







背景
构造一棵树,再通过json返回给前端展示是我们经常需要遇到的功能。在这里总结一下通过递归功能构造树,结合着stream,将代码变得简洁易懂。
实体结构
通常的实体类型树结构,为List< List<…> >,最外边为root节点,里边为子子孙孙节点。其中还需要有一个关联关系,子节点可以通过parentId关联父节点。实体类例子如下:
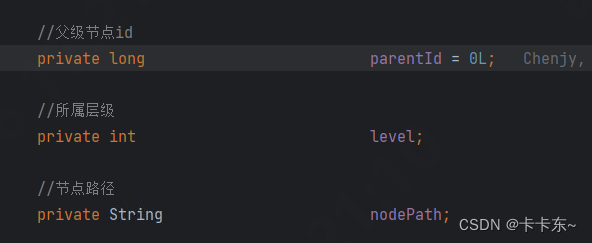
这是一个类名为SlogPolicy的树结构,其中主要用到的属性如下:

所属层级和路径如有需要可以加上,并不影响树的构造

代码
因为比较简单、代码就直接贴图了。但是思路会在下方指出
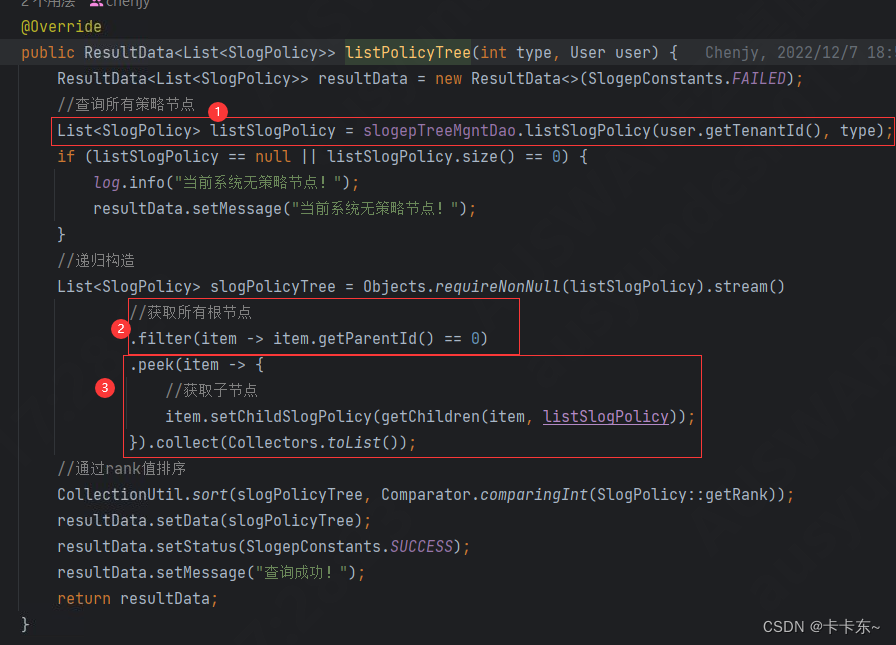
上图有三步:
- 从数据库中获取到所有需要展示的节点,相当于直接缓存到内存中;
- 通过filter方法过滤出父节点,依据为parentId为0;
- 通过peek方法在每一个父节点下set子节点。
之后进入获取子节点的递归方法getChildren(),如下:
参数说明:第一个参数就是当前父节点、第二个参数为上述步骤1查询出的数据
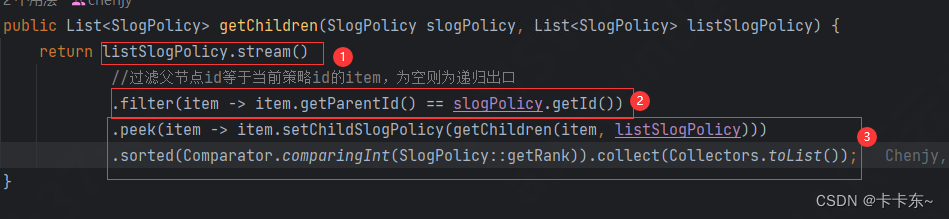
- 通过stream对所有数据进行操作
- 通过filter方法过滤出所属父节点,依据为子节点的parentId为父节点的id;
- 通过peek方法在每一个子节点下再set孙节点。如有需要也可以通过sorted方法对生成的列表排序
递归出口:可以想到,当子节点下再找不到下一级的子节点了,那么这个root节点下的递归构造就完成了,便可回溯。也就是通过filter方法过滤出的数据为空了。
上诉步骤完成后,树结构就构造完成。可以看到通过stream流方式很方便。
这样的方法还可以想到优化的点,因为每次要把所有查到的数据作为参数代入到递归方法中,之后通过stream处理。数据量大的情况下会耗费一定的性能。因此也可以通过:
1、不一次性查询到所有数据缓存到内存中,而是先查到所有父节点数据,再在递归过程中查询到其下的子节点数据。(这样是会照成请求数据库I/O次数较多)。
2、可以将已经set的数据进行清理,这样数据量会逐级递减。
上诉stream流中使用到了peek方法,说明一下与map的区别:
主要区别为:peek为消费型接口,调用peek方法后, 流还在。
map方法是函数型接口。调用map方法后,流已经被消费。
peek对一个对象进行操作的时候,对象不变,但是可以改变对象里面的值
map方法接收一个Function作为入参. Function是有返回值的, 这就表示map对Stream中的元素的操作结果都会返回到Stream中去
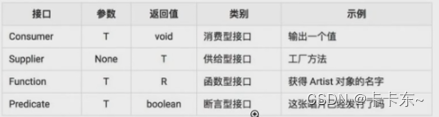
四种函数式接口:
示例代码
import java.util.ArrayList;
import java.util.List;
class Person {
private int id;
private String name;
private int parentId;
private List<Person> children;
public Person(int id, String name, int parentId) {
this.id = id;
this.name = name;
this.parentId = parentId;
this.children = new ArrayList<>();
}
public int getId() {
return id;
}
public String getName() {
return name;
}
public int getParentId() {
return parentId;
}
public List<Person> getChildren() {
return children;
}
}
public class TreeBuilder {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person(1, "Alice", 0));
personList.add(new Person(2, "Bob", 1));
personList.add(new Person(3, "Charlie", 1));
personList.add(new Person(4, "David", 2));
personList.add(new Person(5, "Eve", 2));
List<Person> treeList = buildTree(personList);
// 使用 treeList 进行后续操作
}
public static List<Person> buildTree(List<Person> personList) {
List<Person> treeList = new ArrayList<>();
personList.stream()
.filter(person -> person.getParentId() == 0)
.peek(treeList::add)
.forEach(root -> addChildren(root, personList));
return treeList;
}
private static void addChildren(Person parent, List<Person> personList) {
personList.stream()
.filter(person -> person.getParentId() == parent.getId())
.peek(parent.getChildren()::add)
.forEach(child -> addChildren(child, personList));
}
}
使用 Stream 流的 filter() 方法来筛选根节点和子节点,并使用 peek() 方法将节点添加到相应的列表中。在 buildTree() 方法中,我们首先筛选出根节点(parentId 为 0),并将它们添加到 treeList 中。然后,通过调用 addChildren() 方法递归地添加每个根节点的子节点。
在 addChildren() 方法中,我们使用 Stream 流的 filter() 方法筛选出每个父节点的子节点,并将它们添加到父节点的 children 列表中。然后,再递归地调用 addChildren() 方法,以添加每个子节点的子节点,直到所有节点被处理完毕。














 4157
4157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









