







刚学习PYQT,这里需要用Python进行数据 通信,有几个常用功能。我们的上位机软件里的变量往往都是整型、浮点型、字符串等等,但是我们在数据传输的过程中,往往需要的是ByteArray格式。
这里有两组非常重要的方法:struct.pack()和struct.unpack,以及encode()和decode();
下面逐一进行讲解:
struct.pack个人感觉常用于数值型。
struct.pack用于将Python的值根据格式符,转换为字符串(因为Python中没有字节(Byte)类型。
可以把这里的字符串理解为字节流,或字节数组。
其函数原型为:struct.pack(fmt, v1, v2, …),
参数fmt是格式字符串,关于格式字符串的相关信息在下面有所介绍。
v1, v2, …表示要转换的python值。下面的例子将两个整数转换为字符串(字节流):
import struct
a = 20
b = 400
str = struct.pack("ii", a, b) #转换后的str虽然是字符串类型,但相当于其他语言中的字节流(字节数组),可以在网络上传输
print 'length:', len(str)
print str
print repr(str)
#---- result
#length: 8
# 乱码
#'/x14/x00/x00/x00/x90/x01/x00/x00'
格式符"i"表示转换为int,'ii’表示有两个int变量。进行转换后的结果长度为8个字节(int类型占用4个字节,两个int为8个字节),可以看到输出的结果是乱码。因为结果是二进制数据,所以显示为乱码。可以使用python的内置函数repr来获取可识别的字符串,其中十六进制的0x00000014, 0x00001009分别表示20和400。用的小端法。
struct.unpack
struct.unpack做的工作刚好与struct.pack相反,用于将字节流转换成python数据类型。它的函数原型为:struct.unpack(fmt, string),该函数返回一个元组。 下面是一个简单的例子:
str = struct.pack("ii", 20, 400)
a1, a2 = struct.unpack("ii", str)
print 'a1:', a1
print 'a2:', a2
#---- result:
#a1: 20
#a2: 400
encode()函数个人感觉常用语字符串型。
Python3严格区分文本(str)和二进制数据(Bytes),文本总是Unicode,用str类型,二进制数据则用Bytes类型表示,这样严格的限制也让我们对如何使用它们有了清晰的认识。
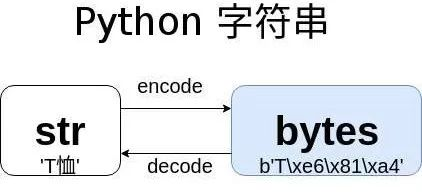
描述:以指定的编码格式编码字符串,默认编码为 ‘utf-8’。
语法:str.encode(encoding=‘utf-8’, errors=‘strict’) -> bytes (获得bytes类型对象)
encoding 参数可选,即要使用的编码,默认编码为 ‘utf-8’。字符串编码常用类型有:utf-8,gb2312,cp936,gbk等。
errors 参数可选,设置不同错误的处理方案。默认为 ‘strict’,意为编码错误引起一个UnicodeEncodeError。 其它可能值有 ‘ignore’, ‘replace’, 'xmlcharrefreplace’以及通过 codecs.register_error() 注册其它的值。
str1 = "我爱祖国"
str2 = "I love my country"
print("utf8编码:",str1.encode(encoding="utf8",errors="strict")) #等价于print("utf8编码:",str1.encode("utf8"))
print("utf8编码:",str2.encode(encoding="utf8",errors="strict"))
print("gb2312编码:",str1.encode(encoding="gb2312",errors="strict"))#以gb2312编码格式对str1进行编码,获得bytes类型对象的str
print("gb2312编码:",str2.encode(encoding="gb2312",errors="strict"))
print("cp936编码:",str1.encode(encoding="cp936",errors="strict"))
print("cp936编码:",str2.encode(encoding="cp936",errors="strict"))
print("gbk编码:",str1.encode(encoding="gbk",errors="strict"))
print("gbk编码:",str2.encode(encoding="gbk",errors="strict"))
utf8编码: b'\xe6\x88\x91\xe7\x88\xb1\xe7\xa5\x96\xe5\x9b\xbd'
utf8编码: b'I love my country'
gb2312编码: b'\xce\xd2\xb0\xae\xd7\xe6\xb9\xfa'
gb2312编码: b'I love my country'
cp936编码: b'\xce\xd2\xb0\xae\xd7\xe6\xb9\xfa'
cp936编码: b'I love my country'
gbk编码: b'\xce\xd2\xb0\xae\xd7\xe6\xb9\xfa'
gbk编码: b'I love my country'
a = '编码测试'
#使用不同的编码格式给a进行编码
b = a.encode('utf-8')
c = a.encode('gb2312') #发现gb2312和gbk结果一样
d = a.encode('gbk')
print(type(b),b)
print(type(c),c)
print(type(d),d)
'''
<class 'bytes'> b'\xe7\xbc\x96\xe7\xa0\x81\xe6\xb5\x8b\xe8\xaf\x95'
<class 'bytes'> b'\xb1\xe0\xc2\xeb\xb2\xe2\xca\xd4'
<class 'bytes'> b'\xb1\xe0\xc2\xeb\xb2\xe2\xca\xd4'
'''
#使用不同的解码方式解码
b1 = b.decode('utf-8')
c1 = c.decode('gb2312')
d1 = d.decode("gbk")
b11 = b.decode('gbk') #b本来是用utf-8编码,现在用gbk进行解码,出现乱码的情况
print(type(b1),b1)
print(type(c1),c1)
print(type(d1),d1)
print(type(b11),b11) #b本来是用utf-8编码,现在用gbk进行解码,出现乱码的情况
'''
<class 'str'> 编码测试
<class 'str'> 编码测试
<class 'str'> 编码测试
<class 'str'> 缂栫爜娴嬭瘯
'''















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









