







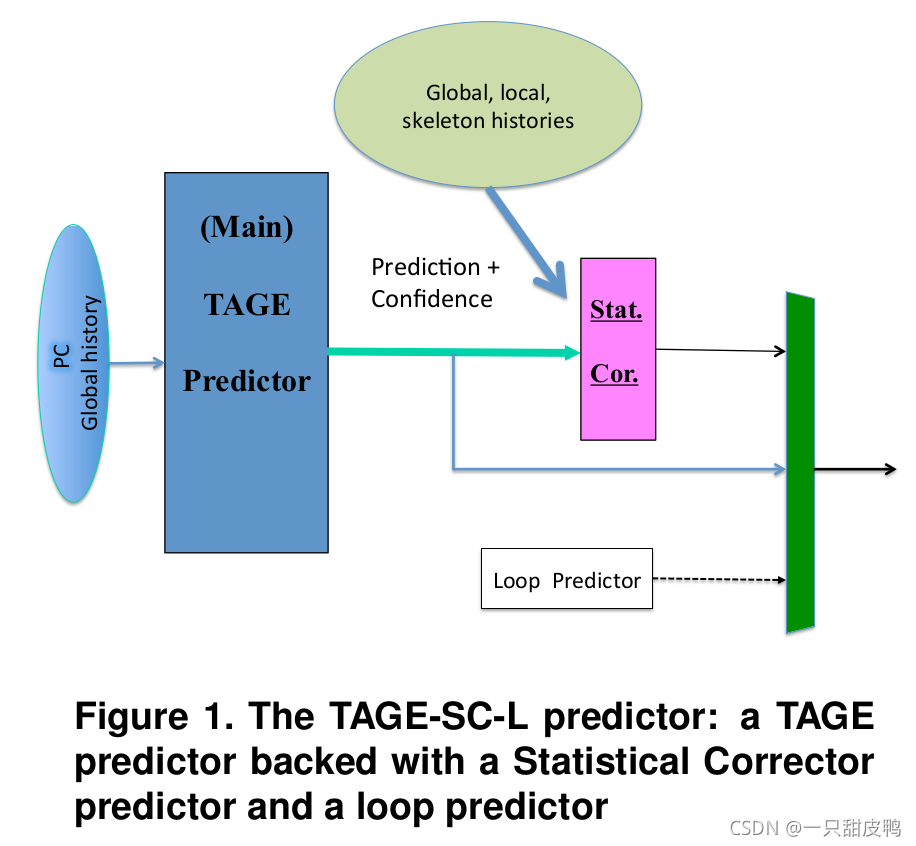
TAGE + 简单的辅助预测器统计校正器(statistical corrector简称SC)+ 循环预测器(loop predictor简称L)
- 为什么要用不同长度的历史?
既适用于有较长历史的分支可以利用足够多的历史,又可以为历史较短的分支或等待 warm up 的过程提供预测,当没有较长历史时仍可以采用已有的历史进行预测。
- 为什么要用几何长度的历史?
- 为什么用部分标记匹配而不是加法树?
对于使用几何序列历史长度的预测器,部分标记匹配比加法树更具成本效益。
- 用于索引预测表的信息
分支地址、全局历史、路径历史
为了限制分支别名效应,在分支历史中包括一些非条件分支历史,或记录分历史。分支别名影响随历史长度的增加而减小。
- 为什么要及时更新预测表?
在处理器中,硬件预测器表在指令退休时更新,以避免被错误路径污染。每个在正确路径上的分支访问3次预测期表:预测时读、退休时读、退休时写,如此大量的访问可能会导致非常昂贵的分支预测结构。
- 为什么要为循环专用循环预测器?
TAGE预测周期性的有规律的分支行为通常有效,即使周期长度横跨数百甚至数千个分支。但如果一个循环体内的控制流路径是不规律的,TAGE不能很好的预测循环退出分支。而循环预测器能够通过迭代的次数更加有效地跟踪循环,因此预测这些循环的退出分支非常有效。
- 为什么要用统计校正预测器?
一些应用上,一些分支行为与分支历史或路径相关性较弱,表现出一个统计上的预测偏向性。对于这些分支,相比TAGE,使用计数器捕捉统计偏向的方法更为有效。
- 为什么要使用局部历史?
在一些应用中,有一些分支使用局部历史比使用全局历史能够进行更好的预测。将SC中的全局历史替换为局部历史提供了一种平稳地将TAGE和局部预测器结合起来的方法。
存储预算
- 在32Kbits存储预算下,TAGE预测器使用大部分存储预算,只有非常有限的存储预算可以给辅助预测器。在CBP-4 trace下性能达到3.315MPKI。
- 在256Kbits存储预算下,可以实现具有TAGE预测器循环预测其LP和相当复杂的统计校正器SC。在CBP-4 trace下性能达到2.365MPKI。
- 在无限制存储预算下,可以实现更为复杂的统计校正器。在CBP-4 trace下性能达到1.782MPKI。
结构特点
- TAGE:预测计数器(3-bits)、有用计数器(2-bits)、
- TAGE预测器提供主预测,预测算法与之前相同,然后统计校正器对该预测进行确认或者恢复。
- 在相似的情况下(预测、分支历史、分支置信度)TAGE统计预测错误时,统计预测器进行预测。
- 循环预测器对于预测具有长循环体的规则循环很有用。
- Hysteresis bit:为了节省存储空间,迟滞位由多个计数器共享。
Tag宽度
- 使用较大的标签宽度会浪费部分存储空间,而使用过小的标签宽度会导致错误的标签匹配检测。
- 对于提交的有限大小的预测器,在所有表上增加1位的标签宽度将导致不显著的准确性益处,而减少该宽度将导致大约1%的误预测率增加。
更新TAGE预测器
- 预测正确时:更新provider component的预测计数器,若预测可信度较低,则同时更新alternate provider。
- 预测错误时:
- 更新provider component;
- 分配新项:如果提供预测的不是具有最长历史的组件,则需在比提供预测组件历史更长的且u-bit为空的组件中分配新项。对于有限大小的预测器,对于中到大数量的TAGE表,分配两项比一项更好(预测器预热更快),但对于一个32Kbits的预测器,当误预测率高时,应避免分配许多项(避免污染)。因此,实际中根据预测失误动态决定要分配的项的数量。
- 更新u-bit:当实际预测是正确的并且alternate prediction是不正确的,provider component的有用计数器u就递增。
理解u-bit的更新:当altpred 和 provider 预测相同时,说明没有必要用历史更长的provider,用前者预测就足够,因此不增加其有用计数器;当二者不同且后者正确时,说明provider是有用且必要的,因此增加其有用计数器。
- u-bit策略:在分配新项时,动态监控预测失误后尝试分配新项的成功和失败次数,这种监控通过一个名为TICK的计数器实现。预测失误时,相关项的u-bit可能递会减,而递减的概率随着TICK计数器值的增加而增加。
+ IUM:The Immediate Update Mimicker
思想:使用正在执行的还未结束的分支的信息进行预测,以减少因更新延迟而带来的错误预测。
(实验证明,IUM几乎可以恢复所有由于更新延迟导致的错误预测。)
例如,如果为分支B提供预测的表和表项,与已经执行了但还没有退休的分支B'所用的表和表项相同,就直接使用B'的执行结果作为预测,而不使用预测表的预测。
当取到一条条件分支时,IUM记录该分支的预测,TAGE预测器中提供预测的条目 E 的身份(即表号及其索引)。当分支解决预测错误时候,IUM通过重初始化其头指针到相关IUM项且用正确的方向更新该项(指的是IUM 中与该分支相关的项)进行修复。
当在正确的路径上取指时,与执行中分支 B 相关联的 IUM 项具有匹配的预测器条目 E,预测器中的项提供了 TAGE 预测,而IUM 中的项提供了分支 B 的有效结果(如上段所述在错误预测后已被更新)。此时如果在该指令退休前又出现一次分支B,则此时(TAGE预测器+IUM)的结构可以由IUM提供正确的方向而不适TAGE的方向(TAGE预测器中对应项还未更新,提供的预测是错的)。
+ 循环预测器
- 当整个循环体以相同的迭代次数连续执行7次且达到一定置信度时,循环预测器提供全局预测。
- 循环预测器每一项由10-bit的过去迭代计数、10-bit的退出迭代计数、10-bit的tag、3-bit的置信度计数器、3-bit age计数器和1-bit方向位组成,每项37位。
- 替换政策基于age计数器:一项只有在age计数器为空时会被替换。Age计数器首先置为7,若某项是一个可能的替换目标,age计数器就递减;当某项被使用 且 提供了有效预测 且 如果没有循环预测器就会预测错误时,age计数器递增;当分支被确定不是常规循环时,age被重置为0。
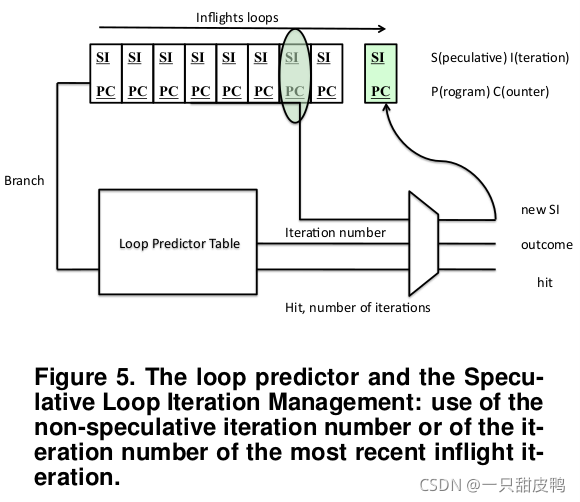
- 循环预测器的整体硬件复杂性不在预测器本身,而在于迭代次数的推测管理。
为什么需要对迭代次数进行推测管理:
可能出现上次循环分支还未更新迭代次数,该循环的另一个分支实例已经开始预测,则此时获取到的当前迭代次数是实际迭代次数-1,对于循环内的分支并不会有影响,但对于跳出循环的分支,将会做出错误预测。因此,需要在当前循环分支预测时(下个分支实例预测前)就对当前迭代次数进行更新,最简单的方法是立即更新表中的当前迭代计数器,即每次预测时就更新(而非执行结果出来后)。
上述立即更新带来的问题是,当该分支预测错误时,需要对循环预测表进行恢复,不止恢复该循环所对应的项,甚至包括其他循环所对应的项。因为在该分支结果出来之前,可能已经对其他循环分支进行了预测,并立即更新了循环预测表的表项。但这种恢复并不容易。
论文里提出的这种推测管理方法可以则有效地降低预测错误时恢复的难度。
- SLIM(Speculative Loop Iteration Manager):每个识别为循环的分支分配一个新项,每项中记录着分支PC和推测的当前迭代次数。 在预测时,会检查循环预测器。 在高置信度命中时,预测表中当前迭代的(非推测性)次数和循环总迭代次数被读取,并同时读取SLIM 上的推测迭代次数。 如果分支也在 SLIM 中命中,则由SLIM 提供当前迭代次数,与总迭代次数进行比较,提供预测结果,同时把SLIM 中该项移动到队首。 在错误预测时,错误预测分支(PC匹配)后的所有 SLIM 项将被清除。 在循环退出时,其相关联的 SLIM 项被清除。
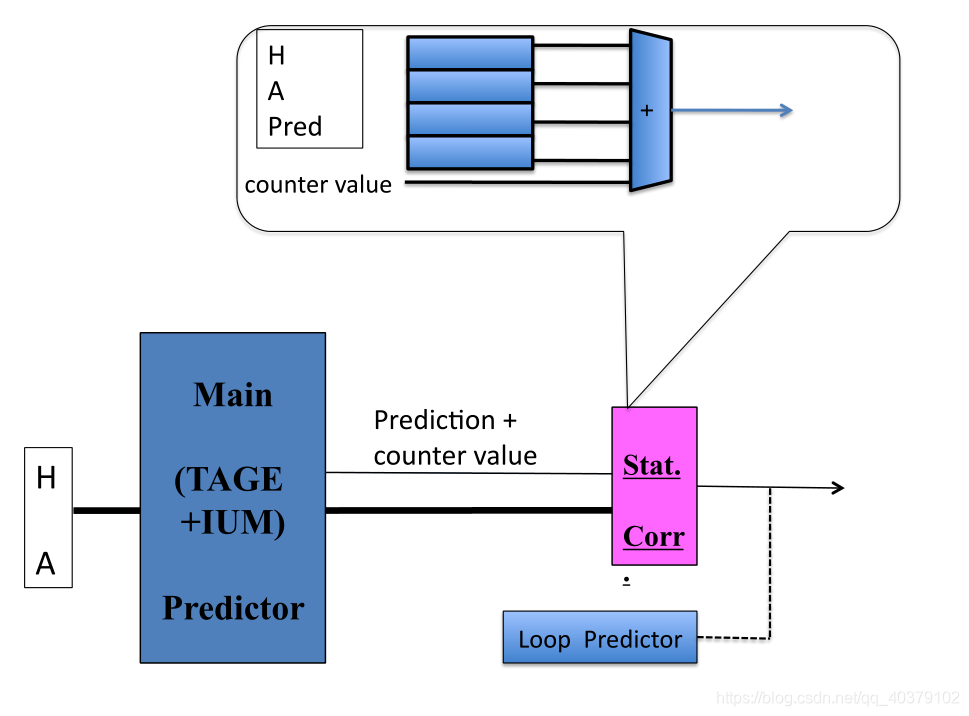
+ 统计校正预测器
- TAGE在预测非常相关的分支时非常有效,TAGE未能预测有统计偏向的分支,例如只对一个方向有小偏差,但与历史路径没有强相关性的分支。
- 统计校正的目的是检测不太可能的预测并将其恢复,来自TAGE的预测以及分支信息(地址、全局历史、全局路径、局部历史)被呈现给统计校正预测器,其决定是否反转预测。
A. 对于32Kbits的预测器
使用校正过滤器,实际上是一个关联表,用于监控来自TAGE的错误预测,预测失误(PC和预测方向)以低概率存储在关联表中。命中校正过滤器时,如果某项指示以高置信度恢复预测,则预测被反转,但校正过滤器不会反转从TAGE流出的高置信度的分支。
B. 对于256Kbits的预测器
MGSC(multi-GEHL SC):由6个组件组成,1个偏置组件和5个GEHL-like组件。
- 偏置组件:由PC和TAGE预测方向索引。由两个用不同哈希函数进行索引的表组成;当分支B在方向D上被预测时,并且已经观察到在大多数类似的情况下,B被错误预测,则偏置组件将指示恢复预测。
- 5个GEHL-like组件:分别使用全局条件分支历史(4个表)、返回堆栈相关分支历史(4个表)、一个256项局部历史(3个表)和2个16项局部历史(4个表和3个表)进行索引。其中全局条件分支历史组件在其索引中还使用TAGE输出。
Q:5个GEHL-like 组件的意思是每个都是一个类似GEHL的组件,每个都包括几张表?
A:好像 是的。
- 返回堆栈相关分支历史:历史存储在与调用相同的返回堆栈中。在调用时,堆栈的顶部被复制到堆栈中新分配的条目上,在相关的返回之后,分支历史记录反映了调用之前执行的分支。这允许捕获在被调用函数的执行过程中可能丢失的一些相关性。
- 预测计算:统计校正预测器表上的预测结果之和的符号,加上GEHL表数量乘以方向(+1或-1)的两倍。(不确定是不是这么回事儿)
- MGSC预测表使用动态阈值策略进行更新,使用一个PC索引的动态阈值表。
256Kbits TAGE-SC-L 性能评估
相比 256Kbits L-TAGE,降低6.8%的误预测率,其中统计校正预测器所占存储不超过46Kbits。
采用没有预算限制的校正预测器时,相比256K bits L-TAGE 可以降低超过20%的误预测率。

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









