







Python中常见的解析技术:正则、xpath、BeautifullSoup、json模块、jsonpath
正则:从任意的字符串中查找需要数据
Ⅹpath, BeautifullSoup都是用于处理有层次结构的数据,比如:html,xmlisQn模块与 nonpath:专门用于处理json数据
性能
正则:最快,使用难度高,无需安装,内置re模块
Xpath:是通过c语言实现,速度比较快,使用比较简单,安装比较简单
BeautifullSoup:通过 python实现,速度比较慢,使用简单,安装比较简单
json模块:速度一般,使用非常简单,通过内置的json模块
jsonpath:速度一般,使用简单,安装比较简单
正则表达式(爬虫中常用的两种)
方法 功能 参数说明 返回值类型

import re
# 从“你好,hello,世界”从字符串中提取中文
text = '你好,hello,世界'
# 通过正则表达式,生成一个pattern对象(只用于匹配中文)
pattern = re.compile(r'[\u4e00-\u9fa5]+')
# 检索字符串,将匹配的中文存入列表
result = pattern.findall(text)
print(result)
xpath语法
1.选取节点

2、谓语(补充说明节点)
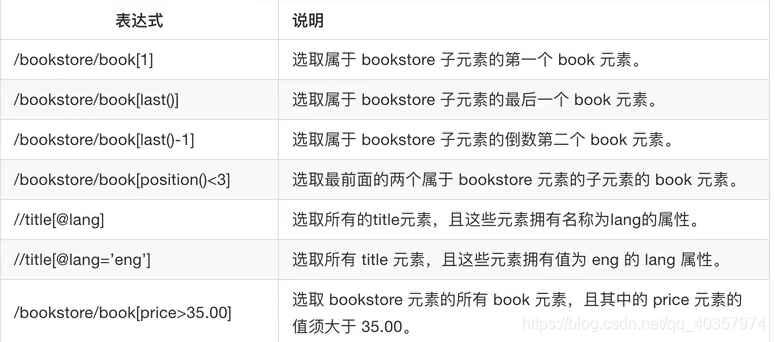
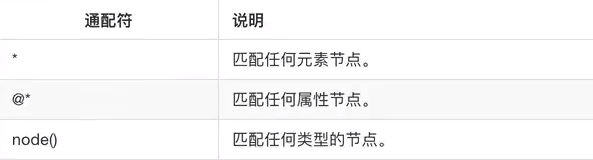
3、选取未知节点















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









