







《Redis设计与实现》(一)数据结构与对象
1、简单动态字符串(SDS)
1、1 总览





SDS的作用不止于此,它在redis中也被用作缓冲区,如AOF中的AOF缓冲区,客户端的输入缓冲区。
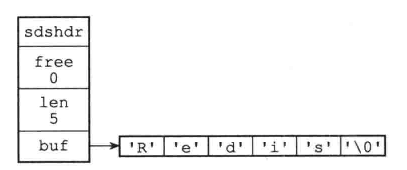
1、2 SDS数据结构

示例:
1、3 SDS与C语言字符串的区别
-
获取字符串长度的时间复杂度:
SDS为O(1),因为SDS的数据结构维护了len变量;
C语言字符串(后续称之为C串)为O(N),因为要遍历整个串。 -
杜绝缓冲区溢出:
C语言的字符串拼接函数:

在C中,使用这个函数可能会缓冲区溢出,因为拼接之后原串的长度会边长,会覆盖后面一些字节空间的内容,即溢出。
而在SDS中,也有类似的函数,叫sdscat,它不会溢出,因为在拼接之前会预先申请足够的空间。 -
修改字符串时的内存重分配次数
在C中,每次增加或者缩短一个字符串的时候,都需要对保存该C串的字符数组重新进行内存分配。若不分配,当增长C串时,会缓存溢出;在缩短C串时,会内存泄漏。
而在SDS中,由于空间预分配和惰性空间释放这两个特点,可以减少内存重新分配次数。
空间预分配:在增长字符串时,SDS的API会申请额外的空间。
惰性空间释放:在缩短字符串时,SDS不会立即释放未使用的空间,而是用free关键字来记录未使用的空间。 -
二进制安全
C串只能保存文本,不能保存二进制文件,因为二进制文件中可能包含’\0’。
而SDS可以,因为在SDS的buf数组中保存的不是字符,而是二进制数据(暂不理解),因此在redis中存入什么,就能原封不动的读出什么。

2、redis的链表
数据结构:


例子:

特点:

3、字典
redis的字典可以用来保存数对键值对,如下图所示

3、1数据结构
redis的字典基于hash表,由于C语言没有实现hash表,所以redis自己实现了,其结构如下:

上图是redis的hash表的数据结构示意图,而redis的字典的数据结构和示意图如下:


下图是一个没有在rehash状态下的字典的示意图:

3、2hash算法
计算dictEntry的索引的方法:hash(key) & (size - 1)
解决hash冲突:链地址法
负载因子的计算方法:
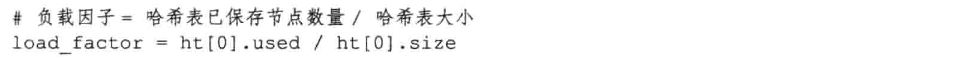
当负载因子小于0.1时,程序自动收缩哈希表;

在执行BGSAVE或者BGREWRITEAOF命令的时候,为了防止rehash的发生,redis提高了负载因子的阈值

3、3渐进式hash


4、跳跃表-有序集合
https://www.cnblogs.com/hunternet/p/11248192.html
5、整数集合

5、1 整型的升级

注:全部元素都要升级,时间复杂度是O(n)
往redis的整数集合里面添加一个整数,时间复杂度是O(n),即最坏情况。
升级之后不会降级。
6、 压缩列表
https://www.cnblogs.com/hunternet/p/11306690.html
7、对象
7、1 数据结构


7、2 redis中的对象
7、2、1 字符串对象
如果一个字符串对象保存的是整数值,并且这个整数值可以用long来保存,那么redis会用int来encoding该字符串对象,并且将对象头中的ptr由void*改为long。


如果保存的是普通的串:
长度大于32字节的,用SDS来保存这个值,编码方式为raw
否则,编码方式为embstr



long double类型的浮点数在redis中也是用字符串来保存的



int可以转为raw,比如向数值类型的字符串append一些字符。
embstr不可修改,当需要修改时,会转成raw编码
7、2、2 列表对象
列表对象的编码可以是ziplist和linkedList

当以ziplist编码的列表,不满足以上条件的时候,会由ziplist编码转换成linkedList编码
7、2、3 哈希对象
hash对象的编码可以是ziplist和hashtable,用ziplist编码的hash对象如图所示:



ziplist可以转成hashtable
7、2、4 集合对象
编码可以是intset和hashtable

intset可以转成hashtable
7、2、5 有序集合
编码是ziplist和skiplist
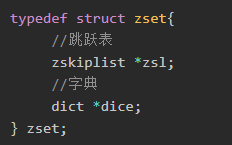
为什么同时使用这两种编码方式呢?
其实有序集合单独使用字典或跳跃表其中一种数据结构都可以实现,但是这里使用两种数据结构组合起来,原因是假如我们单独使用 字典,虽然能以 O(1) 的时间复杂度查找成员的分值,但是因为字典是以无序的方式来保存集合元素,所以每次进行范围操作的时候都要进行排序;假如我们单独使用跳跃表来实现,虽然能执行范围操作,但是查找操作有 O(1)的复杂度变为了O(logN)。因此Redis使用了两种数据结构来共同实现有序集合。

7、3 内存回收
由于C语言没有内存回收功能,所以redis采用了基于引用计数的内存回收机制


7、4 对象共享
redis在启动时,会创建0-9999这些数值的字符串对象,当后续有创建这些对象时,只需要引用即可,无需新创建。大大节省内存。















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









