







#作者:朱雷
文章目录
一、Promethues exporter简介
1.1. 定义与作用
Exporter 是 Prometheus 生态中用于采集目标系统监控数据并将其转换为 Prometheus 兼容格式的组件。
其核心作用包括:
数据转换:将非 Prometheus 原生支持的监控数据(如硬件、数据库、中间件等)标准化为 Prometheus 可识别的指标格式。
端点暴露:通过 HTTP 服务提供 /metrics 默认接口,供Prometheus Server 定期拉取数据。
1.2. Exporter分类
| 类型 | 特点 | 示例 | 原理 |
|---|---|---|---|
| 直接采集型 | 监控目标原生支持 Prometheus 协议,直接暴露指标接口(无需独立 Exporter) | Kubernetes | 目标系统内置指标生成逻辑 |
| 间接采集型 | 需独立部署 Exporter,通过适配器或脚本从目标系统采集并转换数据 | Node Exporter、MySQL Exporter、Redis Exporter | Exporter 调用目标系统API或连接到目标系统使用工具命令生成指标 |
二、开发环境
| 主机node | Go版本 | Redis cluster版本 | 备注 |
|---|---|---|---|
| BCLinux | >=1.16 | 6.2.12 | 3主节点/3从节点 |
三、开发指南
3.1. 指标类型
Prometheus 文档: https: //prometheus.io/docs/concepts/metric_types/
Prometheus 客户端库提供四种核心指标类型:
| 指标类型 | 说明 | 备注 |
|---|---|---|
| Counter | 计数器:是一种累积指标,表示单个单调递增的计数器,其值只能在重新启动时增加或重置为零 可以使用计数器来表示已处理的请求数、已完成的任务数或错误数 | 不要使用计数器来显示可能减少的值 |
| Gauge | 仪表: 表示可以任意上升或下降的单个数值 | 仪表通常用于测量温度或当前内存使用情况等值,但也用于测量可以上升和下降的“计数”,例如并发请求的数量 |
| Histogram | 直方图: 对观察结果进行采样(通常是请求持续时间或响应大小等) ,并将它们计数到可配置的存储桶中。提供所有观察值的总和 | 可以从直方图甚至直方图聚合中计算分位数。直方图也适用于计算 Apdex 分数。在对桶进行操作时,请记住直方图是累积的 |
| Summary | 摘要:会抽样观察结果(通常是请求持续时间和响应大小等)。虽然它还提供观察结果的总数和所有观察值的总和,但它会在滑动时间窗口内计算可配置的分位数 |
除了基本指标类型 Gauge、Counter、Summary 和 Histogram 之外,Prometheus 数据模型的一个非常重要的部分是以“标签”的维度对样本进行分区,从而生成指标向量。
基本类型包括 GaugeVec、CounterVec、SummaryVec 和 HistogramVec。
虽然只有基本指标类型实现了 Metric 接口,但指标及其向量版本都实现了 Collector 接口。Collector 管理大量指标的收集,但为了方便起见,指标也可以“自行收集”。请注意,Gauge、Counter、Summary 和 Histogram 本身是接口,而 GaugeVec、CounterVec、SummaryVec 和 HistogramVec 不是。
要创建 Metrics 及其向量版本的实例,需要一个合适的Opts 结构,即 GaugeOpts、CounterOpts、SummaryOpts 或 HistogramOpts。
3.2.一个简单例子
package main
import (
"log"
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
type metrics struct {
cpuTemp prometheus.Gauge
hdFailures *prometheus.CounterVec
}
func NewMetrics(reg prometheus.Registerer) *metrics {
m := &metrics{
cpuTemp: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "cpu_temperature_celsius",
Help: "Current temperature of the CPU.",
}),
hdFailures: prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "hd_errors_total",
Help: "Number of hard-disk errors.",
},
[]string{"device"},
),
}
reg.MustRegister(m.cpuTemp)
reg.MustRegister(m.hdFailures)
return m
}
func main() {
// Create a non-global registry.
reg := prometheus.NewRegistry()
// Create new metrics and register them using the custom registry.
m := NewMetrics(reg)
// Set values for the new created metrics.
m.cpuTemp.Set(65.3)
m.hdFailures.With(prometheus.Labels{"device":"/dev/sda"}).Inc()
// Expose metrics and custom registry via an HTTP server
// using the HandleFor function. "/metrics" is the usual endpoint for that.
http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{Registry: reg}))
log.Fatal(http.ListenAndServe(":8080", nil))
}
这是个基本的程序,它导出两个指标,一个仪表和一个计数器,后者带有标签,可将其转换为(一维)向量。它使用自定义注册表注册指标,并通过 /metrics 端点上的 HTTP 服务器公开它们。
3.3.开发一个redis cluster exporter
从上面简单例子可以知道,开发到采集流程为:
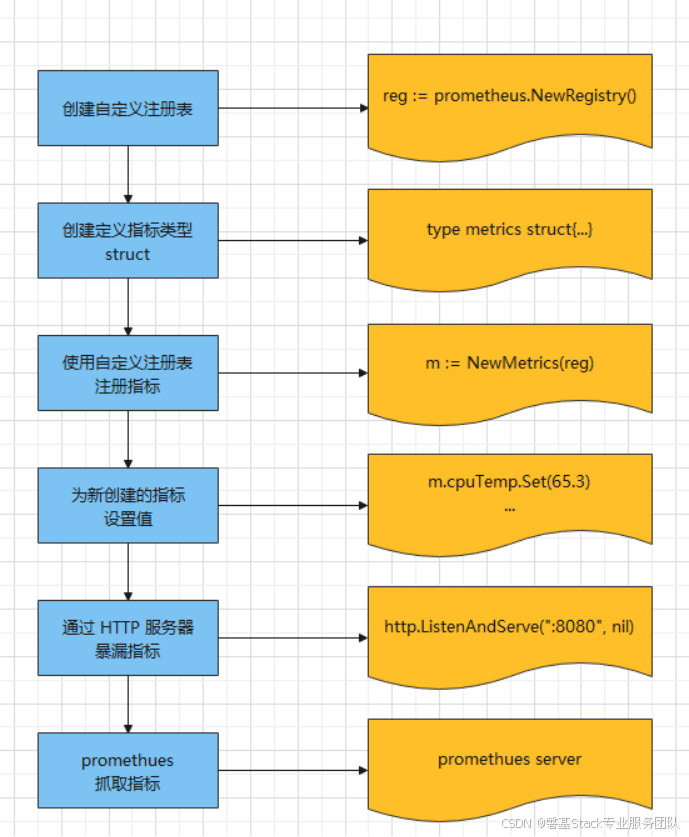
从流程图中可以看出,除了 “设置指标值” 需要自己实现外,其余都是标准化操作。
下面我们根据这个流程开发一个redis cluster exporter 参考,抛砖引玉,并在后面扩展成可以自定义监控多台redis cluster 实例上的集群状态数据。
关键代码:
3.3.1. 定义指标类型
type clusterMetrics struct {
cluster_state prometheus.Gauge
cluster_slots_assigned prometheus.Gauge
cluster_slots_ok prometheus.Gauge
cluster_slots_pfail prometheus.Gauge
cluster_slots_fail prometheus.Gauge
cluster_known_nodes prometheus.Gauge
cluster_size prometheus.Gauge
// cluster_size *prometheus.CounterVec
}
3.3.2. 使用自定义注册表注册指标
func NewClusterMetrics(reg prometheus.Registerer) *clusterMetrics {
m := &clusterMetrics{
cluster_state: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_state",
Help: "redis cluster current state ok or not",
}),
cluster_slots_assigned: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_slots_assigned",
Help: "分配的槽位数",
}),
cluster_slots_ok: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_slots_ok",
Help: "不在FAIL或PFAIL状态槽位数",
}),
cluster_slots_pfail: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_slots_pfail",
Help: "在PFAIL状态槽位数",
}),
cluster_slots_fail: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_slots_fail",
Help: "在FAIL状态槽位数",
}),
cluster_known_nodes: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_known_nodes",
Help: "the number of node",
}),
cluster_size: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "redis_cluster_size",
Help: "主节点数",
}),
}
reg.MustRegister(m.cluster_state)
reg.MustRegister(m.cluster_slots_assigned)
reg.MustRegister(m.cluster_slots_ok)
reg.MustRegister(m.cluster_slots_pfail)
reg.MustRegister(m.cluster_slots_fail)
reg.MustRegister(m.cluster_known_nodes)
reg.MustRegister(m.cluster_size)
return m
}
3.3.3. 设置指标状态数据
func GetRedisClusterStateMetrics(addr, pwd string, logger klog.Logger) *prometheus.Registry {
reg := prometheus.NewRegistry()
m := NewClusterMetrics(reg)
// 创建 Redis 客户端
conn := redis.NewClient(&redis.Options{
Addr: addr, // Redis 地址,可以是本地或者远程
Password: pwd, // 如果没有设置密码,可以为空
// DB: 0, // 使用默认的 DB
MaxRetries: 3,
})
ok, err := conn.Ping().Result()
level.Info(logger).Log("Ping 返回值: %s", ok)
if err != nil || ok != "PONG" {
level.Error(logger).Log("redis连接失败. redis地址: %s. 错误信息: %s %s", addr, ok, err)
}
level.Info(logger).Log("redis连接成功, redis地址: %s", addr)
val, err := conn.Do("CLUSTER", "INFO").Result()
if err == redis.Nil || err != nil || val.(string) == "" {
level.Error(logger).Log("获取redis state 地址: %s. 错误信息: %s", addr, err)
return reg
}
infoMap := TextToMap(val.(string))
m.cluster_state.Set(0)
if val, ok := infoMap["cluster_state"]; ok && val == "ok" {
m.cluster_state.Set(1)
}
if val, ok := infoMap["cluster_slots_assigned"]; ok {
floatValue, _ := strconv.ParseFloat(val, 64)
m.cluster_slots_assigned.Set(floatValue)
}
if val, ok := infoMap["cluster_slots_ok"]; ok {
floatValue, _ := strconv.ParseFloat(val, 64)
m.cluster_slots_ok.Set(floatValue)
}
if val, ok := infoMap["cluster_slots_pfail"]; ok {
floatValue, _ := strconv.ParseFloat(val, 64)
m.cluster_slots_pfail.Set(floatValue)
}
if val, ok := infoMap["cluster_slots_fail"]; ok {
floatValue, _ := strconv.ParseFloat(val, 64)
m.cluster_slots_fail.Set(floatValue)
}
if val, ok := infoMap["cluster_known_nodes"]; ok {
floatValue, _ := strconv.ParseFloat(val, 64)
m.cluster_known_nodes.Set(floatValue)
}
if val, ok := infoMap["cluster_size"]; ok {
floatValue, _ := strconv.ParseFloat(val, 64)
m.cluster_size.Set(floatValue)
}
return reg
}
从 cluster info 获取集群状态信息数据,经处理后给指标设置值。
其他指标可以自行定义指标类型,并从redis的字段标签{LABLES} INFO 中获取数据值。
3.3.4. 扩展使exporter监控多台redis集群实例
以上程序只能一个exporter监控采集一个redis 实例数据,要同时采集多个实例需要开启多个exporter进程。如果资源比较紧张,这会导致资源浪费。
我们可以改造程序让它适配采集多个redis集群实例数据。
改造思路:
提供一个多个实例连接参数信息的配置文件
修改暴漏指标信息的HTTP服务器接收redis连接信息参数name
改造代码:
配置文件参考:
host:
test001: # name 参数名,标识一个redis 实例
ip: 192.168.3.127
pwd: ''
port: 6379
test002: # name 参数名,标识一个redis 实例
ip: 192.168.2.128
pwd: xxxxx
port: 6379
程序代码参考:
func newHandler(logger klog.Logger) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
params := r.URL.Query()["name"]
level.Info(logger).Log("msg", "collect[] params", "params", strings.Join(params, ","))
host := viper.GetStringMapString(fmt.Sprintf("host.%s", params[0]))
addr := host["ip"] + ":" + host["port"]
reg := GetRedisClusterStateMetrics(addr, host["pwd"], logger)
h := promhttp.HandlerFor(reg, promhttp.HandlerOpts{Registry: reg})
h.ServeHTTP(w, r)
}
}
更多改造和完整程序实例请参考:
https://github.com/zhuleiandy888/redis-cluster-exporter-template
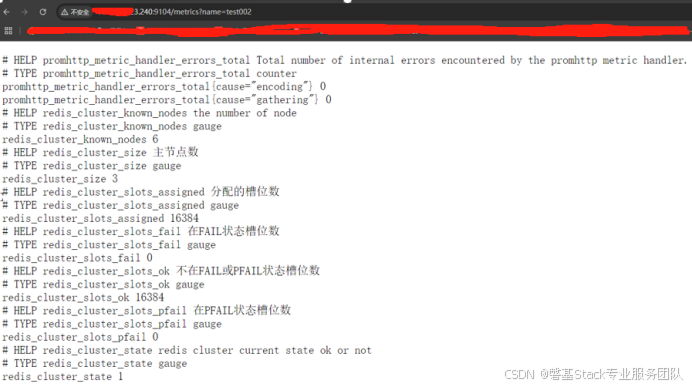
3.3.5. 监控指标展示
四、Promethues 监控配置文件参考
抓取自定义 redis cluster exporter 配置文件:
scrape_configs:
- job_name: 'redis_cluster_exporter'
scrape_timeout: 10s
scrape_interval: 30s
static_configs:
- targets:
- '192.168.3.240:9104' # 建议使用节点域名
labels:
name: test001
__metrics_path__: /metrics
__param_name: test001
- targets:
- '192.168.3.240:9104' # 建议使用节点域名
labels:
name: test002
__metrics_path__: /metrics
__param_name: test002



















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









