







简介
之前的几篇文章都有使用过链表来实现一些数据结构,诸如C语言链表实现队列,C语言链表实现堆栈等,本篇文章就简单介绍一下如何用C语言实现一个简单的单向链表结构,以及一些链表的操作。比起数组来存储数据,链表对删除元素添加元素这些操作更加的灵活。实际上就是把物理上不相邻的内存空间通过“链”的方式链接起来,成为逻辑上相邻的内存空间。
链表操作
- 初始化链表:初始化一个链表。
- 插入结点:在链表的特定位置(头、尾、或者中间某个位置)插入一个新的结点。
- 删除结点:删除链表中特定的结点。
- 查找结点:按照特定的条件在链表中查找节点。本篇文章将通过查找第一次出现数据和通过索引的方式查找特定的结点。
- 反转链表:改变链表指针的指向。
- 获取链表长度:计算链表中结点的个数。
- 遍历链表:按照顺序访问链表中的每个结点并对其进行操作,我这里就是打印一下链表的data。
- 清空链表:释放链表结点的内存空间。
链表结点
由于是单向链表,所以一般就包含两个变量,一个存储数据的变量,一个指向下一个结点的指针变量。
具体代码示例如下:
// 定义链表结点指针类型
typedef struct StackNode *PStackNode;
// 定义链表结点类型
typedef struct StackNode {
int data;
PStackNode next;
} SNode;
链表结构
// 定义链表的结构,以及别名和指针别名
// 结构中有三个变量
// 链表头部head、链表尾部tail、以及索引index
typedef struct {
PStackNode head;
PStackNode tail;
int index;
} LList, *LListPtr;
链表初始化
// 初始化时是一个空的链表所以头尾都是NULL指针
// index从-1开始方便后续查找之类的函数实现
void initLinkedList(LListPtr lListPtr) {
lListPtr->head = NULL;
lListPtr->tail = NULL;
lListPtr->index = -1;
}
首先看看插入操作,对于空链表插入第一个元素的时候需要做个特殊判断,因为插入结束之后头尾指针指向
同一个结点。所以代码可以这么写:
PStackNode p = (PStackNode) malloc(sizeof(SNode));
if (p) {
p->data = item;
if (!lListPtr->tail) {
// 头尾指针同时指向第一个节点
lListPtr->tail = p;
lListPtr->head = p;
// 第一个节点的next是NULL
p->next = NULL;
}
// 加入结点索引加1
lListPtr->index++;
}
处理完空链表添加第一个节点之后的操作,就需要再做两个特殊的操作一个是往链表头部前面添加节点,也
就是让原本的头部结点变成链表中第二个节点。新结点next指向没插入前的头结点,插入结束后新节点就要变成
新的头结点,所以代码可以这么写:
// 其中p是新结点的指针
p->next = lListPtr->head;
lListPtr->head = p;
还有一个操作就是往链表尾部添加新结点,这个也就比较简单了。只要将tail->next指向新的结点,然后
新结点变成链表的尾部结点并将新节点的next指针指向NULL,所以代码可以这么写:
lListPtr->tail->next = p;
lListPtr->tail = p;
p->next = NULL;
最后就是从链表中间插入新结点了,这个操作我们只需要知道当前被插入的节点,将新节点的next指针指向
当前被插入结点的next所指的结点,然后将被插入结点的next指针指向新的结点,由于我们链表只知道头尾两
个指针,所以需要做遍历操作,比如我这里是通过传入一个index索引值来查找对应需要插入的结点位置是在哪
里。
具体代码示例如下:
int count = 0;
PStackNode current = lListPtr->head;
while (count < index) {
current = current->next;
count++;
}
// 跳出循环,说明此时的current指针指向的就是我们要插入的结点
p->next = current->next;
current->next = p;
我这里写了三个函数其中两个是特殊情况,从插入结点、插入尾结点,剩下一个是根据index插入对应的结
点位置。具体代码如下:
// 先从链表结尾插入结点
void addNodeOnTail(LListPtr lListPtr, int item) {
addNodeByIndex(lListPtr, lListPtr->index, item);
}
// 往链表头部前面插入结点
void addNodeOnHead(LListPtr lListPtr, int item) {
addNodeByIndex(lListPtr, -1, item);
}
// 根据索引插入结点
// 首先判断索引是否合法,规定传入的index意思就是从该index往后插入一个节点
// 此时有个特殊的插入方式就是往头结点前面插入元素,此时可以传入index为-1
// 所以需要特殊判断,还有防止传入的index超过结点的最大索引
// 或者如果插入的结点超过最大索引就认为是插入到尾部结点后面
// 规范点还是限定插入结点的索引好了,即特殊索引就-1一个
// 如果插入结点索引不合法则不插入
// 一开始链表为空的时候需要考虑
void addNodeByIndex(LListPtr lListPtr, int index, int item) {
// 判断插入结点索引合法性
if (index < -1 || index > lListPtr->index) {
printf("待插入结点索引不合法,结点插入失败!!!\n");
} else {
PStackNode p = (PStackNode) malloc(sizeof(SNode));
if (p) {
p->data = item;
// 开始为空链表的情况
if (!lListPtr->tail) {
lListPtr->tail = p;
lListPtr->head = p;
p->next = NULL;
} else {
// 处理往头前面以及尾部后面插入结点的特殊情况
if (index == -1) {
p->next = lListPtr->head;
lListPtr->head = p;
} else if (index == lListPtr->index) {
lListPtr->tail->next = p;
lListPtr->tail = p;
// 尾部插入的时候需要添加
// 之前忘了,发现无限循环
// 打印链表
p->next = NULL;
} else {
int count = 0;
PStackNode current = lListPtr->head;
while (count < index) {
current = current->next;
count++;
}
p->next = current->next;
current->next = p;
}
}
lListPtr->index++;
// 调试用
// printf("this index: %d\n", lListPtr->index);
} else {
printf("无法申请到内存空间!!!\n");
}
}
}
其实上面这个写法不算好,应该把最后面的函数插入尾部和插入头部的逻辑写在上面两个函数中,再判断如果是特殊的插入尾部或插入头部那么就调用对应的函数,而不是像我这样把它们逻辑写在一起看起来整个函数很复杂。所以后面删除结点的操作我就把各个函数的职责给分离了。
删除操作
和上面的插入的逻辑差不多,不同的是删除是找到对应的位置然后free所申请的内存空间,而插入是找到对应位置然后加入一个新的结点。查找结点的过程就不多赘述可,上面的插入操作也有查找的过程。这里就讲讲几种删除的方式。
删除头部
由于链表知道头指针所以删除头部其实是很方便的,不需要遍历去找待删除结点。具体操作就是将临时指针
变量先存储一下需要被删除的头部指针,然后头指针指向第二个结点head = head->next。此时需要做一个判断
如果当前链表只有一个结点的话如果删除了头结点也就是链表将要变成空链表的时候需要对尾部指针也做一个赋
值NULL的操作,具体代码如下所示:
// 删除结点好像只有删除头结点需要特殊操作
void deleteNodeOnHead(LListPtr lListPtr) {
if (lListPtr->head) {
PStackNode p = lListPtr->head;
lListPtr->head = lListPtr->head->next;
if (NULL == lListPtr->head) {
lListPtr->tail = NULL;
}
free(p);
lListPtr->index--;
}
}
删除其他位置
除了删除头部节点是特殊的操作,其他的删除操作都可以通过下面的函数执行删除。
void deleteNodeByIndex(LListPtr lListPtr, int index) {
// 删除头结点
if (index == 0) {
deleteNodeOnHead(lListPtr);
// 这里的判断条件可以保证传入的不是空链表
// 比如此时如果传入一个空链表那么lListPtr->index此时为-1
// 不管传入的index是什么值,条件都进不去
// 只有链表不为空的时候才能进入条件
} else if (index <= lListPtr->index && index > 0) {
// 删除index对应索引的下标
// 执行删除操作需要两个指针一个为待删除结点
// 一个为指向待删除结点的前一个节点
// 所以这里用两个变量current、perv来表示
PStackNode current = lListPtr->head;
PStackNode perv = NULL;
int count = 0;
while (count < index) {
perv = current;
current = current->next;
count++;
}
// 前一个节点指向当前要删除结点的后面
perv->next = current->next;
free(current);
lListPtr->index--;
} else {
printf("需要删除的结点不存在\n");
}
}
同时还提供了一个编辑删除尾部的操作
// 提供一个便捷删除尾部结点的操作
void deleteNodeOnTail(LListPtr lListPtr) {
// 输入当前链表的最大索引值,删除尾部结点
deleteNodeByIndex(lListPtr, lListPtr->index);
}
查找结点
我这里通过索引值和数据值两个方式来获取结点的指针,具体操作因为比较好理解所以直接贴代码了
// 返回第一个数据值匹配结点指针,没找到时返回NULL
PStackNode getNodeByData(LListPtr lListPtr, int data) {
PStackNode ret = NULL;
for (PStackNode p = lListPtr->head; p; p = p->next) {
if (p->data == data) {
ret = p;
break;
}
}
return ret;
}
// 返回索引所对应的结点指针,没找到时返回NULL
PStackNode getNodeByIndex(LListPtr lListPtr, int index) {
PStackNode ret = NULL;
// 输入的索引在对应链表的范围内才能返回对应的指针
if (0 < index && index < lListPtr->index) {
int count = 0;
PStackNode p = lListPtr->head;
// 如果进入循环
// 那么count == index 时条件退出
// 此时p就是我们要找的结点指针
while (count < index) {
p = p->next;
count++;
}
ret = p;
} else if (0 == index) {
ret = lListPtr->head;
} else if (lListPtr->index == index) {
ret = lListPtr->tail;
}
return ret;
}
获取链表长度
因为我们一开始就用了index索引值来表示链表此时最大的索引,由于index从0开始每次插入结点时加1,删除结
点时减1,所以获取长度代码如下:
int getLinkedListLength(LListPtr lListPtr) {
return lListPtr->index + 1;
}
反转链表
意思就是将链表头变成尾部,尾部变成头部,其他位置的指针指向都变成反方向,比如结点A开始指向结点B,反
转之后节点B指向结点A这样。
// 反转链表操作
void reverseLinkedList(LListPtr lListPtr) {
// 需要三个指针
// 前一个结点、当前结点、下一个结点
// prev、current、next
PStackNode prev = NULL;
PStackNode current = lListPtr->head;
PStackNode next = NULL;
// 遍历链表
while (current) {
// 下一个结点时当前结点的next很好理解吧
next = current->next;
// 由于需要反转此时当前的结点就要指向它前面一个节点
// A->B 变成 A<-B这样
current->next = prev;
// 处理完上面之后下一次循环的前一个结点就是当前结点
// 所以
prev = current;
// 当前结点向后移动
current = next;
}
// 如果如果循环执行了,那么结束之后prev指向链表的反转之后的头部
// 原来的链表尾部变成头部结点
lListPtr->tail = lListPtr->head;
lListPtr->head = prev;
}
遍历链表
这个操作也很好理解,从头指向尾,所以需要一个临时指针保存一下头结点的位置,具体代码如下所示:
for (PStackNode p = lListPtr->head; p; p = p->next) {
// do something
// 我这里只是打印了结点的值
printf("%d ", p->data);
}
// 用while来写就是
PStackNode p = lListPtr->head
while(p)
{
// do something
p = p->next;
}
清空链表
由于链表的结点都是malloc动态申请到的内存空间,所以不需要使用的时候需要清空一下链表,其实和遍历操作
很像,具体代码如下:
void clearLinkedList(LListPtr lListPtr) {
for (PStackNode p = lListPtr->head, q = NULL; p; p = q) {
// 只不过每次free操作之后p指向什么都不知道了
// 所以需要提前保存一下当前p结点的下一个结点
// 这里用q来保存
// 每次循环结束之后p=q
q = p->next;
free(p);
}
// 清空一下链表的几个数据
// 防止二次调用该函数出现不安全的内存访问
initLinkedList(lListPtr);
}
完整代码
完整代码我也会贴出来,提供给有需要的同学作参考。
头文件single_linked_list.h
#ifndef C_SINGLE_LINKED_LIST_H
#define C_SINGLE_LINKED_LIST_H
#include "linked_list_stack.h"
typedef struct {
PStackNode head;
PStackNode tail;
int index;
} LList, *LListPtr;
void initLinkedList(LListPtr lListPtr);
int getLinkedListLength(LListPtr lListPtr);
void addNodeOnTail(LListPtr lListPtr, int item);
void addNodeOnHead(LListPtr lListPtr, int item);
void addNodeByIndex(LListPtr lListPtr, int index, int item);
PStackNode getNodeByData(LListPtr lListPtr, int data);
PStackNode getNodeByIndex(LListPtr lListPtr, int index);
void deleteNodeOnHead(LListPtr lListPtr);
void deleteNodeByIndex(LListPtr lListPtr, int index);
void deleteNodeOnTail(LListPtr lListPtr);
void printLinkedList(LListPtr lListPtr);
void reverseLinkedList(LListPtr lListPtr);
void clearLinkedList(LListPtr lListPtr);
void linkedListTest(void);
#endif //C_SINGLE_LINKED_LIST_H
代码文件single_linked_list.c
#include "single_linked_list.h"
#include <stdlib.h>
#include <stdio.h>
//typedef struct {
// PStackNode head;
// PStackNode tail;
//} LList, *LListPtr;
void initLinkedList(LListPtr lListPtr) {
lListPtr->head = NULL;
lListPtr->tail = NULL;
lListPtr->index = -1;
}
int getLinkedListLength(LListPtr lListPtr) {
return lListPtr->index + 1;
}
// 先从链表结尾插入结点
void addNodeOnTail(LListPtr lListPtr, int item) {
addNodeByIndex(lListPtr, lListPtr->index, item);
}
// 往链表头部前面插入结点
void addNodeOnHead(LListPtr lListPtr, int item) {
addNodeByIndex(lListPtr, -1, item);
}
// 根据索引插入结点
// 首先判断索引是否合法,规定传入的index意思就是从该index往后插入一个节点
// 此时有个特殊的插入方式就是往头结点前面插入元素,此时可以传入index为-1
// 所以需要特殊判断,还有防止传入的index超过结点的最大索引
// 或者如果插入的结点超过最大索引就认为是插入到尾部结点后面
// 规范点还是限定插入结点的索引好了,即特殊索引就-1一个
// 如果插入结点索引不合法则不插入
// 一开始链表为空的时候需要考虑
void addNodeByIndex(LListPtr lListPtr, int index, int item) {
// 判断插入结点索引合法性
if (index < -1 || index > lListPtr->index) {
printf("待插入结点索引不合法,结点插入失败!!!\n");
} else {
PStackNode p = (PStackNode) malloc(sizeof(SNode));
if (p) {
p->data = item;
// 开始为空链表的情况
if (!lListPtr->tail) {
lListPtr->tail = p;
lListPtr->head = p;
p->next = NULL;
} else {
// 处理往头前面以及尾部后面插入结点的特殊情况
if (index == -1) {
p->next = lListPtr->head;
lListPtr->head = p;
} else if (index == lListPtr->index) {
lListPtr->tail->next = p;
lListPtr->tail = p;
// 尾部插入的时候需要添加
// 之前忘了,发现无限循环
// 打印链表
p->next = NULL;
} else {
int count = 0;
PStackNode current = lListPtr->head;
while (count < index) {
current = current->next;
count++;
}
p->next = current->next;
current->next = p;
}
}
lListPtr->index++;
// 调试用
// printf("this index: %d\n", lListPtr->index);
} else {
printf("无法申请到内存空间!!!\n");
}
}
}
PStackNode getNodeByData(LListPtr lListPtr, int data) {
PStackNode ret = NULL;
for (PStackNode p = lListPtr->head; p; p = p->next) {
if (p->data == data) {
ret = p;
break;
}
}
return ret;
}
PStackNode getNodeByIndex(LListPtr lListPtr, int index) {
PStackNode ret = NULL;
// 输入的索引在对应链表的范围内才能返回对应的指针
if (0 < index && index < lListPtr->index) {
int count = 0;
PStackNode p = lListPtr->head;
while (count < index) {
p = p->next;
count++;
}
ret = p;
} else if (0 == index) {
ret = lListPtr->head;
} else if (lListPtr->index == index) {
ret = lListPtr->tail;
}
return ret;
}
// 删除结点好像只有删除头结点需要特殊操作
void deleteNodeOnHead(LListPtr lListPtr) {
if (lListPtr->head) {
PStackNode p = lListPtr->head;
lListPtr->head = lListPtr->head->next;
if (NULL == lListPtr->head) {
lListPtr->tail = NULL;
}
free(p);
lListPtr->index--;
}
}
// 提供一个便捷删除尾部结点的操作
void deleteNodeOnTail(LListPtr lListPtr) {
deleteNodeByIndex(lListPtr, lListPtr->index);
}
void deleteNodeByIndex(LListPtr lListPtr, int index) {
// 删除头结点
if (index == 0) {
deleteNodeOnHead(lListPtr);
} else if (index <= lListPtr->index && index > 0) {
// 删除index对应索引的下标
PStackNode current = lListPtr->head;
PStackNode perv = NULL;
int count = 0;
while (count < index) {
perv = current;
current = current->next;
count++;
}
// 前一个节点指向当前要删除结点的后面
perv->next = current->next;
free(current);
lListPtr->index--;
} else {
printf("需要删除的结点不存在\n");
}
}
// 将链表打印出来
void printLinkedList(LListPtr lListPtr) {
for (PStackNode p = lListPtr->head; p; p = p->next) {
printf("%d ", p->data);
}
}
// 反转链表操作
void reverseLinkedList(LListPtr lListPtr) {
PStackNode prev = NULL;
PStackNode current = lListPtr->head;
PStackNode next = NULL;
while (current) {
next = current->next;
current->next = prev;
prev = current;
current = next;
}
// 如果如果循环执行了,那么结束之后prev指向链表的反转之后的头部
// 原来的链表尾部变成头部结点
lListPtr->tail = lListPtr->head;
lListPtr->head = prev;
}
void clearLinkedList(LListPtr lListPtr) {
for (PStackNode p = lListPtr->head, q = NULL; p; p = q) {
q = p->next;
free(p);
}
// 清空一下链表的几个数据
// 防止二次调用该函数出现不安全的内存访问
initLinkedList(lListPtr);
}
void linkedListTest() {
LList list;
LListPtr listPtr = &list;
initLinkedList(listPtr);
printf("before: \n");
for (int i = 0; i < 5; ++i) {
if (i == 0) {
printf("item nums: \n");
}
int item = rand() % 101;
printf("%d ", item);
if (i + 1 == 5) {
printf("\n");
}
// addNodeOnHead(listPtr, item);
addNodeOnTail(listPtr, item);
}
// addNodeByIndex(listPtr, -1, rand() % 101);
// deleteNodeOnHead(listPtr);
// deleteNodeByIndex(listPtr, 4);
// deleteNodeOnTail(listPtr);
printf("%d \n", getNodeByIndex(listPtr, 0)->data);
printLinkedList(listPtr);
// reverseLinkedList(listPtr);
// printf("\n");
// printf("after: \n");
// printLinkedList(listPtr);
// clearLinkedList(listPtr);
}
测试函数输出
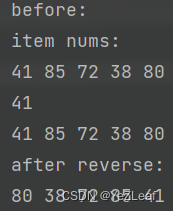
总结
单向链表的一些操作就是上面这些,这里实现了一个简单的单向链表,希望可以帮助你对如何用C语言实现单向链表加深理解。上面这些也只是我在学习数据结构时敲的一些简单代码,如果有什么错误希望能在评论区指出来,毕竟我也是一个初学者,也可能会犯错。感谢你能看到这里。后续如果有时间可能还会考虑双向链表的实现。















 1779
1779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









