







《Table-GPT: Table-tuned GPT for Diverse Table Tasks》论文深度阅读笔记
微软发表的这篇论文《Table-GPT: Table-tuned GPT for Diverse Table Tasks》在LLM处理表格数据方向具有非常高的研究价值。
本文简单记录一些笔者的阅读笔记。
论文简介
如今的语言模型(GPT-3、ChatGPT等)在表格数据相关任务上的表现并不理想,这可能是因为它们是基于一维的自然语言数据预训练的,而表格数据往往是二维对象。
微软团队在论文中提出了新的语言模型微调范式 “table-tuning”:使用从真实表格数据合成得到各种表任务作为训练数据,对语言模型(GPT-3、ChatGPT)进行训练/微调得到新模型 Table-GPT,提升了语言模型在理解表格和处理表格任务上的表现。
论文实验表明 Table-GPT 模型:
- 具备更好的表格理解能力
- 在表格任务上具有优秀的普遍适用性
论文贡献:
- 提出了一种新的 “table-tuning” 范式来继续训练语言模型,专门设计用于增强语言模型执行表任务的能力
- 开发了用于表调优的 task-level, table-level, instruction-level, and completionlevel 数据增强技术,这些技术可以避免模型过拟合,并确保模型具有普遍适应性
- 我们表明,Table-GPT不仅在 zero-shot and few-shot settings out of box 都擅长表任务,还可以作为一个“表基础模型”,用于下游的单任务优化,例如特定任务的微调和提示工程
研究背景
目前语言模型在表格数据上表现不稳定
Markdown表是以往的工作中将表提供给语言模型的常用格式,也是GPT等模型在需要输出表数据时使用的格式
| 自然语言文本 | 表格数据 | |
|---|---|---|
| 维度 | 单向 | 二维(行和列) |
| 阅读方向 | 从左到右的阅读顺序 | 往往还可以在同一列从上往下阅读 |
| 顺序 | tokens 顺序改变通常会改变语义 | 行数据/列数据的排列往往可以自由改变而不改变语义 |
微软团队通过两种表格任务测试目前语言模型在表格数据上的表现:
- (T-1) Missing-value-identification:向模型提供一个真实表格,其中有且仅有一个空单元格,让模型回答空单元格所在的行名、列名。
- (T-2) Column-finding:向模型提供一个真实表格,其中有一个单元格内容是独一无二的,让模型回答该单元格所在的列名。
论文指出,在 T-1 之外设计了一个相似的 T-2 任务,是为了确认模型是否准确理解 T-1 任务中输入指令的 “missing value” 、“empty cell”,进而排除了模型因为指令理解错误而导致表现差,确认了模型是对表格数据的理解能力差。这是个很严谨的研究思路。
T-1 和 T-2 任务的测试明确表明,当前基于自然语言文本预训练的大语言模型并不适合阅读理解二维表格,这导致了模型在各种表格任务上不理想的表现。微软团队认为在模型在垂直方向的阅读能力在表格问答等其它表格任务的执行中同样重要。

此外,他们测试发现大语言模型对表格数据中列数据的顺序敏感。
提升语言模型在表格数据上表现的方向
已有的研究表明,提示工程是增强模型性能(包括处理表格任务)的一个有前途的方向,但它需要针对特定任务的调优。
微软的团队则提出了一种新的 “table-tuning” 微调范式,通过使用多样的表格任务作为训练数据,仅修改一次底层语言模型的权重,来提高语言模型理解和处理表格数据的能力。 “table-tuning” 与提示工程是互补的,合理的提示工程仍然可以进一步提升表格调优后的模型性能。
“table-tuning” 的设计参考了指令调优。训练数据为 (instruction, table,completion) 的格式,是从大量真实表格数据合成得到的。
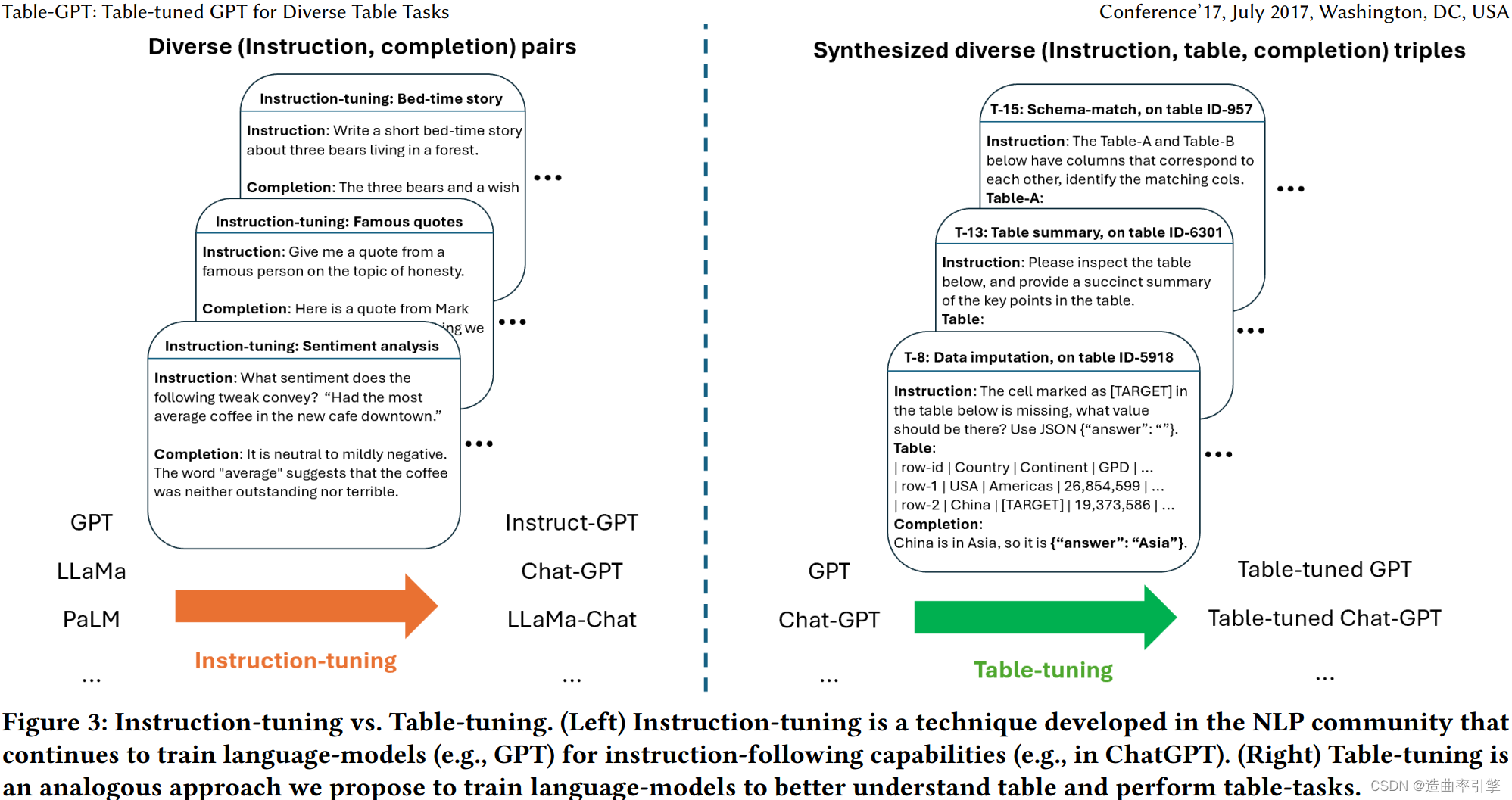
语言模型调优
- Encoder-style language models:BERT、RoBERTa……
- 需要基于特定任务标记的训练数据进行微调,限制了模型推广到新任务上的能力
- Decoder-style “generative” language models: GPT、LLaMa……
- 在无需对特定任务的微调的情况下,能够很好地推广到新的下游任务
- 尤其是在指令调优后,很容易适应处理新的任务(并且是以自然语言指令的方式)
语言模型在表格数据上的能力
测试列方向阅读能力
设计两种任务:
- T-1(a):保留表格数据中空单元格的列分隔符(markdown中的
| |),让模型识别空单元格的行名、列名 - T-1(b):去除表格数据中空单元格的列分隔符(markdown中的
| |),让模型识别空单元格的行名、列名
结果表明,语言模型阅读二维表格数据(尤其垂直方向)的能力欠佳
测试对排列顺序的敏感度
改变同一个表格的列顺序,进行测试。
结果表明,语言模型对表格数据的列排列顺序敏感
表格数据与自然语言文本的其它区别
- 表格单元格中的文本往往是短语、条目名称,这些文本在行方向上的排列与自然语言文本有很大区别
- 同一列中往往具有相似的、同构的文本值,这种编码关系与自然语言文本有很大区别
TABLE-TUNING FOR TABLE-GPT
整体策略:Synthesis-then-Augment
用 “(instruction, table, completion)” 格式定义一种表格任务,𝑡 = (𝐼𝑛𝑠,𝑇,𝐶):
- 𝐼𝑛𝑠:针对特定表格任务的自然语言指令
- 𝑇:目标表格
- 𝐶:根据指示 𝐼𝑛𝑠 执行表 𝑇 上的任务的预期完成情况,可以是自然语言、JSON等数据格式、表格或者混合形式
由于目前表格数据的基准数据集(数据数量和任务类型)较少,导致调优后的模型过拟合。在没有大量人力进行人工标注的情况下,微软团队提出了方法 Synthesis-then-Augment,能够基于真实表格数据生成不同的表格任务训练数据。
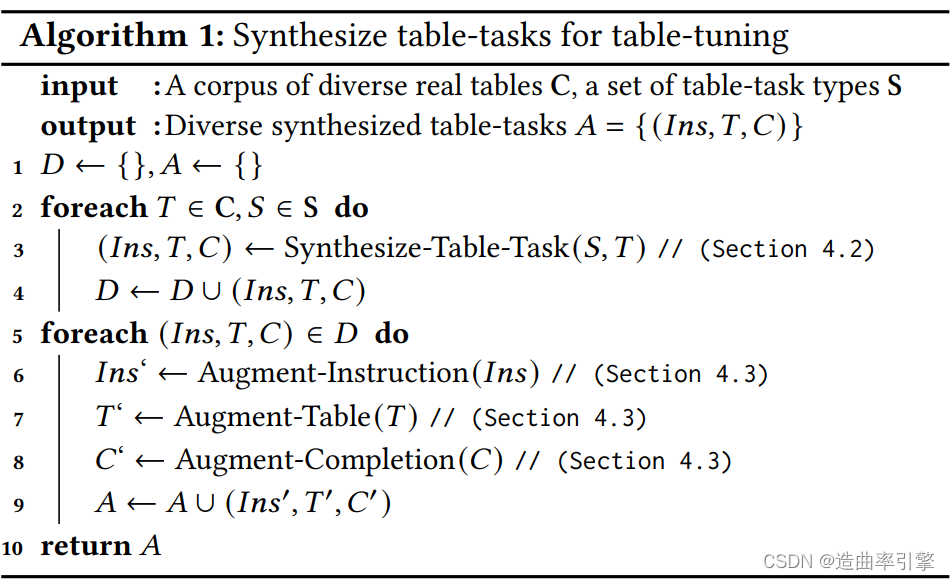
Synthesize diverse table-tasks
Synthesize new table-tasks for task-diversity
几种表格任务的合成方法介绍:
- (T-13) Table summarization (TS):选取具备描述性标题的网络表格,将标题作为 completion
- (T-14) Column augmentation:将表格的前一部分列作为 table,后一部分列作为 completion
- (T-15) Row augmentation (RA):与 T-14 相似
- (T-16) Row/column swapping (RS/CS): 将变换顺序后的表格作为 completion
- 像 T-16 这样简单的表格任务在以往研究中极少被测试过,在这里并非是将行/列交换作为测试目标,而是通过这样的方式使模型能够更好地阅读和操作表格数据
- (T-17) Row/column filtering:选取需要筛选出的行、列作为 completion
- 同样用于训练模型操作表格的能力
- (T-18) Row/column sorting (RS/CS):将排列好的表格作为 completion
- (T-11) Head-value matching (HVM):将表格列表头摘出并打乱,和没有列表头的表格一起作为 table,将完整的表格作为 completion
- 为了帮助模型更好地理解和关联起列表头和其下单元格内容的语义
Synthesize new table test-cases for data-diversity
对于一些在以往研究中比较重要的表格任务,也需要合成相应的数据:
- (T-5) Row-to-row Data Transformation (R2R):寻找表格中满足转换关系 𝑃 (𝐶𝑖𝑛) = 𝐶𝑜𝑢𝑡 的相关列,随机去除𝐶𝑜𝑢𝑡中的一个单元格,作为 table,完整的表格作为 completion
- (T-7) Schema Matching (SM):将表格的行数据分为两份,将其中一份行数据的列表头通过语言模型进行同义替换,然后打乱两者的列顺序,作为 table
- (T-8) Data Imputation (DI):随机选取表格,随机去除一个单元格,作为 table,完整表格作为 completion
- 尽管一些 DI 任务数据不能被准确预测,但这样做有利于训练模型捕捉行列之间的潜在关系的能力
- (T-9) Error Detection (ED):随机选取表格,通过调用包,将其中随机一个单元格替换为相应的印刷错误,作为 table,错误单元格作为 completion
- (T-10) List extraction (LE) :去除表格中的列分隔符,作为 table,让模型根据垂直方向的值对齐补全分隔符
Augment synthesized table-tasks
微软团队通过task-level, table-level, instruction-level, and completionlevel 等层次的增强来提升数据多样性并避免模型的过拟合。
Instruction-level augmentations
因为在训练数据实例中重复使用相同的指令会导致过度拟合,他们使用像GPT这样的生成模型来为规范的自然语言指令生成多种变体。
Table-level augmentations
二维表在很大程度上应该是与排列顺序无关的,通过执行列置换、行置换、列抽样和行抽样等操作,以增加表任务中使用的表的多样性。
Completion-level augmentations
- Language-model assisted completion-augmentation:在 Completion 可以添加推理步骤(思维链),这被证明在复杂的表格任务上取得更好的表现。可以向像GPT这样的生成模型输入任务和任务结果,从而让模型生成相应的推理步骤添加到 Completion 。
- Ground-truth assisted completion-augmentation:对于 (T-9) Error Detection (ED) 这类任务,实践表明添加推理步骤的效果并不理想。这时可以在 Completion 中使用可用的基本事实
Additional augmentations
还有其它的一些方法:
- template-level augmentation:混合使用 zero-shot 和 few-shot 任务模版(few-shot 是指在指令后提供一些输入-输出样例)
- task-level augmentation:生成新种类的表格任务
调优和验证
将 (𝐼𝑛𝑠,𝑇 ) 作为提示,𝐶 作为 “completion”,最小化语言模型的 loss of completion。
为了严谨,要求在以下四种情形下对比表格调优后的效果:
- Out of the box zero-shot:只输入指令
- Out of the box few-shot:输入指令和随机的样例
- Task-specific prompt-tuning:当有少量用于下游任务的标记数据,执行提示调优以选择最佳指令/示例组合
- Task-specific fine-tuning:当有足够数量的标记数据,执行针对特定任务的微调
实验
实验设计
- 对比模型:GPT-3.5 (text-davinci-002) 与 Table-GPT-3.5 (text-davinci-002 +table-tune);ChatGPT (text-chat-davinci-002) 与 Table-ChatGPT (text-chat-davinci-002 +table-tune)
- 训练任务和数据: T-5 to T-18
- T-6 和 T-12 不能自动合成,使用现成的基准数据集
- T-6 和 T-12 以外的任务使用 50:50 比例的 zero-shot 和 few-shot 任务模版
- 测试任务和数据:T-1 to T-4 ;T-5 to T-9
- 确保测试数据与表调优的训练数据来自不同的数据集并且有着非常不同的特性

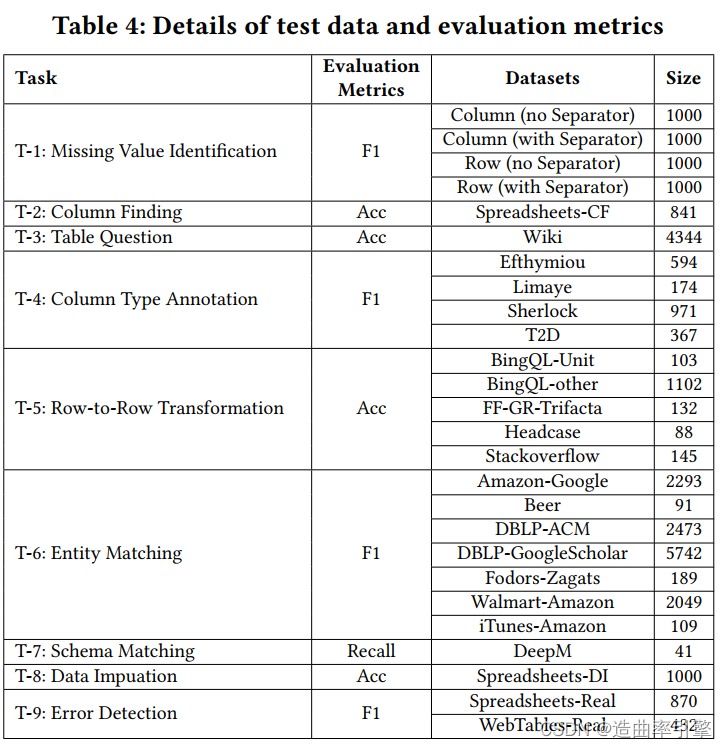
实验结果
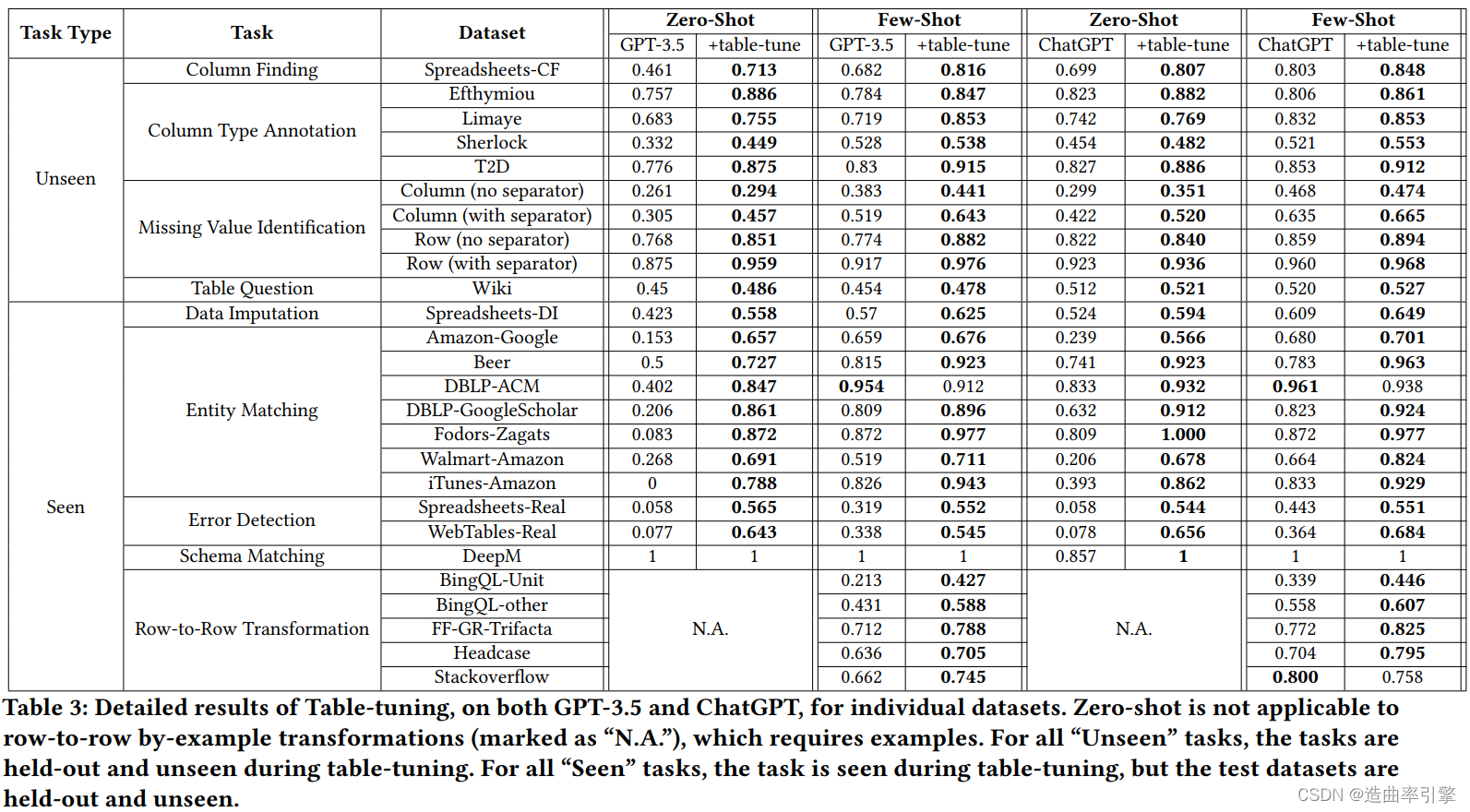
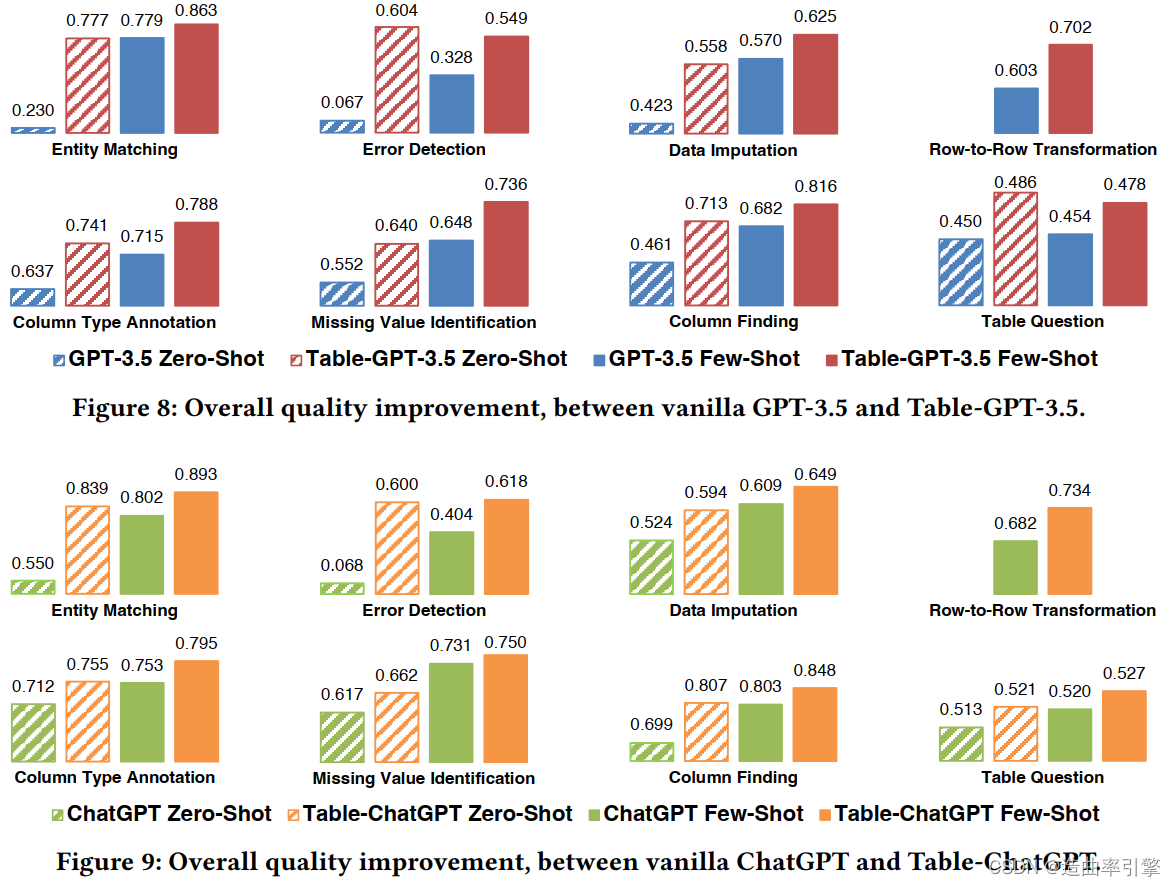
结果分析
- 总体来讲,得益于多样的表格任务类型,表格调优得到的模型在大多数表格任务上的表现都有提升
- 基于 GPT-3.5 和 ChatGPT 的表格调优都取得了提升,说明论文提出的表格调优方法具有普遍适用性
- 在单任务提示工程和单任务微调两种情景下,表格调优后的 Table-GPT-3.5 都比 GPT-3.5 表现更好(该部分实验结果见论文,篇幅较小)
Sensitivity Analysis
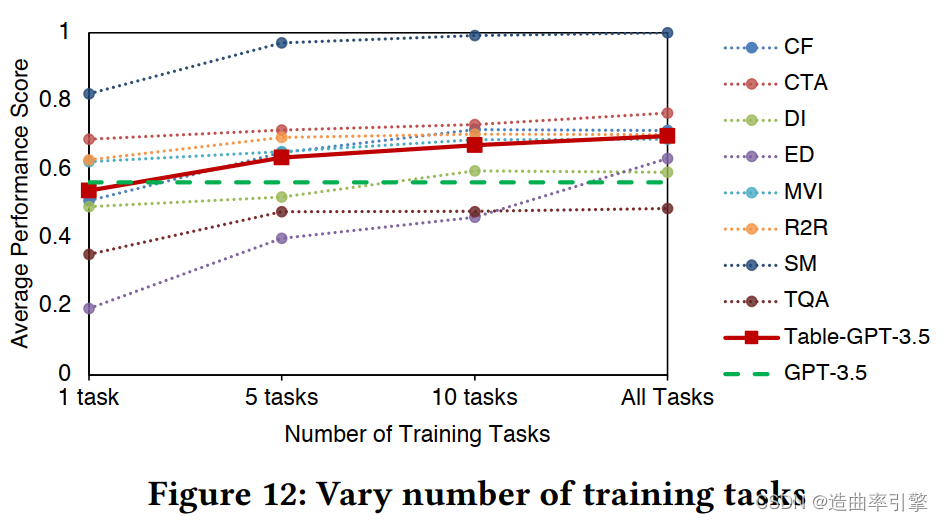
arxiv 论文 pdf 中,5.4 节第一张图引用错误,应为 Figure 12
- Varying the number of training tasks:当表格调优退化为单任务调优时,模型在其它任务上的性能普遍变差;随着训练任务种类增加,训练效果提升
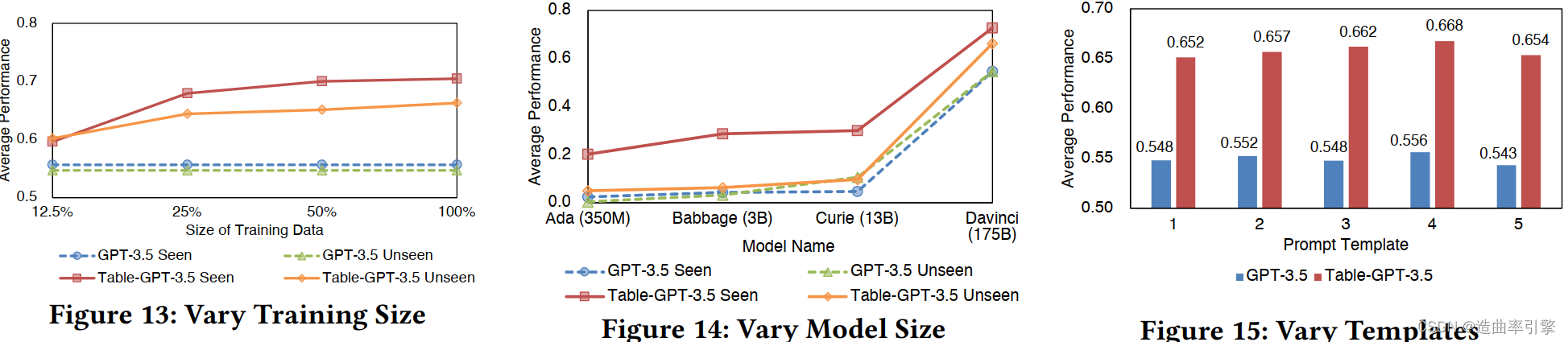
- Vary the amount of training data:随着训练数据增加,模型在可见、不可见任务上的表现都有所提升(当数据量达到一定程度,提升幅度降低)
- Vary base-model Size:对于不可见的任务(重要的是检查模型的泛化性),表调优模型在较小的模型(Ada/Babbage/Curie)上产生的提升很少,但是在较大的模型(GPT-3.5和ChatGPT)上的提升突然变得显著,这印证了大语言模型的涌现能力
- Vary prompt templates:表调优模型对于不同的提示具有鲁棒性
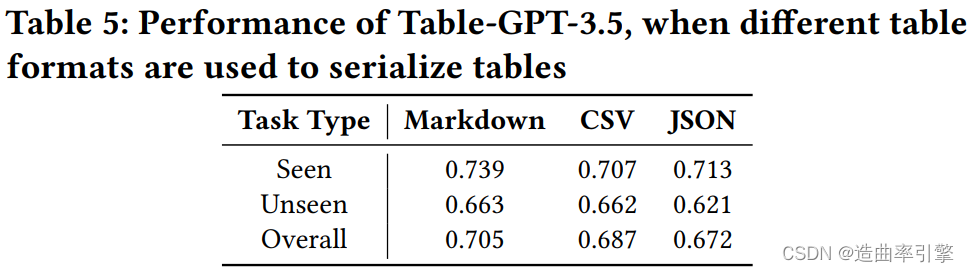
- Vary table formats:markdown 平均表现最好,但其它两个格式的差距不大
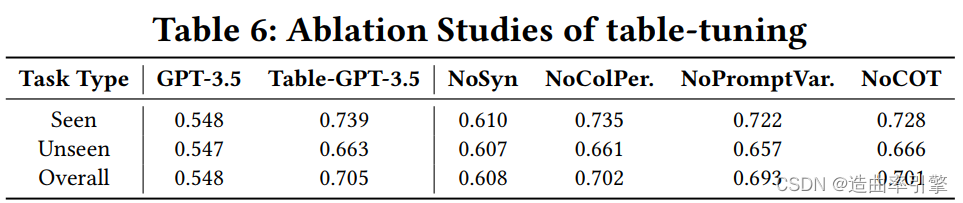
消融研究
- No task-level augmentation (no synthesized tasks):性能降低明显,表明实验生成的多样表格任务类型具有显著贡献
- No table-level augmentation (no column permutations):略有降低
- No instruction-level augmentation (no prompt variations):略有降低,微软团队认为这可能是因为多样的表格任务类型某种程度上抵消了重复相同的提示带来的错误影响
- No completion-level augmentation (no chain-of-thought):略有降低
一些阅读思考
-
论文中的示例表格都为类 markdown 格式的简单表格,这种表格无法表示合并单元格等更复杂的表格结构。论文测试过的 Markdown、CSV、JSON 三种格式中,JSON可以表示更复杂的表格结构,但论文缺乏进一步的论述。
- 因此不能确认主要基于简单结构表格数据调优得到的模型是否能够在复杂表格结构上取得相应的优秀表现。
-
在本论文的实验中,并没有将 T-3 表格问答任务作为训练数据(可能是因为没法自动生成大量的训练数据)。可以发现,在实验结果中,T-3 任务的表现提升幅度并不大;而其它同时用于训练和测试的任务类型在 Zero-Shot 上大都取得了显著的提升。
- 我认为这种现象表明目前的表格调优在推广到新的、复杂的表格任务时的表现仍然有待提升。
- 如果对特定的一些表格任务有需求,仍然应当需要一定数量的该类型任务训练数据,以取得预期的效果。
- 有趣的是,微软有发布过一个表格问答数据集,而同为微软发布的 Table-GPT 却没有选择该数据集用于表格问答的微调或评估。
-
在消融实验中,no column permutations 的性能降幅并不大。
- 这可能是因为测试性能的数据集并没有针对列顺序敏感度进行定向测试,不过实践中这对应了一种极端情况,训练中不能忽略这一步骤。
-
在消融实验中,no chain-of-thought 的性能降幅并不大。
- 笔者对思维链的预期比较高,因此对这个结果比较惊讶。初步推断可能有以下几点原因:
- LLM生成的思维链不够严谨
- 含有思维链的训练样本较少
- 训练用的任务大多是选取能够自动生成数据的任务类型,逻辑链对这些任务类型没有显著的帮助。如果是表格问答这类任务,逻辑链可能能够起到更显著的正面作用
- 笔者对思维链的预期比较高,因此对这个结果比较惊讶。初步推断可能有以下几点原因:
-
Vary base-model Size 测试中的指标为平均表现,并没有呈现出模型在各类任务上的表现,而作者却分析了模型在 unseen 任务上的性能跃升。
- 仅仅展现模型的平均表现并不能证明什么,尤其是作者直接从13B跳到了175B,缺乏足够的中间规格模型测试,并不能展现出大模型的涌现能力。
- 此外,不同任务类型显然对模型性能要求不同,是否存在一些简单任务在不同规格模型上表现变化不大?而另一些复杂任务在大模型上才体现出明显的性能提升?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









