







谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代,被称为Google的三驾马车。本文介绍MapReduce的相关内容。
一、背景
在21世纪初,互联网上的内容,大多数企业需要存储的数据量并不大。但是Google不同,Google的搜索引擎的数据基于爬虫,而由于网页的大量增加,爬虫得到的数据也随之急速膨胀,单机或简单的分布式方案已经不能满足业务的需求,所以Google必须设计新的数据存储系统,其产物就是Google File System(GFS)。
不过,在Google的设计中,为了尽可能的解耦,GFS仅负责数据存储而不提供类似数据库的服务。也就是说,GFS只存数据,而对数据的具体内容一无所知,自然也就不能提供基于内容的检索功能。所以,更进一步,Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。
此外,Google 的搜索结果依赖于PageRank算法的排序,而该算法又需要一些额外的数据,比如某网页的被引用次数,所以他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。
其总体架构如下,GFS能充分利用多个Linux服务器的磁盘,并向上掩盖分布式系统的细节。Bigtable在GFS的基础上对数据内容进行识别和存储,向上提供类似数据库的各种操作。MapReduce则使用Bigtable中的数据进行运算,再提供给具体的业务使用。
二、Map-Reduce基本思想
Map Reduce本来是函数式编程中的两个函数,在尝试解决利用大数据进行计算时,Jeff Dean和Sanjay Ghemawat想到了使用这种思想简化计算模型。
MapReduce把所有的计算都拆分成两个基本的计算操作,即Map和Reduce。其中Map函数以一系列键值对作为输入,然后输出一个中间文件(Intermediate)。这个中间态是另一种形式的键值对。然后,Reduce函数将这个中间态作为输入,计算得出结果。其中,Map函数和Reduce函数的逻辑都是由开发人员自行定义的。一种经典的逻辑如下图所示。
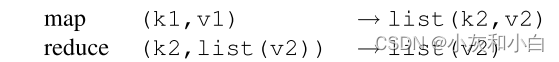
以WordCount为例,准备要统计一本书中所有单词出现的次数。在Map函数中,我们每遇到一个单词W,就往中间文件中写入(W,1)。然后,在Reduce函数中,把所有(W,1)出现的次数相加,就能得到W的出现次数V。
三、Map-Reduce流程
上面提到的模型和思想都是单机的,想要在分布式系统中实现,还需要一些改动。在MapReduce中,他们选择将大任务拆分成小任务分配给多台机器,以此充分利用分布式系统的性能。下图是论文中展示的MapReduce的流程图。
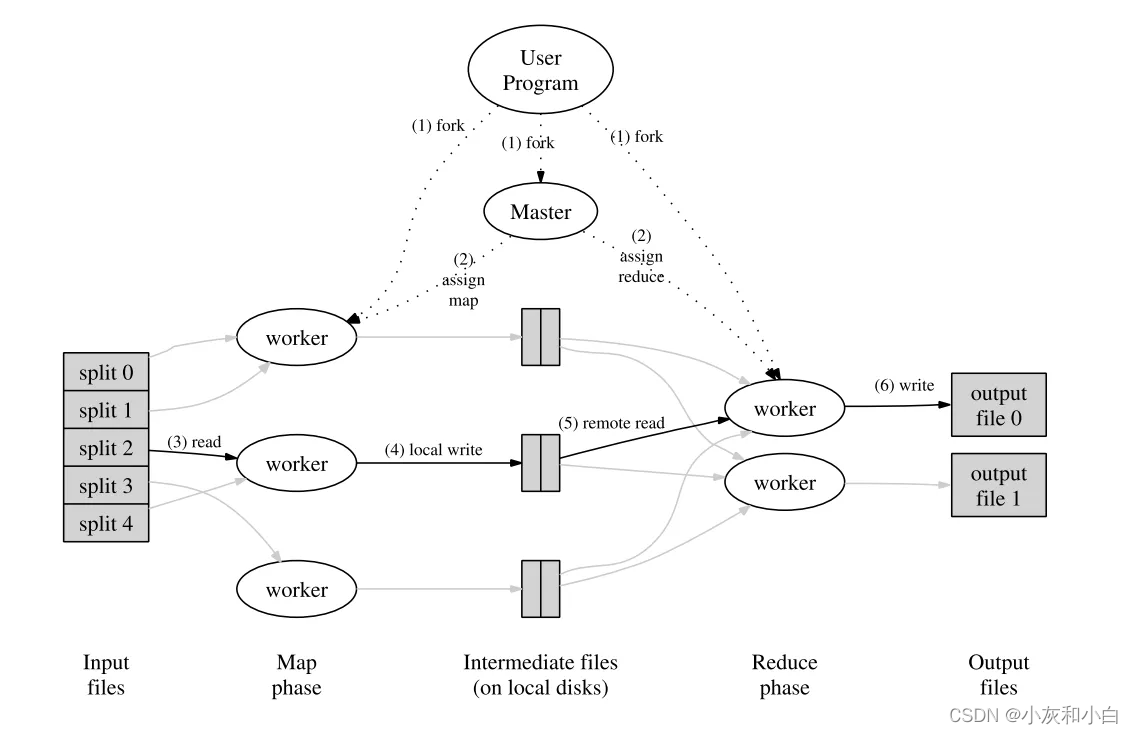
具体的流程如下
1.MapReduce客户端会将输入的文件会分为M个片段,每个片段的大小通常在 16~64 MB 之间。然后在多个机器上开始运行MapReduce程序。
2.系统中会有一个机器被选为Master节点,整个 MapReduce 计算包含M个Map 任务和R个 Reduce 任务。Master节点会为空闲的 Worker节点分配Map任务和 Reduce 任务
3.执行Map任务的 Worker开始读入自己对应的片段并将读入的数据解析为输入键值对。然后调用由用户定义的 Map任务。最后,Worker会将Map任务输出的结果存在内存中。
4.在执行Map的同时,Map Worker根据Partition 函数将产生的中间结果分为R个部分,然后定期将内存中的中间文件存入到自己的本地磁盘中。任务完成时,Mapper 便会将中间文件在其本地磁盘上的存放位置报告给 Master。
5.Master会将中间文件存放位置通知给Reduce Work。Reduce Worker接收到这些信息后便会通过RPC读取中间文件。在读取完毕后,Reduce Worker会对读取到的数据进行排序,保证拥有相同键的键值对能够连续分布。
6.最后,Reduce Worker会为每个键收集与其关联的值的集合,并调用用户定义的Reduce 函数。Reduce 函数的结果会被放入到对应的结果文件。
7.当所有Map和Reduce都结束后,程序会换新客户端并返回结果。
主要流程:
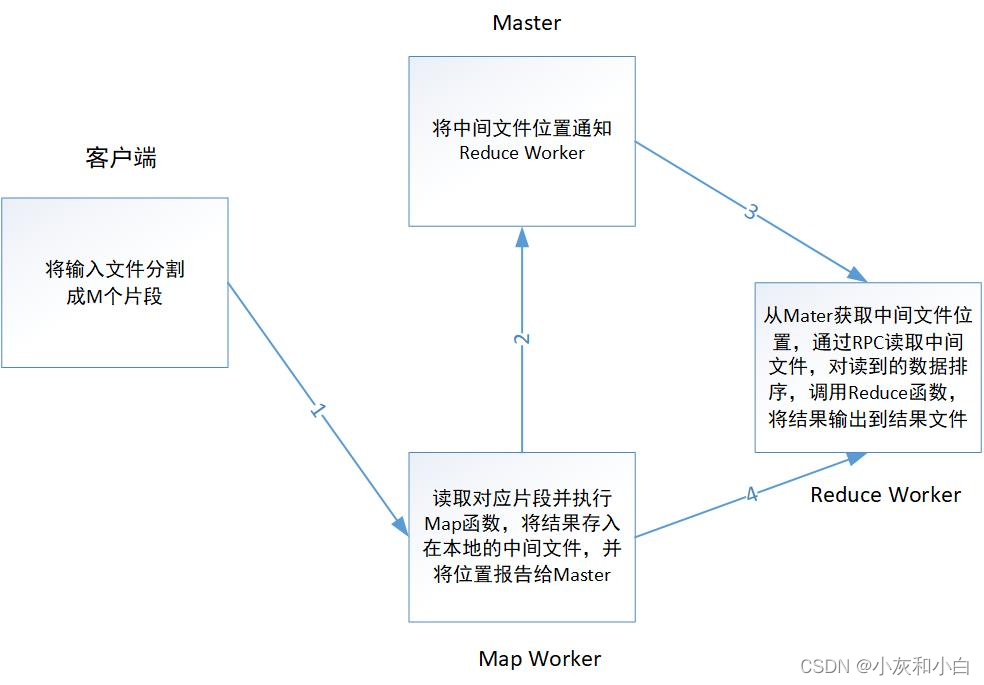
四、容错
1.Master
周期性的写入CheckPoints,遇到故障恢复最近的。
2.Worker
Master定期Ping所有的Worker,如果一定时间内没有收到回复,Master则标记该Worker故障。
(1)Map任务
故障Worker上所有正在进行和已完成的Map任务都需要重新调度运行,因为Map任务输出结果在Worker的本地机器,因该机器故障我们无法读取,所以已完成的Map任务也需要重新运行。
(2)reduce任务
故障Worker上所有正在运行的Reduce任务需要重新调度运行,已完成的Reduce任务不需要重新运行,因为Reduce任务的结果输出在GFS上。
五、优化点——Backup Tasks
当一个MapReduce操作接近完成时,Master会给还在执行的长尾任务调度一个备用节点来执行。不管原来的还是备用的节点执行完毕,这个任务都会被标记为执行完成。
六、总结
MapReduce是一个相当简单的计算模型,它尝试将所有的计算任务都拆分成基础的Map和Reduce,以此降低实现的复杂度。但是,这恰恰提高了编程逻辑的复杂度。
另一方面,MapReduce的程序类似于批处理程序,需要完整的输入程序才能开始运算,而且每次运算都要至少写入两次磁盘。这就导致每次运算都要等待很长的时间,完全不能实现需要快速响应的业务场景的需求。
以上两个方面,一个引出了支持类SQL的计算工具,另一个引出了支持流式计算的工具,而这两个特性正是今天流行的计算工具的热点。
总得来说,虽然MapReduce在今天几乎抛弃了,但是在当初那个年代以及谷歌的业务需求看来,是相当合适的。















 2337
2337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









