







强化学习环境-gym-gym wrappers
Gym Wrappers
The extremely powerful feature of wrappers made available to us courtesy of OpenAI’s gym
作用
- add functionality to environments, such as modifying observations and rewards to be fed to our agent.
- preprocess observations in order to make them more easy to learn from:image输入
用法
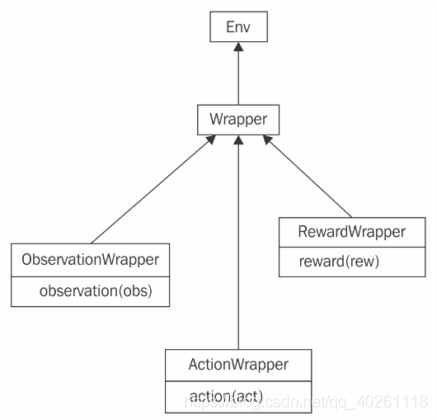
- The
gym.Wrapperclass inherits from thegym.Envclass, - Implementing the
gym.Wrapperclass requires defining an__init__method that accepts the environment to be extended as a parameter - 样例:
class BasicWrapper(gym.Wrapper):
def __init__(self, env):
super().__init__(env)
self.env = env
def step(self, action):
next_state, reward, done, info = self.env.step(action)
# modify ...
return next_state, reward, done, info
env = BasicWrapper(gym.make("CartPole-v0"))
可以利用这个结构,对原生环境得到的observation,action,reward进行修改
细节
gym.observationWrapper:Used to modify the observations returned by the environment:
class ObservationWrapper(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
def observation(self, obs):
# modify obs
return obs
gym.RewardWrapper:Used to modify the rewards returned by the environment.
class RewardWrapper(gym.RewardWrapper):
def __init__(self, env):
super().__init__(env)
def reward(self, rew):
# modify rew
return rew
gym.ActionWrapper:Used to modify the actions passed to the environment.
class ActionWrapper(gym.ActionWrapper):
def __init__(self, env):
super().__init__(env)
def action(self, act):
# modify act
return act
使用方法:
- ObservationWrapper:
例:gym.Discrete: generates a new environment with a one-hot encoding of the discrete states, for use in, for example, neural networks.
class DiscreteToBoxWrapper(gym.ObservationWrapper):
def __init__(self, env):
super().__init__(env)
assert isinstance(env.observation_space, gym.spaces.Discrete), \
"Should only be used to wrap Discrete envs."
self.n = self.observation_space.n
self.observation_space = gym.spaces.Box(0, 1, (self.n,))
def observation(self, obs):
new_obs = np.zeros(self.n)
new_obs[obs] = 1
return new_obs
env = DiscreteToBoxWrapper(gym.make("FrozenLake-v0"))
T = 10
s_t = env.reset()
for t in range(T):
a_t = env.action_space.sample()
s_t, r_t, done, info = env.step(a_t)
print(s_t)
if done:
s_t = env.reset()
上述输出:
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
- ActionWrapper:
import gym
from typing import TypeVar
import random
Action = TypeVar('Action')
class RandomActionWrapper(gym.ActionWrapper):
def __init__(self, env, epsilon=0.1):
super(RandomActionWrapper, self).__init__(env)
self.epsilon = epsilon
def action(self, action):
if random.random() < self.epsilon:
print("Random!")
return self.env.action_space.sample()
return action
if __name__ == "__main__":
env = RandomActionWrapper(gym.make("CartPole-v0"))
obs = env.reset()
total_reward = 0.0
while True:
obs, reward, done, _ = env.step(0)
total_reward += reward
if done:
break
print("Reward got: %.2f" % total_reward)
# 上述输出
rl_book_samples/ch02$ python 03_random_actionwrapper.py
WARN: gym.spaces.Box autodetected dtype as <class
'numpy.float32'>. Please provide explicit dtype.
Random!
Random!
Random!
Random!
Reward got: 12.00
Beyond Wrapper Class
add functionality to the environment, such as providing auxillary observation functions that allow for multiple preprocessing streams to occur.
构造更多功能的类,实现更多功能
问题:
In more complex applications of deep reinforcement learning, evaluating the policy can take significantly longer than stepping the environment. This means that the majority of computational time is spent choosing actions, which makes data collection slow.
Since deep reinforcement learning is extremely data intensive (often requiring millions of timesteps of experience to achieve good performance), we should prioritize rapidly acquiring data.
为了更快采集数据,复制n个环境,形成一个环境向量:
class VectorizedEnvWrapper(gym.Wrapper):
def __init__(self, make_env, num_envs=1):
super().__init__(make_env())
self.num_envs = num_envs
self.envs = [make_env() for env_index in range(num_envs)]
def reset(self):
return np.asarray([env.reset() for env in self.envs])
def reset_at(self, env_index):
return self.envs[env_index].reset()
def step(self, actions):
next_states, rewards, dones, infos = [], [], [], []
for env, action in zip(self.envs, actions):
next_state, reward, done, info = env.step(action)
next_states.append(next_state)
rewards.append(reward)
dones.append(done)
infos.append(info)
return np.asarray(next_states), np.asarray(rewards), \
np.asarray(dones), np.asarray(infos)
num_envs = 128
env = VectorizedEnvWrapper(lambda: gym.make("CartPole-v0"), num_envs=num_envs)
T = 10
observations = env.reset()
for t in range(T):
actions = np.random.randint(env.action_space.n, size=num_envs)
observations, rewards, dones, infos = env.step(actions)
for i in range(len(dones)):
if dones[i]:
observations[i] = env.reset_at(i)
print(observations.shape)
print(rewards.shape)
print(dones.shape)
# 结果
(128, 4)
(128,)
(128,)
参考:
https://hub.packtpub.com/openai-gym-environments-wrappers-and-monitors-tutorial/
https://alexandervandekleut.github.io/gym-wrappers/
Monitor the agent
if __name__ == "__main__":
env = gym.make("CartPole-v0")
env = gym.wrappers.Monitor(env, "recording")
-
输入的第二项:
name of directory it will write the results to;shouldn’t exist 否则会出现异常:删掉当前已存在目录,或者force=True 传入monitor -
Monitor class需要FFmpeg(系统中的环境):将observation转换为video file
-
三个需要:
- The code should be run in an X11 session with the OpenGL extension (GLX)
- The code should be started in an Xvfb virtual display
- You can use X11 forwarding in ssh connection
-
video recording:
通过对屏幕截图生成;有些环境通过openGL得到画面,在云服务器会有问题,如果没有屏幕或者图形界面,解决:virtual graphical display 叫做Xvfb(install package xvfb),在服务器上开一个虚拟display
另一种解决方法是用 X11 server, 还可以通过ssh 让云服务器画面在本地显示
参考:
https://hub.packtpub.com/openai-gym-environments-wrappers-and-monitors-tutorial/

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









