









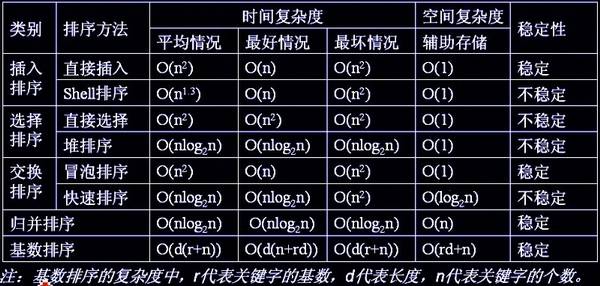
插入排序:
直接插入:
思想:
假设待排序的记录存放在数组R[1..n]中。初始时,R[1]自成1个有序区,无序区为R[2..n]。从i=2起直至i=n为止,依次将R[i]插入当前的有序区R[1..i-1]中,生成含n个记录的有序区。
ways1:
void insertSort1(int arr[], int len)
{
int i;//未排序序列带排序的元素下标
int j;//已排序序列最大元素的下标
int temp;
for (i = 1; i < len; ++i)
{
temp = arr[i];
for (j = i - 1; j >= 0; --j)
{
if (arr[j] > temp)
{
arr[j + 1] = arr[j];
}
else
{
break;
}
}
arr[j + 1] = temp;
}
}
ways2:
void insertSort(int arr[], int len)
{
int i;//未排序序列带排序的元素下标
int j;//已排序序列最大元素的下标
int temp;
for (i = 1; i < len; ++i)
{
temp = arr[i];
for (j = i - 1; j >= 0 && arr[j] > temp; --j)
{
arr[j + 1] = arr[j];
}
arr[j + 1] = temp;
}
}希尔排序:
思想:
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
该方法实质上是一种分组插入方法。
void shell(int arr[], int len, int dk)
{
int i, j;
int temp;
for (i = dk; i < len; ++i)
{
temp = arr[i];
for (j = i - dk; j >= 0 && arr[j] > temp; j -= dk)
{
arr[j + dk] = arr[j];
}
arr[j + dk] = temp;
}
}
void shellSort(int arr[], int arrlen, int dka[], int dkalen)
{
//dka[]为增量数组,dkalen为增量数组的长度
for (int i = 0; i < dkalen; ++i)
{
shell(arr, arrlen, dka[i]);
}
}选择排序:
简单选择排序:
n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果:
内层循环实现在无序数组中找到其最值,外层循环,控制循环次数
void selectSort(int arr[], intlen)
{
inti, j;
intmin; //待排序数组中最小值的下标
inttmp;
for(i = 0; i < len - 1; ++i)
{
min= i;
for(j = i + 1; j < len; ++j)
{
if(arr[j] < arr[min])
{
min= j;
}
}
tmp= arr[i];
arr[i]= arr[min];
arr[min]= tmp;
}
}
堆排序:
思想:
n个关键字序列Kl,K2,…,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质):
(1) ki≤K2i且ki≤K2i+1 或(2)Ki≥K2i且ki≥K2i+1(1≤i≤![]() )
)
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
void HeapAdjust(int *arr,int start,int end)
{
int tmp = arr[start];
int parent = start;
for(int i=2*start+1;i<=end; i=2*i+1)//O(log n)
{
if((i+1)<=end && arr[i]<arr[i+1])//找到左右孩子的较大值
{
i++;
}//i表示左右孩子较大值的下标
if(tmp < arr[i])//孩子大于父,需要更新到父的位置
{
arr[parent] = arr[i];
parent = i;
}
else
{
break;
}
}
arr[parent] = tmp;
}
void HeapSort(int *arr,int len)//O(nlog n),O(1)
{
//第一次建大根堆
int i;
for(int i=(len-1-1)/2;i>=0;i--)//O(nlog n)
{
HeapAdjust(arr,i,len-1);
}
int tmp;
for(i=0;i<len-1;i++)//O(nlog n)
{
tmp = arr[0];
arr[0] = arr[len-1-i];
arr[len-1-i] = tmp;
HeapAdjust(arr,0,len-1-i-1);
}
}交换排序:
冒泡排序(优化后):
内部循环再走一遍,若无数据交换,说明数组已有序,直接退出循环
void BubbleSort(int arr[], int len)
{
int i, j;
int tmp;
int mark = 0;//标志位
for (i = 0; i < len - 1; ++i)
{
mark = 0;
for (j = 0; j < len - 1 - i; ++j)
{
if (arr[j] > arr[j + 1])
{
tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
mark = 1;
}
}
printf("%d\n", i);
if (mark == 0)
{
break;
}
}
}void Merge(int arr[], int tmp[],int startIndex, int midIndex, int endIndex)
{
int leftIndex = startIndex;
int rightIndex = midIndex + 1;
int tmpIndex = startIndex;
while (leftIndex < midIndex + 1 && rightIndex < endIndex + 1)
{
if (arr[leftIndex] > arr[rightIndex])
{
tmp[tmpIndex++] = arr[rightIndex++];
}
else
{
tmp[tmpIndex++] = arr[leftIndex++];
}
}
while (leftIndex < midIndex + 1)
{
tmp[tmpIndex++] = arr[leftIndex++];
}
while (rightIndex < endIndex + 1)
{
tmp[tmpIndex++] = arr[rightIndex++];
}
for (int i = startIndex; i < endIndex + 1; ++i)
{
arr[i] = tmp[i];
}
}
void MyMerge(int arr[], int tmp[],int startIndex, int endIndex)
{
if (startIndex < endIndex)
{
int midIndex = (endIndex + startIndex) / 2;
MyMerge(arr, tmp, startIndex, midIndex);
MyMerge(arr, tmp, midIndex + 1, endIndex);
Merge(arr,tmp,startIndex,midIndex,endIndex);
}
}
void MergeSort(int arr[], int len)
{
int *tmp = (int*)malloc(sizeof(int)*len);
MyMerge(arr, tmp, 0, len - 1);
}int FindMaxDigit(int arr[], int len)
{
int maxnumber = arr[0];
for (int i = 1; i < len; ++i)
{
if (arr[i] > maxnumber)
{
maxnumber = arr[i];
}
}
int count = 0;
while (maxnumber != 0)
{
maxnumber /= 10;
count++;
}
return count;
}
/*
digit :
0 个位
1 十位
num /10^0 %10;
num / 10^1 %10;
num / 10^2 %10;
double pow(double,int)
(int)pow(10.0,digit);
*/
int FindNumberDigit(int num, int digit)
{
return num / (int)pow(10.0, digit) % 10;
}
void Radix(int arr[], int **bucket,
int len, int digit)
{
//每个桶中现有的元素的个数
int count[10] = { 0 };
for (int i = 0; i < len; ++i)
{
int digitnumber = FindNumberDigit(arr[i], digit);
bucket[digitnumber][count[digitnumber]] = arr[i];
count[digitnumber]++;
}
int index = 0;
for (int j = 0; j < 10; ++j)
{
for (int k = 0; k < count[j]; ++k)
{
arr[index++] = bucket[j][k];
}
}
}
void RadixSort(int arr[], int len)
{
int** bucket = (int **)malloc(sizeof(int*)* 10);
for (int j = 0; j < 10; ++j)
{
bucket[j] = (int *)malloc(sizeof(int)*len);
}
int maxdigit = FindMaxDigit(arr, len);
for (int i = 0; i < maxdigit; ++i)
{
Radix(arr,bucket,len,i);
}
for (int j = 0; j < 10; ++j)
{
free(bucket[j]);
}
free(bucket);
}快速排序:
两端扫描,一端挖坑,另一端填补
基本思想,使用两个变量i和j,i指向最左边的元素,j指向最右边的元素,我们将首元素作为中轴,将首元素复制到变量pivot中,这时我们可以将首元素i所在的位置看成一个坑,我们从j的位置从右向左扫描,找一个小于等于中轴的元素A[j],来填补A[i]这个坑,填补完成后,拿去填坑的元素所在的位置j又可以看做一个坑,这时我们在以i的位置从前往后找一个大于中轴的元素来填补A[j]这个新的坑,如此往复,直到i和j相遇(i == j,此时i和j指向同一个坑)。最后我们将中轴元素放到这个坑中。最后对左半数组和右半数组重复上述操作。
public static void QuickSort2(int[] A, int L, int R){
if(L < R){
//最左边的元素作为中轴复制到pivot,这时最左边的元素可以看做一个坑
int pivot = A[L];
//注意这里 i = L,而不是 i = L+1, 因为i代表坑的位置,当前坑的位置位于最左边
int i = L, j = R;
while(i < j){
//下面面两个循环的位置不能颠倒,因为第一次坑的位置在最左边
while(i < j && A[j] > pivot){
j--;
}
//填A[i]这个坑,填完后A[j]是个坑
//注意不能是A[i++] = A[j],当因i==j时跳出上面的循环时
//坑为i和j共同指向的位置,执行A[i++] = A[j],会导致i比j大1,
//但此时i并不能表示坑的位置
A[i] = A[j];
while(i < j && A[i] <= pivot){
i++;
}
//填A[j]这个坑,填完后A[i]是个坑,
//同理不能是A[j--] = A[i]
A[j] = A[i];
}
//循环结束后i和j相等,都指向坑的位置,将中轴填入到这个位置
A[i] = pivot;
QuickSort2(A, L, i-1);//递归左边的数组
QuickSort2(A, i+1, R);//递归右边的数组
}
}















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









