







本题适合一到三年 Java 开发 ,以下问题都是按照原面试官提问记录
文章目录
- redis五种基本数据类型
- redis为什么那么快
- es和solr区别
- 搜索项目qps、数据量、架构说下
- 说一下tfidf和bm25
- hashmap jdk8做过哪些优化
- 抓取动态页如何失效,怎么区分动态静态页,讲一下你们抓取项目,如何维护种子页?
- 多线程了解?然后我分别介绍了Future、threadpool、Forkjoin、semaphore、countdownlatch
我要进大厂系列面试题
全部真题,欢迎投稿你的面试经验。
一面
- redis 五种基本数据类型
- String 、 Hash 、 List 、 Set 、 ZSet
- redis为什么那么快
- 完全基于内存,纯粹的内存操作,非常快。类似于 HashMap ,HashMap的查找和操作时间复杂度都是O(1)。
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在对现场切换导致的小号CPU,不用考虑锁得问题,导致的性能消耗。
- 使用多路I/O复用模型,非阻塞IO。
答前俩点就可以,第三点拓展。多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
- es和solr区别
- 单纯的对已有数据进行搜索时,Solr更快。
- 当实时建立索引时,Solr会产生io阻塞,查询性能较差,Elasticsearch 具有明显的优势。
- 随着数据量的不断动态添加,Sorl 的搜索效率会变得更低,而 Elasticsearch 却没有明显变化。
- 综上所述,Sorl 不适合实时搜索的应用。
拓展:
二者安装都很简单;
Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
- 说一下tfidf和bm25
TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率).
- tfidf
是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章.
需要注意的是:过滤掉常见的通用词语,他们对主题没有太大影响
bm25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法
- bm25
掌握BM25,核心要点有三个:分词之后w的权重,w和q的相似性,w和d的相似性。
再用简单的话来描述下bm25算法:我们有一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,我们的做法是,先对query进行切分,得到单词 q i q_i qi,然后单词的分数由3部分组成:
单词$q_i$和D之间的相关性
单词$q_i$和D之间的相关性
每个单词的权重
最后对于每个单词的分数我们做一个求和,就得到了query和文档之间的分数。
- hashmap jdk8做过哪些优化
- 典型回答
在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的,JDK 1.8 之后新增了红黑树的组成结构,当链表大于 8 并且容量大于 64 时,链表结构会转换成红黑树结构。
考点分析:(面试官想要知道的远不止这些,如下)
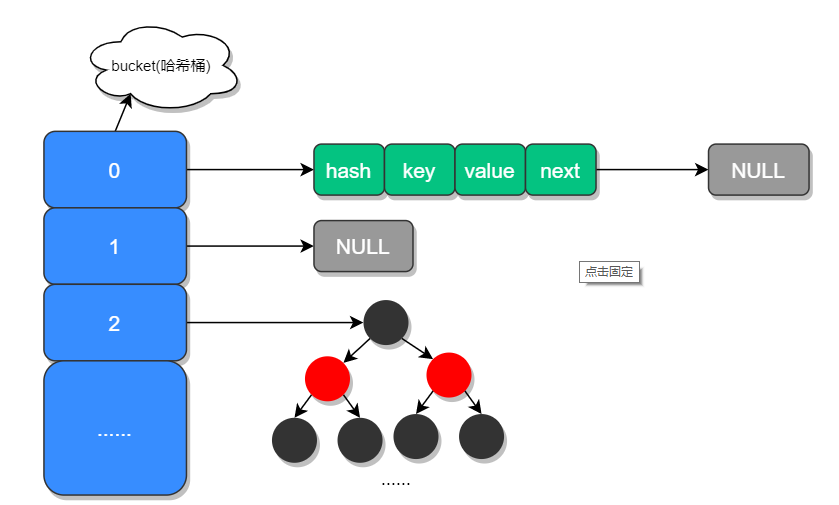
- JDK 1.8 HashMap 扩容时做了哪些优化?
在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的,JDK 1.8 之后新增了红黑树的组成结构,当链表大于 8 并且容量大于 64 时,链表结构会转换成红黑树结构。
- 加载因子为什么是 0.75?
加载因子也叫扩容因子或负载因子,用来判断什么时候进行扩容的,假如加载因子是 0.5,HashMap 的初始化容量是 16,那么当 HashMap 中有 16*0.5=8 个元素时,HashMap 就会进行扩容。
这是在内存和性能之间考虑的结果,当加载因子过大的时候,扩容门槛就相对比较高,内存占用小,但是发生Hash冲突的概率就比较大,需要更复杂的数据结构(红黑树)存储,运行效率相对下降;当加载因子过小的时候,扩容门槛低,元素稀疏,发生哈希冲突的概率就小,操作性能好,但是占用大。
- 当有哈希冲突时,HashMap 是如何查找并确认元素的?
当哈希冲突的时候,会进行key值的判断来找到对应的元素。
-
HashMap 源码中有哪些重要的方法?
a. hash():计算对应的位置
b. resize():扩容
c. putTreeVal():树形节点的插入
d. treeifyBin():树形化容器
-
HashMap 是如何导致死循环的?
这个问题设计到多线程问题,hashmap是有并发问题的,详细介绍阅读下文。
参考:https://www.jianshu.com/p/1e9cf0ac07f4
- 抓取动态页如何失效,怎么区分动态静态页,讲一下你们抓取项目,如何维护种子页?rpush,lpoll
这是一道开放性题目,当一个站点采集批量处理失败时,我们就需要用动态采集尝试(执行请求到的JavaScript文件)。
对于维护种子页,我在项目中一般使用 redis 的 list 数据结构,使用 rpoplpush key key 命令循环遍历。
- 多线程了解?然后我分别介绍了 Forkjoin、Future、threadpool、semaphore、countdownlatch
Forkjoin框架:
就是在必要的情况下,将一个大任务,进行拆分成若干个小任务(拆到不可再拆时),再将一个个小任务运算的结果进行 join 汇总。也就是 分而治之 的思想。
使用方式:
我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork和join的操作机制,通常我们不直接继承ForkjoinTask类,只需要直接继承其子类。
RecursiveAction,用于没有返回结果的任务。
RecursiveTask< V >,用于有返回值的任务。
ForkjoinTask要通过ForkJoinPool来执行,使用submit 或 invoke 提交。
两者的区别是:
invoke是同步执行,调用之后需要等待任务完成,才能执行后面的代码。
submit是异步执行。
join和get方法当任务完成的时候返回计算结果。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
/**
* ForkJoin执行累加
*/
public class SumArray {
private static class SumTask extends RecursiveTask<Integer>{
/*阈值*/
private final static int THRESHOLD = MakeArray.ARRAY_LENGTH/10;
private int[] src;
private int fromIndex;
private int toIndex;
public SumTask(int[] src, int fromIndex, int toIndex) {
this.src = src;
this.fromIndex = fromIndex;
this.toIndex = toIndex;
}
@Override
protected Integer compute() {
//任务的大小是否合适
if (toIndex - fromIndex < THRESHOLD){
//合适,做我们自己的工作
System.out.println(" from index = "+fromIndex
+" toIndex="+toIndex);
int count = 0;
for(int i= fromIndex;i<=toIndex;i++){
count = count + src[i];
}
//提交
return count;
}else{
//不满足,拆分任务,这里数量为2个
int mid = (fromIndex+toIndex)/2;
SumTask left = new SumTask(src,fromIndex,mid);
SumTask right = new SumTask(src,mid+1,toIndex);
//提交任务ForkJoinPool
invokeAll(left,right);
//任务完成返回计算结果
return left.join()+right.join();
}
}
}
public static void main(String[] args) {
int[] src = MakeArray.makeArray();
//创建ForkJoin池
ForkJoinPool pool = new ForkJoinPool();
//创建任务
SumTask innerFind = new SumTask(src,0,src.length-1);
long start = System.currentTimeMillis();
//异步提交任务
pool.submit(innerFind);
//同步提交任务
//pool.invoke(innerFind);
System.out.println("Task is Running.....");
System.out.println("The count is "+innerFind.join()
+" spend time:"+(System.currentTimeMillis()-start)+"ms");
}
}
import java.util.Random;
public class MakeArray {
//数组长度
public static final int ARRAY_LENGTH = 4000000;
public static int[] makeArray() {
//new一个随机数发生器
Random r = new Random();
int[] result = new int[ARRAY_LENGTH];
for(int i=0;i<ARRAY_LENGTH;i++){
//用随机数填充数组
result[i] = r.nextInt(ARRAY_LENGTH*3);
}
return result;
}
}
countdownlatch:
闭锁,CountDownLatch这个类能够使一个线程等待其他线程完成各自的工作后再执行。
CountDownLatch是通过一个计数器来实现的,计数器的初始值为初始任务的数量。每当完成了一个任务后,计数器的值就会减1(CountDownLatch.countDown()方法)。当计数器值到达0时,它表示所有的已经完成了任务,然后在闭锁上等待CountDownLatch.await()方法的线程就可以恢复执行任务。
import java.util.concurrent.CountDownLatch;
/**
*类说明:演示CountDownLatch用法,
* 共5个初始化子线程,6个闭锁扣除点,扣除完毕后,主线程和业务线程才能继续执行
*/
public class UseCountDownLatch {
static CountDownLatch latch = new CountDownLatch(6);
/*初始化线程*/
private static class InitThread implements Runnable{
public void run() {
System.out.println("Thread_"+Thread.currentThread().getId()
+" ready init work......");
latch.countDown();
for(int i =0;i<2;i++) {
System.out.println("Thread_"+Thread.currentThread().getId()
+" ........continue do its work");
}
}
}
/*业务线程等待latch的计数器为0完成*/
private static class BusiThread implements Runnable{
public void run() {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
for(int i =0;i<3;i++) {
System.out.println("BusiThread_"+Thread.currentThread().getId()
+" do business-----");
}
}
}
public static void main(String[] args) throws InterruptedException {
//这个线程里有2个扣除点
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread_"+Thread.currentThread().getId()
+" ready init work step 1st......");
latch.countDown();
System.out.println("begin step 2nd.......");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread_"+Thread.currentThread().getId()
+" ready init work step 2nd......");
latch.countDown();
}).start();
new Thread(new BusiThread()).start();
//4个线程共4个扣除点,加上面的2个扣除点,一共6个
for(int i=0;i<=3;i++){
Thread thread = new Thread(new InitThread());
thread.start();
}
//主线程等待
latch.await();
System.out.println("Main do work........");
}
}
应用场景:
实现最大的并行性:有时我们想同时启动多个线程,实现最大程度的并行性。例如,我们想测试一个单例类。如果我们创建一个初始计数为1的CountDownLatch,并让所有线程都在这个锁上等待,那么我们可以很轻松地完成测试。我们只需调用 一次countDown()方法就可以让所有的等待线程同时恢复执行。
开始执行前等待n个线程完成各自任务:例如应用程序启动类要确保在处理用户请求前,所有N个外部系统已经启动和运行了,例如处理excel中多个表单。
Semaphore:
Semaphore 是一个计数信号量,必须由获取它的线程释放。
常用于限制可以访问某些资源的线程数量,例如通过 Semaphore 限流(控制同时访问特定资源的线程数量,通过协调各个线程,以保证合理的使用资源)。
Semaphore 只有3个操作:
初始化
增加
减少
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class StudySemaphore {
public static void main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
//信号量,只允许 3个线程同时访问
Semaphore semaphore = new Semaphore(3);
for (int i=0;i<10;i++){
final long num = i;
executorService.submit(new Runnable() {
@Override
public void run() {
try {
//获取许可
semaphore.acquire();
//执行
System.out.println("Accessing: " + num);
Thread.sleep(new Random().nextInt(5000)); // 模拟随机执行时长
//释放
semaphore.release();
System.out.println("Release..." + num);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
executorService.shutdown();
}
}
Future:
Future 是 java1.5 引入的一个 interface,可以方便的用于与异步结果的获取。
在并发编程中,我们经常用到的非阻塞模型。通过实现 Callback 接口,并用 Future 来接收多线程的执行结果。(比如下代码举例,买包子(3s)和买凉菜(1s)并行执行)。
常用到的场景:
1. 计算密集场景。
2. 处理大数据量。
3. 远程方法调用等。
// author: JavaPub rodert
public static void main(String[] args) throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
// 等凉菜
Callable ca1 = new Callable() {
@Override
public String call() throws Exception {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "凉菜准备完毕";
}
};
FutureTask<String> ft1 = new FutureTask<String>(ca1);
new Thread(ft1).start();
// 等包子 -- 必须要等待返回的结果,所以要调用join方法
Callable ca2 = new Callable() {
@Override
public Object call() throws Exception {
try {
Thread.sleep(1000 * 3);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "包子准备完毕";
}
};
FutureTask<String> ft2 = new FutureTask<String>(ca2);
new Thread(ft2).start();
System.out.println(ft1.get());
System.out.println(ft2.get());
long end = System.currentTimeMillis();
System.out.println("准备完毕时间:" + (end - start));
}
明显看到执行结果是 准备完毕时间:3005
threadpool
线程池可以看做线程的容器,类似数据库连接池(池化技术)。减少创建和销毁线程的次数,工作线程重复利用。

Executor 是 Java 线程池的顶级接口,严格来说 Executor 并不是线程池,而是一个执行线程池的工具。真正的线程池接口是 ExecutorService。
要配置一个线程池比较复杂,而且对线程池原理不熟悉情况下,可能配置的线程池不是较优的,因此 Executors 类提供了一些静态工厂,生成常用的线程池。
newSingleThreadExecutor 单线程线程池,主要保证任务执行顺序按提交顺序执行。
newFixedThreadPool 创建固定大小的线程池。
newCachedThreadPool 创建一个可缓存的线程池。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
newScheduledThreadPool 创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
Executors 类创建几种线程池的源码中可以发现,底层调用了 ThreadPoolExecutor 类的构造方法。
包含如下参数:
/**
* 用给定的参数创建一个线程池
*
* @param corePoolSize 池中所保存的线程数,包括空闲线程。
* @param maximumPoolSize 池中允许的最大线程数。
* @param keepAliveTime 当线程数大于核心时,此为终止前多余的空闲线 程等待新任务的最长时间。
* @param unit 参数的时间单位。
* @param workQueue 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的Runnable任务。
* @param threadFactory 执行程序创建新线程时使用的工厂。
* @param handler 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
*/
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
更多参考:https://www.jianshu.com/p/2dc69025cebe
到这里一面题目结束,北京某厂真题。下面是一些财经相关。
疫情期间股市剧烈波动,一大波新老用户都在涌现,我D的政策是**加快形成以国内大循环为主体、国内国际双循环相互促进的新发展格局*。最近新能源汽车行业发展迅猛,今年以来涨了很多,个人后续还持续看好。
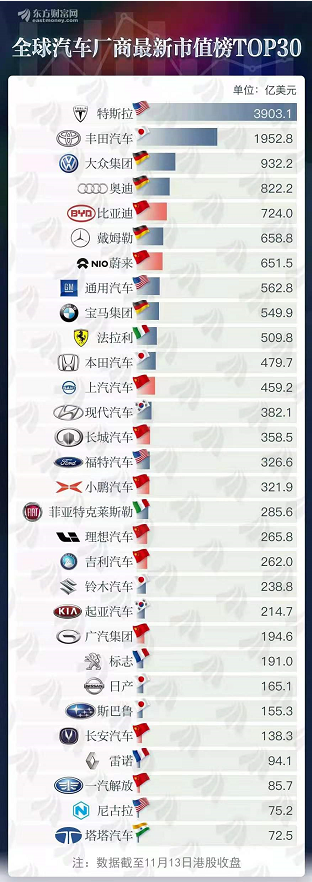















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











