









scrapy 兼容 cloudscraper
scrapy 原生对 cloudscraper的兼容性差
经过我这几天的摸索和时间,scrapy对cloudscerper兼容性并不好,所以需要进行一定的二次开发,才能加强兼容性
神奇的AroayCloudScraper
上面说需要做二次开发调整,才能提高兼容性,好在已经有大佬做了这件事,它就是AroayCloudScraper,github地址
超级简单的使用方式(参考作者的文档)
settings 设置:
# 默认日志级别
AROAY_CLOUDSCRAPER_LOGGING_LEVEL = logging.DEBUG(可调整)
默认超时
AROAY_CLOUDSCRAPER_DOWNLOAD_TIMEOUT = 30
# 默认延迟
AROAY_CLOUDSCRAPER_DELAY = 1
#必须设置,否则报错
COMPRESSION_ENABLED = False
RETRY_ENABLED: True
RETRY_TIMES: 3
建议:
如果只有少部分爬虫用到cloudscraper,建议将相关的AROAY设置,放到爬虫的custom_settings中(暂时不建议这么做,还是全局setting把,需要注意COMPRESSION_ENABLED = False的影响).
Middleware:
'aroay_cloudscraper.downloadermiddlewares.CloudScraperMiddleware': 543,
代码样本:
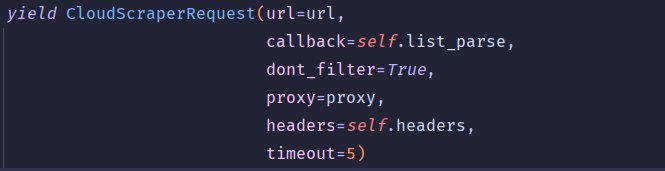
proxy说明
proxy 为cloudscraper所用,格式是:
proxy = {
'http': 'http://***',
'https': 'https://****'
}
headers 说明
headers中可加cookie,也可不加,作者写的代码里,单独加了对cookie的支持,感兴趣的可看源码.
因使用cloudescraper需升级openssl版本教程




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











