









写在前面
小编来广州已经读了一年书了,对广州当地的美食还是品尝过不少的,说真的,广州的美食真的很深受小编的喜爱。于是,今天闲时有空,看看美团官网上各大美食的情况吧。
一、目标网站
美团官网:广州美食
二、工具
今天采用pymongo模块来存储那么多详细的信息,其他的工具照旧。
三、网站分析
总的来说,这个美团官网对这商户信息的保护还是蛮公开的,大家尽可能看到详尽。所以来很容易获取到其主要信息。
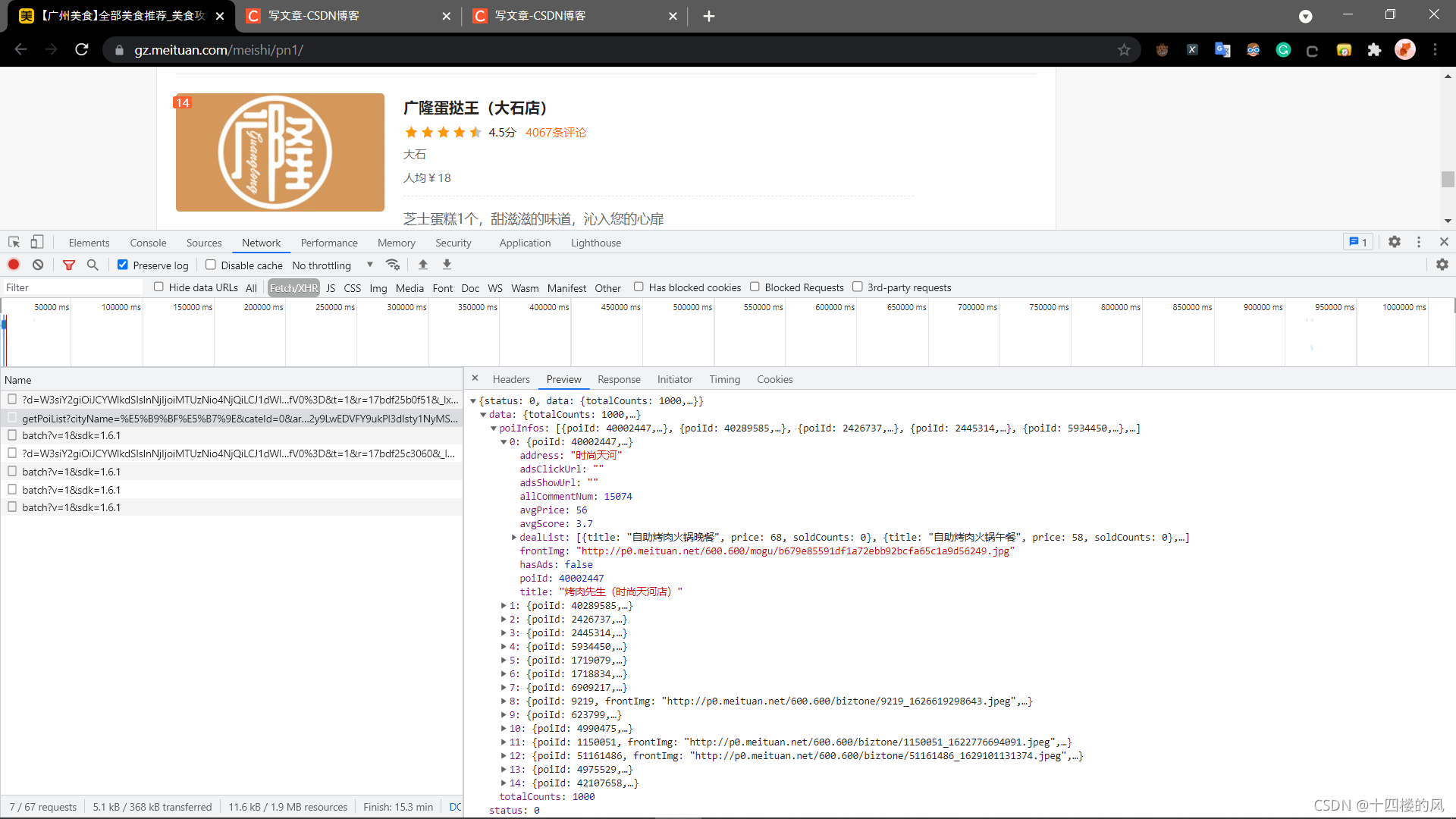
很明显,该链接下就有我们需要的信息,看来不用费什么太大的功夫了。
但是在写代码测试过程中,小编发现,该网站对请求的头部信息有点要求,因此一定要加上去,尤其需要登陆后才能看到这些信息。这些都是简单操作,小编就不详细说明了。
四、代码展示
百度网盘链接:https://pan.baidu.com/s/1eSe-FhDsRCA7DVAtIscP2A
提取码:nf9z
代码中唯一的瑕疵就是小编将cookie去掉了,大家可以自己加就行。
五、结果展示
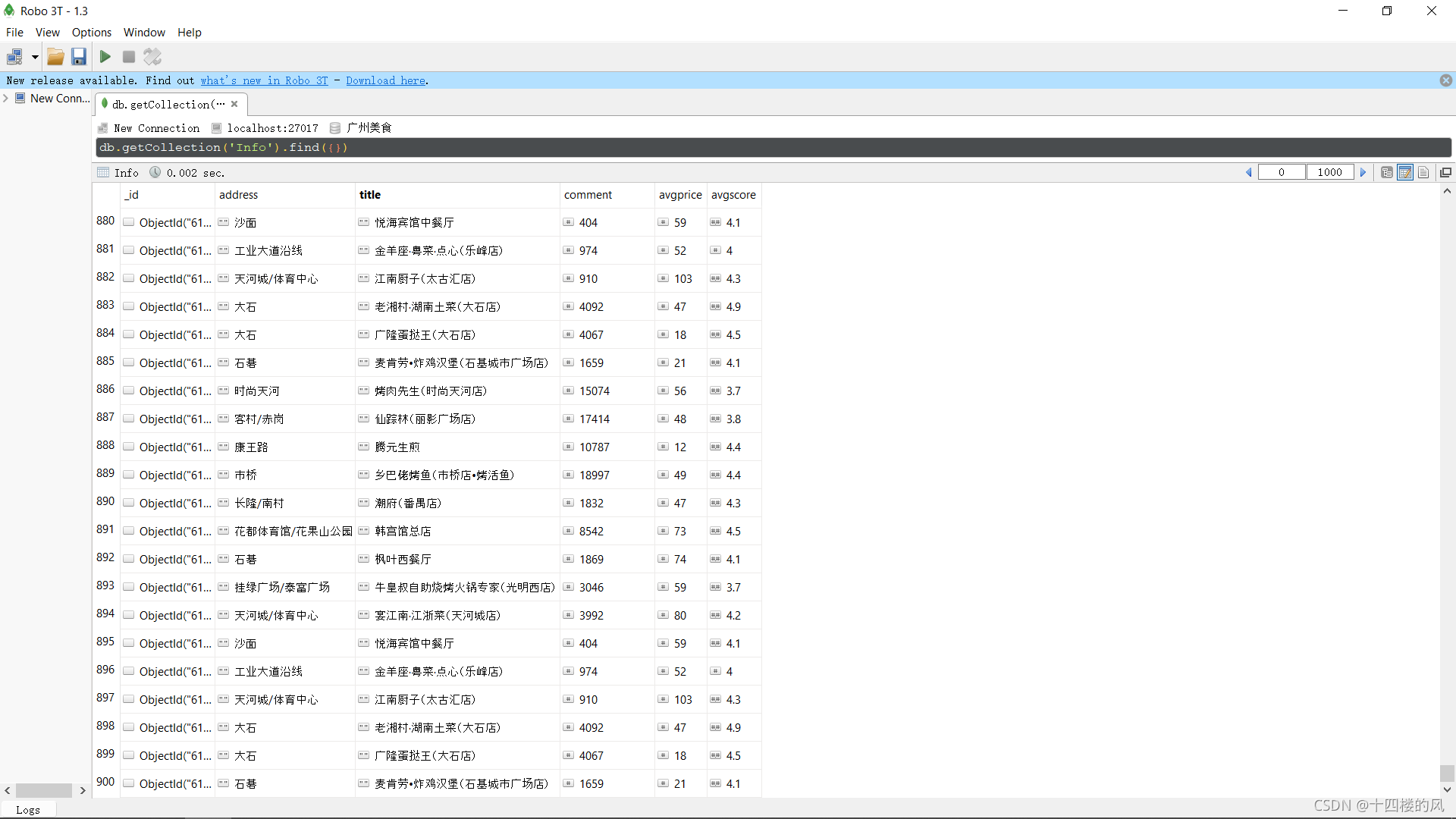 小编的数据库中,包含了900条关于广州美食的一些基本信息,希望下次小编可以对这些基本信息做个数据分析吧。
小编的数据库中,包含了900条关于广州美食的一些基本信息,希望下次小编可以对这些基本信息做个数据分析吧。
六、感慨万分
来广州吧,满足你对青年时期最好的回忆。














 1397
1397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









