






#作者:韩长刚
官方地址https://hbase.apache.org/book.html#configuration查看hadoop和hbase的版本对应表,选择合适的版本下载安装
每台主机的hosts文件都要写入三台主机名解析
192.168.3.181 hadoop1
192.168.3.182 hadoop2
192.168.3.183 hadoop3
在每台机子上安装ntp服务
$ sudo apt -y install ntpdate
$ sudo ntpdate cn.pool.ntp.org
$ sudo hwclock --systohc
安装JDK1.8版本,这里不再描述安装步骤
设置免密钥登录
$ ssh-keygen -t rsa -b 2048
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
三台机子都要相同用户名设置密钥,并且所有主机的authorized_keys文件内同时具有三个机子的公钥,设置完成后三台机子互相连接,为的是把第一次连接的yes去掉
安装zookeeper集群
$ sudo tar -C /data/ -xf apache-zookeeper-3.8.0-bin.tar.gz
$ cd /data
$ sudo mv apache-zookeeper-3.8.0-bin zookeeper
$ cd /data/zookeeper/conf
$ sudo cp zoo_sample.cfg zoo.cfg
修改zookeeper配置文件
$ sudo vim zoo.cfg
clientPort=2182
dataDir=/data/zookeeper/data
dataLogDir=/data/zookeeper/logs
server.1=192.168.3.181:2888:3888
server.2=192.168.3.182:2888:3888
server.3=192.168.3.183:2888:3888
创建相关目录
$ sudo mkdir -p /data/zookeeper/{data,logs}
创建ServerID标识,三台机子的zookeeper分别执行
$ sudo sh -c "echo 1 > /data/zookeeper/data/myid"
$ sudo sh -c "echo 2 > /data/zookeeper/data/myid"
$ sudo sh -c "echo 3 > /data/zookeeper/data/myid"
启动集群,在三台机子上分别执行
$ sudo chown -R $USER:$USER /data/zookeeper
$ bash /data/zookeeper/bin/zkServer.sh start
查看各节点状态
$ /data/zookeeper/bin/zkServer.sh status
下载hadoop
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/
解压hadoop
$ sudo tar -C /data/ -xf hadoop-2.7.7.tar.gz
$ cd /data;sudo mv hadoop-2.7.7 hadoop
$ sudo mkdir -p /data/hadoop/tmp/dfs/{data,name}
$ cd /data/hadoop/etc/hadoop
连续修改七个配置文件
1.修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9010</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
</configuration>
2.修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.rpc-address</name>
<value>hadoop1:9010</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>hadoop1</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>hadoop1:50090</value>
</property>
<property>
<name>dfs.datanode.directoryscan.throttle.limit.ms.per.sec</name>
<value>1000</value>
</property>
</configuration>
3.将mapred-site.xml.template复制成mapred-site.xml并修改
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
4.修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<property>
<!--ResourceManager对客户端暴露的地址-->
<name>yarn.resourcemanager.address</name>
<value>hadoop1:8032</value>
</property>
<property>
<!--ResourceManager对ApplicationMaster暴露的地址-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop1:8030</value>
</property>
<property>
<!--ResourceManager对NodeManager暴露的地址-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop1:8031</value>
</property>
<property>
<!--ResourceManager对管理员暴露的地址-->
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop1:8033</value>
</property>
<property>
<!--ResourceManager对外web暴露的地址,可在浏览器查看-->
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop1:8088</value>
</property>
</configuration>
5.修改yarn-env.sh添加jdk环境变量
export JAVA_HOME=/usr/local/jdk
6.修改hadoop-env.sh
添加jdk环境变量
export JAVA_HOME=/usr/local/jdk
7.修改slaves
删掉localhost添加三台机子的主机名
hadoop1
hadoop2
hadoop3
将hadoop整个目录通过scp复制到另外两台机子,然后在所有机子上将hadoop添加到环境变量
$ sudo vim /etc/profile
export HADOOP_HOME=/data/hadoop
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
$ source /etc/profile
$ sudo chown -R $USER:$USER /data/hadoop
在hadoop1上初始化namenode
$ hadoop namenode -format

在hadoop1上启动namenode
$ hadoop namenode
在三个节点分别启动datanode
$ hadoop datanode
这次关闭之后下次再启动就可以使用脚本启动
$ start-dfs.sh
$ start-yarn.sh
或者直接
$ start-all.sh
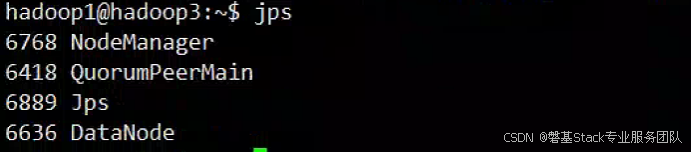
接着使用jps查看进程
hadoop1(master)
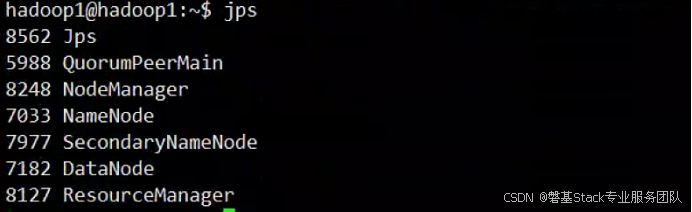
hadoop2和hadoop3(slave)
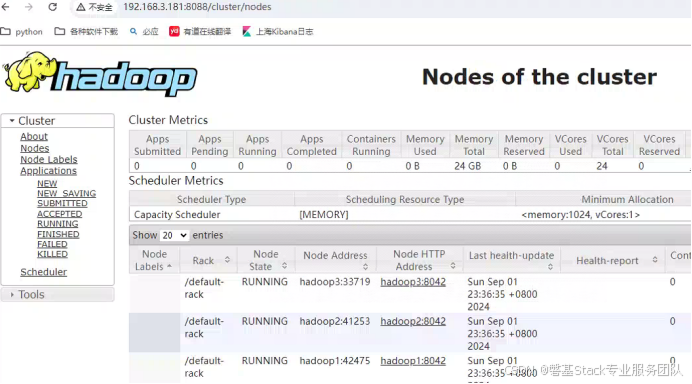
在浏览器输入http://192.168.3.181:8088可以看到YARN集群状态
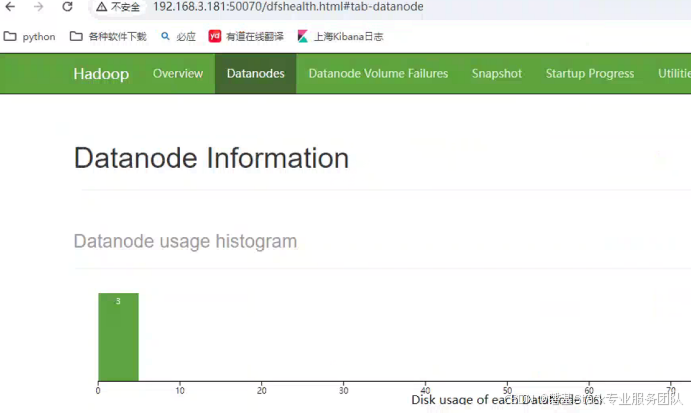
输入http://192.168.3.181:50070查看HDFS状态
基于hadoop分布式集群部署hbase
下载hbase
https://archive.apache.org/dist/hbase/
解压
$ sudo tar -C /data/ -xf hbase-2.4.9-bin.tar.gz
$ cd /data;sudo mv hbase-2.4.9 hbase
$ sudo mkdir /data/hbase/tmp
$ cd /data/hbase/conf
修改hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9010/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2182</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.temp.dir</name>
<value>/data/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/data/zookeeper/data</value>
</property>
</configuration>
修改hbase-env.sh
$ sudo vim hbase-env.sh
将export HBASE_MANAGES_ZK=true修改为false,关闭hbase自带的zookeeper
添加export JAVA_HOME=/usr/local/jdk
修改regionservers
hadoop1
hadoop2
hadoop3
新建backup-masters,这个配置文件的作用是选择其中一个作为主的备份节点
$ sudo vim backup-masters
hadoop2
将/data/hbase整个目录复制给其他两台机子,将hadoop3的backup-masters删除,存留hadoop1和hadoop2的该文件,并修改所有机子的环境变量
$ sudo vim /etc/profile
export HBASE_HOME=/data/hbase
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
$ source /etc/profile
$ sudo chown -R $USER:$USER /data/hbase
在hadoop正常运行的前提下启动hbase
$ start-hbase.sh
在hadoop1节点上执行jps命令
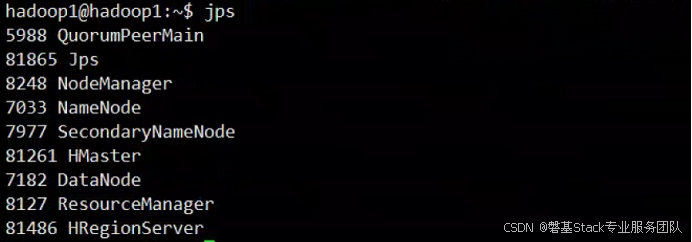
HRegionServer和HMaster即为hbase进程,三台机子中hadoop3没有Hmaster这个进程
在hadoop1上测试hbase
$ hbase shell
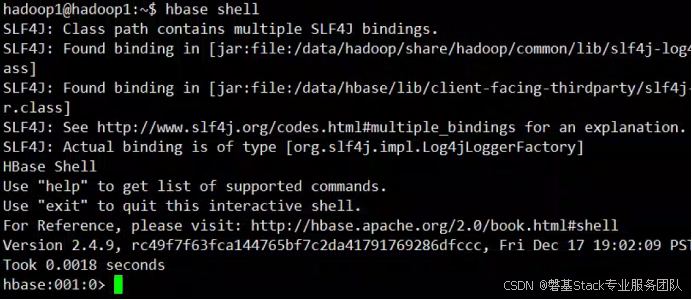
通过浏览器访问http://192.168.3.181:16010查看整个集群的状态信息

基于hadoop分布式集群部署hive
mysql的安装这里不再书写,下面是为hive配置mysql
mysql> create user hive identified by 'hive'; #创建一个用户名为hive,密码为hive的用户
mysql> create database hive; #创建一个hive的数据库
mysql> grant all privileges on hive.* to 'hive'@'%'; #给hive用户授权
mysql> flush privileges;
下载并解压hive
hive的下载地址:https://archive.apache.org/dist/hive/
# tar -xf apache-hive-2.3.9-bin.tar.gz -C /data/
# cd /data;mv apache-hive-2.3.9-bin hive
三台机子配置hive
# vim /etc/profile
export HIVE_HOME=/data/hive
export PATH=$PATH:$HIVE_HOME/bin
# source /etc/profile
查看hive环境变量配置是否生效
# hive --version

在hadoop中添加hive的相关文件目录并设置相应权限
# hadoop fs -mkdir -p /data/hive/warehouse
# hadoop fs -mkdir -p /data/hive/tmp
# hadoop fs -mkdir -p /data/hive/log
# hadoop fs -chmod -R 0777 /data/hive
进入/data/hive/conf目录执行以下命令
# cp hive-env.sh.template hive-env.sh
打开hive-env.sh文件向其中添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
export HADOOP_HOME=/data/hadoop
export HIVE_HOME=/data/hive
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export HIVE_AUX_JARS_PATH=${HIVE_HOME}/lib
修改hive-site.xml文件
# cp hive-default.xml.template hive-site.xml
清空hive-site.xml文件,添加以下内容
<configuration>
<!-- 设置hive仓库在HDFS上的位置 -->
<property>
<name>hive.exec.scratchdir</name>
<value>/data/hive/tmp</value>
</property>
<!--资源临时文件存放位置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/data/hive/warehouse</value>
</property>
<!-- 设置日志位置 -->
<property>
<name>hive.querylog.location</name>
<value>/data/hive/log</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false&allowPublicKeyRetrieval=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
前往mysql官网下载JDBC驱动,官方网址https://dev.mysql.com/downloads/connector/j/
点击Archives下载历史版本
选择Platform Independent, ZIP Archive进行下载
解压mysql-connector-java-5.1.49.zip,将mysql-connector-java-5.1.49-bin.jar复制到/data/hive/lib目录中
初始化hive
# schematool -dbType mysql -initSchema
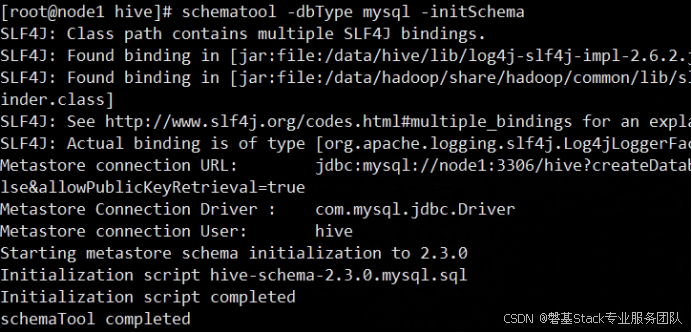
进入mysql查看hive库中的表信息
mysql> use hive;
mysql> show tables;
启动hive
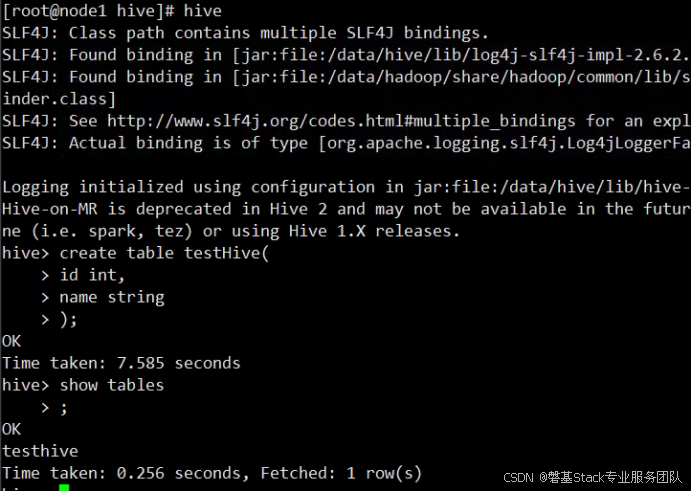
# hive
在hive中创建一个表,验证hive运行是否正常
hive> create table testHive(
id int,
name string
);
创建成功后再查看刚创建的表
hive> show tables;
配置其他节点
使用scp命令拷贝/data/hive整个目录至其他两个节点
,在其他两个节点上配置hive的环境变量,并在这两个从节点中的hive-site.xml添加以下配置
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.3.110:9083</value>
</property>
启动metastore服务
在使用slave节点访问hive之前,在node1节点中,执行hive --service metastore &来启动metastore服务
,metastore服务对应的进程为RunJar,使用jps命令即可查看
两个节点启动hive
# hive
hive>show tables;
node2和node3上看到node1上创建的表,集群创建完成
Spark集群分布式安装
下载Spark安装包
https://archive.apache.org/dist/spark/
安装基础
1、JDK1.8安装成功
2、zookeeper安装成功
3、hadoop2.7.7HA或普通分布式安装成功
Spark安装
# tar -C /data/ -xf spark-2.4.8-bin-without-hadoop.tgz
# cd /data/;mv spark-2.4.8-bin-without-hadoop spark
# cd spark/conf/
# cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
export HADOOP_CONF_DIR=/data/hadoop/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/data/hadoop/bin/hadoop classpath)
export HADOOP_HDFS_HOME=/data/hadoop
export SPARK_HOME=/data/spark
export SPARK_MASTER_IP=192.168.3.110
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_HOST=node1
export SPARK_WORKER_CORES=2
export SPARK_WORKER_PORT=8901
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=2g
export SPARK_MASTER_WEBUI_PORT=8079
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2182,node2:2182,node3:2182 -Dspark.deploy.zookeeper.dir=/spark"
复制slaves.template成slaves
# cp slaves.template slaves
# vim slaves
node1
node2
node3
将安装包通过scp分发给其他两个节点,放在和node1同样的安装路径下
所有节点均要配置环境变量
# vim /etc/profile
export SPARK_HOME=/data/spark
export PATH=$PATH:$SPARK_HOME/bin
# source /etc/profile
在node1节点上启动spark集群
# cd /data/spark/sbin/
# ./start-all.sh
# jps
正常显示worker和master两个进程
,如果其他两个节点只显示worker,需要在其他两个节点上分别执行
# start-master.sh
再次查看进程即可
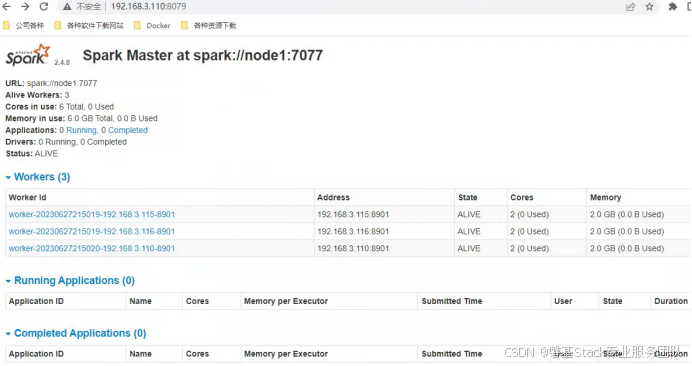
访问http://192.168.3.110:8079查看spark节点的各种状态,其他节点也是这种访问方式
提交jar包并验证
找到spark目录下的jar包

# cd /data/spark/bin
# ./spark-submit --master spark://192.168.3.110:7077 --class org.apache.spark.examples.SparkPi
--executor-memory 512M --total-executor-cores 2 /data/spark/examples/jars/spark-examples_2.11-2.4.8.jar 1000




















 390
390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









