







前言:
工作中涉及到并发编程,于是看了看java集合源码的各种实现,在这里记录下。
汇总贴CSDN链接:【看看源码】Java1.8 集合源码
一、初识ArrayList
首先看一下类引用框图:
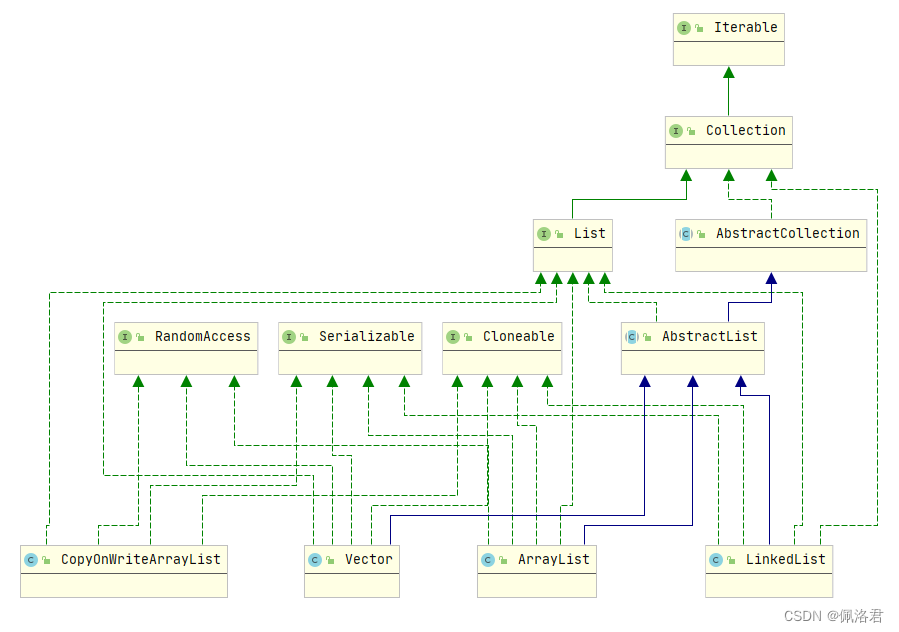
然后翻译下ArrayList的类的官方注释:
*List接口的由可调整大小的数组实现。实现所有可选的列表操作,并允许所有元素,包括null。
除了实现List接口外,这个类还提供了一些方法来操作内部用于存储列表的数组的大小。
(这个类大致相当于Vector,只是它是不同步的。)
*size、isEmpty、get、set、迭代器和listIterator操作以恒定时间运行。
加法运算以摊余常数时间进行,即添加n个元素需要O(n)时间。
所有其他操作都在线性时间内运行(粗略地说)。
与LinkedList实现相比,常数因子较低。
*每个ArrayList实例都有一个容量。容量是用于存储列表中元素的数组的大小。
它总是至少与列表大小一样大。当元素添加到ArrayList时,其容量会自动增长。
除了增加一个要素具有恒定的摊余时间成本这一事实之外,没有具体说明增长政策的细节。
*应用程序可以在使用ensureCapacity操作添加大量元素之前增加ArrayList实例的容量。
这可能会减少增量重新分配的数量。
*请注意,此实现不是同步的。
*如果多个线程同时访问一个ArrayList实例,
并且至少有一个线程在结构上修改了该列表,则必须对其进行外部同步。
(结构修改是指添加或删除一个或多个元素,或显式调整后台数组大小的任何操作;
仅设置元素的值不是结构修改。)这通常是通过对一些自然封装列表的对象进行同步来实现的。
*如果不存在这样的对象,则应使用{@link Collections#synchronizedList Collections.synchronizedList}方法“包装”列表。
最好在创建时执行此操作,以防止意外地对列表进行不同步的访问:
*List List=集合。synchronizedList(新的ArrayList(…));
*此类的{@link#迭代器()迭代器}和
{@link#listIterator(int)listIterator}方法返回的迭代器是故障快速的:
*如果在迭代器创建后的任何时候都对列表进行了结构修改,
则可以通过迭代器自己的方式以外的任何方式进行修改
*{@link ListIterator#remove()remove}或
*{@link ListIterator#add(Object)add}方法,迭代器将抛出
*{@link并发修改异常}。因此,面对并发修改,迭代器会迅速而干净地失败,
而不是冒着在未来不确定的时间出现任意、不确定行为的风险。
*请注意,迭代器的快速失效行为是无法保证的,因为一般来说,在存在不同步的并发修改的情况下,不可能做出任何硬保证。
故障快速迭代器在尽最大努力的基础上抛出{@code ConcurrentModificationException}。
*因此,编写依赖于此异常的正确性的程序是错误的:迭代器的快速故障行为应该只用于检测错误。
*此类是<a href=“{@docRoot}/../technotes/guides/collections/index.html”>的成员
*Java集合框架</a>。
从注释中,我们就可以获得一些明确的信息:
- (原文:Resizable-array implementation of the List interface. )
List接口的由可调整大小的数组实现,说白了就是动态数组。 - ArrayList是不同步的(不是线程安全的)
二、ArrayList初始化
我们看下源码:
我们平常初始化一个ArrayList对象时,一般初始化方法:
List list = new ArrayList(); //编译的时候只认父类
对应的是空参构造器
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
/*用于默认大小的空实例的共享空数组实例。
我们将其与EMPTY_ELEMENTDATA区分开来,以了解添加第一个元素时要膨胀多少。*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
/*存储ArrayList元素的数组缓冲区。
ArrayList的容量就是这个数组缓冲区的长度。
添加第一个元素时,任何elementData==DEFAULTCAPACITY_empty_elementData的
空ArrayList都将扩展为DEFAULT_CAPACITY。*/
transient Object[] elementData; // non-private to simplify nested class access
....
....
....
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
其中做了一个对 this.elementData 的赋值,elementData类型是transient Object[]
在Java中,transient是一个关键字,用于修饰实例变量(成员变量)。当一个实例变量被声明为transient时,它的值不会被持久化(即不会被序列化)。
那么ArrayList为什么要将存储数据的this.elementData用transient修饰?
答:
- 避免序列化大量未使用空间:ArrayList 底层使用数组来存储元素,并且通常会有一些预留的空间用于未来的扩展。如果直接序列化整个数组,那么这些未使用的空间也会被序列化,从而导致序列化后的数据体积增大。使用 transient 修饰 elementData 可以避免这些未使用空间被序列化。
- 提高序列化性能:只序列化数组中实际使用的部分,可以减少序列化所需的时间和带宽,从而提高性能。
- 确保数据的完整性:虽然 elementData 用 transient 修饰,但在 ArrayList 的 writeObject 方法中,会手动将数组中实际存储的元素写入到输出流中。在反序列化时,通过 readObject 方法读取这些元素并恢复到 elementData 中。这样可以确保在序列化和反序列化过程中数据的完整性。
- 支持泛型:由于 ArrayList 是泛型集合,其 elementData 数组在编译时并不知道具体类型。如果直接序列化 elementData,那么在反序列化时可能无法正确地恢复元素类型。通过 transient 和自定义的序列化逻辑,可以确保类型信息在序列化过程中得到正确处理。
综上所述,将 elementData 用 transient 修饰是为了优化 ArrayList 的序列化性能,同时确保数据的完整性和类型信息。
三、ArrayList add()方法导致数组扩容
当初始化完成后,向ArrayList中添加元素时,当list.size > 10 就会触发扩容,具体请看源码:
public static void main(String[] args) {
List list = new ArrayList();
for(int i =0 ;i < 30; i++){
list.add("111"); //当list.size() = 11时,F7进入add()方法
}
}
F7进入add()方法
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
再进入ensureCapacityInternal()方法
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
...
...
...
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
很明显,现在的minCapacity入参是11,直接进入ensureExplicitCapacity()方法。
(modCount此时也是11,英文注释是 The number of times this list has been structurally modified,就是此list在结构上被修改的次数)
总之在ensureExplicitCapacity()方法中,minCapacity - elementData.length > 0判断为true,进入grow()方法,而这个grow方法估计就是数组动态扩容的方法了。
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
其中minCapacity传入11,则 newCapacity = oldCapacity+ oldCapacity /2 = 15,新的扩容长度为15。
Arrays.copyOf()方法是 Java 中 java.util.Arrays 类的一个方法,用于复制数组。这个方法接收两个参数:要复制的原始数组和一个新数组的长度。它可以用来创建一个原始数组的浅拷贝,并且新数组的长度可以与原始数组相同,也可以更大。
Arrays.copyOf() 方法是线程安全的,因为它是一个静态方法,不依赖于任何实例变量,所以可以安全地在多个线程之间共享。同时,Arrays.copyOf() 方法内部使用的是 System.arraycopy() 方法,后者也是线程安全的。
但是,需要注意的是,**虽然 Arrays.copyOf() 方法是线程安全的,但如果你在多个线程中共享原始数组本身,那么数组本身可能不是线程安全的。**在这种情况下,你需要采取适当的同步措施,以防止在复制数组时发生并发修改异常。
四、ArrayList remove()方法
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
*
* @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
我们可以看到,每一次remove()都需要一次
整体System.arraycopy(elementData, index+1, elementData, index,numMoved);
这个方法接收五个参数,分别表示:
- elementData:源数组,即要从中复制元素的数组。
- index+1:源数组中的起始位置(开始复制元素的位置)。
- elementData:目标数组,即要复制到哪个数组。
- index:目标数组中的起始位置(开始粘贴元素的位置)。
- numMoved:要复制的元素数量。
这个方法可以实现数组中元素的移动和复制。
需要注意的是,源数组和目标数组可以是同一个数组,这样就可以实现数组中元素的移动。
当remove掉大部分元素时,我们发现this.elementData 并没有缩小,当然这是符合直觉的,因为代码中没有缩容的实现

可以看到,扩容至33的this.elementData 的length没有减少,被remove的元素都变成了null。
五、ArrayList在并发下保证线程安全
import java.util.ArrayList;
import java.util.List;
public class CollectionTest {
private static List<Integer> list = new ArrayList<>();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
testList();
list.clear();
}
}
private static void testList() throws InterruptedException {
Runnable runnable = () -> {
for (int i = 0; i < 100000; i++) {
try {
list.add(i);
}catch (Exception e){
e.printStackTrace();
}
}
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
Thread t3 = new Thread(runnable);
t1.start();
t2.start();
t3.start();
t1.join();
t2.join();
t3.join();
System.out.println(list.size());
}
}
控制台运行后
Connected to the target VM, address: '127.0.0.1:62036', transport: 'socket'
java.lang.ArrayIndexOutOfBoundsException: 823
at java.util.ArrayList.add(ArrayList.java:459)
at com.health.video.CollectionTest.lambda$testList$0(CollectionTest.java:20)
at java.lang.Thread.run(Thread.java:745)
119151
142703
132376
128572
158921
129364
128966
129584
136424
134454
显然是不正确的,因为按照线程安全去理解,输出不应该有报错并且,十次输出结果每次都应该为300000
比如我们把多线程任务目标设定小一点设定成不扩容的10,则十次输出均成功
Connected to the target VM, address: '127.0.0.1:62483', transport: 'socket'
30
30
30
30
30
30
30
30
30
30
但只要设计成11,让动态数组达到扩容的条件,则很大概率会出错。
Connected to the target VM, address: '127.0.0.1:62725', transport: 'socket'
java.lang.ArrayIndexOutOfBoundsException: 10
at java.util.ArrayList.add(ArrayList.java:459)
at com.health.video.CollectionTest.lambda$testList$0(CollectionTest.java:20)
at java.lang.Thread.run(Thread.java:745)
32
33
33
33
33
33
33
33
33
33
所以可以证明,ArrayList在多线程并发下是线程不安全的,可能导致扩容不及时的ArrayIndexOutOfBoundsException,或者最后总数量出错,下面进行多线程并发下的错误情况分析。
- 错误情况1:发生 ArrayIndexOutOfBoundsException 异常
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
通过add方法的源码可以看出:ArrayList的实现主要就是用了一个Object的数组,用来保存所有的元素,以及一个size变量用来保存当前数组中已经添加了多少元素。执行add方法时,主要分为两步:
(1) 首先判断elementData数组容量是否满足需求——>判断如果将当前的新元素加到列表后面,列表的elementData数组的大小是否满足,如果size + 1的这个需求长度大于了elementData这个数组的长度,那么就要对这个数组进行扩容;
(2)之后在elementData对应位置上设置元素的值。
1.列表大小为9,即size=9
2.线程A开始进入add方法,这时它获取到size的值为9,调用ensureCapacityInternal方法进行容量判断。
3.线程B此时也进入add方法,它获取到size的值也为9,也开始调用ensureCapacityInternal方法。
4.线程A发现需求大小为10,而elementData的大小就为10,可以容纳。于是它不再扩容,返回。
5.线程B也发现需求大小为10,也可以容纳,返回。
6.线程A开始进行设置值操作, elementData[size++] = e 操作。此时size变为10。
7.线程B也开始进行设置值操作,它尝试设置elementData[10] = e,而elementData没有进行过扩容,它的下标最大为9。
于是此时会报出一个数组越界的异常ArrayIndexOutOfBoundsException.
由于ArrayList添加元素是如上面分两步进行,可以看出第一个不安全的隐患,在多个线程进行add操作时可能会导致elementData数组越界。
-
错误情况2:程序正常运行,输出了少于实际容量的大小
这个也是多线程并发赋值时,对同一个数组索引位置进行了赋值,所以出现少于预期大小的情况。 -
错误情况3:程序正常运行,输出了预期容量的大小
这是正常运行结果,未发生多线程安全问题,但这是不确定性的,不是每次都会达到正常预期的。
那么如何改善ArrayList多线程并发下的线程不安全问题?
- Vector
private static List<Integer> list = new Vector<>();
就效果来看完全解决了并发下线程不安全的问题,看看Vector是如何解决的。
/**
* The array buffer into which the components of the vector are
* stored. The capacity of the vector is the length of this array buffer,
* and is at least large enough to contain all the vector's elements.
*
* <p>Any array elements following the last element in the Vector are null.
*
* @serial
*/
protected Object[] elementData;
/**
* The number of valid components in this {@code Vector} object.
* Components {@code elementData[0]} through
* {@code elementData[elementCount-1]} are the actual items.
*
* @serial
*/
protected int elementCount;
/**
* The amount by which the capacity of the vector is automatically
* incremented when its size becomes greater than its capacity. If
* the capacity increment is less than or equal to zero, the capacity
* of the vector is doubled each time it needs to grow.
*
* @serial
*/
protected int capacityIncrement;
...
...
...
/**
* Constructs an empty vector with the specified initial capacity and
* capacity increment.
*
* @param initialCapacity the initial capacity of the vector
* @param capacityIncrement the amount by which the capacity is
* increased when the vector overflows
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
...
...
...
/**
* This implements the unsynchronized semantics of ensureCapacity.
* Synchronized methods in this class can internally call this
* method for ensuring capacity without incurring the cost of an
* extra synchronization.
*
* @see #ensureCapacity(int)
*/
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
...
...
...
/**
* Appends the specified element to the end of this Vector.
*
* @param e element to be appended to this Vector
* @return {@code true} (as specified by {@link Collection#add})
* @since 1.2
*/
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
/**
* Removes the first occurrence of the specified element in this Vector
* If the Vector does not contain the element, it is unchanged. More
* formally, removes the element with the lowest index i such that
* {@code (o==null ? get(i)==null : o.equals(get(i)))} (if such
* an element exists).
*
* @param o element to be removed from this Vector, if present
* @return true if the Vector contained the specified element
* @since 1.2
*/
public boolean remove(Object o) {
return removeElement(o);
}
/**
* Inserts the specified element at the specified position in this Vector.
* Shifts the element currently at that position (if any) and any
* subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws ArrayIndexOutOfBoundsException if the index is out of range
* ({@code index < 0 || index > size()})
* @since 1.2
*/
public void add(int index, E element) {
insertElementAt(element, index);
}
/**
* Removes the first (lowest-indexed) occurrence of the argument
* from this vector. If the object is found in this vector, each
* component in the vector with an index greater or equal to the
* object's index is shifted downward to have an index one smaller
* than the value it had previously.
*
* <p>This method is identical in functionality to the
* {@link #remove(Object)} method (which is part of the
* {@link List} interface).
*
* @param obj the component to be removed
* @return {@code true} if the argument was a component of this
* vector; {@code false} otherwise.
*/
public synchronized boolean removeElement(Object obj) {
modCount++;
int i = indexOf(obj);
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
/**
* Inserts the specified object as a component in this vector at the
* specified {@code index}. Each component in this vector with
* an index greater or equal to the specified {@code index} is
* shifted upward to have an index one greater than the value it had
* previously.
*
* <p>The index must be a value greater than or equal to {@code 0}
* and less than or equal to the current size of the vector. (If the
* index is equal to the current size of the vector, the new element
* is appended to the Vector.)
*
* <p>This method is identical in functionality to the
* {@link #add(int, Object) add(int, E)}
* method (which is part of the {@link List} interface). Note that the
* {@code add} method reverses the order of the parameters, to more closely
* match array usage.
*
* @param obj the component to insert
* @param index where to insert the new component
* @throws ArrayIndexOutOfBoundsException if the index is out of range
* ({@code index < 0 || index > size()})
*/
public synchronized void insertElementAt(E obj, int index) {
modCount++;
if (index > elementCount) {
throw new ArrayIndexOutOfBoundsException(index
+ " > " + elementCount);
}
ensureCapacityHelper(elementCount + 1);
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index);
elementData[index] = obj;
elementCount++;
}
可以看到,所有的add和remove底层调用的子方法都被synchronized 关键字修饰了,从而保证了线程安全。
扩容方法grow和ArrayList基本一致,不同的是两倍扩容。
//capacityIncrement 默认值为0
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);
- java.util.Collections.SynchronizedList
它能把所有 List 接口的实现类转换成线程安全的List,比 Vector 有更好的扩展性和兼容性。
SynchronizedList的初始化方式如下:
private static List<Integer> list = Collections.synchronizedList(new ArrayList<>());
它能把所有 List 接口的实现类转换成线程安全的List,比 Vector 有更好的扩展性和兼容性。
实现是基本上所有方法都加上了synchronized 锁。
public int hashCode() {
synchronized (mutex) {return list.hashCode();}
}
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
public int indexOf(Object o) {
synchronized (mutex) {return list.indexOf(o);}
}
public int lastIndexOf(Object o) {
synchronized (mutex) {return list.lastIndexOf(o);}
}
public boolean addAll(int index, Collection<? extends E> c) {
synchronized (mutex) {return list.addAll(index, c);}
}
很可惜,它所有方法都是带同步对象锁的,和 Vector 一样,它不是性能最优的。
比如在读多写少的情况,SynchronizedList这种集合性能非常差,还有没有更合适的方案?
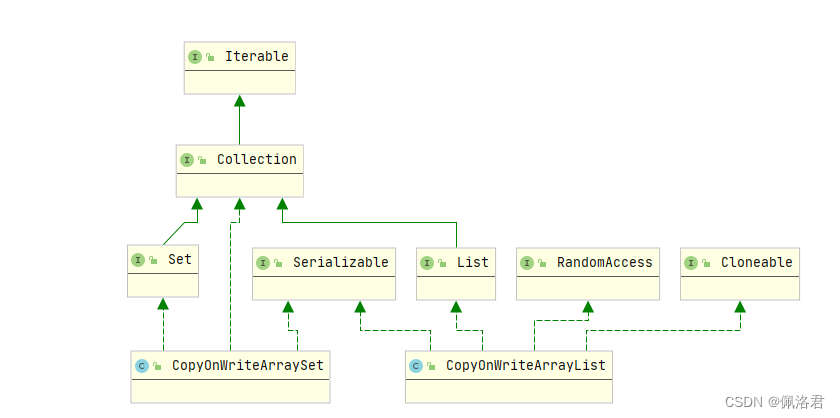
- java.util.concurrent.CopyOnWriteArrayList 和 java.util.concurrent.CopyOnWriteArraySet
CopyOnWrite集合类也就这两个,Java 1.5 开始加入,你要能说得上这两个才能让面试官信服。
CopyOnWrite(简称:COW):即复制再写入,就是在添加元素的时候,先把原 List 列表复制一份,再添加新的元素。
初始化方法:
private static List<Integer> list = new CopyOnWriteArrayList<>();
然而经过我的测试,100000条数据add跑得相当慢,我都以为是不是写错了。
一看它的源码才发现,每次add都加锁然后复制一遍数组?这不是纯纯大怨种吗。
/**
* Replaces the element at the specified position in this list with the
* specified element.
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
可以看到,每次add添加元素时,先加锁,再进行复制替换操作,最后再释放锁。
而它的get方法是不加锁的
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return get(getArray(), index);
}
可以看到,获取元素并没有加锁。
这样做的好处是,在高并发情况下,读取元素时就不用加锁,写数据时才加锁,大大提升了读取性能。
但是对于写入操作很多的并发场景,这种集合太慢了。
这是错误的方式,因为CopyOnWriteArraySet不可以当List用,因为没继承,它本质是一个Set
private static List<Integer> list = new CopyOnWriteArraySet<Integer>(); //错误,直接报编译错误
- 使用ThreadLocal
ThreadLocal在我看来只能保证每个线程中该变量不被影响,但是无法共享每个线程的改变到其他线程。















 8204
8204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









