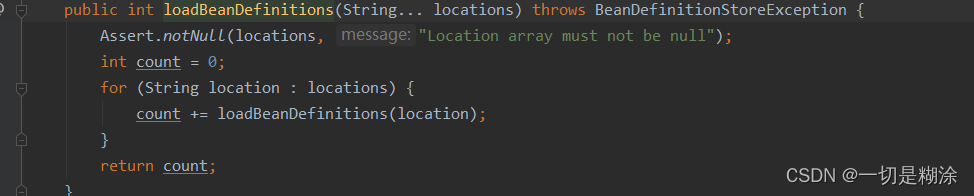
这里较为简单了,单纯的将String数组里面的元素取出来,再利用loadBeandefinitions重载方法,将String类型放进去。进入到此方法中:
public int loadBeanDefinitions(String location, @Nullable Set<Resource> actualResources) throws BeanDefinitionStoreException {
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader == null) {
throw new BeanDefinitionStoreException(
"Cannot load bean definitions from location [" + location + "]: no ResourceLoader available");
}
if (resourceLoader instanceof ResourcePatternResolver) {
// Resource pattern matching available.
try {
Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);
int count = loadBeanDefinitions(resources);
if (actualResources != null) {
Collections.addAll(actualResources, resources);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location pattern [" + location + "]");
}
return count;
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"Could not resolve bean definition resource pattern [" + location + "]", ex);
}
}
else {
// Can only load single resources by absolute URL.
Resource resource = resourceLoader.getResource(location);
int count = loadBeanDefinitions(resource);
if (actualResources != null) {
actualResources.add(resource);
}
if (logger.isTraceEnabled()) {
logger.trace("Loaded " + count + " bean definitions from location [" + location + "]");
}
return count;
}
}
这个方法我们看下,因为classPathxmlapplicationContext是属于ResourceLoader的,所以会进入if()判断里面来,所以Resource[] resources = ((ResourcePatternResolver) resourceLoader).getResources(location);这个方法比较有意思,看下执行流程:

这里的resourcePatternResolver我们在super时,已经设置过了,是ant风格表达式,所以跳过,后面的getResources方法呢,在里面对locations匹配,比如是否以classpath:开头,最终返回一个Resource[]数组。
继续往下看,又会进入到loadBeanDefinitions重载里面,将Resource数组传进去,下面我们不用看就知道还是循环,取出resource对象。进入到重载方法里面。
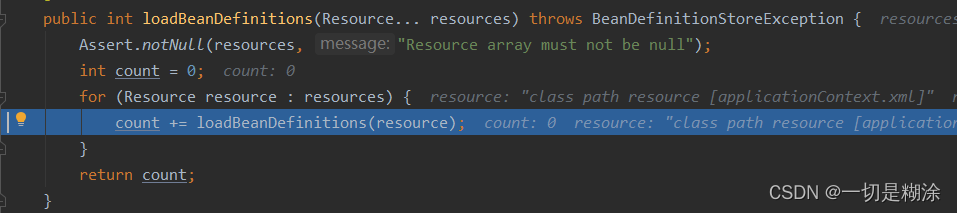
继续进入到重载方法,参数为resource里面:
public int loadBeanDefinitions(EncodedResource encodedResource) throws BeanDefinitionStoreException {
Assert.notNull(encodedResource, "EncodedResource must not be null");
if (logger.isTraceEnabled()) {
logger.trace("Loading XML bean definitions from " + encodedResource);
}
Set<EncodedResource> currentResources = this.resourcesCurrentlyBeingLoaded.get();
if (currentResources == null) {
currentResources = new HashSet<>(4);
this.resourcesCurrentlyBeingLoaded.set(currentResources);
}
if (!currentResources.add(encodedResource)) {
throw new BeanDefinitionStoreException(
"Detected cyclic loading of " + encodedResource + " - check your import definitions!");
}
try (InputStream inputStream = encodedResource.getResource().getInputStream()) {
InputSource inputSource = new InputSource(inputStream);
if (encodedResource.getEncoding() != null) {
inputSource.setEncoding(encodedResource.getEncoding());
}
return doLoadBeanDefinitions(inputSource, encodedResource.getResource());
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(
"IOException parsing XML document from " + encodedResource.getResource(), ex);
}
finally {
currentResources.remove(encodedResource);
if (currentResources.isEmpty()) {
this.resourcesCurrentlyBeingLoaded.remove();
}
}
}
这里进入到了一个loadBeanDefinitions,参数为encode的重载方法中。
首先是this.resourcesCurrentlyBeingLoaded.get();方法,这个是threadLocal类型的,获取已经加载的资源,这里没有,则为空,当前线程没有做过任何处理工作。
然后是inputStream,从encodedResource中获取已经封装的Resource对象并再次从Resource中获取其中的inputStream。读取了配置文件。
然后到达了核心步骤,doLoadBeanDefinitions。
下面看下这个核心方法doLoadBeanDefinitions。
protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
Document doc = doLoadDocument(inputSource, resource);
int count = registerBeanDefinitions(doc, resource);
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + count + " bean definitions from " + resource);
}
return count;
}
doLoadDocument(inputSource, resource);这个方法是做什么的?因为上一步inputStream读进来的都是字符串,不能进行识别,所以我们需要对这些字符串转成可以识别的对象,所以这里读成了document,看下这个方法。

前面3个参数都是前面设置好了,这里不多说了,而getValidationModeForResource(resource)则是否需要对xml文件进行验证,并决定哪种格式,如果xsd,那么返回3,如果dtd,返回2等等。
继续进入到loadDocument方法中去:
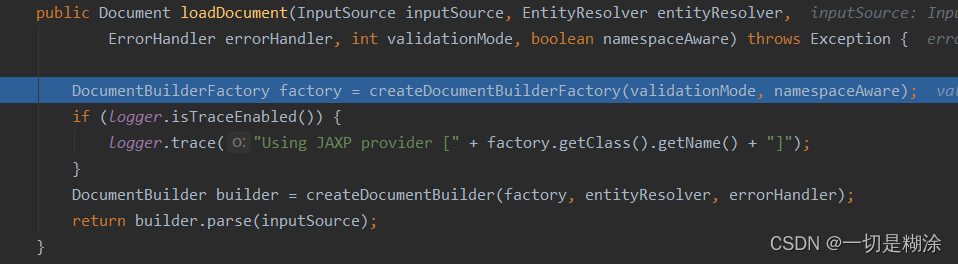
这里创建了一个工厂,根据这个工厂创建了builder,然后就是解析的过程,也就是parse方法。后面整体的解析工作建议不用看了,意义不大。
这里返回到doloadBeanDefinitions方法中,可以看下是否包含document信息。
我们解析好了document后,应该预测下后面会做什么事,应该要解析document的父元素是什么,子元素是什么,还有标签里面的属性又是什么。
总结下上面到底做了什么:,从String[] -string-Resource[]- resource,最终开始将resource读取成一个document文档,根据文档的节点信息封装成一个个的BeanDefinition对象。
然后完成了document方法的执行,下面是registerBeanDefinitions方法。

这里需要对document进行解析,所以创建了documentR解析的对象。
下面,getRegistry,这个就是我们的defaultListableBeanFactory,这里会获取到beanDefinitionMap的size,这里为0.
继续下面,这里registerBeanDefinitions的重载方法,点进入会发现这里有doRegisterBeanDefinitions。

进入到doRegisterBeanDefinitions方法中去:
protected void doRegisterBeanDefinitions(Element root) {
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
if (this.delegate.isDefaultNamespace(root)) {
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(
profileSpec, BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
if (logger.isDebugEnabled()) {
logger.debug("Skipped XML bean definition file due to specified profiles [" + profileSpec +
"] not matching: " + getReaderContext().getResource());
}
return;
}
}
}
preProcessXml(root);
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}
创建了一个委托,去解析,处理工作。
这里会判断是否是默认的命名空间,一般后面的流程spring没有的,也就是是否是profile,所以跳过。
下面的preProcessxml于postProcessxml在springMVC里面扩展。
而中间这个方法就比较重要了,parseBeanDefinitions。
loadBeanDefinitions——》dololadBeanDefinitions——》document——》registerBeanDefinitions——》doregisterBeanDefinitions——》parseBeanDefinitions
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate);
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
这里主要是if里面判断的逻辑,这里会判断是否是默认空间,这里的默认空间里面有哪些标签呢?我们往下debug可以看到进入了parseDefaultElement方法。
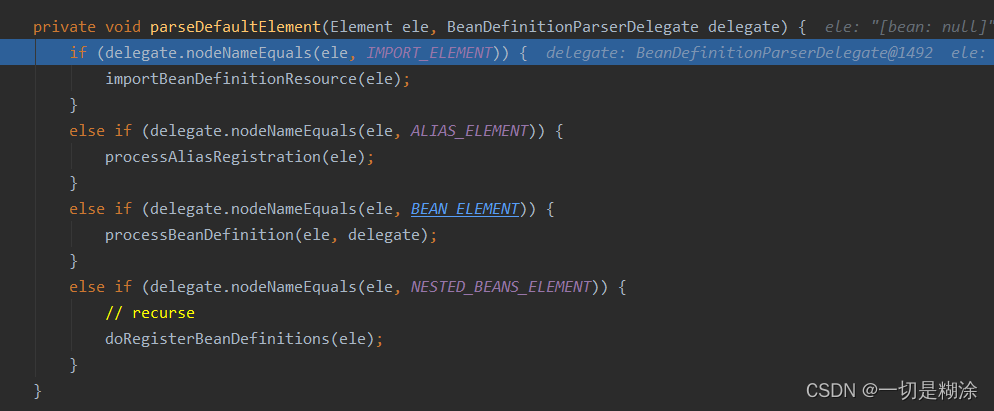
这里就是默认的命名空间,除了Import、bean、alias、nested_beans_element之外,都不是默认的命名空间。
如果不是
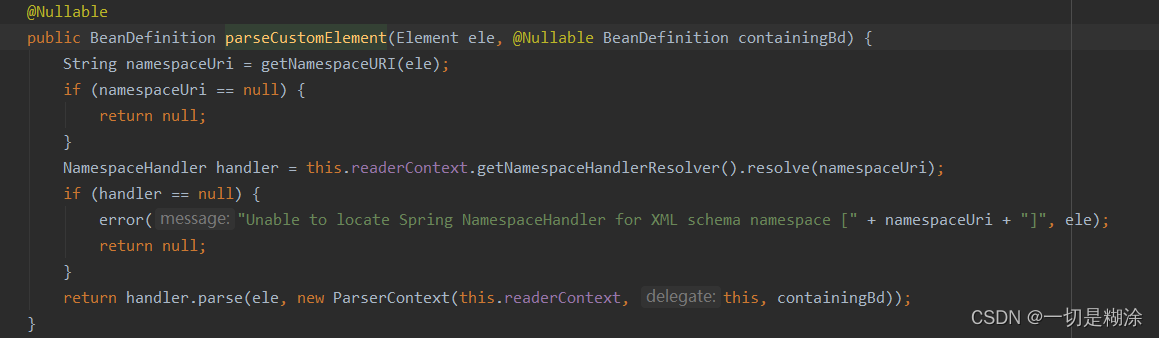
如果不是默认的命名空间,那么需要获取对应的命名空间,根据命名空间找到处理器,再解析。
我们这里用了bean标签,所以进默认的命名空间,然后进行判断,会进入到processBeanDefinition(ele, delegate)方法。
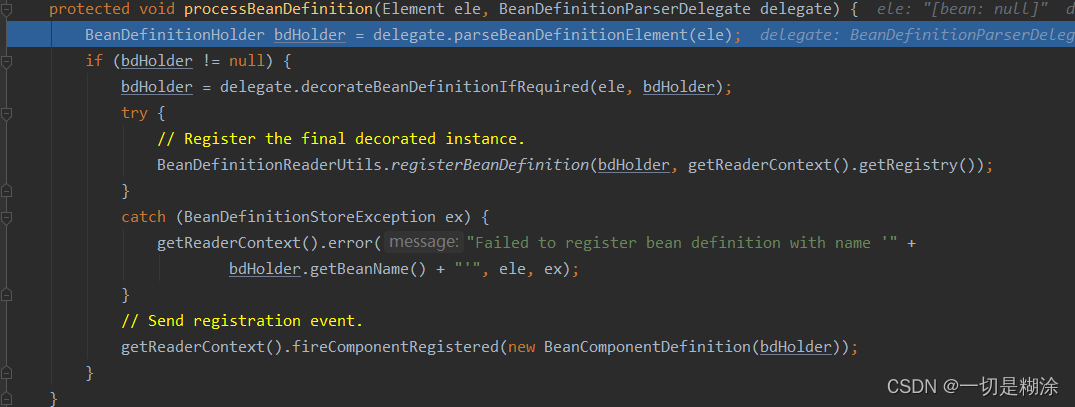 beanDefinitionHolder是beanDefinition对象的封装类,封装了BeanDefinition,bean的名字和别名,用它来完成向IOC容器的注册得到这个beanDefinitionHolder就意味着beandefinition是通过BeanDefinitionParserDelegate对xml元素的信息按照spring的bean规则进行解析得到的。
beanDefinitionHolder是beanDefinition对象的封装类,封装了BeanDefinition,bean的名字和别名,用它来完成向IOC容器的注册得到这个beanDefinitionHolder就意味着beandefinition是通过BeanDefinitionParserDelegate对xml元素的信息按照spring的bean规则进行解析得到的。
这里就是解析元素的方法。

继续进来
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List<String> aliases = new ArrayList<>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isTraceEnabled()) {
logger.trace("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isTraceEnabled()) {
logger.trace("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
首先获取bean的id,name以及别名,检查名字是否唯一。
下面会看到一个parseBeanDefinitionElement方法的重载,因为现在只是解析了3个,其他元素并没有解析,所以这里需要对bean详细的解析。进入到此重载方法可以看到:
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, @Nullable BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
// 解析class属性
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
// 解析parent属性
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
try {
// 创建装在bean信息的AbstractBeanDefinition对象,实际的实现是GenericBeanDefinition
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 解析bean标签的各种其他属性
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
// 设置description信息
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
// 解析元数据
parseMetaElements(ele, bd);
// 解析lookup-method属性
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// 解析replaced-method属性
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
// 解析构造函数参数
parseConstructorArgElements(ele, bd);
// 解析property子元素
parsePropertyElements(ele, bd);
// 解析qualifier子元素
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
在这个方法中,解析好了class与parent属性后,会创建一个beanDefinition,这里默认创建的是GenericBeanDefinition(),并在里面设置了beanClass以及parent。
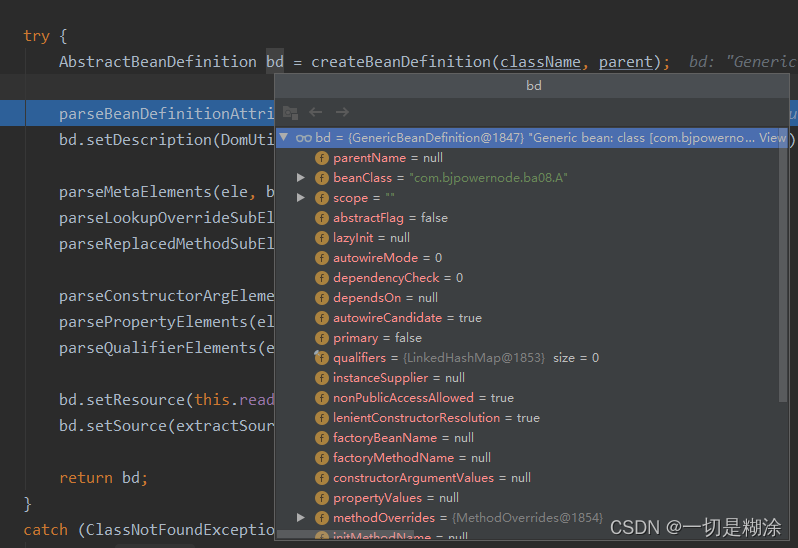
但是可以看到bd的其他属性并没有设置,所以下面就是设置bd的其他属性。这里略过,返回至parseBeanDefinitionElement方法中,beanDefinition已经解析完成了,这个时候需要放到beanFactory里面了。返回至processBeanDefinition,在BeanDefinitionHolder生成后面继续看下面代码。
decorateBeanDefinitionIfRequired这个是装饰的方法,一般不需要装饰的。
继续向下,registerBeanDefinition,往beanfactory里面注册了。
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);
// 处理注册已经注册的beanName情况
if (existingDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);
}
else if (existingDefinition.getRole() < beanDefinition.getRole()) {
if (logger.isInfoEnabled()) {
logger.info("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
existingDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(existingDefinition)) {
if (logger.isDebugEnabled()) {
logger.debug("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + existingDefinition +
"] with [" + beanDefinition + "]");
}
}
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
removeManualSingletonName(beanName);
}
}
else {
// Still in startup registration phase
this.beanDefinitionMap.put(beanName, beanDefinition);
// 记录beanName
this.beanDefinitionNames.add(beanName);
removeManualSingletonName(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (existingDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
else if (isConfigurationFrozen()) {
clearByTypeCache();
}
}
这里有获取beanDefinition时,会判断是否允许覆盖,这个参数实际上我们已经在obtainFreshBeanFactory()设置为true了。
然后放进beanDefinitionMap与beanDefinionNames里面去了,这里完成了意味着已经将、放进beanfactory里面了。
这里就是所有的loadBeanDefinions所有内容了,下一个需要记录下怎么自定义xml标签。
总结
- loadBeanDefinions重载方法的流程:
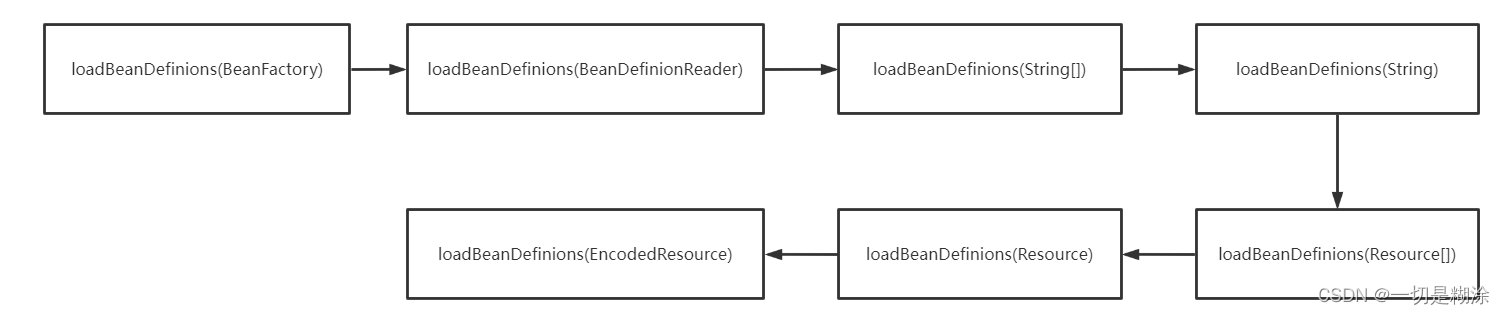
上面是loadBeanDefinions重载方法的流程,这里记录下,其实记这个流程就行,内部的基本都是千篇一律。
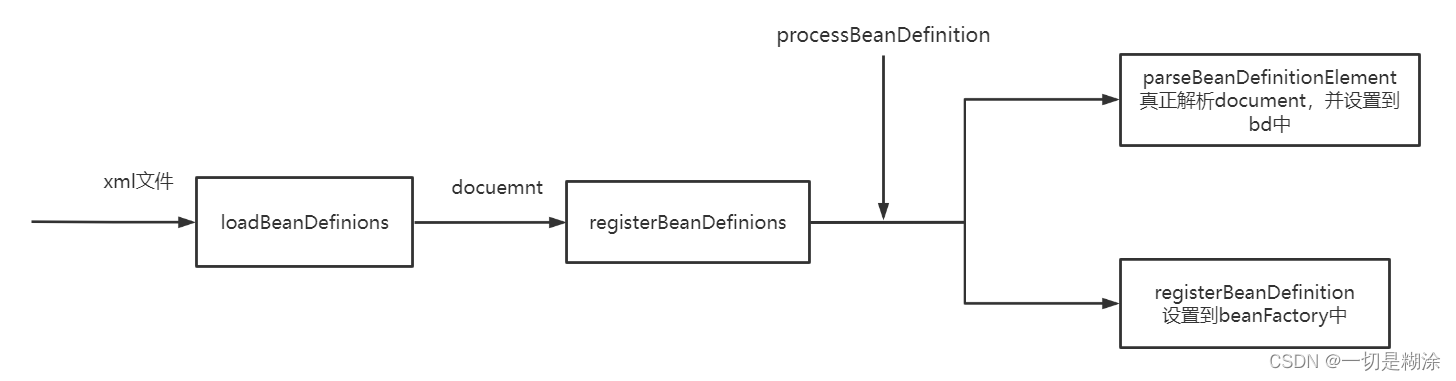
- 下面是loadbeanDefinions解析xml文件整体流程:

上面是loadbeanDefinions解析xml文件整体流程,如果缩略的来说,流程是loadBeanDefinitions ——> dololadBeanDefinitions——> document ——> registerBeanDefinitions ——> doregisterBeanDefinitions ——> parseBeanDefinitions ——> processBeanDefinion ——> BeanDefinionHolder ——> registerBeanDefinition.
仔细的来说,在loadBeanDefinions(EncodeResurce)里面,会将xml用inputStream读进来,并包装成inputSource类,然后调用此方法的doloadBeanDefinions,这里主要做了两个事,一个是将xml文件解析成document结构,并返回一些节点信息;其次注册BeanDefinions,包含了对document文件的解析、设置到beandefinion、设置到beanFactory。在registerBeanDefinions里,创建了document的解析器,然后调用registerBeanDefinitions重载方法完成解析过程,这里会再调用doRegisterBeanDefinitions,这个方法做的事情主要是解析beanDefinions,调用了parseBeanDefinitions方法,这个方法会根据是否是默认的命名空间,决定走哪个方法,如果是,那么走parseDefaultElement,然后如果是bean标签,那么走processBeanDefinition方法,这个方法很重要,包含了document解析,并设置到beanDefinion中,这个方法是返回了beanDinfinionHolder;还有一个作用,将解析完毕的beanDefinion,放到两个集合中去,一个为BeandefinionMap与BeanDefinionNames中,相当于设置到了BeanFactory里了。
至此,loadBeanFactory结束。














 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









