1、导入词典
from pyhanlp import *
def load_dictionary():
"""
加载HanLP中的mini词库
:return: 一个set形式的词库
"""
IOUtil = JClass('com.hankcs.hanlp.corpus.io.IOUtil')
path = "CoreNatureDictionary.mini.txt" #字典所在的路径
dic = IOUtil.loadDictionary([path]) #参数为列表形式
return set(dic.keySet()) #返回集合
if __name__ == '__main__':
dic = load_dictionary()
print(len(dic))
print(list(dic)[0])
2、使用字典进行分词
from pyhanlp import *
#在字典中加入‘路麟城 nr 1’保证分词正确,删除bin文件重新运行
print(HanLP.segment('''路明非累了。其实在路麟城第二次带他去那充满水银蒸汽的炼金术矩阵见小魔鬼时,
他已经决定要接受切割了。'''))
for term in HanLP.segment('''你好,欢迎在python中调用hanlp的api'''):
print(f'{term.word}\t{term.nature}')
------------------------------------------------------------
[路明非/nr, 累/a, 了/ule, 。/w, 其实/d, 在/p, 路麟城/nr, 第二/mq, 次/qv, 带/v, 他/rr, 去/vf, 那/rzv, 充满/v, 水银/n, 蒸汽/n, 的/ude1, 炼金术/n, 矩阵/n, 见/v, 小魔鬼/nz, 时/qt, ,/w,
/w, 他/rr, 已经/d, 决定/v, 要/v, 接受/v, 切割/v, 了/ule, 。/w]
路明非 nr
累 a
了 ule
。 w
from pyhanlp import *
HanLP.Config.ShowTermNature = False #不显示词性
#导入分词器
segment = JClass('com.hankcs.hanlp.seg.Other.AhoCorasickDoubleArrayTrieSegment')()
segment.enablePartOfSpeechTagging(True) #识别英文和数字
print(segment.seg("江西鄱阳湖干枯,中国six最大淡水湖变成大草原,tree"))
3、加载语料库
'my_cws_corpus.txt'
商品 和 服务
商品 和服 物美价廉
服务 和 货币
--------------------------------------
from pyhanlp import *
CorpusLoader = SafeJClass('com.hankcs.hanlp.corpus.document.CorpusLoader')
sents = CorpusLoader.convert2SentenceList('my_cws_corpus.txt')
for sent in sents:
print(sent)
-------------------
[商品, 和, 服务]
[商品, 和服, 物美价廉]
[服务, 和, 货币]
4、语法统计
from pyhanlp import *
NatureDictionaryMaker = SafeJClass('com.hankcs.hanlp.corpus.dictionary.NatureDictionaryMaker')
CorpusLoader = SafeJClass('com.hankcs.hanlp.corpus.document.CorpusLoader')
def train_bigram(corpus_path,model_path):
sents = CorpusLoader.convert2SentenceList(corpus_path)
for sent in sents:
#为兼容hanlp字典格式,为每个单词添加占位符
for word in sent:
word.setLabel('n')
#创建maker对象
maker = NatureDictionaryMaker()
#进行一元、二元统计
maker.compute(sents)
#保存文件,会得到三个文件
maker.saveTxtTo(model_path)
if __name__ == '__main__':
train_bigram('my_cws_corpus.txt','my_cws_model')
5、获取词频
from pyhanlp import *
#必须用双引号
def load_bigram(model_path):
#更改字典路径
HanLP.Config.CoreDictionaryPath = model_path + ".txt"
HanLP.Config.BiGramDictionaryPath = model_path + ".ngram.txt"
CoreDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreDictionary')
CoreBiGramTableDictionary = SafeJClass('com.hankcs.hanlp.dictionary.CoreBiGramTableDictionary')
print(CoreDictionary.getTermFrequency("商品"))
print(CoreBiGramTableDictionary.getBiFrequency("商品","和"))
if __name__ == '__main__':
load_bigram('my_cws_model')
6、构建词网
from jpype import JString
from pyhanlp import *
WordNet = JClass('com.hankcs.hanlp.seg.common.WordNet')
Vertex = JClass('com.hankcs.hanlp.seg.common.Vertex')
#更改配置中字典路径
HanLP.Config.CoreDictionaryPath = "my_cws_model.txt"
CoreDictionary = LazyLoadingJClass('com.hankcs.hanlp.dictionary.CoreDictionary')
def generate_wordnet(sent, trie):
searcher = trie.getSearcher(JString(sent), 0)
wordnet = WordNet(sent)
while searcher.next():
wordnet.add(searcher.begin + 1,
Vertex(sent[searcher.begin:searcher.begin + searcher.length], searcher.value, searcher.index))
# 原子分词,保证图连通
vertexes = wordnet.getVertexes()
i = 0
while i < len(vertexes):
if len(vertexes[i]) == 0: # 空白行
j = i +








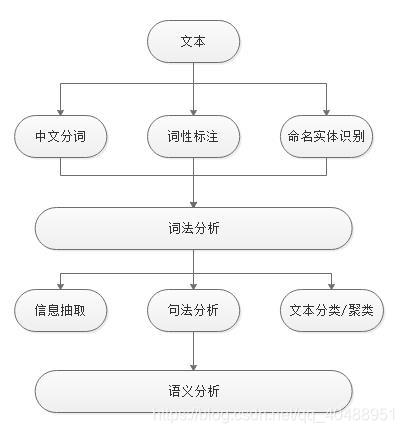
 这篇博客详细介绍了如何使用HanLP进行自然语言处理,包括导入词典、分词、加载语料库、语法统计、词频分析、词网构建、中文分词、模型评测、词性标注、命名实体识别、信息抽取以及句法分析等核心步骤,讲解了信息熵、互信息和TF-IDF等关键概念,并探讨了文本聚类和句法分析的方法。
这篇博客详细介绍了如何使用HanLP进行自然语言处理,包括导入词典、分词、加载语料库、语法统计、词频分析、词网构建、中文分词、模型评测、词性标注、命名实体识别、信息抽取以及句法分析等核心步骤,讲解了信息熵、互信息和TF-IDF等关键概念,并探讨了文本聚类和句法分析的方法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









