











css
flex
对于某个元素只要声明了display: flex;,那么这个元素就成为了弹性容器,具有flex弹性布局的特性。
每个弹性容器都有两根轴:主轴和交叉轴,两轴之间成90度关系。注意:水平的不一定就是主轴。

flex-direction
我们可以在弹性容器上通过flex-direction修改主轴的方向




flex-wrap
通过设置flex-wrap: nowrap | wrap | wrap-reverse可使得主轴上的元素不折行、折行、反向折行。
一个复合属性
flex-flow = flex-drection + flex-wrap
flex-flow相当于规定了flex布局的“工作流(flow)”
flex-flow: row nowrap;弹性伸缩
flex-shrink:缩小比例(容器宽度<元素总宽度时如何收缩)flex-grow:放大比例(容器宽度>元素总宽度时如何伸展)
flex-shrink: 缩小比例
实际上,flex-shrink默认为1,也就是当不够分配时,元素都将等比例缩小,占满整个宽度,如下图。

#container {
display: flex;
flex-wrap: nowrap;
flex-shrink:1
}flex-grow: 放大比例
在flex布局中,容器剩余宽度默认是不进行分配的,也就是所有弹性元素的flex-grow都为0。
通过指定flex-grow为大于零的值,实现容器剩余宽度的分配比例设置。

flex-basis
flex-basis设置的是元素在主轴上的初始尺寸,所谓的初始尺寸就是元素在flex-grow和flex-shrink生效前的尺寸。
- 与width/height的区别
<div id="container">
<div>11111</div>
<div>22222</div>
</div>
- width: 0 —— 完全没显示
- flex-basis: 0 —— 根据内容撑开宽度

- width: 非0;
- flex-basis: 非0
—— 数值相同时两者等效
—— 同时设置,flex-basis优先级高

常用的复合属性 flex
flex = flex-grow + flex-shrink + flex-basis
flex: 1 = flex: 1 1 0%
flex: 2 = flex: 2 1 0%
flex: auto = flex: 1 1 auto;
flex: none = flex: 0 0 auto; // 常用于固定尺寸 不伸缩justify-content

align-items






order:更优雅地调整元素顺序

#container > div:first-child {
order: 2;
}
#container > div:nth-child(2) {
order: 4;
}
#container > div:nth-child(3) {
order: 1;
}
#container > div:nth-child(4) {
order: 3;
}
order:可设置元素之间的排列顺序
- 数值越小,越靠前,默认为0
- 值相同时,以dom中元素排列为准
垂直水平居中方案
- 方案一
div.box{
weight:200px;
height:400px;
<!--把元素变成定位元素-->
position:absolute;
<!--设置元素的定位位置,距离上、左都为50%-->
left:50%;
top:50%;
<!--设置元素的左外边距、上外边距为宽高的负1/2-->
margin-left:-100px;
margin-top:-200px;
}- 方案二
div.box{
width:200px;
height:400px;
<!--把元素变成定位元素-->
position:absolute;
<!--设置元素的定位位置,距离上、下、左、右都为0-->
left:0;
right:0;
top:0;
bottom:0;
<!--设置元素的margin样式值为 auto-->
margin:auto;
}- 方案三
div.box{
display: flex;
justify-content: center;
align-items: center;
}Javascript
数据类型有哪些?
字符串 string、数字 number、布尔 boolean、空 null、undefined、对象 object
理解基础类型与引用类型
基础类型
- 基本数据类型值不可变
- 存放在栈内存中的简单数据段,数据大小确定,内存空间大小可以分配,是直接按值存放的,所以可以直接访问
var str = "abc";
console.log(str[1]="f"); // f
console.log(str); // abc引用类型
引用类型(object)是存放在堆内存中的,变量实际上是一个存放在栈内存的指针,这个指针指向堆内存中的地址。每个空间大小不一样,要根据情况开进行特定的分配。
引用类型是可以直接改变其值的,例如:
var a = [1,2,3];
a[1] = 5;
console.log(a[1]); // 5引用类型的比较是引用的比较
所以每次我们对 js 中的引用类型进行操作的时候,都是操作其对象的引用(保存在栈内存中的指针),所以比较两个引用类型,是看其的引用是否指向同一个对象。例如:
var a = [1,2,3];
var b = [1,2,3];
console.log(a === b); // false虽然变量 a 和变量 b 都是表示一个内容为 1,2,3 的数组,但是其在内存中的位置不一样,也就是说变量 a 和变量 b 指向的不是同一个对象,所以他们是不相等的。

关于栈和堆理解
- 栈(stack)是后进先出,堆(heap)是先进先出。
- 栈(stack)内存是我们手动分配, 堆(heap)内存是自动分配。
数组与字符串互转
数组变字符串
var a = [];
var b = '';
a=new Array{0,1,2,3,4,5};
b=a.join(“-”); //b="0-1-2-3-4-5" 字符串变数组
var b="0-1-2-3-4-5";
var a=b.split("-"); //在-分解 什么是原型
JavaScript 中,万物皆对象!但对象也是有区别的。分为普通对象和函数对象,Object ,Function 是JS自带的函数对象。每个对象都有原型(null和undefined除外),你可以把它理解为对象的默认属性和方法。
你可以把下面的代码在浏览器打印出来看一下。
console.log(Object.prototype);
//Object{}
var o = new Object();
console.log(o.prototype); //undefined
console.log(Array.prototype);
//[Symbol(Symbol.unscopables): Object]
console.log(Function.prototype);
//function(){}
function hello(){
console.log("hello");
}
hello.prototype = "hello world";
console.log(hello.prototype);
//hello worldObject:Object是一个函数对象,Object的原型就是一个Object对象,它里面存在着一些对象的方法和属性,例如最常见的toString方法。
新建对象:用new Object或者{}建的对象是普通对象,它没有prototype属性,只有__proto__属性,它指向Object.prototype。
Array:Array也是一个函数对象,它的原型就是Array.prototype,它里面存在着一些数组的方法和属性,例如常见的push,pop等方法。
Function:Function也是一个函数对象,但它有点特殊,它的原型就是一个function空函数。
自定义函数:它的原型就是你给它指定的那个东西。如果你不指定,那它的原型就是一个Object.prototype。
什么是原型链
在JavaScript 中,每个对象都有一个指向它的原型(prototype)对象的内部链接。这个原型对象又有自己的原型,直到某个对象的原型为 null 为止(也就是不再有原型指向),组成这条链的最后一环。这种一级一级的链结构就称为原型链(prototype chain)。
JavaScript 对象是动态的属性“包”(指其自己的属性)。JavaScript 对象有一个指向一个原型对象的链。当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依此层层向上搜索,直到找到一个名字匹配的属性或到达原型链的末尾。
var o = {
a:1,
b:2
};
console.log(o.toString());
//不报错,o上没有toString方法,但是Object上有
console.log(o.push("c"));
//报错,o上没有这个方法,Object上也没有这个方法。
console.log(o.a); //1
console.log(o.c); //undefined当你用new Object或者直接定义一个对象时,它的原型链就是:
o ==》 Object.prototype ==》 null但你访问o上没有的属性或方法时,JS会往Object.prototype上寻找该属性和方法。如果有则直接返回,如果没有,方法则报错,这个方法未定义,属性则返回undefined。
function Person(name){
this.name = name;
}
Person.prototype = {age:24};
var tsrot = new Person("tsrot");
console.log(tsrot.name); //tsrot
console.log(tsrot.age); //24
console.log(tsrot.toString()); //[object Object]当你用构造函数(构造函数我们一般首字母大写)建立一个对象时,它的原型链就是:
tsrot ==》 Person.prototype ==》 Object.prototype ==》 nullprototype、__proto__
var objs = new Object()
objs.__proto__ === Object.prototype // true objs.__proto__ 指向构造函数的prototype属性用原型怎么去扩展其他的方法
分析:由于扩展原始对象的方法,我们就必须在原型链(prototype)上面添加方法了
Array.prototype.sum = function() {
var result = 0; //此处必须要赋值一个0,不能为空,否则会返回NaN
for(var i = 0; i < this[length]; i++){
reslut += this[i]; //这里需要注意的是arguments已经不能使用了,要用this。
}
}
// 我们可以随便声明一个数组去求和!
let test = [1,2,34,5,6];
console.log(test.sum()); 检测数据类型
typeof
console.log(typeof ""); // string
console.log(typeof 1); // number
console.log(typeof true); // boolean
console.log(typeof null); // null
console.log(typeof undefined); // undefined
console.log(typeof []); // object
console.log(typeof function(){}); // function
console.log(typeof {}); // object
instanceof
console.log("1" instanceof String); // false
console.log(1 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); //true
console.log({} instanceof Object); // true可以看到前三个都是以对象字面量创建的基本数据类型,但是却不是所属类的实例,这个就有点怪了。后面三个是引用数据类型,可以得到正确的结果。如果我们通过new关键字去创建基本数据类型,你会发现,这时就会输出true,如下:
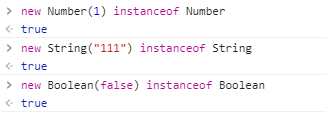
接下再来说说为什么null和undefined为什么比较特殊,实际上按理来说,null的所属类就是Null,undefined就是Undefined,但事实并非如此:控制台输出如下结果:
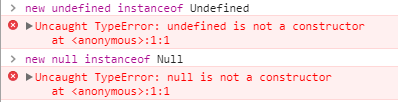
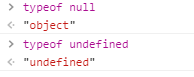
浏览器压根不认识这两货,直接报错。在第一个例子你可能已经发现了,typeof null的结果是object,typeof undefined的结果是undefined
constructor
console.log(("1").constructor === String); // true
console.log((1).constructor === Number); // true
console.log((true).constructor === Boolean); // true
console.log(([]).constructor === Array); // true
console.log((function() {}).constructor === Function); // true
console.log(({}).constructor === Object); // true(这里依然抛开null和undefined)乍一看,constructor似乎完全可以应对基本数据类型和引用数据类型,都能检测出数据类型,事实上并不是如此,来看看为什么:
function Fn(){};
Fn.prototype=new Array();
var f=new Fn();
console.log(f.constructor===Fn); // false
console.log(f.constructor===Array); // true我声明了一个构造函数,并且把他的原型指向了Array的原型,所以这种情况下,constructor也显得力不从心了。
看到这里,是不是觉得绝望了。没关系,终极解决办法就是第四种办法,看过jQuery源码的人都知道,jQuery实际上就是采用这个方法进行数据类型检测的。
Object.prototype.toString.call()
var a = Object.prototype.toString;
console.log(a.call("aaa"));
console.log(a.call(1));
console.log(a.call(true));
console.log(a.call(null));
console.log(a.call(undefined));
console.log(a.call([]));
console.log(a.call(function() {}));
console.log(a.call({}));
可以看到,所有的数据类型,这个办法都可以判断出来。那就有人质疑了,假如我把他的原型改动一下呢?如你所愿,我们看一下:

继承(6种方式)以及优缺点
- 原型链继承
- 构造函数继承
- 组合继承(原型链继承+构造函数继承)
- 原型式继承
- 寄生继承
- 组合寄生继承
es6继承原生构造函数(es5不能继承原生构造函数)
class CustomArray extends Array{
constructor(...args){
super(...args)
}
}
const arr = new CustomArray(3,4,5)
console.log(arr) // [3,4,5]闭包
指有权访问另一个函数作用域中的变量的函数。
//创建函数
var compareNames = createComparisonFunction("name");
//调用函数
var result = compareNames({ name: "Nicholas" }, { name: "Greg" });
//解除对匿名函数的引用(以便释放内存)
compareNames = null;通过将 compareNames 设置为等于 null解除该函数的引用,就等于通知垃圾回收例程将其清除。随着匿名函数的作用域链被销毁,其他作用域(除了全局作用域)也都可以安全地销毁了。
闭包会造成内存泄漏,就是因为它把外部的包含它的函数的活动对象也包含在自己的作用域链中了,会比一般的函数占用更多内存。
如果闭包的作用域链中保存着一个HTML 元素,那么就意味着该元素将无法被销毁
function assignHandler(){
var element = document.getElementById("someElement");
element.onclick = function(){
alert(element.id);
};
}解决办法前言已经提到过,把element.id 的一个副本保存在一个变量中,从而消除闭包中该变量的循环引用同时将element变量设为null。
function assignHandler(){
var element = document.getElementById("someElement");
var id = element.id;
element.onclick = function(){
alert(id);
};
element = null;
}this指向解析
防抖节流模式
防抖debounce与节流throttle都是控制事件处理函数执行频率的方法,当函数会进行DOM操作或者具有请求服务器等行为并且作为高频事件例如onscroll触发的事件处理函数时,就需要进行事件处理函数执行频率的控制,否则会造成大量的资源浪费致使性能下降,当然无论是防抖与节流实质上并没有减少事件触发次数,而是通过减少事件处理函数的执行次数从而提高性能。
防抖模式
非立即防抖
当持续触发事件的时候,事件处理函数是完全不执行的,等最后一次触发结束的一段时间之后,再去执行。最常见的例子就是搜索建议功能,当用户进行持续输入时,并不会请求服务器进行搜索建议的计算,直至用户输入完成后的N毫秒后才会将数据传输至后端并返回搜索建议。
实现思路:每次触发事件时都取消之前的延时调用方法并重设定时器。
function debounce(wait, funct, ...args){
var timer = null;
return () => {
clearTimeout(timer);
timer = setTimeout(() => funct(...args), wait);
}
}
window.onscroll = debounce(300, (a) => console.log(a), 1);立即防抖
当持续触发事件的时候,事件处理函数会立即执行,然后不再执行事件处理函数,直至最后一次事件触发之后的一段时间后才允许再次执行事件处理函数。
实现思路:判断是否存在定时器,没有则执行事件处理函数,然后无论是否已经存在定时器都需要重设定时器。
function debounce(wait, funct, ...args){
var timer = null;
return () => {
if(!timer) funct(...args);
clearTimeout(timer);
timer = setTimeout(() => timer = null, wait);
}
}
window.onscroll = debounce(300, (a) => console.log(a), 1);节流模式
当事件持续触发时,节流操作可以稀释事件处理函数执行频率,假设在1s内onmousemove事件触发了100次,通过节流就可以使得onmousemove事件的事件处理函数每100ms触发一次,也就是在1s内onmousemove事件的事件处理函数只执行10次。
实现思路:判断是否存在定时器,没有则执行事件处理函数并重设定时器。
function throttle(wait, funct, ...args){
var timer = null;
return () => {
if(!timer){
funct(...args);
timer = setTimeout(() => timer = null, wait);
}
}
}
window.onscroll = throttle(1000, (a) => console.log(a), 1);promise
- 什么是promise
es6提供的新的处理异步编程的解决方案。
- 为什么使用promise
支持链式调用,可以解决回调地狱问题 。
- 什么是回调地狱
回调函数嵌套调用,外部回调函数异步执行的结果是嵌套的回调执行的条件。
- 回调地狱的缺点
- 不便于阅读
- 不便于异常处理
// promise初体验
const p = new Promise((resolve) => {
resolve('成功')
}, (rejuct) => {
rejuct('失败')
})
p.then((res) => {
console.log(res) // 成功
}).catch((err)=>{
console.log(err) // 失败
})js事件循环(event loop)
js在运行中的任务,有一套收集,排队,执行的特殊机制,这种机制就是事件循环。遇到同步事件直接执行,遇到异步事件分为宏任务和微任务,如果微任务列表里有任务,先执行微任务再执行宏任务。
new关键字
new一个函数,中间发生了什么
1.开辟一个内存空间,也就是创建一个空对象,obj={}或obj=new Object()。
2.将这个新对象的_proto_属性指向它构造函数的prototype。
3.将构造函数this绑定为这个新对象,在空对象上挂在属性和方法(call或apply方式)。
4.返回这个新对象。
js为什么是单线程、任务队列
- js为什么是单线程
JavaScript的单线程,这与它的用途有关。JavaScript最初被设计用在浏览器中,作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM,这决定了它只能是单线程,否则会带来很复杂的同步问题。
- 任务队列
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
JavaScript语言的设计者意识到,这时主线程完全可以不管IO设备,挂起处于等待中的任务,先运行排在后面的任务。等到IO设备返回了结果,再回过头,把挂起的任务继续执行下去。
所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程、而进入”任务队列”(task queue)的任务,只有”任务队列”通知主线程,某个异步任务可以执行了,该任务才会进入主线程执行。
深拷贝与浅拷贝
浅拷贝
创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
- Object.assign:用于将所有可枚举属性的值从一个或多个源对象复制到目标对象。它将返回目标对象。
// saucxs
let a = {
name: "saucxs",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = Object.assign({}, a);
console.log(b);
// {
// name: "saucxs",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "saucxs",
// book: {title: "You Don't Know JS", price: "55"}
// }- 展开语法 `Spread`
// saucxs
let a = {
name: "saucxs",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = {...a};
console.log(b);
// {
// name: "saucxs",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "saucxs",
// book: {title: "You Don't Know JS", price: "55"}
// }- Array.prototype.slice方法
slice不会改变原数组,`slice()` 方法返回一个新的数组对象,这一对象是一个由 `begin`和 `end`(不包括`end`)决定的原数组的**浅拷贝**。
// saucxs
let a = [0, "1", [2, 3]];
let b = a.slice(1);
console.log(b);
// ["1", [2, 3]]
a[1] = "99";
a[2][0] = 4;
console.log(a);
// [0, "99", [4, 3]]
console.log(b);
// ["1", [4, 3]]深拷贝
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。拷贝前后两个对象互不影响。
- 利用JSON
// saucxs
let a = {
name: "saucxs",
book: {
title: "You Don't Know JS",
price: "45"
}
}
let b = JSON.parse(JSON.stringify(a));
console.log(b);
// {
// name: "saucxs",
// book: {title: "You Don't Know JS", price: "45"}
// }
a.name = "change";
a.book.price = "55";
console.log(a);
// {
// name: "change",
// book: {title: "You Don't Know JS", price: "55"}
// }
console.log(b);
// {
// name: "saucxs",
// book: {title: "You Don't Know JS", price: "45"}
// }缺点:
(1)会忽略 `undefined`
(2)会忽略 `symbol`
(3)不能序列化函数
(4)不能解决循环引用的对象
(5)不能正确处理`new Date()`
(6)不能处理正则
其中(1)(2)(3) `undefined`、`symbol` 和函数这三种情况,会直接忽略。
// saucxs
let obj = {
name: 'saucxs',
a: undefined,
b: Symbol('saucxs'),
c: function() {}
}
console.log(obj);
// {
// name: "saucxs",
// a: undefined,
// b: Symbol(saucxs),
// c: ƒ ()
// }
let b = JSON.parse(JSON.stringify(obj));
console.log(b);
// {name: "saucxs"}利用递归
var obj = {
name: "test",
desc: "origin",
sendobj: {
name: "test2",
desc: "origin2"
}
}
function copy(obj) {
let newobj = null // 接受拷贝的新对象
if(typeof(obj) == 'object' && typeof(obj) !== null) { // 判断是否是引用类型
newobj = obj instanceof Array? []: {} // 判断是数组还是对象
for(var i in obj) {
newobj[i] = copy(obj[i]) // 判断下一级是否还是引用类型
}
} else {
newobj = obj
}
return newobj
}
var obj1 = copy(obj)
obj.sendobj.name = "change"
console.log(obj1)
/*
desc: "origin"
name: "test"
sendobj: {
desc: "origin2"
name: "test2"
}
*/Vue
watch&&methods&&computed区别
Vue中的权限管理怎么做
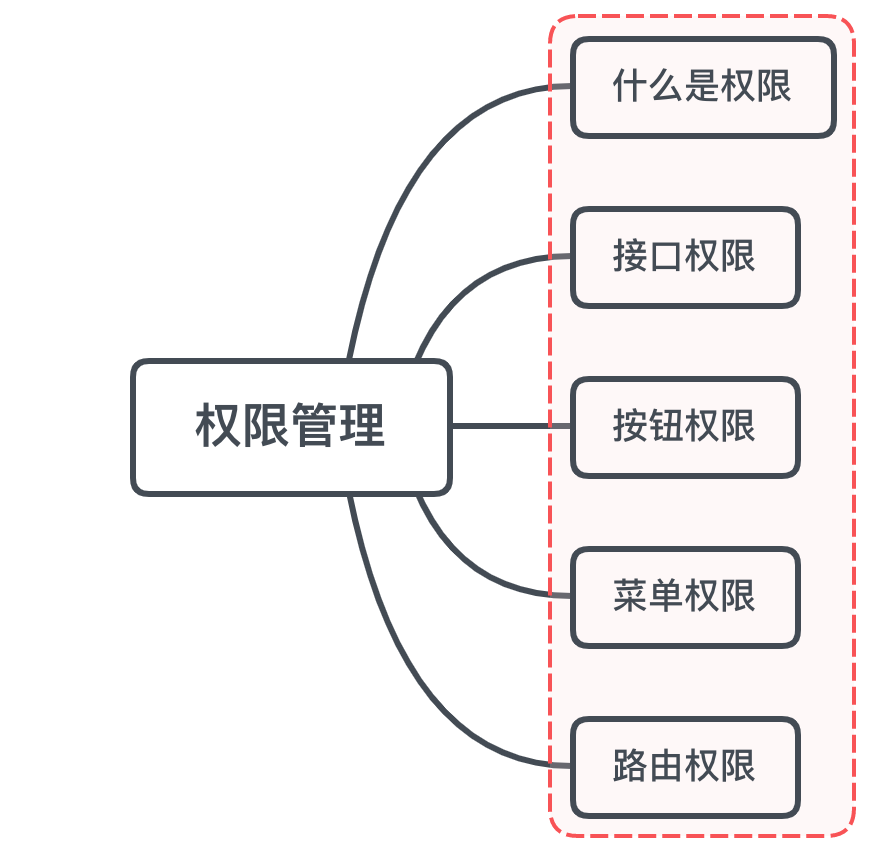
一、是什么
权限是对特定资源的访问许可,所谓权限控制,也就是确保用户只能访问到被分配的资源
而前端权限归根结底是请求的发起权,请求的发起可能有下面两种形式触发
- 页面加载触发
- 页面上的按钮点击触发
总的来说,所有的请求发起都触发自前端路由或视图
所以我们可以从这两方面入手,对触发权限的源头进行控制,最终要实现的目标是:
-
路由方面,用户登录后只能看到自己有权访问的导航菜单,也只能访问自己有权访问的路由地址,否则将跳转
4xx提示页 -
视图方面,用户只能看到自己有权浏览的内容和有权操作的控件
-
最后再加上请求控制作为最后一道防线,路由可能配置失误,按钮可能忘了加权限,这种时候请求控制可以用来兜底,越权请求将在前端被拦截
二、如何做
前端权限控制可以分为四个方面:
- 接口权限
- 按钮权限
- 菜单权限
- 路由权限
接口权限
接口权限目前一般采用jwt的形式来验证,没有通过的话一般返回401,跳转到登录页面重新进行登录
登录完拿到token,将token存起来,通过axios请求拦截器进行拦截,每次请求的时候头部携token
axios.interceptors.request.use(config => {
config.headers['token'] = cookie.get('token')
return config
})
axios.interceptors.response.use(res=>{},{response}=>{
if (response.data.code === 40099 || response.data.code === 40098) { //token过期或者错误
router.push('/login')
}
})路由权限控制
方案一
初始化即挂载全部路由,并且在路由上标记相应的权限信息,每次路由跳转前做校验
const routerMap = [
{
path: '/permission',
component: Layout,
redirect: '/permission/index',
alwaysShow: true, // will always show the root menu
meta: {
title: 'permission',
icon: 'lock',
roles: ['admin', 'editor'] // you can set roles in root nav
},
children: [{
path: 'page',
component: () => import('@/views/permission/page'),
name: 'pagePermission',
meta: {
title: 'pagePermission',
roles: ['admin'] // or you can only set roles in sub nav
}
}, {
path: 'directive',
component: () => import('@/views/permission/directive'),
name: 'directivePermission',
meta: {
title: 'directivePermission'
// if do not set roles, means: this page does not require permission
}
}]
}]这种方式存在以下四种缺点:
-
加载所有的路由,如果路由很多,而用户并不是所有的路由都有权限访问,对性能会有影响。
-
全局路由守卫里,每次路由跳转都要做权限判断。
-
菜单信息写死在前端,要改个显示文字或权限信息,需要重新编译
-
菜单跟路由耦合在一起,定义路由的时候还有添加菜单显示标题,图标之类的信息,而且路由不一定作为菜单显示,还要多加字段进行标识
方案二
初始化的时候先挂载不需要权限控制的路由,比如登录页,404等错误页。如果用户通过URL进行强制访问,则会直接进入404,相当于从源头上做了控制
登录后,获取用户的权限信息,然后筛选有权限访问的路由,在全局路由守卫里进行调用addRoutes添加路由
import router from './router'
import store from './store'
import { Message } from 'element-ui'
import NProgress from 'nprogress' // progress bar
import 'nprogress/nprogress.css'// progress bar style
import { getToken } from '@/utils/auth' // getToken from cookie
NProgress.configure({ showSpinner: false })// NProgress Configuration
// permission judge function
function hasPermission(roles, permissionRoles) {
if (roles.indexOf('admin') >= 0) return true // admin permission passed directly
if (!permissionRoles) return true
return roles.some(role => permissionRoles.indexOf(role) >= 0)
}
const whiteList = ['/login', '/authredirect']// no redirect whitelist
router.beforeEach((to, from, next) => {
NProgress.start() // start progress bar
if (getToken()) { // determine if there has token
/* has token*/
if (to.path === '/login') {
next({ path: '/' })
NProgress.done() // if current page is dashboard will not trigger afterEach hook, so manually handle it
} else {
if (store.getters.roles.length === 0) { // 判断当前用户是否已拉取完user_info信息
store.dispatch('GetUserInfo').then(res => { // 拉取user_info
const roles = res.data.roles // note: roles must be a array! such as: ['editor','develop']
store.dispatch('GenerateRoutes', { roles }).then(() => { // 根据roles权限生成可访问的路由表
router.addRoutes(store.getters.addRouters) // 动态添加可访问路由表
next({ ...to, replace: true }) // hack方法 确保addRoutes已完成 ,set the replace: true so the navigation will not leave a history record
})
}).catch((err) => {
store.dispatch('FedLogOut').then(() => {
Message.error(err || 'Verification failed, please login again')
next({ path: '/' })
})
})
} else {
// 没有动态改变权限的需求可直接next() 删除下方权限判断 ↓
if (hasPermission(store.getters.roles, to.meta.roles)) {
next()//
} else {
next({ path: '/401', replace: true, query: { noGoBack: true }})
}
// 可删 ↑
}
}
} else {
/* has no token*/
if (whiteList.indexOf(to.path) !== -1) { // 在免登录白名单,直接进入
next()
} else {
next('/login') // 否则全部重定向到登录页
NProgress.done() // if current page is login will not trigger afterEach hook, so manually handle it
}
}
})
router.afterEach(() => {
NProgress.done() // finish progress bar
})按需挂载,路由就需要知道用户的路由权限,也就是在用户登录进来的时候就要知道当前用户拥有哪些路由权限
这种方式也存在了以下的缺点:
- 全局路由守卫里,每次路由跳转都要做判断
- 菜单信息写死在前端,要改个显示文字或权限信息,需要重新编译
- 菜单跟路由耦合在一起,定义路由的时候还有添加菜单显示标题,图标之类的信息,而且路由不一定作为菜单显示,还要多加字段进行标识
菜单权限
菜单权限可以理解成将页面与路由进行解耦
方案一
菜单与路由分离,菜单由后端返回
前端定义路由信息
{
name: "login",
path: "/login",
component: () => import("@/pages/Login.vue")
}name字段都不为空,需要根据此字段与后端返回菜单做关联,后端返回的菜单信息中必须要有name对应的字段,并且做唯一性校验
全局路由守卫里做判断
function hasPermission(router, accessMenu) {
if (whiteList.indexOf(router.path) !== -1) {
return true;
}
let menu = Util.getMenuByName(router.name, accessMenu);
if (menu.name) {
return true;
}
return false;
}
Router.beforeEach(async (to, from, next) => {
if (getToken()) {
let userInfo = store.state.user.userInfo;
if (!userInfo.name) {
try {
await store.dispatch("GetUserInfo")
await store.dispatch('updateAccessMenu')
if (to.path === '/login') {
next({ name: 'home_index' })
} else {
//Util.toDefaultPage([...routers], to.name, router, next);
next({ ...to, replace: true })//菜单权限更新完成,重新进一次当前路由
}
}
catch (e) {
if (whiteList.indexOf(to.path) !== -1) { // 在免登录白名单,直接进入
next()
} else {
next('/login')
}
}
} else {
if (to.path === '/login') {
next({ name: 'home_index' })
} else {
if (hasPermission(to, store.getters.accessMenu)) {
Util.toDefaultPage(store.getters.accessMenu,to, routes, next);
} else {
next({ path: '/403',replace:true })
}
}
}
} else {
if (whiteList.indexOf(to.path) !== -1) { // 在免登录白名单,直接进入
next()
} else {
next('/login')
}
}
let menu = Util.getMenuByName(to.name, store.getters.accessMenu);
Util.title(menu.title);
});
Router.afterEach((to) => {
window.scrollTo(0, 0);
});每次路由跳转的时候都要判断权限,这里的判断也很简单,因为菜单的name与路由的name是一一对应的,而后端返回的菜单就已经是经过权限过滤的
如果根据路由name找不到对应的菜单,就表示用户有没权限访问
如果路由很多,可以在应用初始化的时候,只挂载不需要权限控制的路由。取得后端返回的菜单后,根据菜单与路由的对应关系,筛选出可访问的路由,通过addRoutes动态挂载
这种方式的缺点:
- 菜单需要与路由做一一对应,前端添加了新功能,需要通过菜单管理功能添加新的菜单,如果菜单配置的不对会导致应用不能正常使用
- 全局路由守卫里,每次路由跳转都要做判断
方案二
菜单和路由都由后端返回
前端统一定义路由组件
const Home = () => import("../pages/Home.vue");
const UserInfo = () => import("../pages/UserInfo.vue");
export default {
home: Home,
userInfo: UserInfo
};后端路由组件返回以下格式
[
{
name: "home",
path: "/",
component: "home"
},
{
name: "home",
path: "/userinfo",
component: "userInfo"
}
]在将后端返回路由通过addRoutes动态挂载之间,需要将数据处理一下,将component字段换为真正的组件
如果有嵌套路由,后端功能设计的时候,要注意添加相应的字段,前端拿到数据也要做相应的处理
这种方法也会存在缺点:
- 全局路由守卫里,每次路由跳转都要做判断
- 前后端的配合要求更高
按钮权限
方案一
按钮权限也可以用v-if判断
但是如果页面过多,每个页面页面都要获取用户权限role和路由表里的meta.btnPermissions,然后再做判断
这种方式就不展开举例了
方案二
通过自定义指令进行按钮权限的判断
首先配置路由
{
path: '/permission',
component: Layout,
name: '权限测试',
meta: {
btnPermissions: ['admin', 'supper', 'normal']
},
//页面需要的权限
children: [{
path: 'supper',
component: _import('system/supper'),
name: '权限测试页',
meta: {
btnPermissions: ['admin', 'supper']
} //页面需要的权限
},
{
path: 'normal',
component: _import('system/normal'),
name: '权限测试页',
meta: {
btnPermissions: ['admin']
} //页面需要的权限
}]
}自定义权限鉴定指令
import Vue from 'vue'
/**权限指令**/
const has = Vue.directive('has', {
bind: function (el, binding, vnode) {
// 获取页面按钮权限
let btnPermissionsArr = [];
if(binding.value){
// 如果指令传值,获取指令参数,根据指令参数和当前登录人按钮权限做比较。
btnPermissionsArr = Array.of(binding.value);
}else{
// 否则获取路由中的参数,根据路由的btnPermissionsArr和当前登录人按钮权限做比较。
btnPermissionsArr = vnode.context.$route.meta.btnPermissions;
}
if (!Vue.prototype.$_has(btnPermissionsArr)) {
el.parentNode.removeChild(el);
}
}
});
// 权限检查方法
Vue.prototype.$_has = function (value) {
let isExist = false;
// 获取用户按钮权限
let btnPermissionsStr = sessionStorage.getItem("btnPermissions");
if (btnPermissionsStr == undefined || btnPermissionsStr == null) {
return false;
}
if (value.indexOf(btnPermissionsStr) > -1) {
isExist = true;
}
return isExist;
};
export {has}在使用的按钮中只需要引用v-has指令
<el-button @click='editClick' type="primary" v-has>编辑</el-button> $nextTick原理及应用
原理
vue是异步执行dom更新的,一旦观察到数据变化,vue就会开启一个队列,然后把在同一事件循环当中观察到数据变化的watcher推送进这个队列,如果这个watcher被触发多次,只会被推送到队列一次,这种缓冲行为可以有效的去掉重复数据造成的不必要的计算和dom操作,这样可以提高渲染效率。
应用
vue中的nextTick主要用于处理数据动态变化后,DOM还未及时更新的问题,用nextTick可以获取数据更新后最新dom的变化。
在 created 和 mounted 阶段,如果需要操作渲染后的试图,也要使用 nextTick 方法。
mounted: function () {
this.$nextTick(function () {
// Code that will run only after the
// entire view has been rendered
})
}
Vue路由懒加载
对于SPA单页应用,当打包构建时,JavaScript包会变得非常大,影响页面加载速度,将不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应组件,这就是路由的懒加载。
v-model修饰符.lazy详解
lazy修饰符是让数据在失去焦点或者回车时才会更新,避免value内容没有打完就执行后续的change方法。
如何处理首页白屏
VUE首页加载过慢,其原因是因为它是一个单页应用,需要将所有需要的资源都下载到浏览器端并解析。因为是spa,而且所有的渲染都在脚本上,js执行需要时间。另外加载js也要时间,所以页面越大,加载时间越长,而且js执行的时间也长。
解决方案
- 优化 webpack 减少模块打包体积,code-split 按需加载
- 服务端渲染,在服务端事先拼装好首页所需的 html
- 首页加 loading 或 骨架屏 (仅仅是优化体验)
- 服务端开启gzip压缩
- 打包文件分包,提取公共文件包
Vue 双向数据绑定原理
vue数据双向绑定是通过数据劫持结合发布者-订阅者模式的方式来实现的,即使用Object.defineProperty()来实现对属性的劫持,但是Object.defineProperty()中的setter是无法直接实现数组中值的改变的劫持行为的,想要实现对于数组下标直接访问的劫持需要使用索引对每一个值进行劫持
Object.defineProperty缺点
- 只能追踪对象已有数据是否被修改,无法追踪到对象属性的新增或删除。
- 不能监听数组的变化
可以检测数组变化的push/pop/shift/unshift/splice/sort/reverse七个方法。
其他数组方法及数组的使用则无法检测到,例如如下两种使用方式:
vm.items[index] = newValue
vm.items.length--Proxy
Vue3.0使用Proxy实现数据劫持。Proxy的代理针对的是整个对象,而不是像Object.defineProperty针对某个属性。只需做一层代理就可以监听同级结构下的所有属性变化,包括新增属性和删除属性。
- Proxy直接代理整个对象而非对象属性
- Proxy也可以监听数组的变化
vue中key的作用
key的主要作用是为了高效的更新虚拟DOM,其原理是vue在patch过程中通过key可以精准判断两个节点是否是同一个,从而避免频繁更新不同元素,使得整个patch过程更加高效,减少DOM操作量,提高性能。
vue.set()
只有先定义在data 里 数据才具有响应式,如果自己后添加的属性是不具备响应式的。
比如下边这个 属性a 具有响应式,但是b 就不会,如果你想让这个b 具有响应式,你可以使用Vue.set(this.model, “b”, 20 ) 这样写使他具有响应式。
还有就是修改数组的某个值, 你直接通过索引的这种方式修改是不可以的。
但是你如果使用数组的 增删改查,排序,反转 方法 是会触发视图更新的,因为Vue内部重写了这些方法,并定义了响应式。
new Vue({
data(){
return {
list: [1, 2, 3, 4]
model:{
a: 10
}
}
}
})
mounted(){
this.list[0] = 5;
this.model.b = 20;
}
Vue为什么采用异步渲染
因为如果不采用异步更新,那么每次更新数据都会对当前组件进行重新渲染, 这样就会可能进行大量的dom重流或者重绘,所以为了性能考虑,减少浏览器在Vue每次更新数据后会出现的Dom开销,Vue 会在本轮数据更新后,再去异步更新视图。
什么是虚拟dom
虚拟DOM是用Object来代表一颗节点,这个Object叫做VNode,然后使用两个VNode进行对比,根据对比后的结果修改真实DOM。为什么是两个VNode?因为每次渲染都会生成一个新的VNode,然后和上一次渲染时用的VNode进行对比。然后将这一次新生成的VNode缓存,用来进行下一次对比。
minix混入
- 数据对象在内部会进行递归合并,并在发生冲突时以组件数据优先。
var mixin = {
data: function () {
return {
message: 'hello',
foo: 'abc'
}
}
}
new Vue({
mixins: [mixin],
data: function () {
return {
message: 'goodbye',
bar: 'def'
}
},
created: function () {
console.log(this.$data)
// => { message: "goodbye", foo: "abc", bar: "def" }
}
})- 同名钩子函数将合并为一个数组,因此都将被调用。另外,混入对象的钩子将在组件自身钩子之前调用。
var mixin = {
created: function () {
console.log('混入对象的钩子被调用')
}
}
new Vue({
mixins: [mixin],
created: function () {
console.log('组件钩子被调用')
}
})
// => "混入对象的钩子被调用"
// => "组件钩子被调用"- 值为对象的选项,例如
methods、components和directives,将被合并为同一个对象。两个对象键名冲突时,取组件对象的键值对。
var mixin = {
methods: {
foo: function () {
console.log('foo')
},
conflicting: function () {
console.log('from mixin')
}
}
}
var vm = new Vue({
mixins: [mixin],
methods: {
bar: function () {
console.log('bar')
},
conflicting: function () {
console.log('from self')
}
}
})
vm.foo() // => "foo"
vm.bar() // => "bar"
vm.conflicting() // => "from self"注意:混入也可以进行全局注册。使用时格外小心!一旦使用全局混入,它将影响每一个之后创建的 Vue 实例。使用恰当时,这可以用来为自定义选项注入处理逻辑。
// minix.js
export default {
data () {
return {
name: 'minix',
minixName: 'minixObj',
flag: false
}
},
mounted() {
console.log('minixMounted');
},
methods: {
speak() {
console.log('this is minix');
},
getData() {
return '100';
}
}
}
// todo.vue
import myMinix from './minix';
export default {
data () {
return {
name: 'todo',
lists: [1, 2, 3, 4]
}
},
mounted() {
console.log('todoMounted');
},
minixs: [myMinix], // todo.vue 中声明minix 进行混合
methods: {
speak () {
console.log('this is todo');
},
submit() {
console.log('submit');
},
}
}
//==========
// 最终得到的结果
//==========
export default {
data () {
return {
name: 'todo', // 共同有的data, 最后保留自己的data
lists: [1, 2, 3, 4], // 自己独有的,保留
minixName: 'minixObj', // todo没有的,会被添加进来
flag: false // todo没有的,会被添加进来
}
},
mounted() {
// 在钩子函数中的, 会被合并到todo.vue 的钩子函数中, minix中的代码在前,自己的在后
console.log('minixMounted');
console.log('todoMounted');
},
methods: {
// 同时有的方法, 会被封装为一个数组, 先执行minix中的,后执行todo自己的
speak () {
function() {
console.log('this is todo');
}
},
// 自己独有的,保留
submit() {
console.log('submit');
},
// 自己没有的方法会被添加进来
getData() {
return '100';
}
}
}webpack
配置解析别名
configureWebpack:{ // 覆盖webpack默认配置的都在这里
resolve:{ // 配置解析别名
alias:{
'@':path.resolve(__dirname, './src'),
'@h':path.resolve(__dirname, './src/assets/hotcss'),
'@s':path.resolve(__dirname, './src/assets/style'),
'@i':path.resolve(__dirname, './src/assets/images'),
}
}
}常见loader配置
- url-loader
安装: npm install url-loader -D
查看包的历史信息: npm info url-loader
注意: url-loader 内部会用到 file-loader,所以必须下载,但不用配置
安装:npm install file-loader
在 webpack/vue.config.js 中 的 module 配置 rules:
module: [
rules: [
// 处理图片
{
test: /\.(png|jpe?g|gif|svg)$/,
use: {
loader: 'url-loader',
options: {
limit: 1024*5, // 把小于 5kb 的文件 转换成 Base64 格式
name: 'img/[name].[ext]' // 指定路径
}
}
},
// 处理字体
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
use: {
loader: 'url-loader',
options: {
limit: 10240, // 可根据实际情况自行设定
name: 'fonts/[name].[hash:8].[ext]'
}
}
},
// 处理音视频
{
test: /\.(mp4|webm|ogg|mp3|wav|flac|aac)(\?.*)?$/,
use: {
loader: 'url-loader',
options: {
limit: 10240, // 可根据实际情况自行设定
name: 'static/media/[name].[hash:8].[ext]'
}
}
},
]
]- css-loader 与 style-loader
css-loader:把 css 搞到 js 中去
style-loader:再吧 js 中的 css 搞到 style 中
安装:npm install -D css-loader style-loader
module: [
rules: [
// 处理样式
{
test: /\.css$/,
// loader 处理方式 是 从下往上 从右往左
use: ['style-loader', 'css-loader']
},
{
test: /\.less$/,
// loader 处理方式 是 从下往上 从右往左
use: ['style-loader', 'css-loader', 'less-loader']
},
{
test: /\.sass$/,
// loader 处理方式 是 从下往上 从右往左
use: ['style-loader', 'css-loader', 'sass-loader']
},
// 处理 stylus
{
test: /\.(styl|stylus)$/,
// loader 处理方式 是 从下往上 从右往左
use: ['style-loader', 'css-loader', 'stylus-loader']
}
]
}常见plugin配置
- html-webpack-plugin
可以动态的引入js,因为每次打包后的js hash值可能不一样,它可以根据具体的hash值,引入js。
功能:把打包好的文件自动引入到入口文件 index.html 文件中
安装:npm install html-webpack-plugin -D
在 webpack.config.js 中引入
const HtmlWebpackPlugin = require('html-webpack-plugin');
// 配置
plugins:[
new HtmlWebpackPlugin({
// 默许指定 模板的路径 否则会篡改网页 title
template: resolve('public/index.html')
})
]- clean-webpack-plugin
运行webpack build时先把打包进入的文件夹清空。
功能:在每次打包时,先删除上次生成的文件
安装:npm install clean-webpack-plugin -D
在 webpack.config.js 中引入
const CleanWebpakPlugin = require('clean-webpack-plugin');
// 配置
plugins:[
new HtmlWebpackPlugin({
// 默许指定 模板的路径 否则会篡改网页 title
template: resolve('public/index.html')
}),
// 必须指定路径,是数组,可指定多个路径
new CleanWebpakPlugin(['dist'])
]- SplitChunksPlugin
代码分割插件。
optimization: {
splitChunks: {
chunks: 'initial', // 分割方式 async, all ,initial
minSize: 30000, //分割后的文件最小值
minChunks: 1, // 最小引用次数
maxAsyncRequests: 5, // 异步的最大分割数
maxInitialRequests: 3, // 初始模块的最大分割数
automaticNameDelimiter: '~', // 分割后的名字用什么符号链接
name: true,
cacheGroups: { //缓存组
venxx: {
test: /vue/,
name: 'vuevendors'
},
vendors: {
test: /jquery/,
name: 'jqueryvendors'
}
}
}
},主要用途
1.做代码分割,默认是将所以的异步引入单独打包,如常见的Vue异步路由组件
2.将不常改变的模块代码单独打包,这样更有利于浏览器的缓存处理,如将vue vuex vue-router, ui库,这些都是不常改变
3.将业务代码单独打包,这是经常改变的
4.异步模块代码单独打包,做预加载处理,加快首页加载速度
如果项目过大,打包事件过长,可以考虑使用HappyPack 插件,开启多进程打包(不是多线程,js是单线程的)
plugins: [
new HappyPack({
id: 'babel', // 与loader 配置项对应
threads: 4, // 开启多少个进程
loaders: ['babel-loader'] //用什么loader处理
})
]http
关于http缓存
缓存分为强缓存和协商缓存
- 强缓存
在浏览器加载资源时,先看看cache-control里的max-age,判断数据有没有过期,如果没有直接使用该缓存 ,有些用户可能会在没有过期的时候就点了刷新按钮,这个时候浏览器就回去请求服务端,要想避免这样做,可以在cache-control里面加一个immutable。
public:允许客户端和虚拟服务器缓存该资源,cache-control中的一个属性。
private:只允许客户端缓存该资源。
no-storage:不允许强缓存,可以协商缓存。
no-cache:不允许缓存。
- 协商缓存
是服务器用来确定缓存资源是否可用过期。
因为服务器需要向浏览器确认缓存资源是否可用,二者要进行通信,而通信的过程就是发送请求,所以在header中就需要有专门的标识来让服务器确认请求资源是否可以缓存访问,所以就有了下面两组header字段:
Etag和If-None-MatchLast-Modified和If-Modified-Since
http状态码
url输入到浏览器到页面的呈现经历了什么
- 输入网址
- DNS域名解析
- 建立TCP链接
- 浏览器向WEB服务器发起Http请求
- 服务器端处理
- 关闭TCP链接
- 浏览器解析资源
http和https的区别
- https协议需要ca证书,费用较高。
- http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
- 使用不同的链接方式,端口也不同,一般而言,http协议的端口为80,https的端口为443
- http的连接很简单,是无状态的;https协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
浏览器
跨域产生的原因
出于浏览器的同源策略限制。浏览器限制脚本中发起的跨站请求,要求JavaScript或cookie只能访问同源的资源。这里的同源指的是,域名,协议名,以及端口号相同。
跨域
当一个请求url的协议、域名、端口三者之间任意一个与当前页面ur不同即为跨域。
http/https //协议不同
http://www.test.com/与http://www.baidu.com/ //主域名不同
http://www.test.com:8080/ 与 http://www.test.com:7001/ //端口号不同postman调接口不会出现跨域,而浏览器会出现
这里需要理解什么是跨域,跨域是指的当前资源访问其他资源时发起的http请求由于安全原因(由于同源策略,域名、协议。端口中只要有一个不同就不同源),浏览器限制了这些请求的正常访问,特别需要注意的是这些发生在浏览器中。而通过postman等工具调用接口时,只是简单的访问一个资源,并不存在资源的相互访问。
所以,跨域这个情况只会出现在浏览器页面里,因为实际上是浏览器由于安全原因限制了这些请求的访问。
如何解决跨域
通过JSONP
自己理解:JSONP就是使用script标签的src属性来实现跨域,只能使用get请求,后台会返回给你一个方法,你通过这个方法获取你想要的数据。
jsonp原理 前端定义好方法通过src属性传给后端 后端拿到方法后传入数据拼接方法后传给前端,前端当成方法来调用。
JSONP主要是封装好的请求方式添加callback,这个callback是由前后端约定好的。
CORS跨域资源共享(Cross-Origin Resource Sharing)
cors跨域是服务端设置,前端直接调用,也就是说后台允许前端某个站点进行访问。所以说只要服务端提供CORS支持,前端不需要做额外的事情。它允许浏览器向跨域服务器发XMLHttpRequest请求,从而克服AJAX只能同源使用的限制。
这里列出几个返回http中常见的几个CORS请求头:
- Access-Control-Allow-Origin:该字段为必需字段,可以是指定的源名(协议+域名+端口),也可以使用通配符*代表接受所有跨域资源请求
- Access-Control-Allow-Credentials:该字段为boolean值,表示是否允许发送cookie,默认为false,即不允许发送cookie值。
代理跨域
通过修改nginx服务器配置来实现,前端修改后端不动,在vue.config,js文件中进行配置。
常见浏览器兼容问题
- 不同浏览器的标签默认的外补丁和内补丁不同
问题症状:随便写几个标签,不加样式控制的情况下,各自的margin和padding差异较大。
解决方案:CSS里*{margin:0; padding:0;}
- 图片默认有间距
问题症状:几个img标签放在一起的时候,有些浏览器会默认的间距,加了问题一中提到的通配符也不起作用。
解决方案:使用float属性为img布局
- IE6下margin值双倍边距问题
问题表现:IE6下元素浮动之后margin值变成双倍
解决方法:将元素转为行内属性
{
display: inline;
}- height值设置过小问题
问题表现:IE6、IE7下设置标签高度小于10px,存在超出已设置的高度的问题
解决方法:为超出高度的元素添加溢出部分隐藏
{
overflow: hidden;
}














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









