






起点中文网月票榜爬取及数据分析
1. 数据爬取
数据爬取就是通过网络爬虫程序来获取需要的网站上的内容信息,比如文字、视频、图片等数据。网络爬虫(网页蜘蛛)是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。一般是通过网页的url获取网页的源代码中,从源代码中提取需要的信息。
1.1.1 准备
运行cmd命令,通过 pip install +库名 或者pip3 install +库名,安装好需要的库,做好准备后即可开始爬取操作。
需要爬取的网页为 https://www.qidian.com/rank/yuepiao?style=2
1.1.2 网页分析
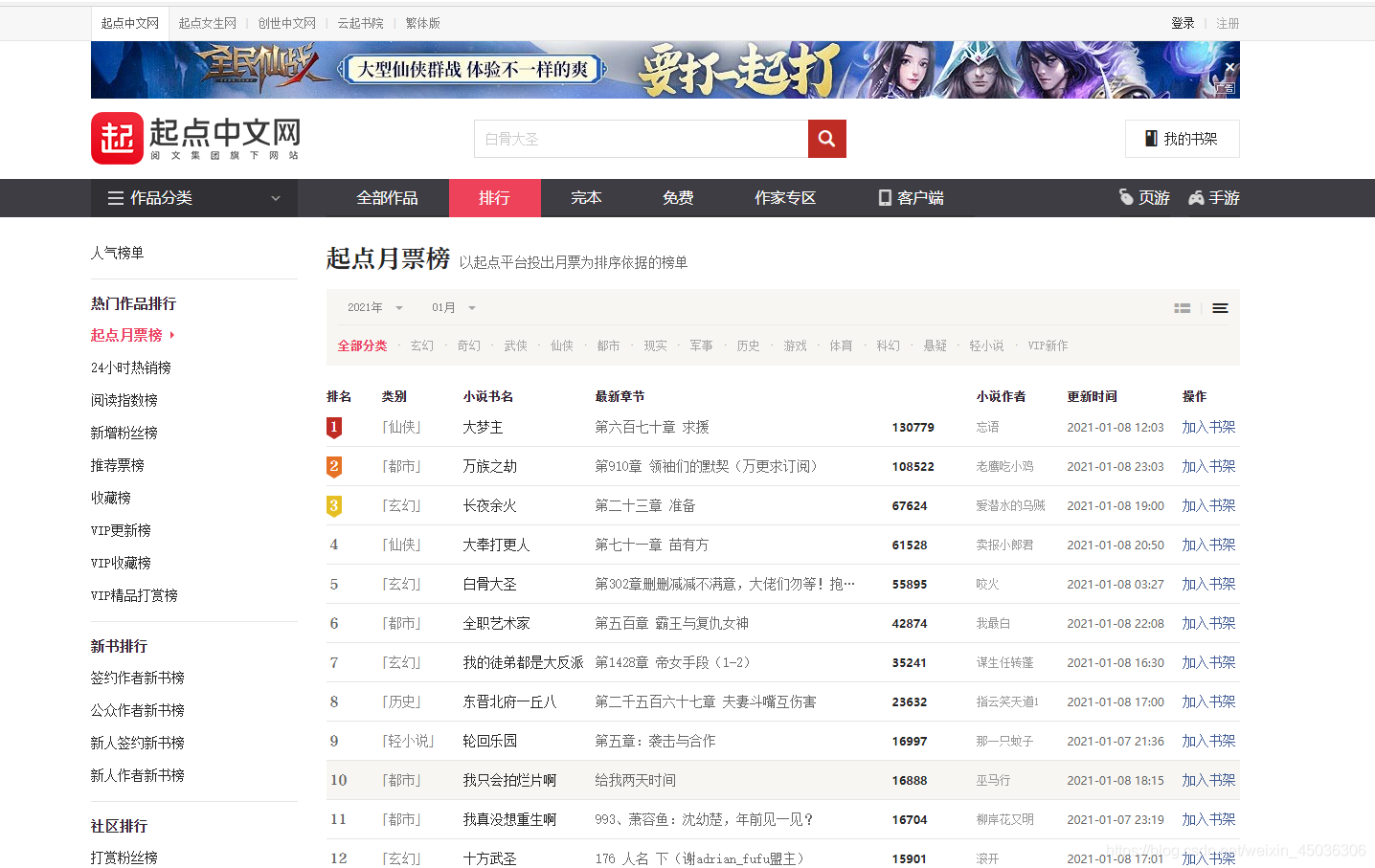
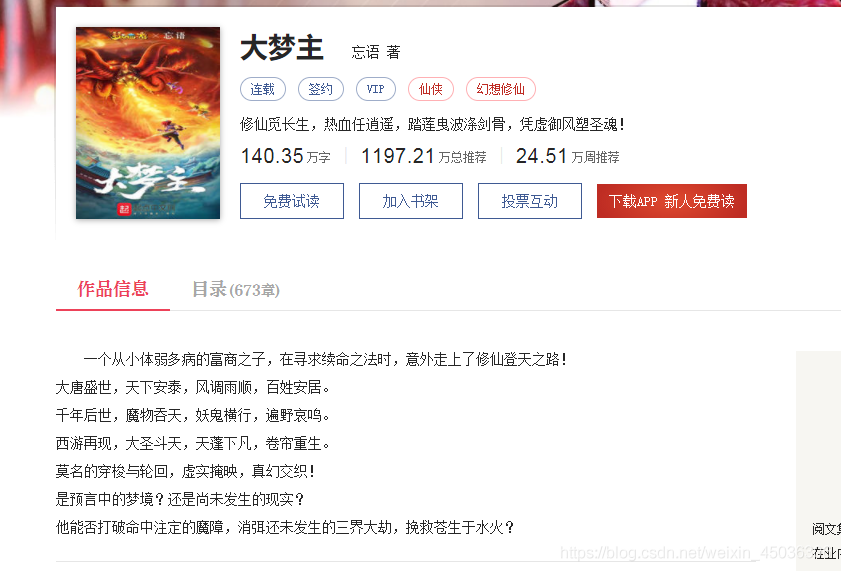
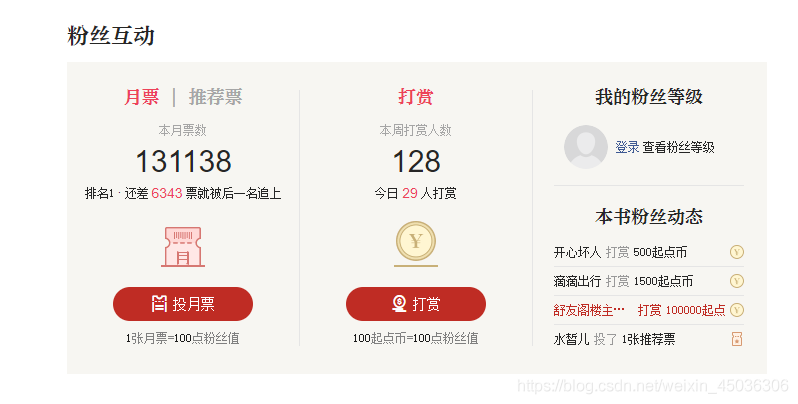
由上图可知,该榜中需要的爬取的有用信息为类名、书名、最新章节、月票数、小说作者、更新的时间、小说简介以及周票数和打赏人数。
1.1.3 层次爬取
html=requests.get(url)
#爬取月票的html文件
html.encoding='UTF-8'
#该网页的编码格式为UTF-8
doc=BeautifulSoup(html.text,'lxml')
#转换为BeautifulSoup对象
排行榜总共有两页,先得到页数,方便后续的访问。先得到前50名上榜书籍,排行榜上能够获取到的信息:

page=doc.find('div',class_="pagination fr")['data-pagemax']
#获取网页最大页码
list1=doc.find('table',class_='rank-table-list hot-new').find('tbody').find_all('tr')
#找出每款书在该页面的信息块
for x in list1:
#通过循环对每款书的信息进行提取
name=x.find('a',class_='name').text.strip()
#取出书名
#strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
infrom='https:'+x.find('a',class_='name')['href']
#规范url格式,方便进行下一步的深度爬取
author=x.find('a',class_='author').text.strip()
#爬取作者
booktype=x.find('a',class_='type').text.strip()
#文本分类
month=x.find(class_='month').text
#月票数量
time=x.find(class_='time').text
#上传日期
new=x.find('a',class_='chapter').text
#最新章节名称
然后爬取每本上榜作品的详细信息
html1=requests.get(infrom)
#爬取第二层的html文件
html1.encoding='UTF-8'
#该网页的编码格式为UTF-8
doc1=BeautifulSoup(html1.text,'lxml')
list1 = doc1.find('div',class_="book-intro")
bookIntrodaction = list1.find("p").text.strip()
#获取小说简介
listt2=doc1.find(class_="fans-interact cf")
monthTickets=listt2.find(class_ ='ticket month-ticket').find(class_ = 'num').text
#小说月票
weekTickets=listt2.find(class_ ='ticket rec-ticket hidden').find(class_ = 'num').text
#小说周票
people=listt2.find(class_= 'rewardNum').text
#小说本周打赏人数
经过以上操作后前50名的信息就获取成功了!!
1.1.4 数据存储
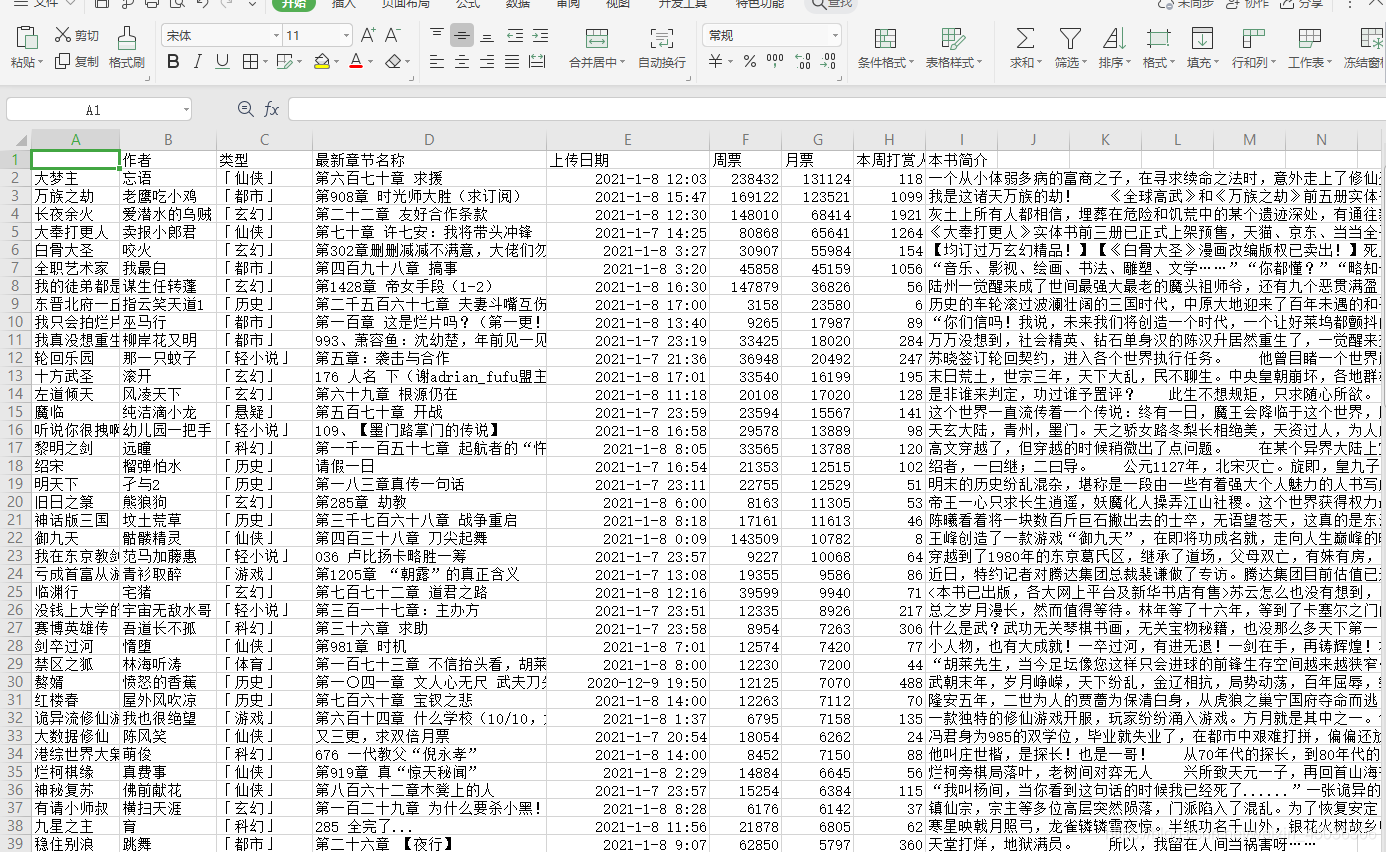
将爬取到的信息存入到csv文件中,方便后续的可视化分析。
file_exists= os.path.isfile('bookRooking.csv')
#判断是否为文件
with open('bookRooking.csv','a',encoding='utf-8',newline='') as f:
#newline = "" 表示读取的换行符保持不变,原来是啥,读出来还是啥
headers=data.keys()
#找出data的所有的键
w =csv.DictWriter(f,delimiter=',',lineterminator='\n',fieldnames=headers)
#创建一个对象
if not file_exists :
w.writeheader()
#第一次写入数据先写入表头
w.writerow(data)
#单行写入
print('当前行写入csv成功!')
此处判断是否为文件,能够有效的防止后面输出的表头不会重复。只有非表头的情况可以写入。
2. 数据分析及可视化
利用csv文件对每个类型书籍的周票均值、月票均值、总共的打赏值绘制折线图,可以一眼出周票、月票、以及打赏最多的类型的书籍。
plt.rcParams['font.sans-serif'] = ['SimHei']
#解决横坐标不能显示中文的况
plt.rcParams['axes.unicode_minus'] = False
#解决横坐标不能显示中文的情况
y1 = data.groupby('类型').sum()['本周打赏人数']
#求和
y2 = data.groupby('类型').mean()['周票']
#求平均值
y3 = data.groupby('类型').mean()['月票']
#求平均值
x=list(dict(y1).keys())
#横坐标值
fig = plt.figure(figsize=(8,6), dpi=100)
#指定画布大小
plt.plot(x,y1,c='red',label='打赏票和')
#指定折线的颜色和标签
plt.plot(x,y2,c='yellow',label='周票均值')
plt.plot(x,y3,c='blue',label='月票均值')
plt.legend(loc='upper left')#标签靠左
plt.title("小说票数折线图")#图名
plt.xlabel('小说类型',fontsize=15)

由上图可以得知仙侠类型的书籍得到的周票和月票均值是最高的其次是玄幻类型的,且玄幻得到打赏的票数最多,军事类型的书籍较少。
利用柱状图能够的出项成绩的具体数据。
plt.rcParams['figure.figsize']=(8,3)#图形大小
data.groupby(['类型']).mean().plot(kind = 'bar')
plt.xticks(rotation=0)#横坐标的角度
plt.ylabel('总票数',fontsize = 15)#纵坐标名
plt.xlabel('小说类型',fontsize = 15)#横坐标名
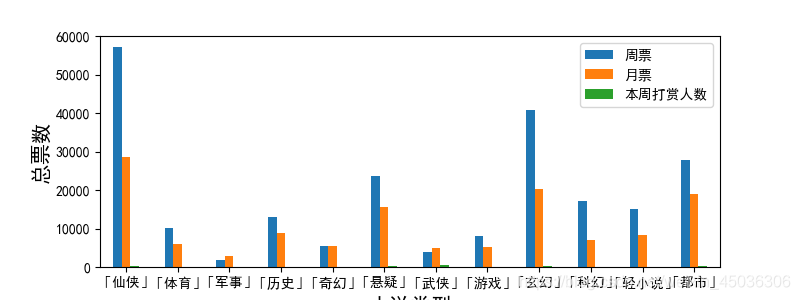
可以看出一周中给出打赏的人占极少数,月票甚至比周榜的人数还少。
通过饼状图可以看清楚在整体中所占的比重。
sizes= []
for booktype in x:#x是上文折线图中横坐标,即小说所有的类型。
bookTypeNum=len(data[data['类型']==booktype])#获取各种小说的数量
sizes.append(bookTypeNum)
plt.figure(figsize=(20,20)) #调节图形大小
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.pie(
sizes,
labels=x,#指定显示的标签
autopct='%1.1f%%'#数据保留固定小数位
)
plt.axis('equal')# x,y轴刻度设置一致#本文中可以不用
plt.title('小说类型受欢迎的分布图比')
plt.legend(loc='upper left')# 左上角显示
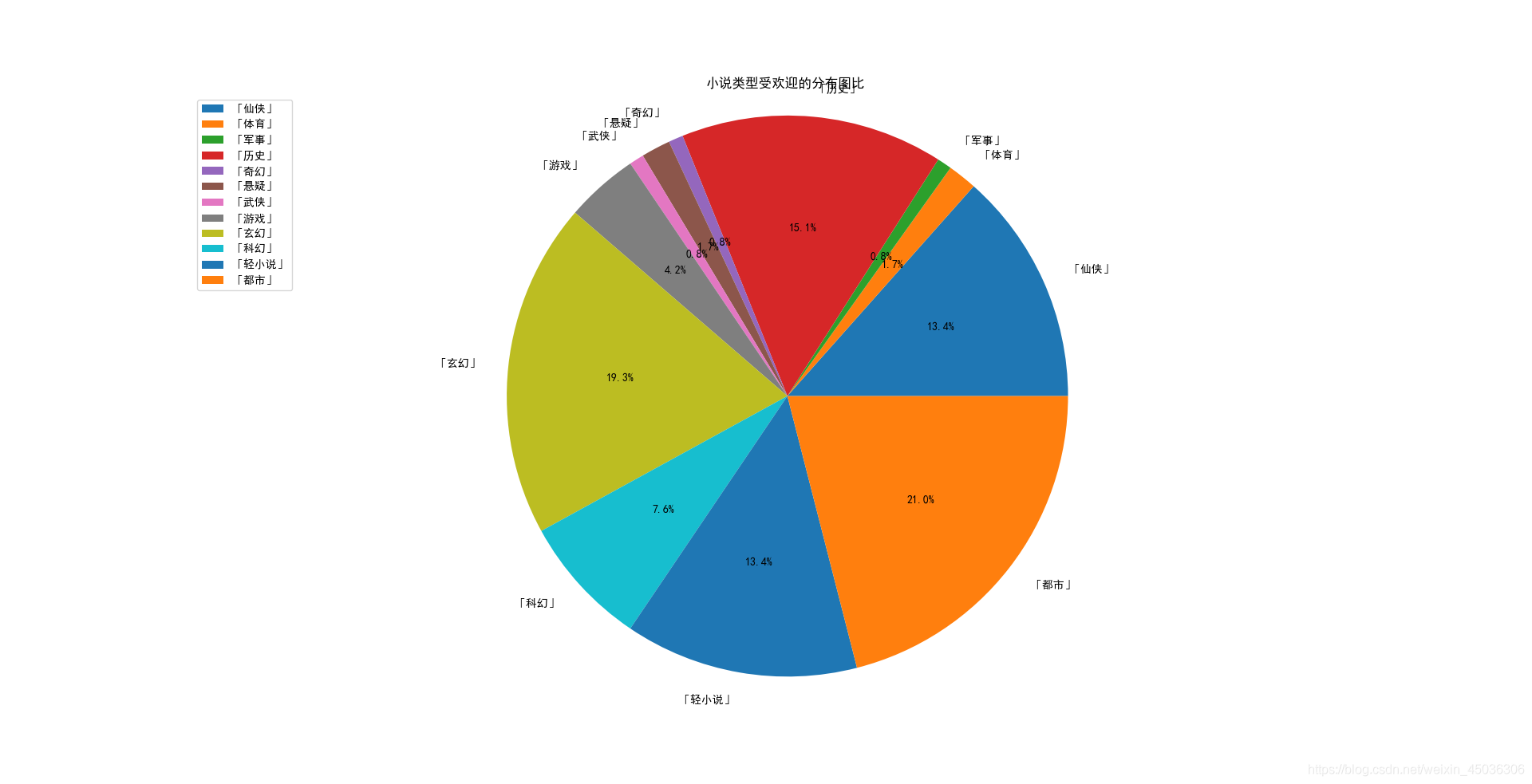
由此可以玄幻和都市类型的小说是现在网络小说最受欢迎的类型,两种占据了40%的比重。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









