







前言
在 Java 开发中,集合框架就像程序员的 "瑞士军刀"—— 无论你需要存储有序数据、去重数据,还是键值对映射,总能找到合适的工具。但很多开发者只停留在 "会用" 的层面,对底层原理一知半解,遇到问题时 debug 到崩溃。本文将从底层实现到实战技巧,带你彻底吃透 Java 集合框架。
一、集合概述:为什么需要集合?
1.1 集合与数组的核心区别
先看一个灵魂拷问:有了数组,为什么还需要集合?我们用一张对比表说清:
| 特性 | 数组 | 集合 |
|---|---|---|
| 长度 | 固定,初始化后不可变 | 动态扩容,自动调整大小 |
| 存储类型 | 只能存相同类型元素 | 可存多种类型(泛型约束前) |
| 功能 | 仅基础存储,无操作方法 | 内置增删改查、排序等方法 |
| 存储对象 | 基本类型 / 对象 | 仅对象(基本类型自动装箱) |
举个例子:如果用数组存学生信息,当学生数量超过数组长度时,需要手动创建新数组并复制元素;而用集合(如 ArrayList),直接调用add()即可,底层会自动扩容。
1.2 集合框架的 "两大阵营"
Java 集合框架主要分为Collection和Map两大体系,结构如下(配图更直观):
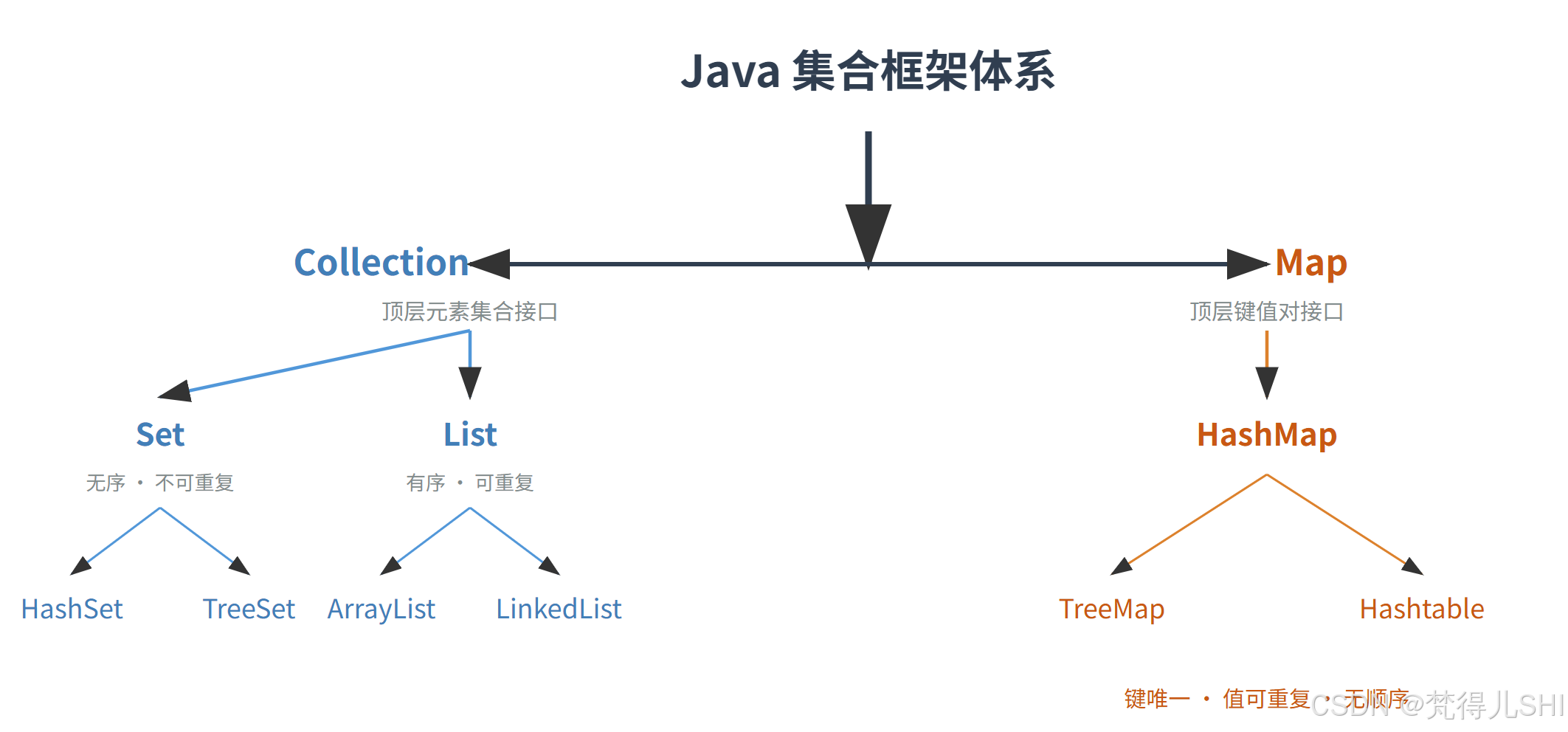
- Collection:存储单值元素的集合,类似 "列表" 或 "集合" 的数学概念。
List:有序、可重复(如购物清单,按添加顺序排列,可买多个苹果)。Set:无序、不可重复(如抽奖号码,每个号码只能出现一次)。
- Map:存储键值对(key-value),类似字典(如学生学号→成绩的映射)。
二、Collection 接口:单值集合的 "通用规则"
Collection是所有单值集合的根接口,定义了通用方法:add()、remove()、size()、isEmpty()等。我们重点看它的两大子接口实现类。
2.1 List 接口:有序可重复的 "序列"
List的核心特点是 "有序"(元素有索引,可通过下标访问)和 "可重复"(允许元素相等)。
2.1.1 ArrayList:数组实现的 "查询王者"
底层结构:基于动态数组(Object [])实现,默认初始容量为 10,当元素满了会自动扩容(扩容为原容量的 1.5 倍)。
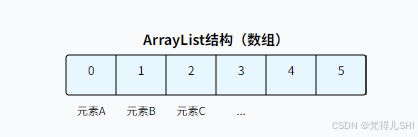
优缺点:
- 优点:查询快(通过索引直接访问,时间复杂度 O (1))。
- 缺点:增删慢(中间位置增删需要移动大量元素,时间复杂度 O (n))。
常用方法:
List<String> list = new ArrayList<>();
list.add("Java"); // 添加元素
list.add(1, "Python"); // 指定索引插入
String elem = list.get(0); // 获取元素
list.remove(0); // 删除指定索引元素
list.set(0, "C++"); // 修改元素
int size = list.size(); // 集合大小
2.1.2 LinkedList:链表实现的 "增删王者"
底层结构:基于双向链表实现,每个元素(节点)包含prev(前节点)、next(后节点)和data(数据)。
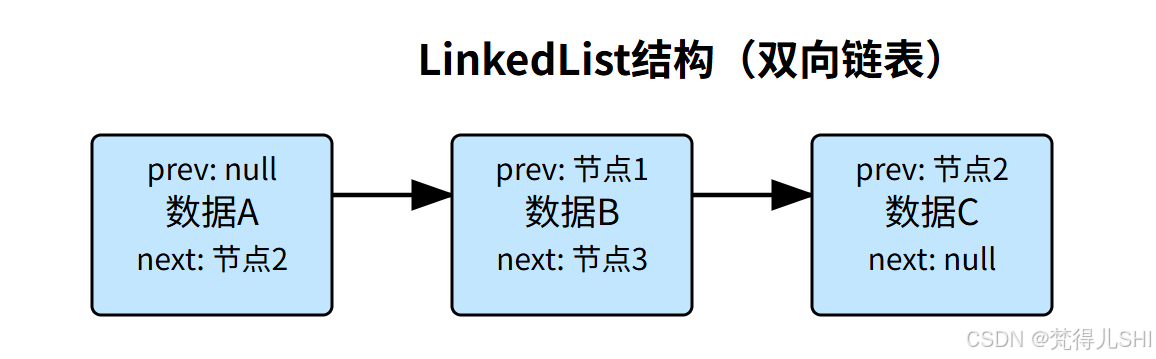
优缺点:
- 优点:增删快(只需修改前后节点的指针,时间复杂度 O (1))。
- 缺点:查询慢(需要从头 / 尾遍历,时间复杂度 O (n))。
常用方法(除了 List 通用方法,还有链表特有):
LinkedList<String> linkedList = new LinkedList<>();
linkedList.addFirst("头元素"); // 头部添加
linkedList.addLast("尾元素"); // 尾部添加
String first = linkedList.getFirst(); // 获取头部
String last = linkedList.getLast(); // 获取尾部
linkedList.removeFirst(); // 删除头部
2.2 Set 接口:无序不可重复的 "集合"
Set的核心是 "不可重复",即不能有两个相等的元素。如何判断 "相等"?这是 Set 的核心考点。
2.2.1 HashSet:哈希表实现的 "去重快手"
底层结构:基于哈希表(HashMap 的 key)实现,默认初始容量 16,负载因子 0.75(当元素数达到容量 ×0.75 时扩容为 2 倍)。
去重原理(核心中的核心):
- 当添加元素
e时,先计算e.hashCode()得到哈希值,确定在哈希表中的位置。 - 如果该位置为空,直接存入。
- 如果该位置已有元素,用
equals()比较两者:- 若
equals()返回 true,视为重复,不存入; - 若
equals()返回 false,视为哈希冲突,用链表 / 红黑树连接(和 HashMap 逻辑一致)。
- 若
关键结论:重写equals()必须同时重写hashCode(),否则会导致 HashSet 去重失效(如两个对象equals为 true 但hashCode不同,会被视为不同元素)。
// 反例:只重写equals,不重写hashCode
class Student {
String id;
Student(String id) { this.id = id; }
@Override
public boolean equals(Object o) {
return o instanceof Student && ((Student) o).id.equals(this.id);
}
// 未重写hashCode
}
public class Test {
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student("001"));
set.add(new Student("001"));
System.out.println(set.size()); // 输出2(去重失败!)
}
}
2.2.2 TreeSet:红黑树实现的 "有序集合"
底层结构:基于红黑树(一种自平衡二叉查找树)实现,元素会按 "自然顺序" 或 "定制顺序" 排序。
去重与排序原理:
- 排序:通过元素的
compareTo()方法(实现Comparable接口)或Comparator比较器确定顺序。 - 去重:当
compareTo()返回 0 时,视为两个元素相等,不存入(替代了equals()的作用)。
// 示例:TreeSet按年龄排序学生
class Student implements Comparable<Student> {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Student o) {
return this.age - o.age; // 按年龄升序
}
}
public class Test {
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
set.add(new Student("张三", 20));
set.add(new Student("李四", 18));
set.add(new Student("王五", 22));
// 输出:李四(18) → 张三(20) → 王五(22)(自动排序)
}
}
三、Map 接口:键值对的 "映射表"
Map存储键值对(key-value),key 不可重复(重复会覆盖),value 可重复。
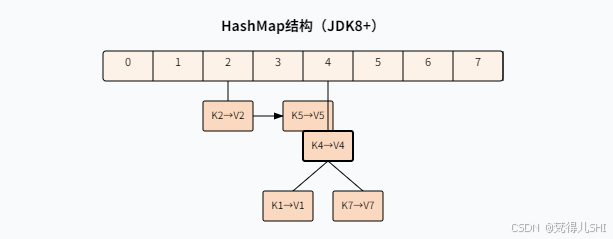
3.1 HashMap:哈希表实现的 "万能映射"
底层结构(JDK 8+):数组 + 链表 + 红黑树。
- 数组:称为 "哈希桶",每个元素是链表 / 红黑树的头节点。
- 链表:当哈希冲突时,元素以链表形式存储(长度≤8)。
- 红黑树:当链表长度≥8 且数组长度≥64 时,转为红黑树(提高查询效率,从 O (n)→O (log n))。
常用方法:
Map<String, Integer> map = new HashMap<>();
map.put("Java", 90); // 添加键值对(key重复则覆盖)
int score = map.get("Java"); // 获取value(无key返回null)
map.remove("Java"); // 删除键值对
boolean hasKey = map.containsKey("Java"); // 是否包含key
Set<String> keys = map.keySet(); // 获取所有key
Set<Map.Entry<String, Integer>> entries = map.entrySet(); // 获取所有键值对
3.2 TreeMap:红黑树实现的 "有序映射"
底层结构:基于红黑树,key 会按自然顺序或定制顺序排序,适合需要按 key 排序的场景(如排行榜)。
与 HashMap 对比:
- 有序性:TreeMap 的 key 有序,HashMap 无序。
- 性能:HashMap 查询 / 添加更快(O (1)),TreeMap 为 O (log n)。
- 去重:key 重复时都会覆盖 value。
3.3 Hashtable:古老的 "线程安全映射"
特点:
- 线程安全(方法加了
synchronized),但性能差,已被ConcurrentHashMap替代。 - 不允许 key 或 value 为 null(HashMap 允许 key 为 null 一次,value 多次)。
四、迭代器:遍历集合的 "统一工具"
遍历集合有两种方式:Iterator接口和 foreach 循环(增强 for 循环)。
4.1 Iterator 接口
Iterator是集合的迭代器,定义了遍历的标准方法:
hasNext():是否有下一个元素。next():获取下一个元素(注意:必须先调用hasNext(),否则抛NoSuchElementException)。remove():删除当前元素(遍历中修改集合的唯一安全方式)。
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String elem = it.next();
if ("A".equals(elem)) {
it.remove(); // 安全删除
}
}
4.2 foreach 循环原理
foreach 本质是Iterator的语法糖,编译后会被转换为迭代器代码。但注意:foreach 中不能修改集合结构(添加 / 删除),否则会抛ConcurrentModificationException。
// 错误示例:foreach中删除元素
for (String elem : list) {
if ("A".equals(elem)) {
list.remove(elem); // 抛异常!
}
}
五、实战练习:从理论到代码
5.1 集合遍历大比拼
| 集合类型 | 遍历方式 | 特点 |
|---|---|---|
| List | 下标遍历 / Iterator/foreach | 下标遍历仅 List 支持 |
| Set | Iterator/foreach | 无下标,只能用迭代器 |
| Map | keySet()/entrySet()/values() | entrySet () 效率最高(少一次 get) |
// Map高效遍历(entrySet)
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
// 处理键值对
}
5.2 去重统计:统计字符串中字符出现次数
public class CountChars {
public static void main(String[] args) {
String str = "hello world";
Map<Character, Integer> countMap = new HashMap<>();
for (char c : str.toCharArray()) {
// 不存在则设为1,存在则+1
countMap.put(c, countMap.getOrDefault(c, 0) + 1);
}
// 输出结果:l:3, o:2, h:1, e:1, :1, w:1, r:1, d:1
for (Map.Entry<Character, Integer> entry : countMap.entrySet()) {
System.out.print(entry.getKey() + ":" + entry.getValue() + ", ");
}
}
}
5.3 学生成绩排序与存储
需求:将学生按成绩降序排序,成绩相同按姓名升序,并存入集合。
class Student implements Comparable<Student> {
String name;
int score;
// 构造器、getter省略
@Override
public int compareTo(Student o) {
if (this.score != o.score) {
return o.score - this.score; // 成绩降序
} else {
return this.name.compareTo(o.name); // 姓名升序
}
}
}
public class SortStudents {
public static void main(String[] args) {
Set<Student> students = new TreeSet<>();
students.add(new Student("张三", 90));
students.add(new Student("李四", 85));
students.add(new Student("王五", 90));
// 输出:张三(90) → 王五(90) → 李四(85)
for (Student s : students) {
System.out.println(s.name + "(" + s.score + ")");
}
}
}
5.4 HashMap 避坑指南
- 多线程不安全:多线程下扩容可能导致死循环(JDK7)或数据错乱,用
ConcurrentHashMap替代。 - key 的 hashCode 不可变:key 应使用不可变对象(如 String、Integer),否则修改后可能无法找到 value。
// 反例:用可变对象当key Map<List<String>, String> map = new HashMap<>(); List<String> key = new ArrayList<>(); map.put(key, "value"); key.add("a"); // 修改key System.out.println(map.get(key)); // 输出null(找不到了) - 初始容量设置:已知大致元素数量时,初始化时指定容量(如
new HashMap<>(1000)),减少扩容次数。 - 避免使用 null key:虽然允许,但可能导致逻辑错误(如判断时需额外处理 null)。
总结
Java 集合框架是开发必备技能,掌握其底层原理(数组 / 链表 / 红黑树)和使用场景,能写出更高效、更健壮的代码。记住:
- 查多改少用
ArrayList,改多查少用LinkedList。 - 去重无序用
HashSet,去重有序用TreeSet。 - 键值对映射用
HashMap,有序映射用TreeMap。 - 遍历修改集合必须用
Iterator.remove()。
收藏这篇文章,遇到集合问题时翻一翻,让集合框架成为你的 "得力助手"!
版权声明:本博客内容为原创,转载请保留原文链接及作者信息。


















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











