







ES下载安装
我选择的是7.13.0的版本,可以在官网下载对应的版本之后再上传到我们自己的Linux虚拟机上。
或者可以在自己本地linux虚拟机上执行如下命令下载es的压缩包。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-linux-x86_64.tar.gz
下载完成后如下图:

然后用如下命令执行解压ES压缩包到指定文件夹下,文件夹的路径必须存在,否则会报错:
tar -zxvf elasticsearch-7.13.0-linux-x86_64.tar.gz -C /usr/local/es/
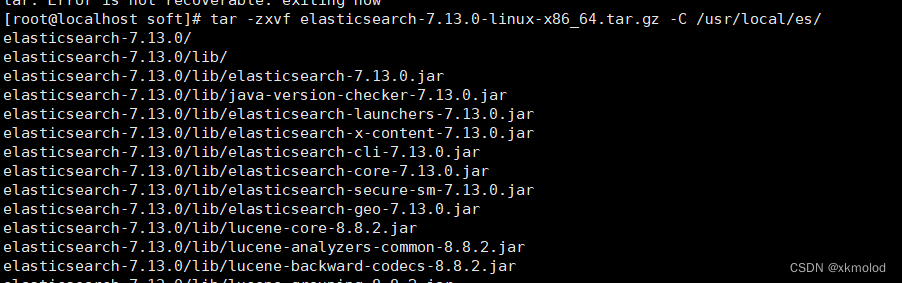
解压成功后在对应目录下可以看到解压后的文件目录:

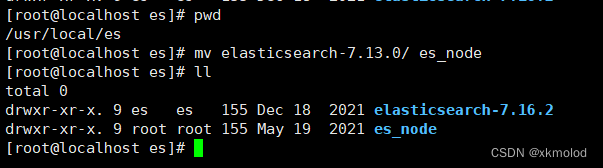
将es的目录进行改名,如下图:
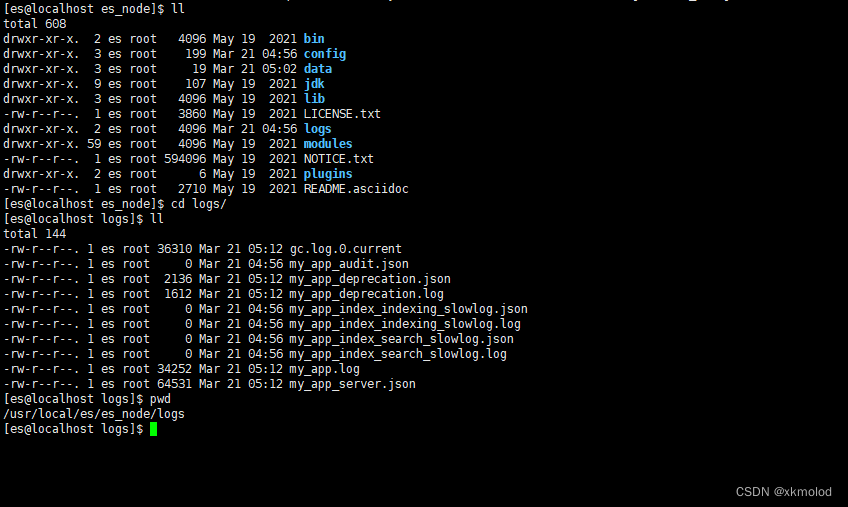
我们来看下es的目录结构,如下图所示:
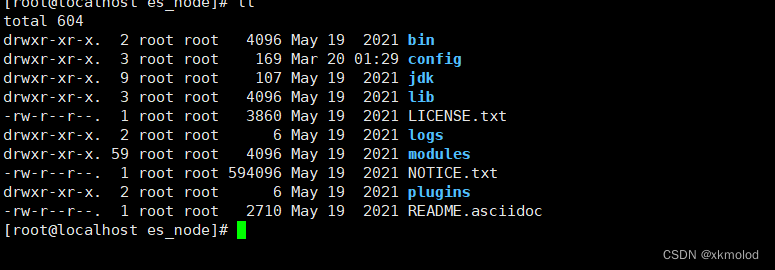
- bin目录:包含一些执行脚本,其中ES的启动文件和脚本安装文件就在这个目录里。
- config目录:包含集群的配置文件(elasticsearch.yml),jvm配置(jvm.options),user等相关配置。
- JDK目录:7.0后自带jdk,java运行环境。
- lib目录:java的类库。
- plugins目录:插件安装的目录。
- modules目录:包含所有es的模块。
修改ES配置
修改elasticsearch.yml文件
#集群的名字 单机也可以配置名称
cluster.name: my_app
#节点的名称
node.name: node_1
#数据文件的存储位置
path.data: /usr/local/es/es_node/data
#日志文件的存储位置
path.logs: /usr/local/es/es_node/logs
#ES 提供服务的监听地址,线上一定不能配置 ip 为 0.0.0.0,这是非常危险的行为。0.0.0.0 表示所有ip都可以访问
network.host: 0.0.0.0
#ES 提供服务的监听端口
http.port: 9200
#在开箱即用的情境下(本机环境)无需配置,ES 会自动扫描本机的 9300 到9305 端口。一旦进行了网络环境配置,这个自动扫描操作就不会执行。discovery.seed_hosts 配置为 master 候选者节点即可。 如果需要指定端口的话,其值可以为:[“localhost:9300”, “localhost:9301”]
#该配置是做服务或者节点发现的,其他节点必须知道他们才能进入集群,一般配置为集群的 master 候选者的列表
discovery.seed_hosts: [“192.168.10.128”]
#指定新集群 master 候选者列表,其值为节点的名字列表。这里配置了 node.name: node_1,所以其值为 [“node_1”],而不是 ip 列表 !
cluster.initial_master_nodes: [“node_1”]
修改jvm.options文件
#初始java堆内存大小
-Xms1g
#最大的堆内存大小
-Xmx1g
JVM 配置需要以下几点:
- -Xms 和-Xmx 这两个 JVM 的参数必须配置为一样的数值。服务在启动的时候就分配好内存空间,避免运行时申请分配内存造成系统抖动。
- Xmx 不要超过机器内存的50%,留下些内存供 JVM 堆外内存使用。
- 并且 Xmx 不要超过 32G。建议最大配置为 30G。接近 32G,可能会使JVM压缩指针的功能失效,导致性能下降。
启动ES
在es_node目录下执行 bin/elasticsearch命令启动报错,如下图所示:
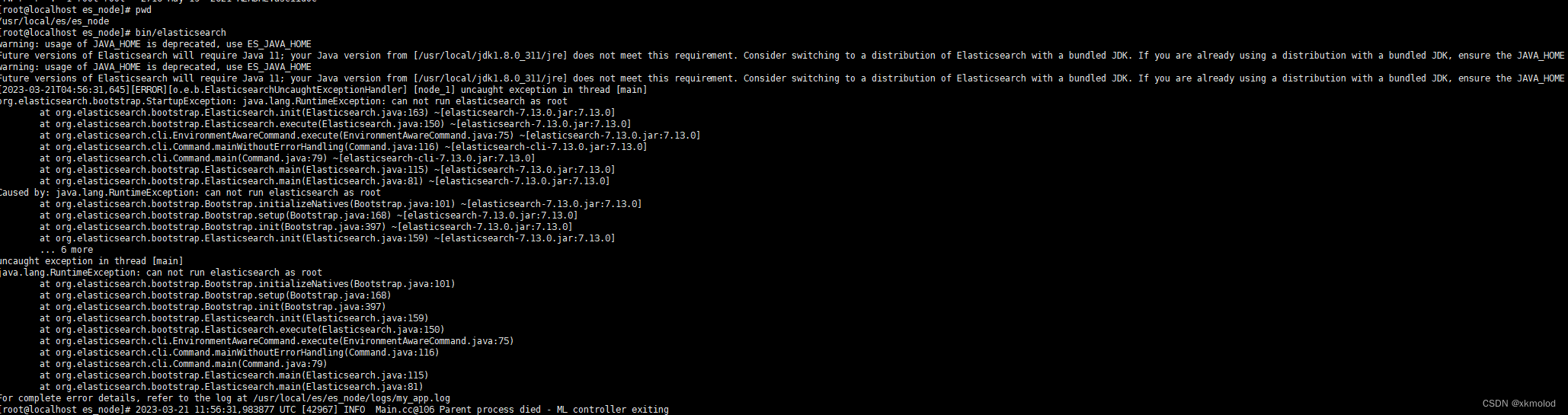
原因是es不能使用root用户启动服务,所以我们还需要为es创建一个用户。
执行以下命令,添加用户并赋予权限:
#创建es用户
useradd es
#将这个文件夹权限赋给es
chown -R es:es /usr/local/es/es_node
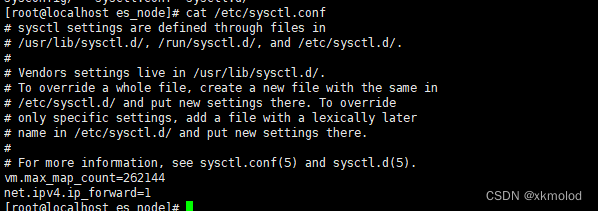
接着再执行上述命令启动,会发现报下面的错误:

按照提示进行操作系统配置就可以了,如下图:
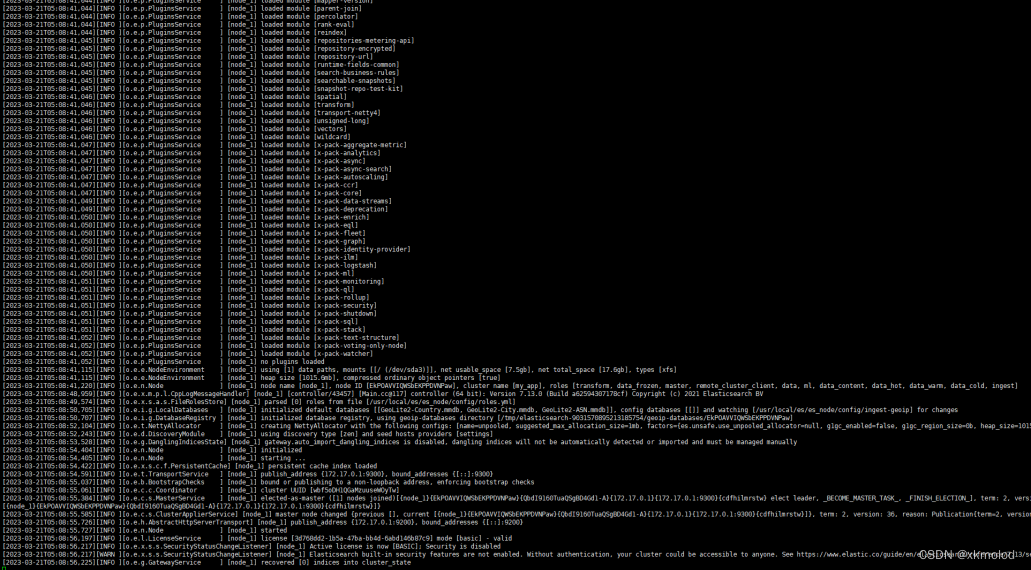
修改完后切换到es用户再启动服务。可以看到es单机服务可以正常启动成功:
./bin/elasticsearch -d 可以使es在后台启动,在对应的my_app.log下可以查看启动日志。
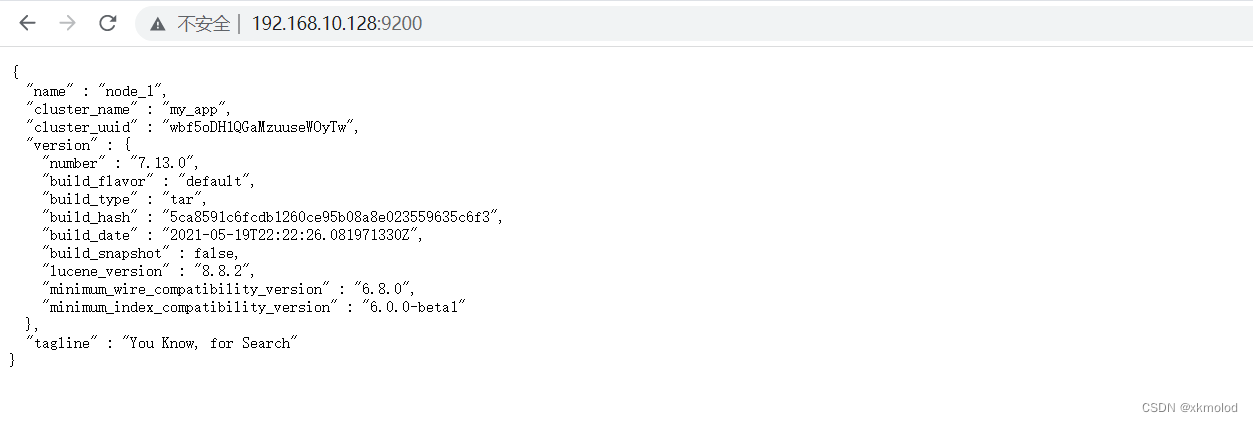
在浏览器中访问 192.168.10.128:9200,如果得到以下结果即运行成功:
kibana的安装与部署
下载解压kibana压缩包
在本地虚拟机执行以下命令下载kibana的压缩包:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.0-linux-x86_64.tar.gz
下载完成如下图:

然后用如下命令执行解压kibana压缩包到指定文件夹下,文件夹的路径必须存在,否则会报错:
tar -zxvf kibana-7.13.0-linux-x86_64.tar.gz -C /usr/local/kibana/
解压成功后在对应目录下可以看到解压后的文件目录:

将kibana的目录进行改名,如下图:
修改kibana配置
#端口
server.port: 5601
#ip
server.host: “192.168.10.128”
#es服务地址
elasticsearch.hosts: ["http://192.168.10.128:9200]
kibana启动
在kibana目录下执行下面的命令启动服务:
./bin/kibana >> run.log 2>&1 &
找到对应的日志查看日志,发现报错:
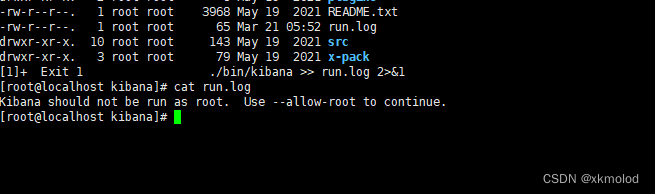
kibana与es一样不能用root用户启动,我们还是切换到es用户启动kibana。
在启动之前先给kibana的目录赋予es用户的权限:
chown -R es:es /usr/local/kibana/kibana/
再切换到es用户启动服务:

安装完成后,在浏览器中访问 192.168.10.128:5601,如果运行成功可以进入到如下界面:
安装 Cerebro
Cerebro 是一个简单的 ES 管理工具,其安装步骤如下:
#如果你无法从github下载文件,那么可以访问下面的链接手动(备份地址无法用wget下载)下载,然后再进行解压。
#备份地址:https://gitee.com/dgl/es-booklet/raw/master/resources/cerebro-0.9.4.tgz
wget https://github.com/lmenezes/cerebro/releases/download/v0.9.4/cerebro-0.9.4.tgz
tar -zxvf cerebro-0.9.4.tgz -C /usr/local/
cd /usr/local/
mv cerebro-0.9.4 cerebro
cd cerebro
sed -i ‘s/server.http.port = ${?CEREBRO_PORT}/server.http.port = 9800/g’ conf/application.conf
echo -e ‘\nhosts = [
{
host = “http://192.168.10.128:9200”
name = “my_app”
}
]’ >> conf/application.conf
配置完成后,运行以下指令启动 cerebo:
#启动, 在run.log中查看日志
nohup ./bin/cerebro > run.log &
如果启动成功,在浏览器中访问 localhost:9800 即可访问 cerebro。
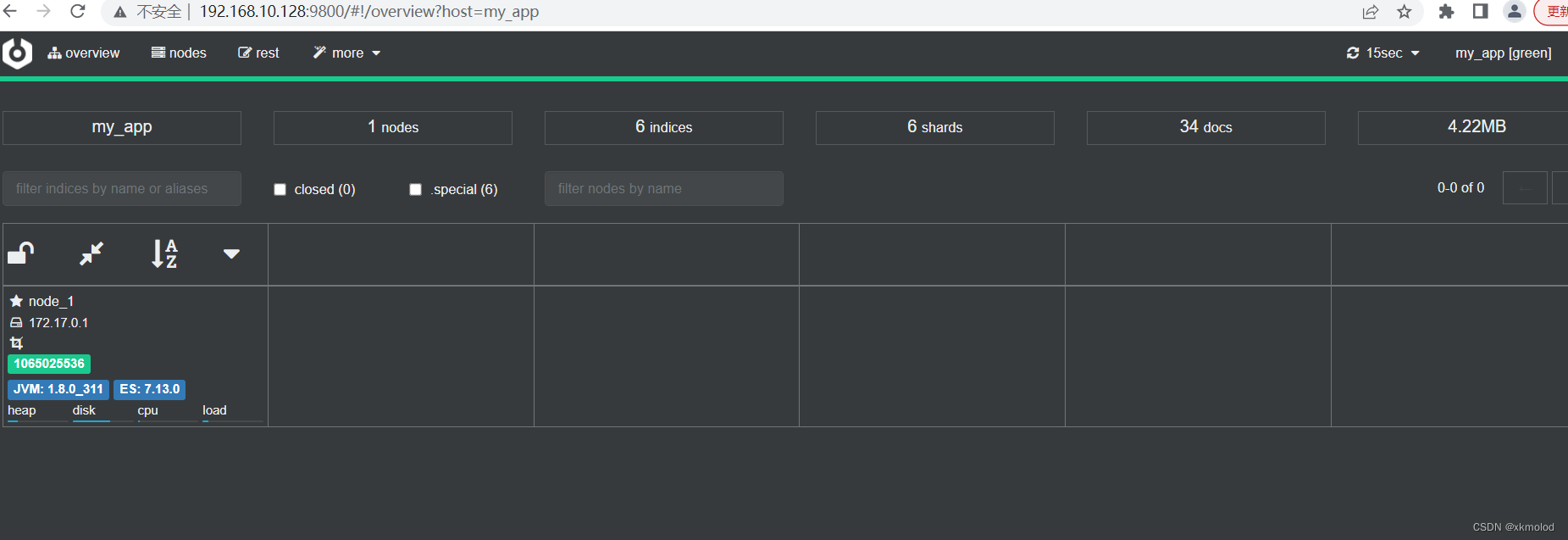
ES集群部署
上述只是搭建启动了一个单机版的es服务,接下来我们在三台虚拟机上分别启动es服务组成es集群。
es节点对应的虚拟机地址如下:
| ES节点名称 | 虚拟机ip地址 |
|---|---|
| node_1 | 192.168.10.128 |
| node_2 | 192.168.10.129 |
| node_3 | 192.168.10.130 |
我们先修改原来单机es服务的配置,然后复制到另外两台机器上,具体修改的内容如下:
#在es的配置文件中将对应的参数修改为下面的值
network.host: 192.168.10.128
discovery.seed_hosts: [“192.168.10.128:9300”,“192.168.10.129:9300”,“192.168.10.130:9300”]
transport.port: 9300
#然后执行以下命令将es所在的目录拷贝到另外两台机器上
scp -r es_node/ root@192.168.10.129:/usr/local/es/
scp -r es_node/ root@192.168.10.130:/usr/local/es/
#在192.168.10.129这台机器上修改对应的es配置文件
#将节点名称修改为node_2
node.name: node_2
#将监听地址改为本机ip地址
network.host: 192.168.10.129
#同理在192.168.10.130机器上将节点名称修改为node_3
node.name: node_3
#将监听地址改为本机ip地址
network.host: 192.168.10.130
在129和130两台机器上添加es用户并赋予对应权限
useradd es
chown -R es:es /usr/local/es/es_node
#然后在每台机器上切换到es用户
su es
#执行命令启动es服务
./bin/elasticsearch -d
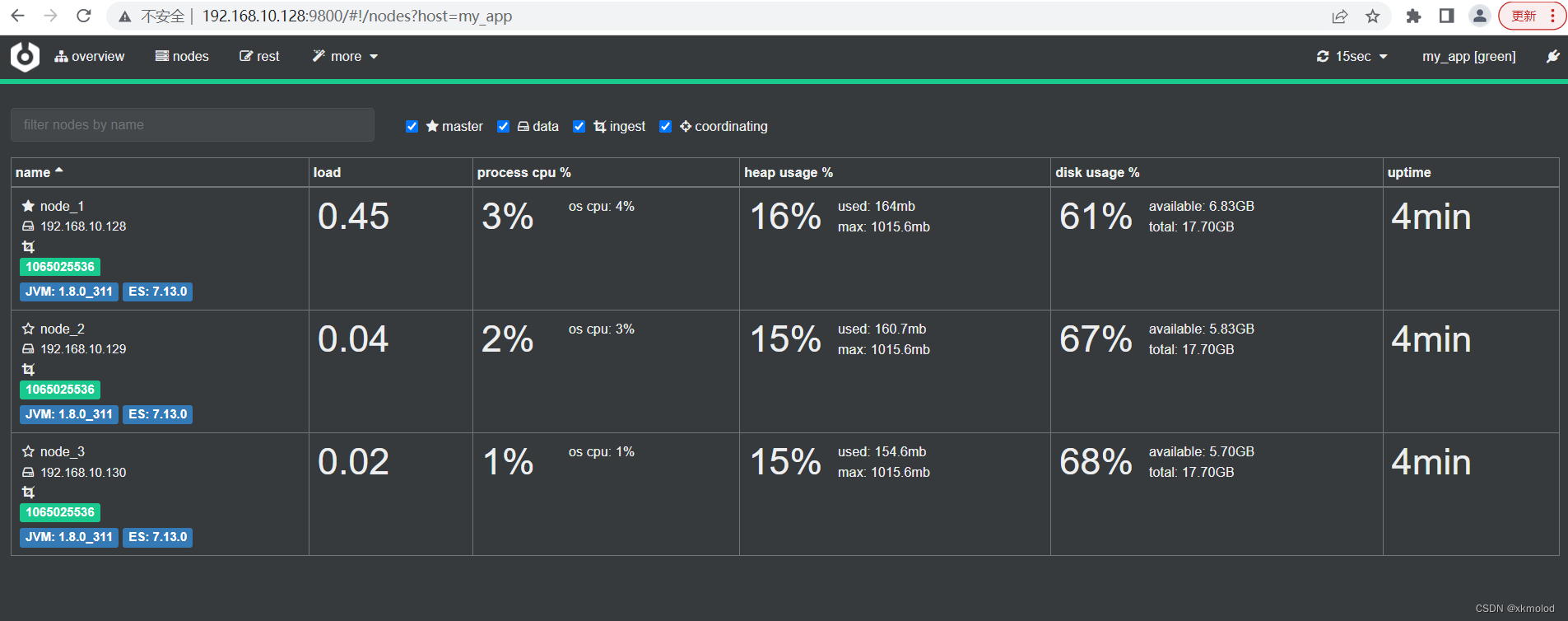
上述步骤都操作成功后,我们可以在cerebro页面看到es集群的相关信息,如下图所示:















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











