






| model | MMLU | C-Eval | GSM8K | HumanEval |
| glm-4-9b | 74.7 | 77.1 | 84.0 | 70.1 |
| qwen1.5-7b | 61 | 74.1 | 62.5 | 36.0 |
| qwen1.5-14b | 67.6 | 78.7 | 70.1 | 37.8 |
数据来源是以下两个图。可以看到GLM4非常优秀,qwen应该也快要开源自己的新模型了,希望国内的大模型团队能够继续坚持,持续努力,坚持就是成功,持续性的努力非常重要!!!
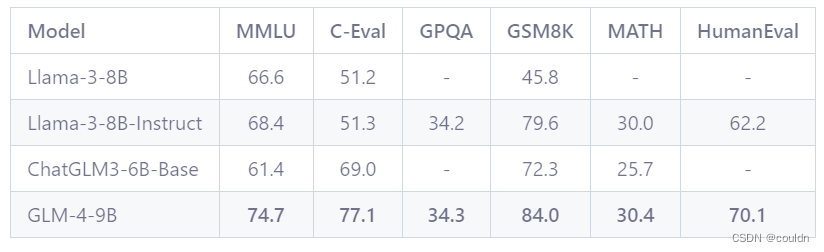
(来源:魔搭社区)
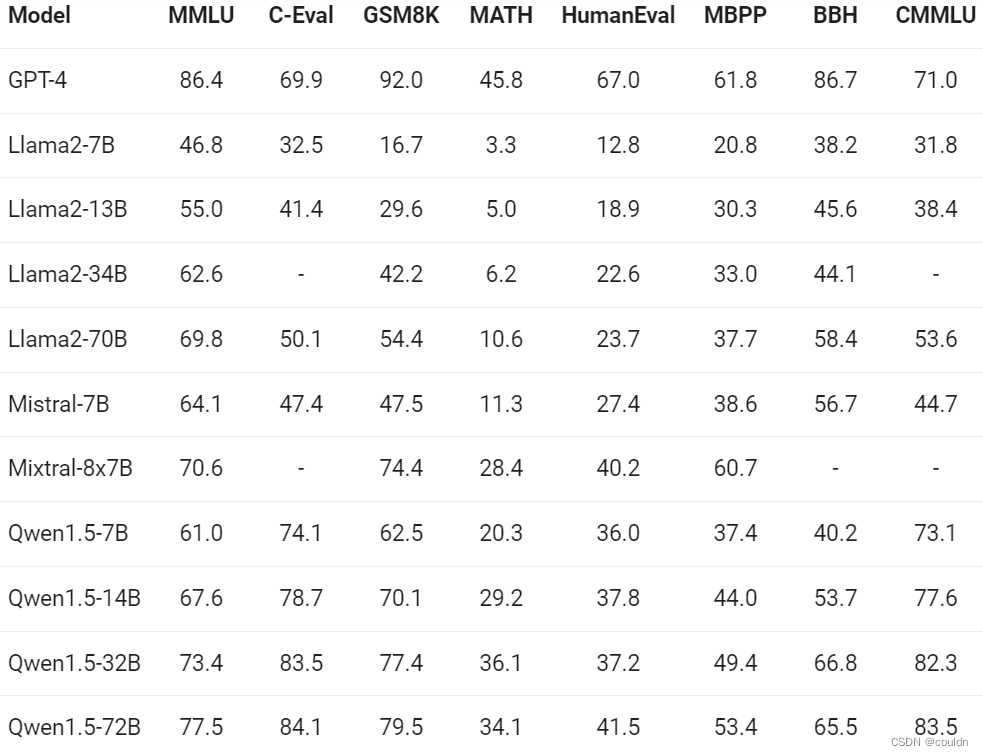
| model | MMLU | C-Eval | GSM8K | HumanEval |
| glm-4-9b | 74.7 | 77.1 | 84.0 | 70.1 |
| qwen1.5-7b | 61 | 74.1 | 62.5 | 36.0 |
| qwen1.5-14b | 67.6 | 78.7 | 70.1 | 37.8 |
数据来源是以下两个图。可以看到GLM4非常优秀,qwen应该也快要开源自己的新模型了,希望国内的大模型团队能够继续坚持,持续努力,坚持就是成功,持续性的努力非常重要!!!
(来源:魔搭社区)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























