









 博主因看了《大江大河》电视剧,想找小说看,便用Python爬虫从傲宇中文网下载小说。介绍了获取小说各章节内容的方法,将内容循环写入txt文件,还提及遇到的问题,最后附上爬取的小说txt百度网盘下载路径。
博主因看了《大江大河》电视剧,想找小说看,便用Python爬虫从傲宇中文网下载小说。介绍了获取小说各章节内容的方法,将内容循环写入txt文件,还提及遇到的问题,最后附上爬取的小说txt百度网盘下载路径。
python爬虫-小说《大江大河》
最近看了电视剧大江大河电视剧,挺好看的,就在网上找找小说看。
大江大河小说地址:傲宇中文网 http://www.aouchina.com/shu/31369/
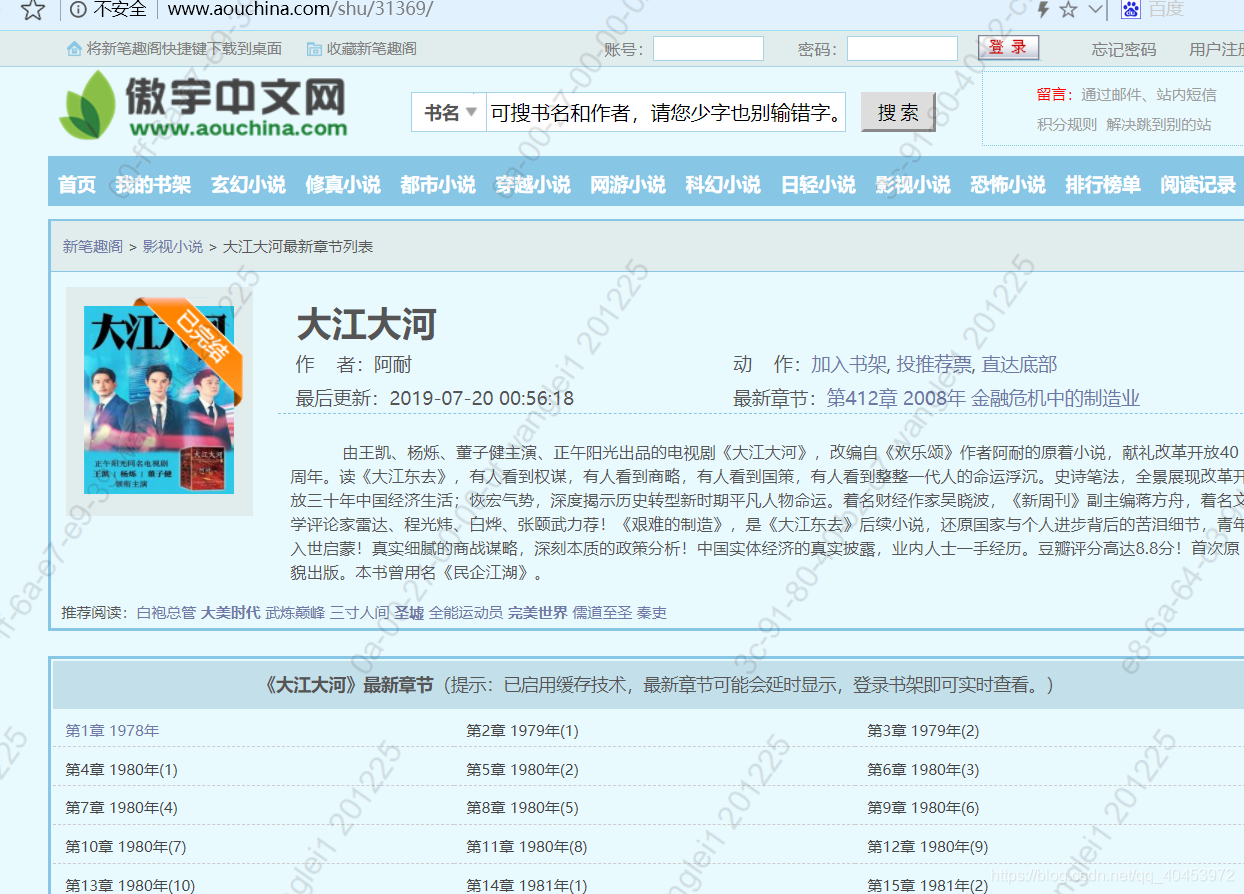
直接鼠标右键查看源码
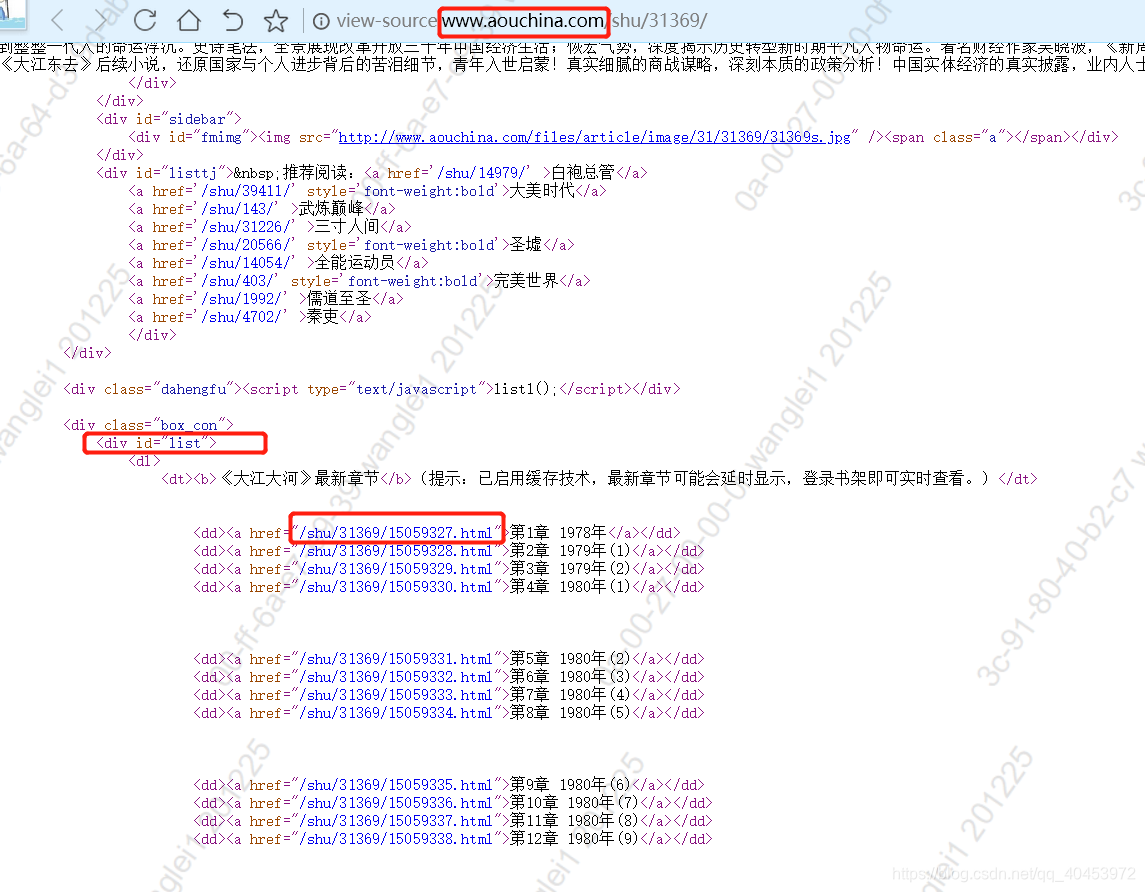
其实原理很简单,在这个网址上点击进入每一章,然后下载里面的内容,例如第一章:第1章 1978年,在这个的href就是相对路径,所以前面加上该网址之后就是 http://www.aouchina.com/shu/31369/15059327.html
进入该网址就是第一章的内容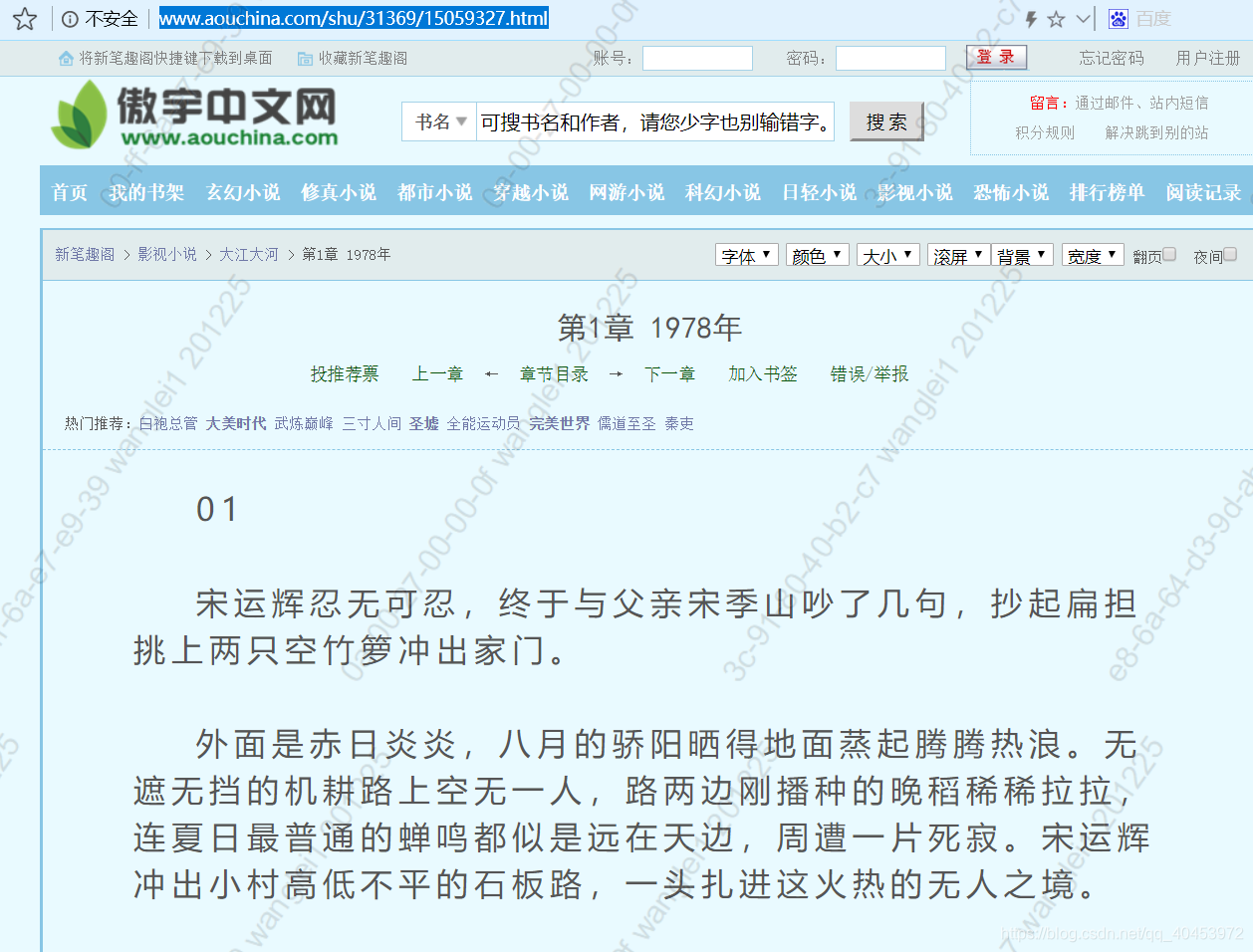
再次右键查看源码:
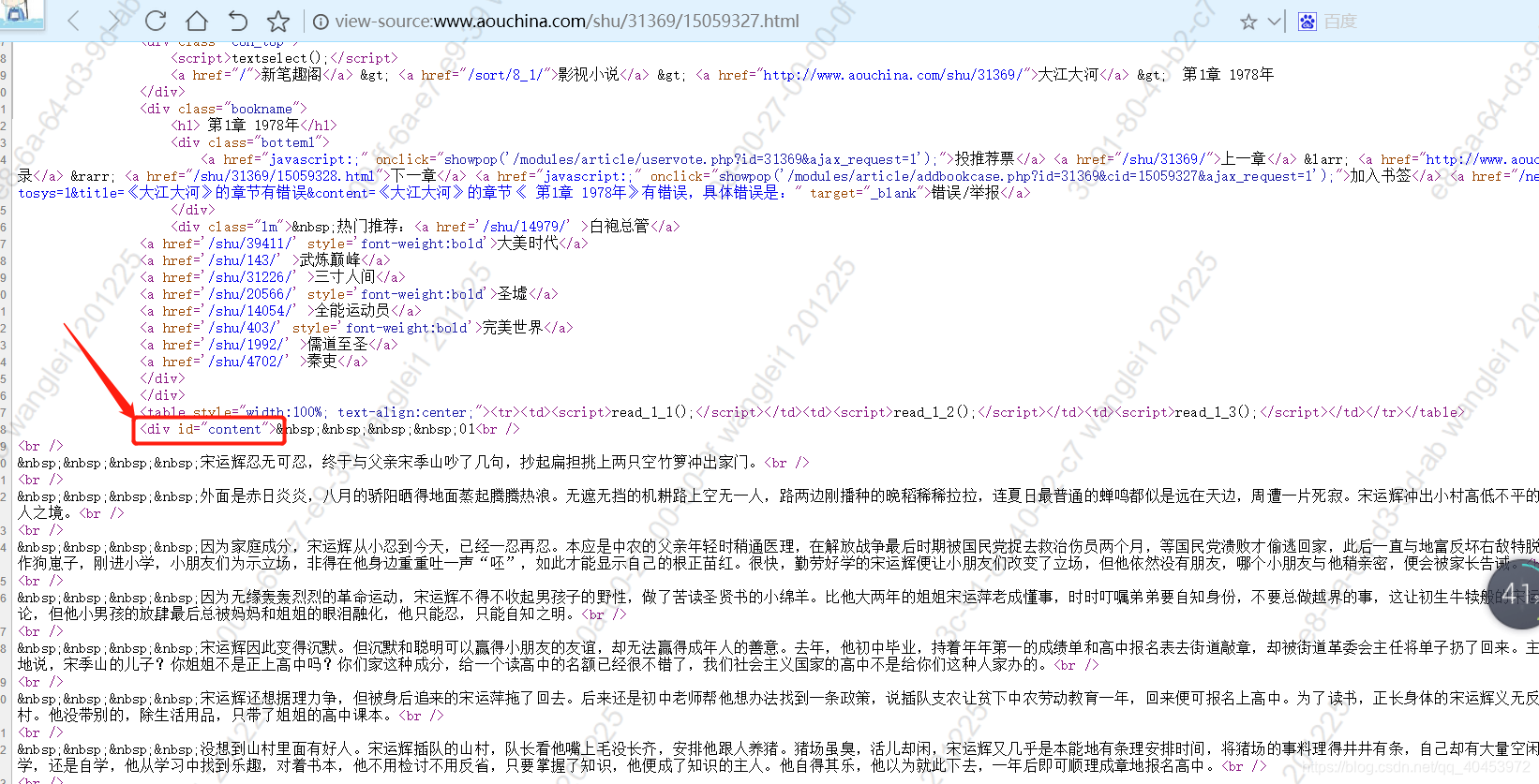
找这个div下面的内容就是小说的内容,最后把所有小说内容循环写进txt中。
最后附上py源码
import time
from urllib import request
from bs4 import BeautifulSoup
import re
import sys
if __name__ == "__main__":
#创建txt文件
file = open('大江大河.txt', 'w', encoding='utf-8')
#一念永恒小说目录地址
target_url = 'http://www.aouchina.com/shu/31369/'
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
target_req = request.Request(url = target_url, headers = head)
target_response = request.urlopen(target_req)
target_html = target_response.read().decode('gbk','ignore')
listmain_soup = BeautifulSoup(target_html, 'html5lib')
print("22222222222"+str(listmain_soup))
#找出div标签中class为list的所有子标签
chapters = listmain_soup.find_all('div',id = 'list')
print("22222222222"+str(chapters))
download_soup = BeautifulSoup(str(chapters))
#计算章节个数
numbers = (len(download_soup.dl.contents) - 1) / 2 - 8
index = 1
begin_flag = False
for child in download_soup.dl.children:
if child != '\n':
#爬取链接并下载链接内容
if child.a != None:
download_url = "http://www.aouchina.com" + child.a.get('href')
download_req = request.Request(url = download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read().decode('gbk','ignore')
download_name = child.string
soup_texts = BeautifulSoup(download_html)
texts = soup_texts.find_all(id = 'content')
soup_text = BeautifulSoup(str(texts))
write_flag = True
file.write(download_name + '\n\n')
#将爬取内容写入文件
for each in soup_text.div.text.replace('\xa0',''):
if each == 'h':
write_flag = False
if write_flag == True and each != ' ':
file.write(each)
if write_flag == True and each == '\r':
file.write('\n')
print('正在写入第{0}小节'.format(index))
index+=1
file.write('\n\n')
#打印爬取进度
sys.stdout.write("已下载:%.3f%%" % float(index/numbers) + '\r')
sys.stdout.flush()
index += 1
file.close()
期间遇到的问题:1 没有安装html5lib

控制台打印的进度和小节有点问题,就懒得改了。
最后附上上述代码运行后爬虫爬下的《大江大河》小说的txt下载路径
复制这段内容后打开百度网盘App,操作更方便哦。 链接:https://pan.baidu.com/s/1gYbDpjo4PewdbvAOiQ7vNQ 提取码:edgq


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









