







 本文介绍了在Windows 7环境下,使用Python 3.5安装和配置Stanford CoreNLP进行中文词性标注的详细步骤。首先通过pip安装stanfordcorenlp,然后下载并放置必要的Java JDK和中文模型jar包。在配置Java环境变量的过程中,详细阐述了每一步骤,包括新建环境变量和修改Path。完成配置后,能够成功运行Java和查看版本,标志着Stanford CoreNLP已准备就绪,可用于中文文本的词性标注工作。
本文介绍了在Windows 7环境下,使用Python 3.5安装和配置Stanford CoreNLP进行中文词性标注的详细步骤。首先通过pip安装stanfordcorenlp,然后下载并放置必要的Java JDK和中文模型jar包。在配置Java环境变量的过程中,详细阐述了每一步骤,包括新建环境变量和修改Path。完成配置后,能够成功运行Java和查看版本,标志着Stanford CoreNLP已准备就绪,可用于中文文本的词性标注工作。
环境
window7 64位
JDK1.8
Python3.5
stanfordcorenlp的使用
进行中文词语词干化的工作,听说coreNLP这个工具不错。
coreNLP是斯坦福大学开发的一套关于自然语言处理的工具(toolbox),使用简单功能强大,有:命名实体识别、词性标注、 词语词干化、语句语法树的构造还有指代关系等功能,使用起来比较方便。
PART1:安装Stanford NLP
1) 安装Stanford nlp自然语言处理包:pip install stanfordcorenlp
2) 下载Stanford CoreNLP文件:http://stanfordnlp.github.io/CoreNLP/download.html
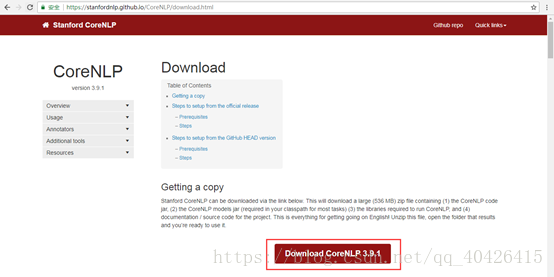
3) 下载中文模型jar包:http://nlp.stanford.edu/software/stanford-chinese-corenlp-208-02-27-models.jar
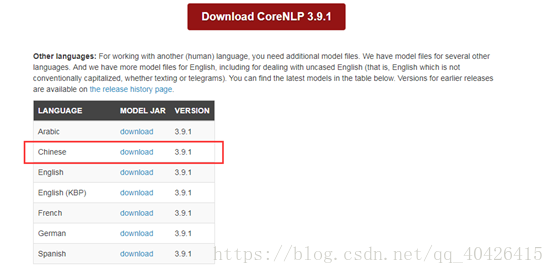
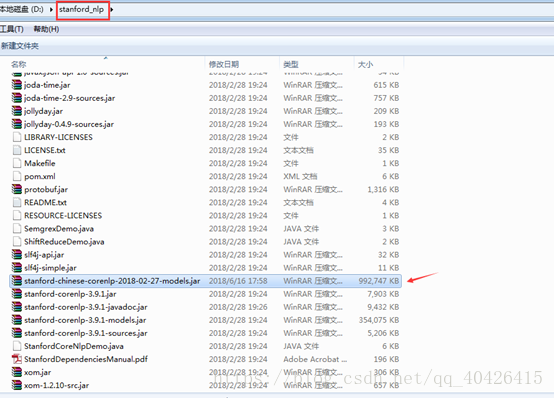
4) 把解压后的Stanford CoreNLP文件夹(个人习惯,这里我重命名为stanford_nlp)和下载的Stanford-chinese-corenlp-2018-02-27-models.jar放在同一目录下(注意:一定要在同一目录下,否则执行会报错)
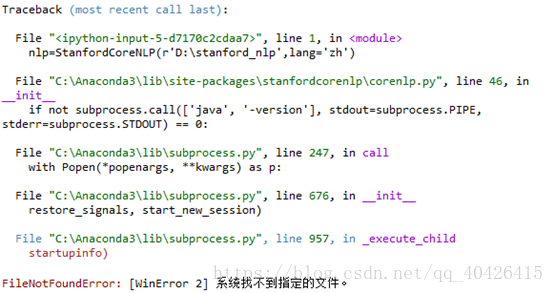
5) 在Python中引用模型,执行下面语句:
from stanfordcorenlp import StanfordCoreNLP
nlp=StanfordCoreNLP(r'D:\stanford_nlp',lang='zh')
PART2:安装过程问题
然而,很多朋友在上面的执行过程中,总遇到下面的问题(可能原因:coreNLP是使用Java编写的,运行环境需要在JDK1.8,1.7貌似都不支持,需要引进 .jar 包)我当时也是特别郁闷,网上对于这个问题的解答比较少,这里依据我的血泪史给大家做个分享,希望对大家有所帮助:
开始安装 java 的 JDK 了,我安装的是:jdk-8u171-windows-x64(点击打开链接)
1)双击安装包,进入安装模式,运行->下一步(N);
2)接着点击下一步或者,可以更改希望Java安装的路径;

3)接着点击下一步或者,可以更改希望Java安装的路径
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









