






2410 青训营 简单/创意标题匹配-含正确答案+编题测试类错误纠正
文章目录
问题描述
# 问题描述
在广告平台中,为了给广告主一定的自由性和效率,允许广告主在创造标题的时候以通配符的方式进行创意提交。线上服务的时候,会根据用户的搜索词触发的 bidword 对创意中的通配符(通配符是用成对 {} 括起来的字符串,可以包含 0 个或者多个字符)进行替换 ,用来提升广告投放体验。例如:“{末日血战} 上线送 SSR 英雄,三天集齐无敌阵容!”,会被替换成“帝国时代游戏下载上线送 SSR 英雄,三天集齐无敌阵容!”。给定一个含有通配符的创意和一句标题,判断这句标题是否从该创意替换生成的。
## 输入格式
第一行输入为 N,代表有 N 个标题
第二行代表含有通配符的创意,创意中包含大小写英文字母和成对的花括号
第三行到第 N + 2 行,代表 N 句标题,每个标题只包含大小写英文字母
## 输出格式
N 行,每行为“True”或者“False”,判断该句标题是否符合创意
**输入样例**
4
ad{xyz}cdc{y}f{x}e
adcdcefdfeffe
adcdcefdfeff
dcdcefdfeffe
adcdcfe
**输出样例**
True
False
False
True
**说明**
adcdcefdfeffe 可以看作 ad{}cdc{efd}f{eff}e 或者 ad{}cdc{efdfe}f{f}e 替换生成,但是无论哪种替换方式都是符合该创意 ad{xyz}cdc{y}f{x}e。
**数据范围**
N <= 10
标题和创意的长度小于等于 100
示例
def solution(n, template, titles):
# Please write your code here
return -2
if __name__ == "__main__":
# You can add more test cases here
testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
testTitles3 = ["abcdefg", "abefg", "efg"]
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,Fales,True" )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,Fales,False,Fales,True" )
print(solution(3, "a{bdc}efg", testTitles3) == "True,Trur,Fales" )
个人思路
思路:
正则匹配在python能用
看懂题目方法:结合测试类可懂每个参数和结果是啥样。
方向一:顺序匹配,且删掉【开始-匹配位】所有内容,持续匹配。可空白匹配,全部匹配后可为True。
①如何判断匹配:遍历
②开头、结尾如何完全匹配:去除这一位,【首位】去掉之后内容,是否长度为1。【末尾】,提取此为到末尾,是否长度为
解题方向:递归-截取字符串/迭代-索引
错误例子集合
1-(递归)此例子确实部分处理 a recursive approach 递归
def match_template(template, title):
print("template="+template)
print("title="+title)
if not template and not title:
return True
if not template or not title:
return False
if template[0] == '{':
end = template.index('}')
# print("end="+end)
for i in range(len(title) + 1):
print("template[end+1:]="+template[end+1:])
print("title[i:]="+title[i:])
if match_template(template[end+1:], title[i:]):
return True
return False
if template[0] != title[0]:
return False
return match_template(template[1:], title[1:])
def solution(n, template, titles):
results = []
for title in titles:
results.append(str(match_template(template, title)))
return ",".join(results)
if __name__ == "__main__":
# You can add more test cases here
testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
testTitles3 = ["abcdefg", "abefg", "efg"]
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,Fales,True" )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,Fales,False,Fales,True" )
print(solution(3, "a{bdc}efg", testTitles3) == "True,Trur,Fales" )
难点:模版:{x}e title:effe
难点:测试1的第一个和第二个经常重复出现问题
在于未完全匹配最后一位:你只匹配到了第一个e,而没有视第一个e为通配符内容
例子:
effe
{x}e
正确答案
def match_template(template, title):
if not template and not title:
return True
if not template:
return all(c == '{' or c == '}' for c in title)
if not title:
return all(c == '{' or c == '}' for c in template)
if template[0] == '{':
end = template.index('}')
for i in range(len(title) + 1):
if match_template(template[end + 1:], title[i:]):
return True
return False
if template[0] != title[0]:
return False
return match_template(template[1:], title[1:])
def solution(n, template, titles):
results = []
for title in titles:
results.append("True" if match_template(template, title) else "False")
return ",".join(results)
# if __name__ == "__main__":
# # testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
# testTitles11 = ["adcdcefdfeffe"]
# testTitles12 = ["adcdcefdfeff"]
# testTitles13 = ["dcdcefdfeffe"]
# testTitles14 = ["adcdcfe"]
# testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
# testTitles3 = ["abcdefg", "abefg", "efg"]
if __name__ == "__main__":
# You can add more test cases here
testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
testTitles3 = ["abcdefg", "abefg", "efg"]
testTitles11 = ["adcdcefdfeffe"]
testTitles12 = ["adcdcefdfeff"]
testTitles13 = ["dcdcefdfeffe"]
testTitles14 = ["adcdcfe"]
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) )
print(solution(3, "a{bdc}efg", testTitles3) )
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,False,True" )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,False,False,False,True" )
print(solution(3, "a{bdc}efg", testTitles3) == "True,True,False" )
# print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles11) == "True")
# print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles12) == "False")
# print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles13) == "False")
# print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles14) == "True")
# print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,False,False,False,True")
# print(solution(3, "a{bdc}efg", testTitles3) == "True,True,False")
# print(solution(1, "ad{xyz}cdc{y}f{x}e", ["adcdcefdfeffe"]) == "True")
# print(solution(1, "{x}e", ["dfeffe"]) == "True")
# print(solution(1, "{x}e", ["dfeff"]) == "False")
编题测试类错误~False 写成了 Fales,把True写成Trur
错误
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,Fales,True" )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,Fales,False,Fales,True" )
print(solution(3, "a{bdc}efg", testTitles3) == "True,Trur,Fales" )
正确
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,False,True" )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,False,False,False,True" )
print(solution(3, "a{bdc}efg", testTitles3) == "True,Trur,False" )
题解一:错误 空值模版匹配title
实际未报错:走了另一条途径
出错:中间递归
例子:
template=ad{xyz}cdc{y}f{x}e
title=adcdcefdfeffe
f匹配错误位置:
template=
title=ffe
def match_template(template, title):
print("template="+template)
print("title="+title)
if not template and not title:
return True
if not template or not title:
return False
if template[0] == '{':
end = template.index('}')
# print("end="+end)
for i in range(len(title) + 1):
print("template[end+1:]="+template[end+1:])
print("title[i:]="+title[i:])
if match_template(template[end+1:], title[i:]):
return True
return False
if template[0] != title[0]:
return False
return match_template(template[1:], title[1:])
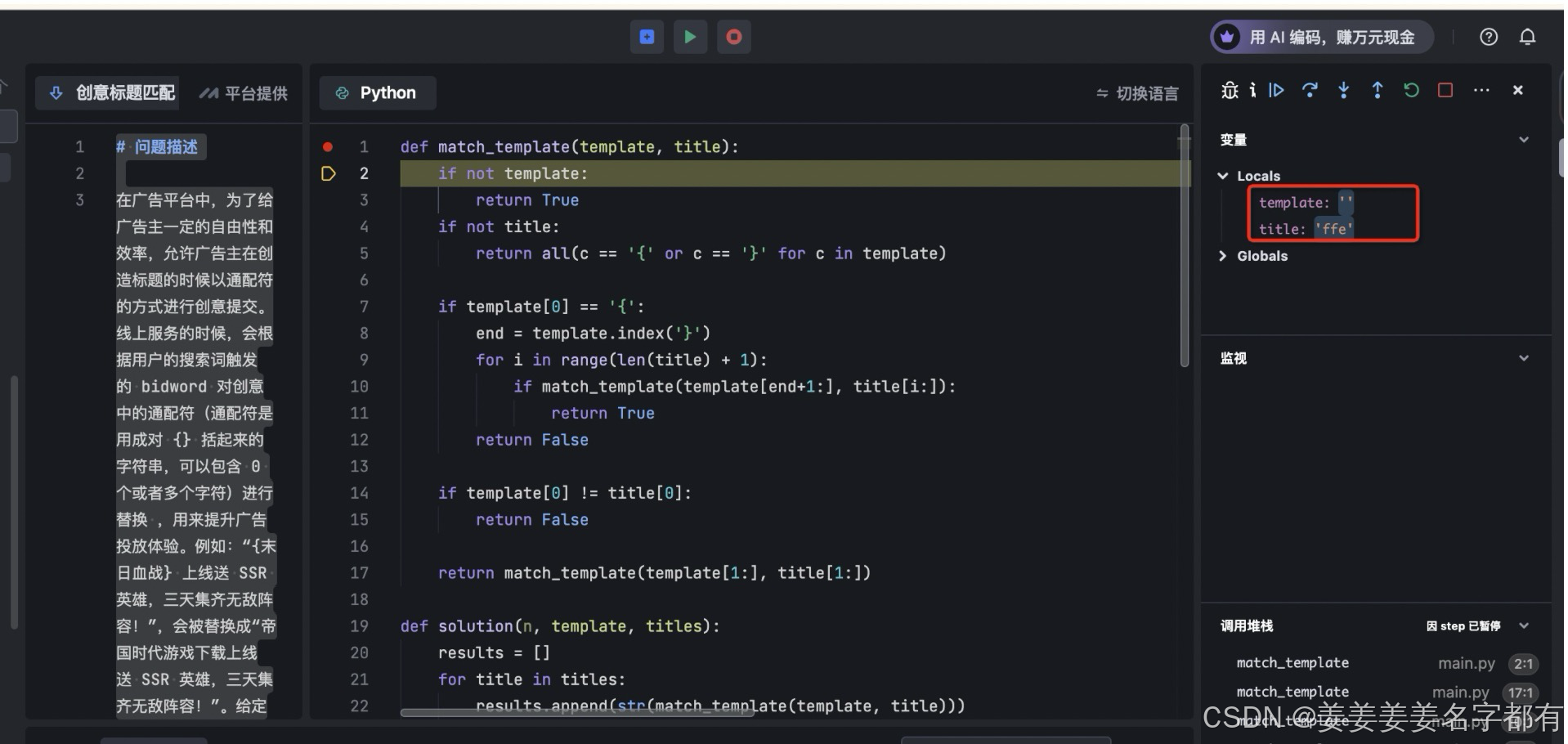
题解二 error 递归 如果尾巴的e在中间被匹配,没有匹配最后的e,就会报错
def match_template(template, title):
if not template:
return True
if not title:
return all(c == '{' or c == '}' for c in template)
if template[0] == '{':
end = template.index('}')
for i in range(len(title) + 1):
if match_template(template[end+1:], title[i:]):
return True
return False
if template[0] != title[0]:
return False
return match_template(template[1:], title[1:])
def solution(n, template, titles):
results = []
for title in titles:
results.append(str(match_template(template, title)))
return ",".join(results)
if __name__ == "__main__":
# You can add more test cases here
testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
testTitles3 = ["abcdefg", "abefg", "efg"]
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,Fales,True" )
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,Fales,False,Fales,True" )
print(solution(3, "a{bdc}efg", testTitles3) == "True,Trur,Fales" )
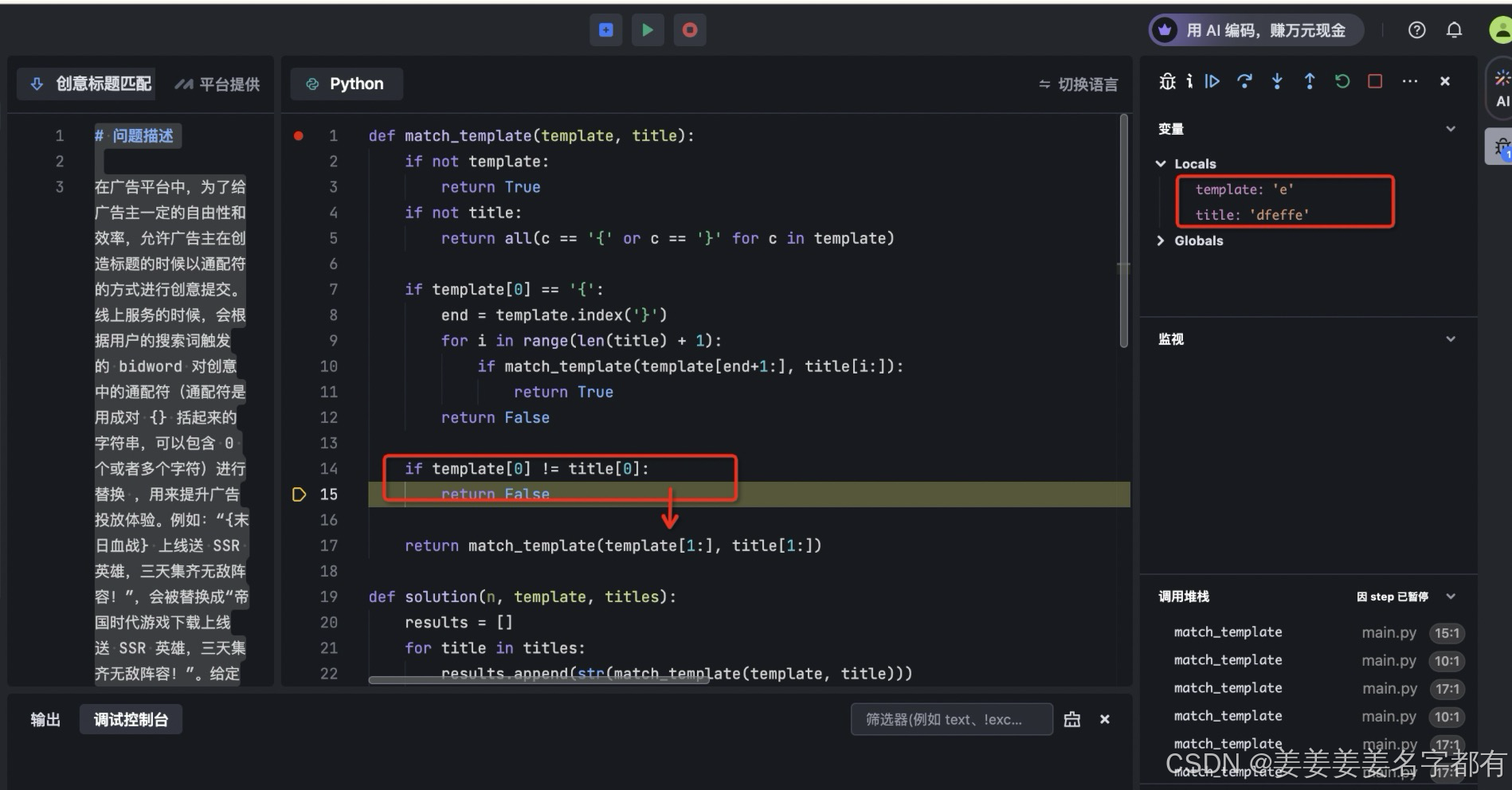
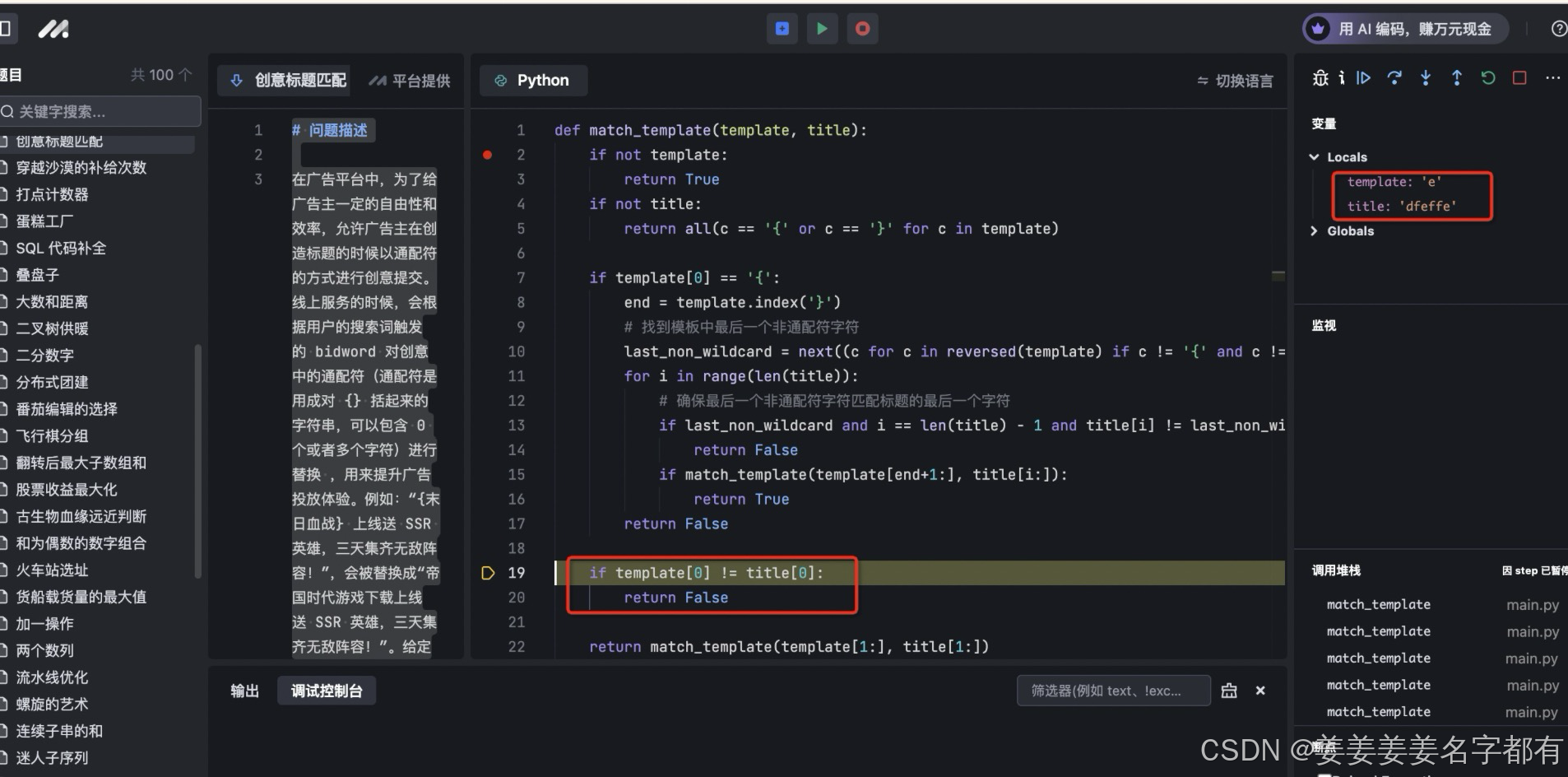
案例三 :迭代 error test1-例子2错误
def match_template(template, title):
if not template:
return True
if not title:
return all(c == '{' or c == '}' for c in template)
if template[0] == '{':
end = template.index('}')
# 找到模板中最后一个非通配符字符
last_non_wildcard = next((c for c in reversed(template) if c != '{' and c != '}'), None)
for i in range(len(title)):
# 确保最后一个非通配符字符匹配标题的最后一个字符
if last_non_wildcard and i == len(title) - 1 and title[i] != last_non_wildcard:
return False
if match_template(template[end+1:], title[i:]):
return True
return False
if template[0] != title[0]:
return False
return match_template(template[1:], title[1:])
def solution(n, template, titles):
results = []
for title in titles:
results.append(str(match_template(template, title)))
return ",".join(results)
if __name__ == "__main__":
testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
testTitles3 = ["abcdefg", "abefg", "efg"]
print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,False,True")
print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,False,False,False,True")
print(solution(3, "a{bdc}efg", testTitles3) == "True,True,False")
print(solution(1, "ad{xyz}cdc{y}f{x}e", ["adcdcefdfeffe"]) == "True")
print(solution(1, "{x}e", ["dfeffe"]) == "True")
print(solution(1, "{x}e", ["dfeff"]) == "False")
案例四:error 问题 test1的第二个字符串依旧无法匹配
def match_template(template, title):
# print(f"\n开始匹配模板 '{template}' 和标题 '{title}'")
t_index = 0 # 模板索引
s_index = 0 # 标题索引
while t_index < len(template) and s_index < len(title):
# print(f"当前位置:模板索引 = {t_index}, 标题索引 = {s_index}")
# print(f"当前字符:模板 = '{template[t_index]}', 标题 = '{title[s_index]}'")
if template[t_index] == '{':
# 找到通配符的结束位置
end = template.index('}', t_index)
# print(f"发现通配符,结束位置:{end}")
# 找到下一个非通配符字符(如果有的话)
next_char = None
next_char_index = end + 1
while next_char_index < len(template):
if template[next_char_index] not in '{}':
next_char = template[next_char_index]
break
next_char_index += 1
# print(f"下一个非通配符字符:{next_char if next_char else '无'}")
# 如果没有下一个字符,检查模板是否结束
if next_char is None:
# print("模板结束,检查标题剩余部分")
return check_title_suffix(template[t_index:], title[s_index:])
# 查找下一个字符在标题中的位置
next_pos = title.find(next_char, s_index)
# print(f"在标题中查找字符 '{next_char}',位置:{next_pos}")
if next_pos == -1:
# print("未找到匹配,返回 False")
return False
# 更新索引
s_index = next_pos
t_index = end + 1
# print(f"更新索引:模板索引 = {t_index}, 标题索引 = {s_index}")
elif template[t_index] != title[s_index]:
# print("字符不匹配,返回 False")
return False
else:
# print("字符匹配,移动到下一个")
t_index += 1
s_index += 1
# 检查是否完全匹配
result = check_title_suffix(template[t_index:], title[s_index:])
# print(f"匹配结束。模板索引 = {t_index}/{len(template)}, 标题索引 = {s_index}/{len(title)}")
# print(f"匹配结果:{'成功' if result else '失败'}")
return result
def check_title_suffix(remaining_template, remaining_title):
# print(f"检查剩余部分:模板 = '{remaining_template}', 标题 = '{remaining_title}'")
# 移除模板中的所有通配符
clean_template = ''.join(c for c in remaining_template if c not in '{}')
if not clean_template:
# print("模板剩余部分全为通配符,匹配成功")
return True
if remaining_title.endswith(clean_template):
# print(f"标题以 '{clean_template}' 结尾,匹配成功")
return True
# print(f"标题不以 '{clean_template}' 结尾,匹配失败")
return False
def solution(n, template, titles):
results = []
for i, title in enumerate(titles):
# print(f"\n===== 测试用例 {i+1} =====")
results.append(str(match_template(template, title)))
return ",".join(results)
# if __name__ == "__main__":
# # testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
# testTitles11 = ["adcdcefdfeffe"]
# testTitles12 = ["adcdcefdfeff"]
# testTitles13 = ["dcdcefdfeffe"]
# testTitles14 = ["adcdcfe"]
# testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
# testTitles3 = ["abcdefg", "abefg", "efg"]
if __name__ == "__main__":
# You can add more test cases here
testTitles1 = ["adcdcefdfeffe", "adcdcefdfeff", "dcdcefdfeffe", "adcdcfe"]
testTitles2 = ["CLSomGhcQNvFuzENTAMLCqxBdj", "CLSomNvFuXTASzENTAMLCqxBdj", "CLSomFuXTASzExBdj", "CLSoQNvFuMLCqxBdj", "SovFuXTASzENTAMLCq", "mGhcQNvFuXTASzENTAMLCqx"]
testTitles3 = ["abcdefg", "abefg", "efg"]
testTitles11 = ["adcdcefdfeffe"]
testTitles12 = ["adcdcefdfeff"]
testTitles13 = ["dcdcefdfeffe"]
testTitles14 = ["adcdcfe"]
# print(solution(4, "ad{xyz}cdc{y}f{x}e", testTitles1) == "True,False,Fales,True" )
# print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,Fales,False,Fales,True" )
# print(solution(3, "a{bdc}efg", testTitles3) == "True,Trur,Fales" )
print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles11) == "True")
print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles12) == "False")
print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles13) == "False")
print(solution(1, "ad{xyz}cdc{y}f{x}e", testTitles14) == "True")
# print(solution(6, "{xxx}h{cQ}N{vF}u{XTA}S{NTA}MLCq{yyy}", testTitles2) == "False,False,False,False,False,True")
# print(solution(3, "a{bdc}efg", testTitles3) == "True,True,False")
# print(solution(1, "ad{xyz}cdc{y}f{x}e", ["adcdcefdfeffe"]) == "True")
# print(solution(1, "{x}e", ["dfeffe"]) == "True")
# print(solution(1, "{x}e", ["dfeff"]) == "False")
True
False
True
True


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









