







背景介绍
word2vec最大的问题是基于局部窗口而训练出来的词向量是没有全局性的(一定程度上),还有一种利用全局矩阵分解形式训练的词向量,但这种方法在词对推理任务上表现不是很好。
GloVe采用了词频共现的模型来训练词向量,即基于全局词汇共现的统计信息来学习词向量,从而将统计信息和局部上下文窗口两种方法的优点结合起来。出自论文《GloVe- Global Vectors for Word Representation》
参考:GloVe详解
GloVe模型讲解
原理
在日常阅读中,我们会发现一些词汇经常是一起出现的,比如当描述一件衣服的颜色时,我们会发现衣服的颜色(红色、黑色等)会和颜色这个词一块出现;形容冰块时我们常常用固体来形容;形容水蒸气时我们常常用气体来形容。也就是说经常一起出现的词汇组,当其中一个词出现时,另一个词在一个句子中出现的概率也很大,而其他不相关的单词出现的概率就很小,所以我们可以用共现矩阵的概率比值来区分词。
如下图,我们使用冰块和蒸汽来描述固体、气体、水和时尚四个词。

当K=solid时:
P
(
s
o
l
i
d
∣
i
c
e
)
P{ \left( {solid \left| ice\right. }\right) }
P(solid∣ice)/
P
(
s
o
l
i
d
∣
s
t
e
a
m
)
P{\left({solid\left|steam\right.}\right)}
P(solid∣steam)为8.9,远大于1,表示固体和冰块共现的概率相比较与蒸汽更大。
当K=gas时:
P
(
g
a
s
∣
i
c
e
)
P{ \left( {gas \left| ice\right. }\right) }
P(gas∣ice)/
P
(
g
a
s
∣
s
t
e
a
m
)
P{\left({gas\left|steam\right.}\right)}
P(gas∣steam)为0.085,远小于1,表示气体和冰块共现的概率相比较与蒸汽更小。
当K=water时:
P
(
w
a
t
e
r
∣
i
c
e
)
P{ \left( {water \left| ice\right. }\right) }
P(water∣ice)/
P
(
w
a
t
e
r
∣
s
t
e
a
m
)
P{\left({water\left|steam\right.}\right)}
P(water∣steam)为1.39,接近1,表示在这个语料库中,水与冰块共现的概率相比较于蒸汽来说只是多一点,或者说水和冰块、蒸汽都相近。
当K=fashion时:
P
(
f
a
s
h
i
o
n
r
∣
i
c
e
)
P{ \left( {fashionr \left| ice\right. }\right) }
P(fashionr∣ice)/
P
(
f
a
s
h
i
o
n
∣
s
t
e
a
m
)
P{\left({fashion\left|steam\right.}\right)}
P(fashion∣steam)为0.96,几乎等于1,表示在这个语料库中,时尚与冰块共现的概率相比较于蒸汽来说相近或者说时尚和冰块、蒸汽都不相关;而且看单独的比值,时尚与这两个词共现的概率都很小。
GloVe模型
GloVe模型首先根据语料库构建一个共现矩阵X,矩阵中的每一元素
X
i
j
X_{ij}
Xij代表了在特定窗口下单词
X
i
X_i
Xi和上下文单词
X
j
X_j
Xj共现的次数;另外GloVe还提出了一个衰减函数的概念:两个单词共现的次数越多,那么其权重就应该越大,表现为:两个单词在上下文窗口的距离为d,权重decay=1/d,距离越远的两个单词所占总计数的权重就越小。
GloVe是构建词向量和共现矩阵之间的近似关系训练词向量的,其关系为:
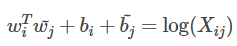
其中
W
i
T
W_i^T
WiT和
W
j
W_j
Wj是我们要求取得词向量。
另外损失函数(均方损失函数)为:

f
(
X
i
j
)
f(X_{ij})
f(Xij)为衰减函数。
GloVe模型细节
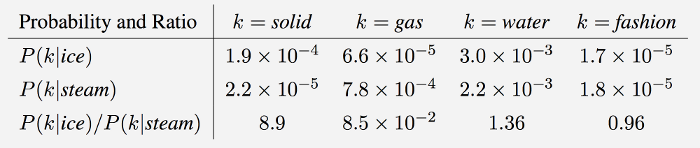
根据上图,由于我们可以用共现矩阵的概率比值来区分词,即可以根据
P
(
K
∣
i
c
e
)
P{ \left( {K\left| ice\right. }\right) }
P(K∣ice)/
P
(
K
∣
s
t
e
a
m
)
P{\left({K\left|steam\right.}\right)}
P(K∣steam)来判断单词K和ice更接近还是和steam更接近。也就是说,我们可以通过概率的比例比较而不是单词K和上下文单词共现的概率去学习词向量,这种方法更好,即可以全局地学习词向量,也可以区分单词间的不同。
构建词向量和共现矩阵之间的近似关系公式推导过程:
首先我们建立公式:
F
(
w
i
,
w
j
,
w
k
~
)
=
P
i
k
P
j
k
,
(1)
F(w_i,w_j,\tilde{w_k}) = \frac{P_{ik}}{P_{jk}},\tag{1}
F(wi,wj,wk~)=PjkPik,(1)
其中
w
i
w_i
wi、
w
j
w_j
wj为上下文窗口单词向量,
w
k
~
\tilde{w_k}
wk~是目标向量。
P
i
k
P_{ik}
Pik、
P
j
k
P_{jk}
Pjk分别为单词K对单词i、j的共现概率。
其次,由于向量空间是线性结构的,所以为了表达出两个概率的比例差异,我们在函数F的形式上做了点改变,即:
F
(
w
i
−
w
j
,
w
k
~
)
=
P
i
k
P
j
k
,
(2)
F(w_i-w_j,\tilde{w_k}) = \frac{P_{ik}}{P_{jk}},\tag{2}
F(wi−wj,wk~)=PjkPik,(2)
再者,公式2的右侧是一个标量值,而函数F内都是向量值,我们可以将其转换为两个向量的内积形式:
F
(
(
w
i
−
w
j
)
T
w
k
~
)
=
P
i
k
P
j
k
,
(3)
F((w_i-w_j)^T \tilde{w_k}) = \frac{P_{ik}}{P_{jk}},\tag{3}
F((wi−wj)Twk~)=PjkPik,(3)
然后我们令F=exp,有如下的推导过程:
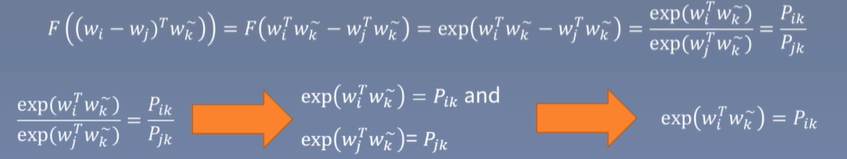
我们可以得知:EXP(
w
i
T
w_i^T
wiT
w
k
~
\tilde{w_k}
wk~)=
P
i
k
P_{ik}
Pik,其中i为上下文窗口任一单词,k为目标单词。
EXP(
w
i
T
w_i^T
wiT
w
k
~
\tilde{w_k}
wk~)=
P
i
k
P_{ik}
Pik,由于
P
i
k
P_{ik}
Pik=
P
i
k
P
j
k
\frac{P_{ik}}{P_{jk}}
PjkPik,那么:
w
i
T
w
k
~
=
log
(
P
i
k
)
=
log
(
X
i
k
)
–
log
(
X
i
)
,
(4)
w_i^T \tilde{w_k} = \log(P_{ik}) = \log(X_{ik}) – \log({X_i}),\tag{4}
wiTwk~=log(Pik)=log(Xik)–log(Xi),(4)
公式4是不满足对称性的,而且这个
log
(
X
i
)
\log(X_i)
log(Xi)是跟K独立的,它只跟i相关,于是我们可以将
w
i
w_i
wi替换为
b
i
b_i
bi,即一个偏差项,那么:
w
i
T
w
k
~
+
b
i
=
log
(
X
i
k
)
,
(5)
w_i^T \tilde{w_k} + b_i= \log(X_{ik}), \tag{5}
wiTwk~+bi=log(Xik),(5)
最后由于公式5还不满足不对称性,我们针对
w
k
w_k
wk增加一个偏差项
b
k
b_k
bk,从而得出我们要训练的模型关系公式:
w
i
T
w
k
~
+
b
i
+
b
k
=
log
(
X
i
k
)
w_i^T \tilde{w_k} + b_i + b_k= \log(X_{ik})
wiTwk~+bi+bk=log(Xik)
损失函数细节
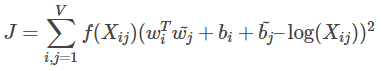
损失函数如上图所示:
右边平方里面就是计算出来的
X
i
j
X_{ij}
Xij的比值和真实的
X
i
j
X_{ij}
Xij之间的差值。
f(
X
i
j
X_{ij}
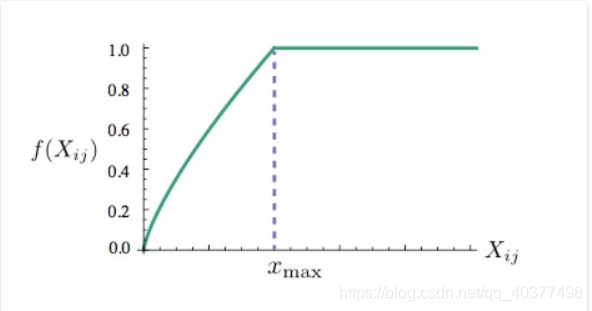
Xij)为权重函数。在一个语料库中,很多单词共现的次数很多,那么这些单词组的权重要大于其他很少一起出现的单词,就比如上面冰块和固体的权重要大于冰块和气体的权重,所以这个函数是非递减函数;同时,权重也不能过大,因为s、the、are这些词的影响(出现次数太多了)。所以设置该权重达到一定程度后就不再增加;另外当两个单词没有在一起出现,即
X
i
j
=
0
X_{ij}=0
Xij=0时,权重为0,那么不参加训练。
那么f(
X
i
j
X_{ij}
Xij)的形式为:
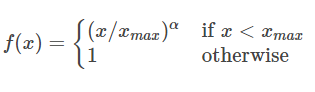
函数图像为:
代码
class glove_model(nn.Module):
def __init__(self,vocab_size,embed_size,x_max,alpha):
super(glove_model, self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
self.x_max = x_max
self.alpha = alpha
self.w_embed = nn.Embedding(self.vocab_size,self.embed_size).type(torch.float64)
self.w_bias = nn.Embedding(self.vocab_size,1).type(torch.float64)
self.v_embed = nn.Embedding(self.vocab_size, self.embed_size).type(torch.float64)
self.v_bias = nn.Embedding(self.vocab_size, 1).type(torch.float64)
def forward(self, w_data,v_data,labels):
w_data_embed = self.w_embed(w_data)
w_data_bias = self.w_bias(w_data)
v_data_embed = self.v_embed(v_data)
v_data_bias = self.v_bias(v_data)
weights = torch.pow(labels/self.x_max,self.alpha)
weights[weights>1]=1
loss = torch.mean(weights*torch.pow(torch.sum(w_data_embed*v_data_embed,1)+w_data_bias+v_data_bias-
torch.log(labels),2))
return loss














 1975
1975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









